When it comes to cloud computing, we usually see such a description, "realized by virtualization technology". It is not difficult to see that in the concept of cloud computing, virtualization is a very basic but very important part, and it is also the realization of cloud computing. The key to many issues such as computing isolation, scalability, and security.
The basis of cloud computing is virtualization, but virtualization is only a part of cloud computing. Cloud computing is an application after virtualizing several resource pools. Many people think that virtualization is just a small boost behind cloud computing, but it is not. Regarding virtualization itself, it has long been widely used in the IT field, and there are completely different virtual technologies for different resources.
Currently, there are four types of virtualization: server virtualization, storage virtualization, memory virtualization, and network virtualization.
There are many applications of server virtualization in the industry. Using server virtualization, we can centrally manage the server's CPU, memory, disk and other hardware, and improve resource utilization efficiency through centralized dynamic on-demand allocation.
Storage virtualization separates the logical view of storage resources from physical storage, thereby providing seamless resource management for the system. However, due to the low degree of storage standardization, if the storage virtualization technology used comes from different vendors, compatibility must be considered.
Memory virtualization refers to the use of virtualization technology to realize the management of memory by the computer memory system. The memory virtualization system enables upper-layer applications to have continuously available memory, and divides multiple fragments on the physical layer to satisfy memory allocation and necessary data exchange.
Network virtualization, the use of software to separate network power from physical network elements, has something in common with other forms of virtualization. However, if network devices and servers are different, they usually face technical challenges, such as the need to perform high I/O tasks and require proprietary hardware modules for data processing.
At present, cloud computing uses server virtualization technology more, but virtualization technology itself does not only serve cloud computing.
1. Virtualization of information resources and cloud resources
1. Information resources
1. Introduction to Information Resources
Information resources can be defined as a general term for all kinds of text, numbers, audio-visual, charts and languages that can be used and generate benefits, as well as all kinds of information related to social production and life. It includes structured, semi-structured and non-institutionalized data, such as databases, document files, images, audio and video, and html, which are all documents, materials, charts, and data involved in people's production and management processes. the general term for. Management guru John Naisbitt argues that out-of-control and disorganized information is no longer a resource, but rather the enemy of the information worker.
2. Characteristics of information resources
In the network environment, information resources are quite different from traditional local information in terms of capacity, carrier, structure, distribution, mode of transmission and scope of transmission, and its new features include the following aspects.
1) Large information capacity and rapid changes
There are countless information distributed throughout the Internet, and manual work alone cannot obtain the required information in a comprehensive and timely manner. Facing the vast ocean of information, it is often difficult to get started. Or want to see the information resource you last viewed, but don't know where it is. The network has a relatively fast update speed, and managers can modify or delete existing access entries at will, making information acquisition more difficult to control.
2) Information is widely distributed and structured
In the Internet environment, information is stored in different servers and uses different data description methods; at the same time, the operating systems, databases, and character sets of each server are different, which makes network information resources complex and diverse. in a disordered state.
3) Highly integrated information lacks unified standards
The information of each information website is collected and sorted out by information administrators, which has the characteristics of cross-industry and cross-time and space, and covers a wide range. And each information management website has its own information representation and organization method, for example, a picture can be directly read by File Transport Protocol (FTP) and stored on the hard disk or stored in a database with a certain character code.
4) Various ways of storage and transmission
Most of the information storage carriers are disks and tapes, and network storage can also be used. Through the Internet, people can obtain information in various ways, such as e-mail, network download, mobile terminal, online chat and video, etc. Users can roam the world without leaving home.
5) Strong real-time information exchange
Binary information spreads at high speed on the Internet. By browsing the Internet, people can obtain real-time news and the latest changes around them. E-mail reduces the time consumption of people's communication.
3. Organization of information resources
The organization of information resources can be broadly described as the following.
1) File method
A simple way to organize and manage local and network information through the file system, which uses the idea of topic organization. Each file is given a name, which is used to identify different information and share information through the network.
FTP organizes network information in this way. File servers based on FTP and HTTP store some unstructured information, such as pictures, videos, audio and programs, etc. Realize operations such as information browsing and downloading. With the widespread demand for network information and the increase in the amount of information, the use of documents as a carrier to disseminate information has become inadequate. When the information structure is complex and more logic functions are required, the efficiency of the file management method is too low, so this method can be used as the underlying file service of the information management system to provide assistance for other functions.
2) Database mode
A database is a warehouse that organizes, stores and manages data according to the data structure, and can perform massive data storage and management. It maintains data integrity and enables data sharing. Users can flexibly set keywords and combine query conditions, and finally return matching network information. Effective query reduces network load.
A large number of information systems have been established based on database technology, and a complete information management model has been formed, which greatly improves user query efficiency and network service capabilities. The disadvantage of the database method is that it is difficult to deal with unstructured information, and the correlation between information is not intuitive. Moreover, the processing of complex information units is inefficient, and the man-machine interchangeability is poor.
3) Home page method
The information organization in the form of the home page refers to organically organizing the detailed information of relevant departments and individuals and displaying them on a specific interface. It is a more comprehensive introduction to the organization and people. Organizations and individuals are free to create homepages on the Internet, and the specific content is up to them.
4. The significance of virtualization to information resource cloud
Information resource cloud is an information resource management platform and service model built with the concept of cloud computing. It does not need to change the distribution of existing Internet resources, but uses related technologies of virtualization and information resource integration to virtualize and integrate information resources. . And carry out the organization and construction of the knowledge level, and guarantee the quality of service to provide users with safe, reliable and on-demand knowledge services.
It can be said that the more complex the user's storage environment is, the more obvious the benefits of virtualization will be. Specifically, the significance of virtualization to information resource cloud is as follows.
- Virtualization can simplify the representation, access and management of resources, and provide standard interfaces for these resources so that users can access them transparently and on demand.
- Virtualization optimizes user-facing applications, reduces storage-related management burdens, and provides a better model for data center migration, backup, disaster recovery, and load balancing.
- Virtualization can implement different applications by virtualizing several machines to form isolation. Isolation can resolve various conflicts and improve resource processing efficiency.
- Virtualization reduces the degree of coupling between users and resources, so that users do not depend on the specific implementation of resources and can also enhance the dynamic scalability of resources.
- Virtualization can uniformly provide good services on the cloud after integrating many low-cost facilities, which greatly saves the provider's development costs and users' usage costs.
- Virtualization helps to establish an elastically scalable application architecture that users can use on demand to meet different business needs at any time. The host service requested by the user can be quickly provisioned and deployed (real-time online provisioning), and the on-demand expansion or reduction of the cloud server configuration can be quickly realized within a few minutes.
5. Barriers to Information Resource Search
There is a lot of information on the Internet, and not all information obtained is usable. The diversity of network information structures and representation methods, as well as the proficiency of network users in searching the network, all cause many obstacles to the query of network information resources. The main factors are analyzed as follows.
1) Various requirements for display terminal software and hardware configuration
The characteristics of information resources directly determine the diversity of access interfaces of local and network information resources. Local files can be browsed and viewed using a file manager or user terminal; database resources can be viewed through a database client or a third-party database display view. Browsing and operation; file information or webpages in the network can be browsed using a browser, including the use of FTP and HTTP protocols, which lead to poor user experience and cumbersome management.
2) Information organization is not standardized and flooded
Most of the information is displayed in the form of web pages, and each website that publishes information has its own set of rules. Website search engine optimization (Search Engine Optimization, SEO) is not all reasonably implemented, which makes keyword retrieval difficult. The information is chaotic and lacks the necessary constraints, and the information is reproduced in external links, which will cause a large number of repetitions in the search results. Although there are a lot of choices for users, it is difficult to distinguish the essence from the dross.
3) Serious information pollution
The Internet is a kingdom of freedom, filled with all kinds of information, making us deep in the ocean of information. Moreover, it contains a large amount of out-of-control, false, outdated, and even illegal information, which reduces the quality of information resources, so the research, analysis, cleaning and review of information are becoming more and more important.
2. Resource virtualization
1. Three types of cloud computing resources
Cloud computing can divide resources into three types, namely physical resources, virtualized resources and service resources.
1) Physical Resource
Refers to the infrastructure of the cloud computing platform, including servers, storage, networks, and routers. Physical resources are managed in an intuitive and relatively fixed structure. However, due to the relatively fixed scale and structure, it is difficult to support changing service requirements.
2) Virtual Resource (Virtual Resource)
Refers to the logical mapping of physical resources generated by virtualization technology on the infrastructure, which is characterized by flexibility and changeability. Based on the support of virtualization technology, administrators can adjust the scale and quantity of resources, and expand the total amount of virtualized resources of the entire platform by increasing physical resources.
3) Service Resource
Refers to an application service unit with specific functions. By calling the service interface, the user can obtain the specific functions supported by the service without caring about the internal implementation of the service. Service instances can be called by other services, and multiple identical service instances can be combined into a load-balanced resource pool, so service instances can be regarded as a form of resource provision.
In fact, resources are realized by a service that can provide certain functions, and it can realize standardized input and output. The resource here can be hardware, such as disk, CPU, memory, server, network and special equipment, etc. It can also be software, such as mail services and web services.
2. Resource virtualization
Resource virtualization refers to the creation of an abstraction layer that abstracts resources provided by physical hardware (such as power, disk space, CPU computing cycles, memory, and networks) and provides them to logical applications (such as Web Service, email, video, and voice) etc.) in order to use these resources.
The abstraction of resources often has multiple levels. For example, in the resource model proposed by the industry at present, several levels of resource abstraction such as virtual machines, clusters, virtual data centers, and clouds have emerged. Resource abstraction defines the object and granularity of operations for the upper-layer resource management logic, and is the basis for building the infrastructure layer. The advantage of this resource abstraction is that it can provide better redundancy, flexibility, and service isolation, thereby providing users with more reliable and powerful services. How to abstract physical resources of different brands and models, manage them as a global unified resource pool and present them to customers is a core problem that must be solved at the infrastructure layer.
From another perspective, resource virtualization refers to the encapsulation of the internal attributes, structures and function realization mechanisms of real resources, and the performance of their functions in a specific form in the virtual space. Virtualized resources in the virtual space provide users or applications with a common calling interface. This mechanism makes the use of resources not tightly bound to physical resources, but can be dynamically bound in real time according to information such as resource status and capabilities. physical resources.
The difficulty of resource virtualization technology often lies in balancing resource utilization and service reliability and efficiency. Massive service requests require a large number and variety of resources. Using limited resources to serve more user requests requires improving resource utilization as much as possible. efficiency. For example, service QoS and service level agreement (Service Level Agreement, SLA) and other requirements. And must provide efficient, stable and reliable services, while reducing service response delays, service acquisition costs, etc.
In addition, cross-virtualization among various resources and cross-platform portability of the same resource virtualization technology are also problems that resource virtualization needs to face.
3. Mapping between virtualized resources and physical resources
Divide virtualization into virtualizing up (Virtualizing Up) and virtualizing down (Virtualizing Down), the former refers to providing a virtualized resource with higher performance than a single physical resource based on multiple physical resources; the latter refers to dismantling a physical resource Provide multiple virtualized resources with lower performance than this physical resource at the same time.
According to resource usage, platform resources can be divided into three types: computing resources, storage resources and network bandwidth resources.
The table below shows a comparison of the virtualization possibilities of the three resources in different forms:
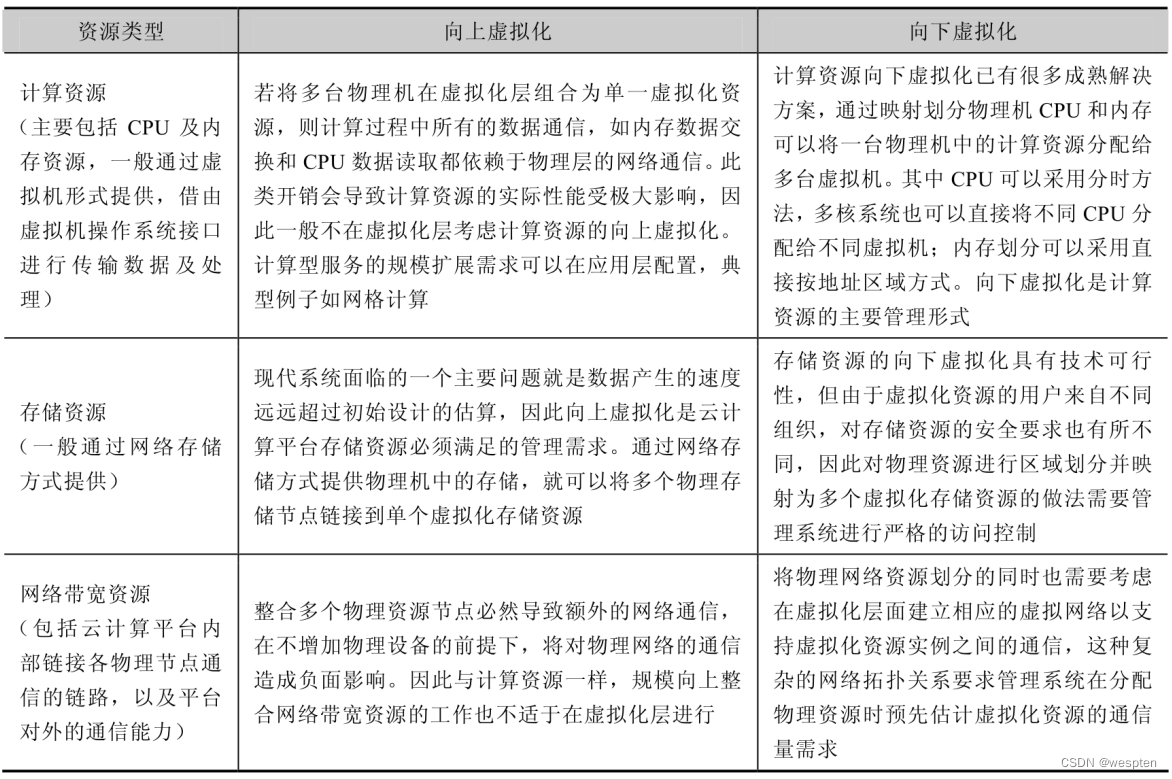
It should be noted that computing resources provide data processing functions, such as CPU and memory resources. It does not include data storage functions, and computing resources are stateless. Storage resources are used to save data and do not include complex logic calculation processing functions. Database applications need to use storage resources to record data and computing resources to analyze and execute program statements.
3. Features of virtual resources
Virtual resources in a network virtualization environment have the following characteristics.
1. Heterogeneity
Virtual resources in a network virtualization environment are of various types and have different functions, and the access configuration methods, local management system operations, and sharing rules are very different; node resources include computers, routers, switches, base stations, and mobile handheld devices.
Link resources include optical fibers, optical wavelengths, microwaves, twisted pairs, and time slots; different forms of network resources lead to differences in virtual resources, and the heterogeneity of virtual resources will inevitably lead to virtual resource management and control. Its management needs to shield the heterogeneity of these physical resources and coordinate the sharing and use of physical resources.
2. Distributed
Virtual resources are distributed geographically and belong to multiple infrastructure providers. In this distributed environment, virtual resource management is not simply to combine distributed heterogeneous virtual resources, but more importantly, to solve the problem of resource allocation and scheduling for virtual network requests, and to achieve multiple virtual networks. Coordination and sharing of resources.
In the distributed heterogeneous virtual resource environment, resource management also needs to implement operations such as resource maintenance and resource configuration, so as to provide cloud users with cloud services with QoS guarantee.
3. Autonomy
The heterogeneous and distributed characteristics of virtual resources also bring autonomy in resource management. Virtual resources first belong to an infrastructure provider, and the infrastructure provider, as the owner of virtual resources, has the highest level of management authority over resources. . That is, it has autonomous management capabilities, so it has autonomy.
On the one hand, in order to make the resources in the system available to other virtual network users, the virtual resources must accept the unified management and configuration of virtual network users according to certain policies and agreements. Therefore, virtual resource management must realize resource sharing and scheduling among various infrastructure providers, and solve issues such as authority, security, and billing management in resource autonomous environments.
On the other hand, the portability of virtual resources provides greater flexibility for infrastructure providers to optimize resource usage. Infrastructure providers can transparently implement resource migration by means of virtual node migration, virtual link migration, virtual path splitting, and virtual path aggregation. For example, infrastructure providers migrate virtual nodes between different physical nodes in their own management area. Optimize the service performance of the virtual network and ensure the connectivity of the virtual network topology.
For reasons of security and ease of management, virtual resource migration should occur within the management domain of the infrastructure provider, without the need to notify other infrastructure providers or the global network of the event.
4. Scalability
The future network is a large global network, and the infrastructure will be provided by different providers. Therefore, the design of network virtualization resource management architecture must consider the problem that the underlying layer is composed of multiple competing infrastructure providers.
Scalability is an important requirement in a network virtualization environment. On the one hand, due to the needs of facility construction, existing infrastructure providers will add new network equipment resources to expand the network scale. On the other hand, due to the needs of business expansion, the virtual network may span new infrastructure providers, and the new infrastructure providers need to be included in the management framework. The expansion of resources and business expansion lead to the expansion of the set of candidate resources, so the resource management system needs to be scalable. Update resource information in time to complete the expansion and maintenance of the virtual network.
5. Dynamic
In a network virtualization environment, virtual resources can dynamically join or leave the system. Especially in a wireless network environment, the location, service provision capability, and load of resources change dynamically over time, and physical failures of equipment may also occur. A condition that renders a resource inaccessible. In the case of dynamic changes in resources, how to maintain the continuous use of resources by the virtual network and the continuous connection relationship of the virtual network topology to ensure that virtual network services do not interrupt are problems that need to be solved in virtual resource management.
To sum up, the characteristics of virtual resources determine the functions and characteristics that the virtual resource management mechanism should have. It must be scalable and hide the heterogeneity of physical network resources, provide a unified access interface for virtual network users to shield the dynamic nature of physical network resources, and respect the local management mechanism and strategy of physical network resources, so that virtual resources Better serve virtual network users.
4. Resource performance indicators
1. Performance indicators of virtualized resources
Virtualized resources are different from cloud services, and their operating processes are quite different depending on the type of resources, so it is impossible to establish a unified indicator system. From the perspective of management system performance indicators, corresponding indicators should be selected according to the actual operation of virtualized resources, such as storage resources, including the number of reads and writes per second, read and write rates, and reliability (backup and recovery mechanisms, etc.).
1) Virtualize computing resources
Computing resources are mainly provided in the form of virtual machines, so the performance indicators of computing resources are similar to those of physical machines. In order to simplify management in the management layer, virtual machines are generally assigned with preset standard configurations.
For example, in the implementation of EC2, virtual machines are divided into different levels such as tiny, small, middle, and large, and their main performance indicators include CPU frequency, number of CPUs, memory size, CPU occupancy, memory occupancy, and data transmission. rate etc.
2) Virtualized storage resources
The main concern of the management system is adjustable performance indicators. The main controllable items of storage resources include increasing the total amount of disk space by increasing storage resources, increasing I/O performance by increasing parallel resources, and improving data reliability through redundant backup between resources. Therefore, the performance indicators of virtualized storage resources include total disk space, used disk space, number of reads and writes per second (Input/Output Per Second, IOPS), I/O rate, maximum number of connections, and data redundancy rate ( recoverable backups), etc.
3) Virtualize network bandwidth resources
The network bandwidth resource of the virtualization layer is a logical concept, which mainly represents the network communication requirements and network topology between virtualized resources. Its performance indicators include the total network bandwidth, network bandwidth occupancy rate, packet delay, and the maximum number of users. When calculating the performance requirements of network bandwidth resources, it needs to be associated with related virtualization resource performance indicators, such as storage resource disk I/O and computing resource data transfer rate. The performance of network bandwidth resources should be at least not lower than these indicators, otherwise it will become a performance bottleneck.
The following table shows some important performance indicators:
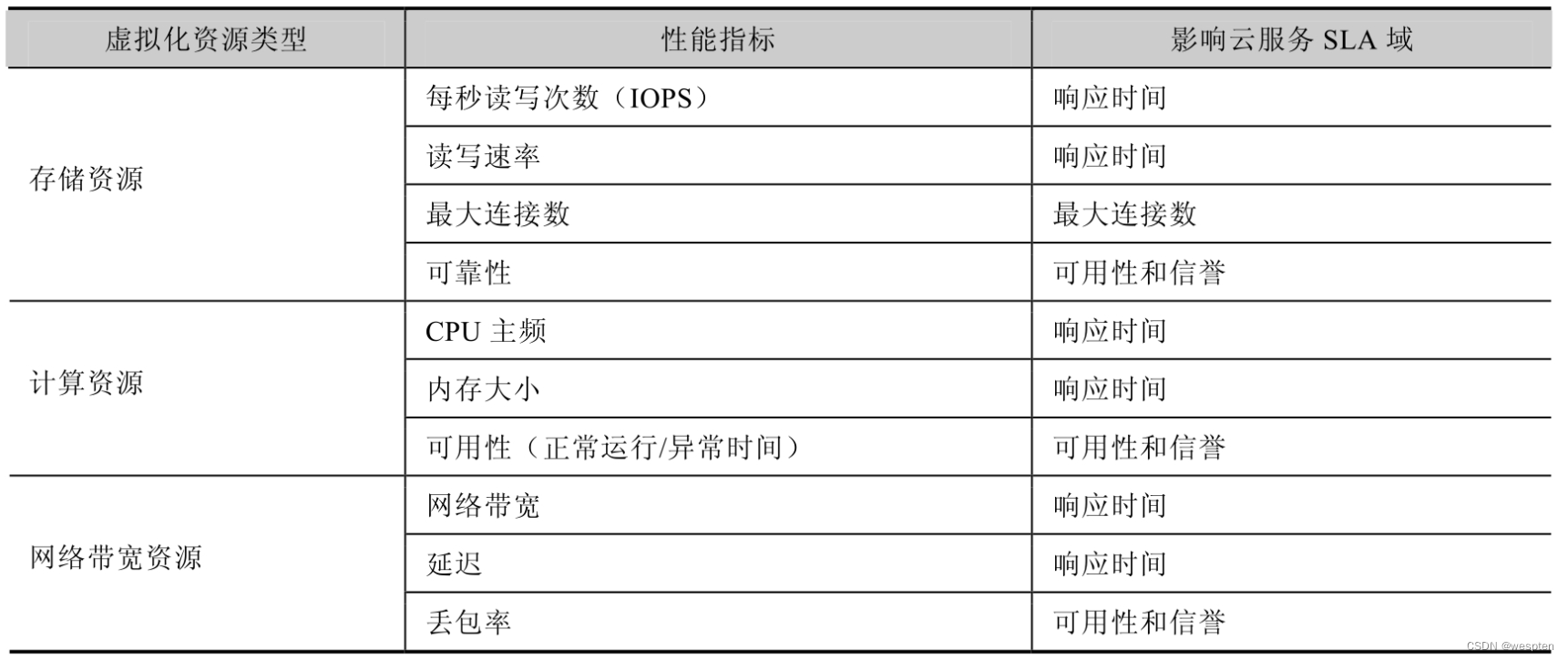
It can be seen that the virtualization resource performance indicators do not completely cover the cloud service SLA domain, because some SLA indicators do not completely determine the resource performance. For example, the availability index of computing services is mainly related to the number of computing resources and whether fault tolerance measures such as HA are taken.
On the other hand, the particularity of network bandwidth resources is that they represent the abstract concept of association between resources. It does not map directly to real-world resource entities, so some metrics that are commonly used for physical network resources do not apply to virtualized network bandwidth resources.
2. Physical resource performance indicators
The performance indicators of virtualized resources are logical summaries and split combinations of physical resource performance indicators. Logical summaries refer to physical resources including information such as node functions, hardware configurations, machine names, and motherboard interface attributes. The management layer does not need to pay attention to these contents at the virtualization resource layer, so it logically summarizes them to exclude unnecessary information; splitting and combining refers to the various topological relationships that virtualization resources occupy on physical resources.
The important performance indicators of physical resources concerned by the management system are as follows.
- Computing resources: CPU performance (Hz), number of CPUs, CPU usage, total memory, memory usage, running time, unavailable time, and network I/O rate, etc.
- Storage resources: total storage capacity, available space, read/write rate, total number of available connections, current number of connections, and network I/O rate, etc.
- Network resources: network bandwidth rate and cache size, etc.
It can be seen that, except some of the performance indicators of virtualized resources have complex logic, the rest are easy to map to physical layer performance indicators.
There is complex logic in the mapping of the following two types of performance indicators:
- Indicators such as reliability and availability cannot be directly calculated from physical resource performance indicators through splitting and combining. There are two factors that determine the reliability of virtualized resources. One is the reliability of physical resources themselves, which can be obtained through physical resource nodes. Environmental conditions (such as motherboard temperature, etc.), service failure records, and the ratio of abnormal operation time to normal operation time are calculated; the second is the operation stability of the virtualization layer. In the example of virtualized storage resources that provide support for more than two physical resources, the reliability of the storage resources is also related to the logical relationship between the physical resources. If physical resources back up each other, the reliability of virtualized resources will be improved.
- The performance indicators of virtualized network resources are not based solely on physical network resources, and this indicator determines the performance indicators of all associated physical network resources. When multiple virtualized network resources occupy the same physical network resource, resource contention will occur. In this case, the service capability of the physical resource needs to be considered separately.
5. The relationship between cloud services and virtualized resources
The virtualization layer provides the cloud computing platform application layer with virtualized resources that meet its operating performance requirements, but there is still a certain distance from providing cloud services with SLA guarantees. The conditions that cloud services should meet are to meet the cloud service life cycle, provide cloud service usage interfaces, have a service SLA guarantee mechanism, and make reasonable use of virtualized resources while providing services.
The general idea of supporting cloud services through virtualized resources is to install service applications in the system based on virtual machines, and then provide various services through virtual machine network interfaces. However, it is not an optimal solution to provide different types of cloud services through virtual machines. Program. For example, if virtual machines are used to provide storage services, the additional overhead of virtualization technology on physical resources will be too high. Moreover, the way storage services are provided is relatively stable, and the flexibility obtained by using virtual machines does not actually improve service quality.
The storage service in Amazon Web Service (AWS) uses S3 instead of EC2, which shows that the provision of different services in the cloud service architecture should fully consider its demand characteristics; on the other hand, it is necessary to well manage complex structures Composition of cloud services requires a well-designed hierarchical resource model. That is to maintain the relevance of the cloud service itself, and can fully simplify the management operation.
Refer to the existing cloud computing platform system to explain the relationship between cloud services and virtualized resources, as well as related management requirements.
1. Provide different types of cloud services
According to the use of cloud services, it can be divided into computing services, storage services and other auxiliary services. Various types of services beyond this basic classification can be regarded as derivatives or combinations of these three types of services.
For example, Web application services are generally composed of background database storage services, Web applications (computing services) and Web display (computing services), and database storage services are composed of database application services and storage services. If it is necessary to realize the monitoring and authentication of this Web service, the assistance of monitoring service and authentication service is needed.
According to the characteristics of virtualized resources, computing services are provided by computing resources plus network resources, while storage services are provided by storage resources plus network resources. Therefore, computing services are generally provided based on virtual machines at the virtualization layer, and specific computing service functions are provided by customizing virtual machine templates; storage services are generally provided based on network storage at the virtualization layer; platform auxiliary cloud services are specified by the cloud computing platform. The server directly provides the system service interface.
From the perspective of system implementation, if a virtual machine supports multiple computing services, its change reuse cost and development cost will increase. Therefore, a single virtual machine is limited to only support one computing service in the described platform.
2. Cloud service structure and virtualized resource structure
To ensure the cloud service SLA, the cloud computing platform management layer must first ensure the performance indicators of the relevant virtualized resources. Therefore, it is very important for the management layer to understand the relationship between cloud services and virtualized resources.
In the platform, a cloud service may be based on multiple basic services, which means that the cloud service is associated with multiple virtualized resources. In addition, cloud services may also involve storage services, etc. Taking a web service with a single function as an example, the cloud services and virtualized resources involved in it may be quite complex, as shown in the figure below.
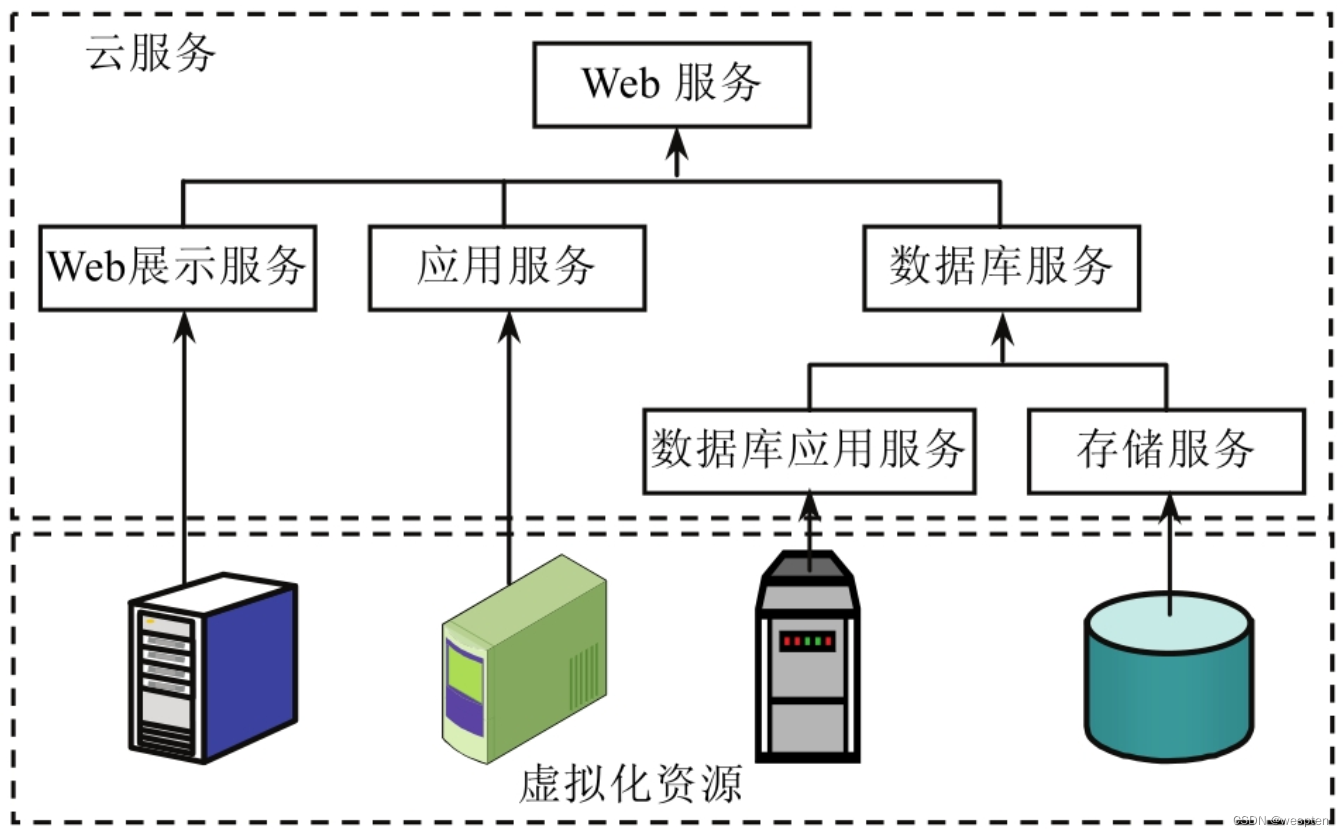
In order to provide this web service, the platform needs to combine and configure a group of virtualized resources according to service requirements. The visible composition shown in the diagram above contains multiple hierarchies consisting of basic computing services plus basic storage services and other ancillary services.
This cloud service structure is universal. In most cloud services and virtualized resource structures, the provision of computing resources is the main load that causes platform energy consumption. Therefore, the management of computing resources is the key management requirement of the virtualization layer. In contrast, the management of storage services and other auxiliary services (such as accounting and authentication, etc.) is relatively simple.
1) Cloud service structure
The composition relationship of cloud services can refer to the simple object access protocol (Simple Object Access Protocol, SOAP) architecture, and reflect the different call processes between a group of cloud services by means of a similar composition service model expression. In the hierarchical relationship of cloud services, there are relationships such as sequential invocation, parallel invocation, and cyclic invocation of services.
2) Virtualization resource structure
The virtualization resource structure has the following two meanings.
- Virtualized resources form a resource network structure based on the virtual network topology at the virtualization layer, and the management system can partition resources according to the virtual network and control management operations such as access rights and load balancing.
- The association of virtualized resources based on the mutual invocation relationship between cloud service applications they support. Taking virtualized computing resources as an example, an application may use multiple virtual machines as its computing service support. According to the combined use of these computing services by this application, corresponding logical structures are generated between these virtual machines, and the network communication between virtualized resources in the same logical structure will be significantly higher than that of independent virtualized resources during service operation. node.
Unifying the resource structure of the two levels can maximize the communication performance of the platform, so the management layer obtains the structure description of the two levels at the same time, and implements effective adjustment management is a necessary condition for optimizing the application performance of the platform.
Imagine an application scenario, that is, the cloud computing platform receives a request to publish cloud service application A, and the SLA requirement description about A is sent together with the request message. The platform management layer first analyzes the basic services required by A and their minimum performance indicators according to the service structure and SLA description, and then searches the available atomic services in the platform service resource pool according to the analysis results and deploys the virtual services used by these services through management operations. resources, such as virtual machines and network storage. Publish virtualized resources on the virtualization layer, optimize resource distribution and structural relationship, and finally the platform returns the user interface of the released cloud service application A.
As shown in the figure below, structure A includes five basic services of cloud services A1 to A5.
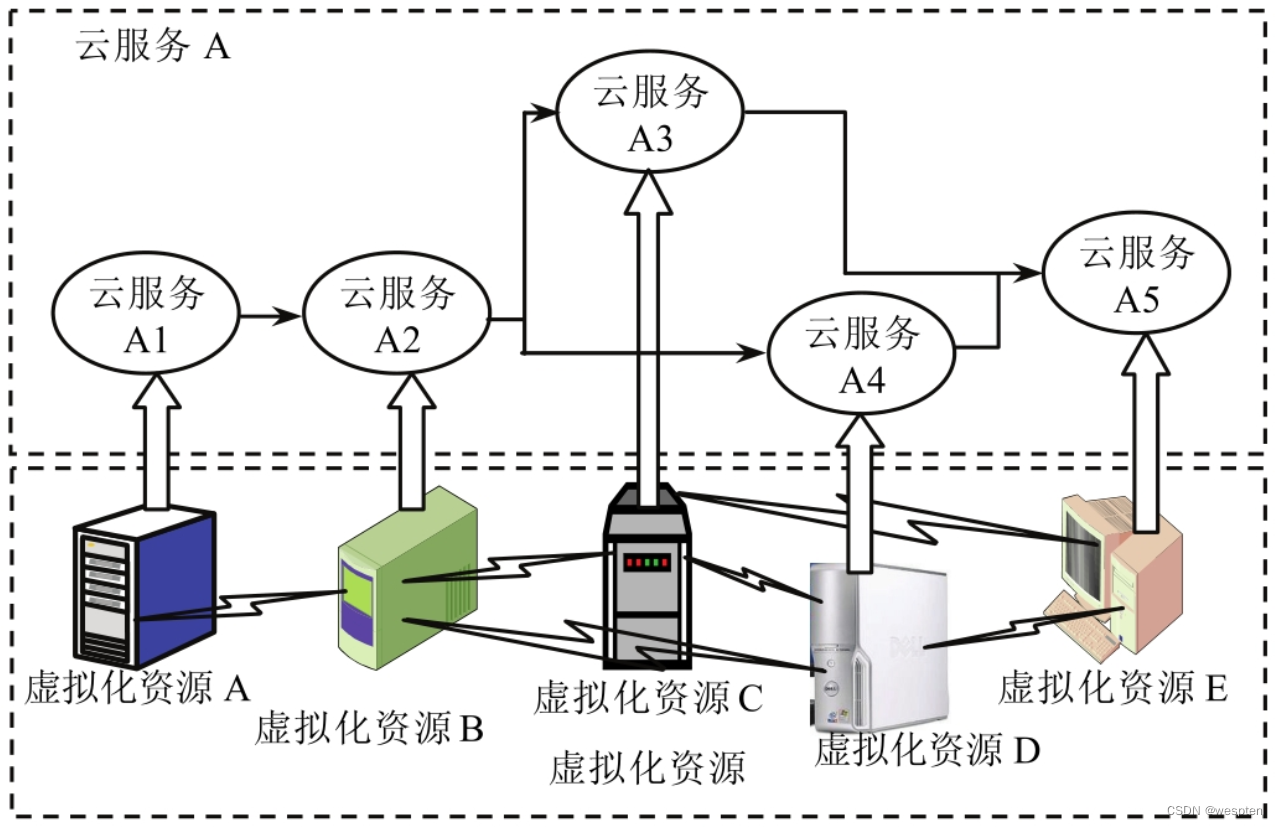
When deploying resources, the platform needs to allocate virtualized resources according to the performance requirements of basic services. In this example, they are virtualized resources A~E, and each virtualized resource supports the operation of one cloud service. At the same time, the platform also configures the virtual network between virtualized resources according to the call relationship between basic cloud services, so as to reduce the transmission cost between virtualized resources that require data transmission.
2. Virtual resource platform
1. Functions of the virtual resource platform
Platform management of virtualized resources is the process of representing computer resources in a way that both users and applications can easily benefit from, rather than in a proprietary way based on the implementation, geographic location, or physical packaging of those resources. In other words, it provides a logical rather than a physical view of data, computing power, storage resources, and other resources.
Resources provide certain functions, which can receive input and provide output based on standard interfaces. Resources can also be hardware, such as servers, disks, networks, and instruments. Or software, such as web services.
Consumers access resources through standard interfaces supported by virtual resources. Using standard interfaces can minimize consumer losses when IT infrastructure changes. The infrastructure of cloud computing enables virtualized computing resources, storage resources, and network resources to be used and managed by users through the network in the form of infrastructure, that is, services.
Although the infrastructure of different cloud providers differs in the services they provide, as a service that provides underlying basic resources, this layer generally has the following basic functions.
1. Resource abstraction
When building infrastructure, the first thing to face is large-scale hardware resources, such as servers and storage devices connected to each other through the network. In order to implement high-level resource management logic, resources must be abstracted, that is, hardware resources must be virtualized.
On the one hand, the virtualization process needs to shield the differences of hardware products, and on the other hand, it needs to provide a unified management logic and interface for each hardware resource.
It is worth noting that depending on the logic implemented by the infrastructure, different virtualization methods of the same type of resources may have very different methods; in addition, according to the needs of business logic and infrastructure service interfaces, the abstraction of infrastructure resources often has multiple levels , resource abstraction is the basis for building infrastructure.
2. Resource monitoring
Resource monitoring is a key task to ensure the high efficiency of cloud computing infrastructure and a prerequisite for load management. Load management cannot be done without effectively monitoring resources. Infrastructure monitors different types of resources in different ways. For CPU, its usage rate is usually monitored; for memory and storage, in addition to monitoring the usage rate, read and write operations are also monitored as needed; for the network, its real-time input and output need to be monitored , and the routing status.
Infrastructure first needs to establish a resource monitoring model based on the abstract model of resources to describe the content and attributes of resource monitoring; at the same time, resource monitoring also has different granularity and abstraction levels. A typical scenario is a specific solution Resource monitoring is carried out in the overall scheme. A solution often consists of multiple virtual resources, and the overall monitoring result is the integration of the monitoring results of each part of the solution.
By analyzing the results, users can more intuitively monitor resource usage and its impact on performance, and take necessary actions to adjust solutions.
3. Load management
In a large-scale resource cluster environment such as cloud computing infrastructure, the load of all nodes is not uniform at any time. If the resource utilization of the nodes is reasonable, even if their load is uneven to some extent, it will not cause serious problems.
However, when the resource utilization rate of too many nodes is too low or the load difference between nodes is too large, it will cause a series of outstanding problems. On the one hand, if the load of too many nodes is low, it will cause waste of resources. The infrastructure needs to provide an automated load balancing mechanism to consolidate loads, improve resource utilization and shut down idle resources after load consolidation. On the other hand, if the difference in resource utilization is too large, the load on some nodes will be too high, and the performance of upper-layer services will be affected. And the load of other nodes is too low, resources are not fully utilized. At this time, the automatic load balancing mechanism of the infrastructure is required to transfer the load, that is, from the node with high load to the node with low load, so that all resources tend to balance in terms of overall load and overall utilization.
4. Data management
The integrity, reliability and manageability of data in the cloud computing environment are the basic requirements for infrastructure data management. Since the infrastructure consists of large-scale server clusters in data centers, or even server clusters in several different data centers, data integrity, reliability, and manageability are extremely challenging.
Integrity requires that the state of the data is determined at any time, and the data can be restored to a consistent state under normal and abnormal conditions through operations, so the integrity requires that the data can be correct at any time Read and synchronize appropriately on write operations.
Reliability requires minimizing the possibility of data damage and loss, for which redundant backups of data are usually required. Manageability requires data to be managed by administrators and upper-level service providers in a coarse-grained and logically simple manner. For this reason, it usually requires sufficient and reliable automated management processes for data management within the infrastructure layer. For the specific cloud infrastructure layer, there are other data management requirements, such as data reading performance or data processing scale requirements, and how to store massive data in the cloud computing environment.
5. Resource deployment
Resource deployment refers to the process of delivering resources to upper-layer applications through automated deployment processes, that is, the process of making infrastructure services available. In the initial stage of application environment construction, when all virtualized hardware resource environments are ready, resource deployment in the initialization process is required; in addition, resource deployment is often performed twice or even multiple times during the application running process. In order to meet the needs of upper-layer services for resources in the infrastructure, that is, dynamic deployment during operation.
There are many application scenarios for dynamic deployment. A typical scenario is to achieve dynamic scalability of infrastructure, that is, cloud applications can be adjusted according to specific user needs and changes in service conditions within an extreme period of time. When the workload of user services is too high, users can easily expand their own service instances from several to thousands, and automatically obtain the required resources.
Usually, this kind of scaling operation must not only be completed in a very short time, but also ensure that the complexity of the operation will not increase with the increase in scale; another typical scenario is fault recovery and hardware maintenance. In cloud computing, thousands of In a large-scale distributed system consisting of tens of thousands of servers, hardware failure is inevitable. Applications also need to be temporarily removed during hardware maintenance. The infrastructure needs to be able to replicate the data and operating environment of the server and establish the same environment on another node through dynamic resource deployment, so as to ensure rapid recovery of services from failures.
6. Security management
The goal of security management is to ensure that infrastructure resources are legally accessed and used. Cloud computing needs to provide a reliable security protection mechanism to ensure data security in the cloud, and provide a security review mechanism to ensure that operations on cloud data are authorized and available. being tracked.
The cloud is a more open environment where user programs can be executed more easily. This means that malicious code and even virus programs can destroy other normal programs from within the cloud. Because programs are quite different from traditional programs in the way they run and use resources, how to better control code behavior or identify malicious code and virus code in a cloud computing environment has become a new challenge for administrators; at the same time , in the cloud computing environment, data is stored in the cloud, how to prevent cloud computing managers from leaking data through security policies is also a problem that needs to be considered emphatically.
7. Billing Management
Cloud computing is also a pay-as-you-go billing model. By monitoring the usage of the upper layer, it is possible to calculate the storage, network and memory resources consumed by the application within a certain period of time, and charge users based on these calculation results. During the specific implementation, the cloud computing provider can adopt some appropriate alternative methods to ensure the smooth completion of the user's business and reduce the fee that the user needs to pay.
The primary function of a virtualized resource platform is to integrate a large number and various types of computer resources, such as storage and network resources. And these resources need to be effectively monitored to achieve load balancing. To this end, the virtualized resource platform needs to have good heterogeneity and be able to effectively integrate different hardware and software resources; in addition, the virtualized resource platform has the function of dynamic resource deployment. That is, two or even multiple resource deployments can be performed during the running of the application. In this way, resources can be used on demand, and resource management and support tools transparent to physical facilities can be provided.
2. Virtual resource platform
In order to break through the key technologies of computing resource virtualization, software as a service, and resource flexible scheduling, it is necessary to build a virtual resource platform layer to provide users with services such as computing resources, virtual machine resources, virtual storage, services, and data resource space, and complete the support " Software as a Service, Location Transparency, and Interaction Pervasiveness" is a networked operating system virtualization platform for new network application models.
1. General framework
A virtualized resource platform (infrastructure layer) can aggregate and manage resources from one or more clusters, a cluster being a group of machines connected to the same LAN. There can be one or more virtual machine management node instances in a cluster, and each instance manages the startup, termination and restart of virtual instances. According to the number of clusters, the virtualization platform layer can be divided into two architectures: single-cluster and multi-cluster.
The single-cluster architecture is shown in the following figure:
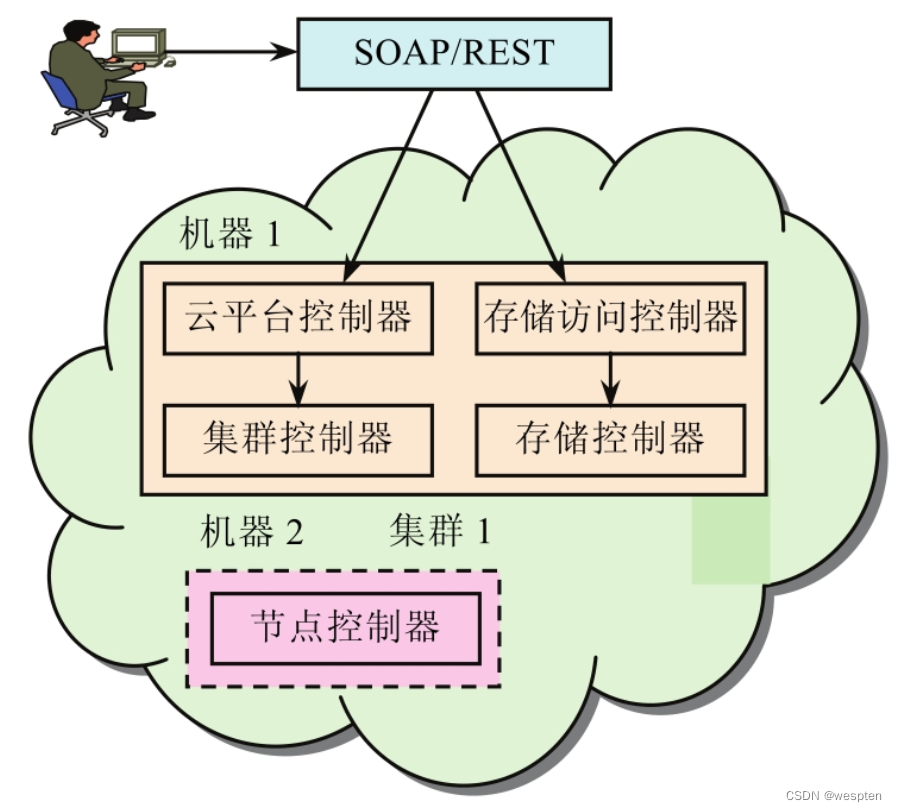
It contains at least two machines, one machine runs cloud platform controller (CLoud Controller, CLC), cluster controller (Cluster Controller, CC), storage access controller (Walrus) and storage controller (Storage Controller, SC), etc. 4 front-end components; the other runs the Node Controller (NC), this configuration is mainly suitable for the purpose of experimentation and quick configuration. The installation process can be simplified by combining the front-end components into a single machine, but the performance of this machine needs to be very robust.
The multi-cluster architecture is shown in the following figure:
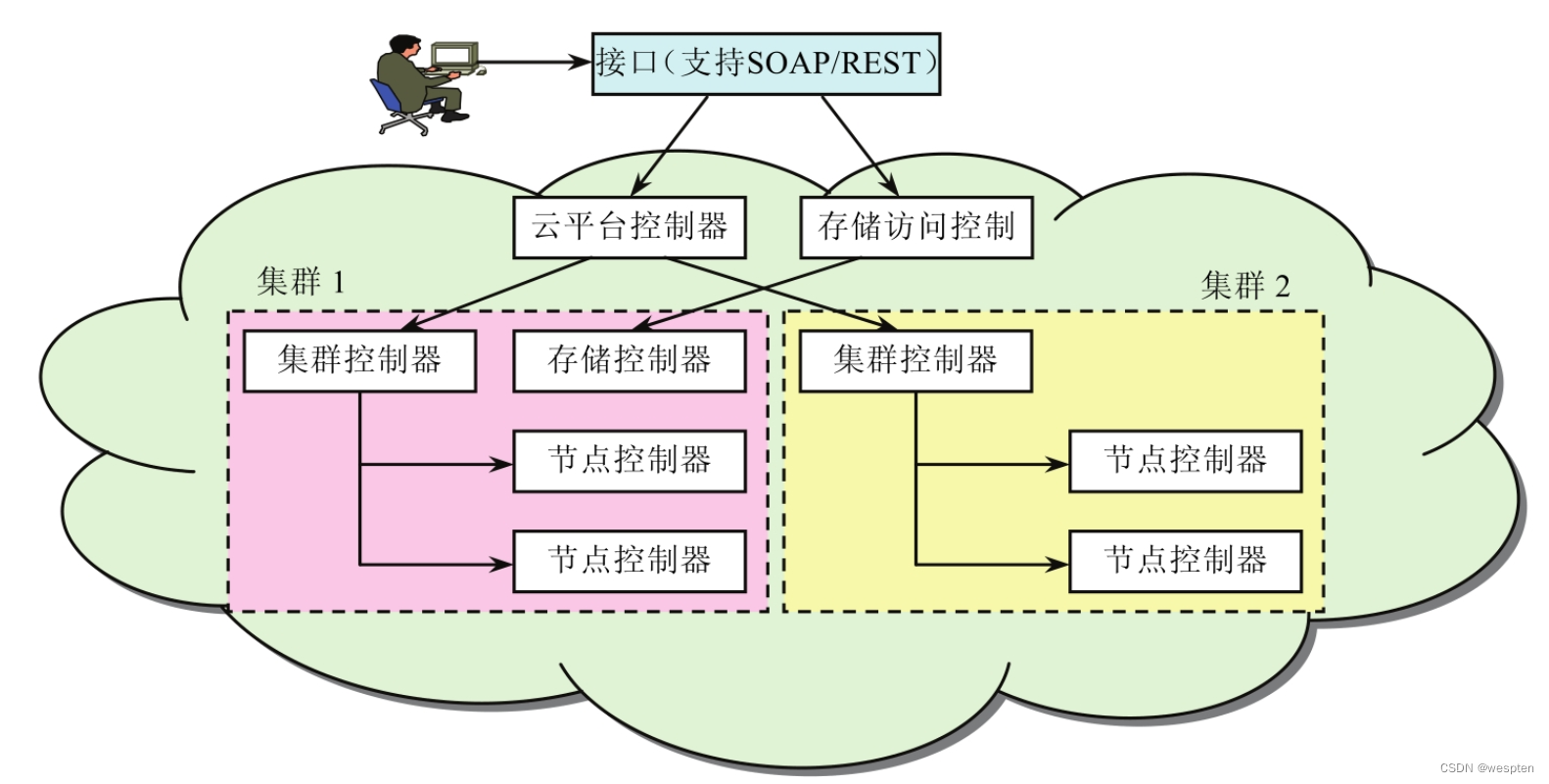
Here the individual components (CLC, SC, Walrus, CC and NC) can be placed in separate machines. This is an ideal way to configure the platform layer if you need to use it to perform significant tasks. A multi-cluster installation can also significantly improve performance by choosing the right machine for the type of controller it is running on. For example, you can choose a machine with an ultra-fast CPU to run CLC or choose a machine with large storage space to install Walrus. Multi-cluster The result is increased availability, and distribution of load and resources across the cluster. The concept of a cluster is similar to the concept of availability zones within Amazon EC2, where resources can be allocated across multiple availability zones so that a failure in one zone does not affect the entire application.
2. Components
Specifically, the virtualization platform layer consists of five main components. That is, CLC, CC, Walrus, SC and NC, they cooperate with each other to provide the required virtualization services, and use SOAP messaging with Work Station (Work Station, WS)-Security to communicate with each other securely.
1)CLC
CLC is the main controller component of the virtualization resource platform, responsible for managing the entire system, and is the main entrance for all users and administrators to enter the virtualization resource platform. All clients communicate with the CLC only through APIs based on SOAP or REpresentational State Transfer (REST), and the CLC is responsible for passing requests to the correct components and sending responses from those components back to the client, which is The external window of the virtual resource platform.
Every virtualized resource platform installation includes a single CLC, which acts as the central nervous system of the system, the user's visible entry point and component for making global decisions. It is responsible for processing requests initiated by users or management requests issued by system administrators, making high-level virtual machine instance scheduling decisions, and handling service level agreements and maintaining system metadata related to users. The CLC consists of a set of services that handle user requests, authenticate and maintain the system, user metadata (virtual machine images, key pairs, etc.), and manage and monitor the operation of virtual machine instances. These services are configured and managed by the Enterprise Service Bus (ESB), through which operations such as service publishing can be performed. The design of the virtualization resource platform emphasizes transparency and simplicity to facilitate experimentation and expansion of the platform.
In order to achieve this granular level of expansion, the components of CLC include virtual machine scheduler, SLA engine, user interface and management interface, etc. They are modular and independent components that provide well-defined interfaces to the outside world, and ESB is responsible for controlling and managing the interaction and organic cooperation between them. CLC can work like Amazon's EC2 by using web services and Amazon's EC2 query interface to interoperate with EC2's client tools.
2)CC
The CC of the virtualization resource platform is responsible for managing the entire virtual instance network, and the request is sent to the CC through the interface based on SOAP or REST. CC maintains all information about NCs running in the system, is responsible for controlling the life cycle of these instances, and routes requests to start virtual instances to NCs with available resources.
A typical CC runs on the head node or server of the cluster, both of which have access to private or public networks. One CC can manage multiple node controllers, and is responsible for collecting node status information from the node controller it belongs to.
According to the resource status information of these nodes, it schedules the requests of the incoming virtual machine instances to be executed on each node controller, and is responsible for managing the configuration of public and private instance networks. Like NC, CC interface is also described by Web Services Description Language (Web Services Description Language, WSDL) document, these operations include runInstances, describeInstances, terminateInatances and describeResources. Describing and terminating an instance is passed directly to the relevant node controller.
When CC receives a runInstances request, it executes a simple scheduling task. The task queries each node controller by calling describeResource, and selects the first NC with enough idle resources to execute the instance running request. CC also implements the describeResources operation, which takes the resources occupied by an instance as input and returns the number of instances that can be executed in its NC at the same time.
3)NC
The NC control host operating system and corresponding virtualization platform hypervisor (Xen or KVM) must run an instance of NC in each machine hosting the actual virtual instance (instantiated upon request from CC).
NC is responsible for managing a physical node, which is a component running on the physical resource hosted by the virtual machine, responsible for starting, checking, shutting down and clearing the virtual machine instance, etc. A typical virtualization platform has multiple NCs installed, but only one NC needs to run on a machine, because one NC can manage multiple virtual machine instances running on the node.
NC interface is described by WSDL document, which defines the instance data structure and instance control operations supported by NC, these operations include runInstance, describeInstance, terminateInatance, describeResource and startNetwork. The running, describing, and terminating operations of the instance perform the minimal configuration of the system and invoke the current hypervisor to control and monitor the running instance.
The describeRescource operation returns the characteristics of the current physical resource to the caller, including information such as processor resources, memory and disk capacity; the StartNetwork operation is used to set and configure virtual Ethernet,
4)Walrus
This controller component manages the user's access to the storage service in the virtualization resource platform, and the request is passed to the storage access controller through the interface based on SOAP or REST.
5)SC
SC implements Amazon's S3 interface and is used in conjunction with Walrus to store and access virtual machine images, kernel images, RAM disk images, and user data. Where VM images can be public or private and are initially stored in a compressed and encrypted format, these images are only decrypted when a node needs to start a new instance and requests access to the image.
3. Virtual logical architecture of information resource cloud
After expanding the specific attributes of information resources in combination with the cloud environment, the virtualization technology is introduced into the abstract layer model of resource virtualization to obtain a logical architecture for realizing cloud virtualization of information resources, as shown in the figure below.
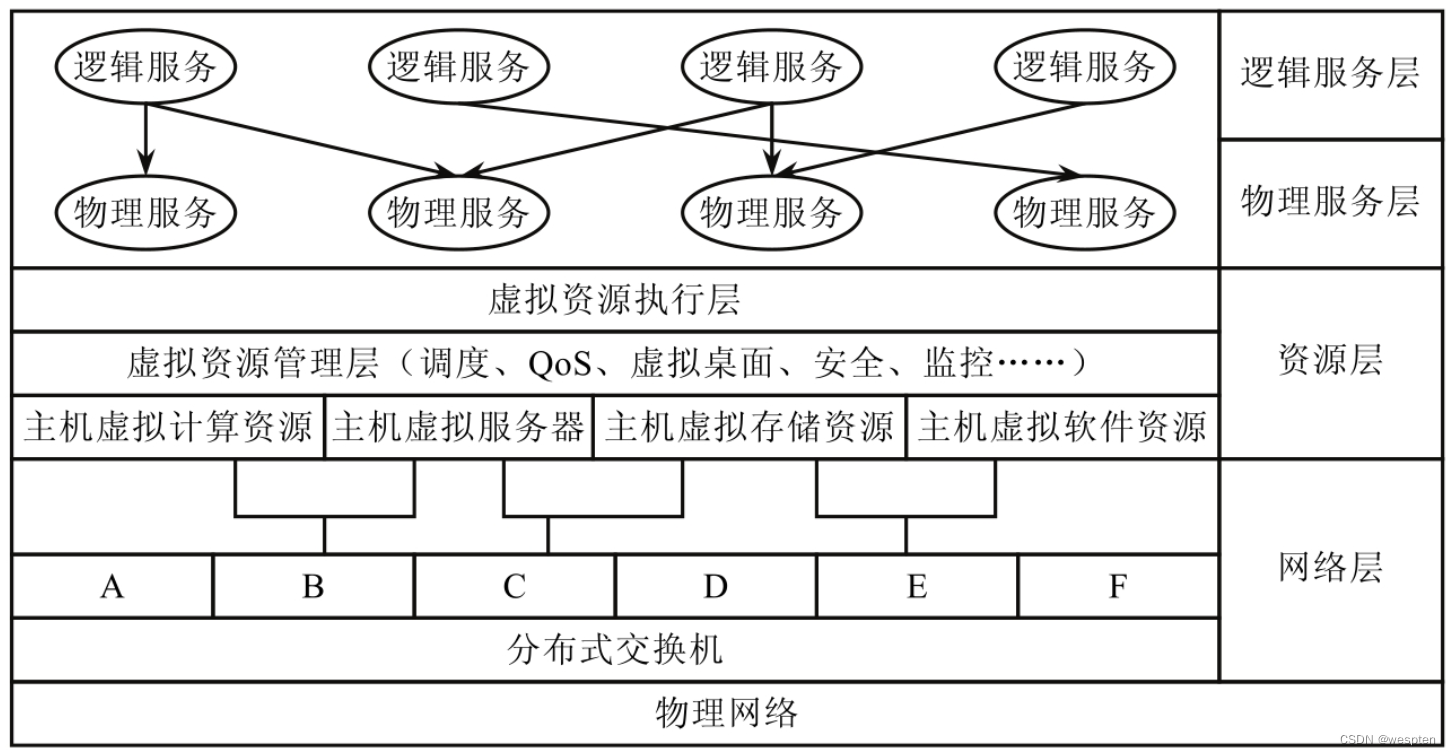
It realizes virtualization from the perspective of user utilization, and can use information resources dynamically, transparently and at low cost.
1. Network layer
The network layer is the most basic layer to realize the virtualization of information resources. The physical host is not only an important carrier of information resources, but also an important part of the information resource cloud. Currently, it is mainly realized through the vNetwork network element in Vmware vSphere.
This layer utilizes distributed switches among virtual machines in a specified physical server to integrate them as a single virtual switch, so that virtual machines can ensure that their network configurations remain consistent when migrating across hosts.
One end of the switch is connected to the port group, and the other end is an uplink, which is connected to the physical Ethernet adapter in the server where the virtual machine resides. A virtual switch can link its uplinks to multiple physical Ethernet adapters to enable NIC teaming. With NIC teaming, two or more physical adapters can share the traffic load or provide passive failover in the event of a physical adapter hardware or network failure. All virtual machines associated with the same port group belong to different physical servers and are on the same network within the virtual environment.
From the perspective of the virtual machine, the communication process in the guest operating system is the same as that of the real physical device; from the outside of the virtual machine, the vNIC (virtual network interface card) has an independent MAC address and one or more IP addresses that comply with the standard Ethernet network protocol. It unifies discrete hardware resources to create a shared dynamic platform with built-in availability, security, and scalability for applications.
Network virtualization can enable virtual machines deployed in physical hosts in the data center to be interconnected in the same way as in the physical environment, regardless of which network they belong to. Thus, the boundary between different networks is eliminated, and the requirement of transparency is met.
2. Resource layer
Network virtualization enables hosts to be used on demand regardless of restrictive factors such as geography and attributes. On this basis, virtualization of storage and servers is required to virtualize the data stored in them.
1) Virtual storage resources
Virtual storage resources can transform the storage medium in the traditional environment into the mode required in the cloud environment. At present, the cloud storage system usually divides the virtual storage into the following three layers.
- Physical device layer: It is mainly used to allocate and manage resources at the data block level, and use the underlying physical device to create a continuous logical address space, that is, a storage pool. According to the attributes of physical devices and user requirements, a storage pool can have multiple data attributes, such as read and write characteristics, performance weight, and reliability level.
- Storage node layer: Allocate and manage resources among multiple storage pools inside the storage node, and integrate one or more storage pools allocated on demand into a unified virtual storage pool within the scope of the storage node. This layer is implemented inside the storage node by the storage node virtual module, which manages the storage devices allocated on demand from the bottom and supports the virtualization layer of the storage area network on the top.
- Storage area network layer: allocate and manage resources between storage nodes, and centrally manage storage pools on all storage devices to form a unified virtual storage pool. This layer is implemented by the virtual storage management module on the virtual storage management server, and manages the resource allocation of the virtual storage system in an out-of-band virtualization manner, and provides services such as address mapping and query for virtual disk management.
A two-layer address space mapping mechanism is introduced in the virtualized storage to construct two logical parts and a mapping component, in which the global extended address space is used to manage all remote free memory mapped to the local extended address space, and the serial extended address space is used to expand local physical address space.
Finally, the mapping component completes the mapping from the global extended address space to the logical extended address space according to certain rules, so as to construct a memory resource abstraction that crosses the boundary of physical server resources. In addition, using balloon drive, page swapping, content-based page sharing and page patching technologies, etc., to dynamically adjust the memory allocation size of virtual machines by releasing free memory and using remote memory, and using remote memory as an additional storage level To mediate memory allocation can achieve maximum optimization of memory resource allocation.
Each piece of data in cloud storage has several backups stored in different nodes. When a node in the cloud fails, the monitor sends a signal to quickly migrate the virtual machine. Nodes can be added and removed dynamically, which is more scalable than the original storage method.
The key to realizing information resource virtualization is storage virtualization. Hadoop distributed file system, vSphere high-performance cluster file system and Google file system are all distributed file systems applicable to cloud environment, which have high fault tolerance and can be deployed on On low-cost hardware equipment.
2) Virtual server
There are two approaches to server virtualization, namely software and hardware virtualization. Properly configured running servers allow multiple virtual machines, servers, or desktops to run on the same physical server, each without requiring its own power supply, generating its own heat, or requiring space. But these virtual machines can all contribute the same service and run in one physical machine at the same time, so that the utilization rate of each data center is greatly improved and a lot of space is saved.
The use of information resources relies on servers, and server virtualization can simplify management and improve efficiency by allocating server resources to workloads that need them most anytime and anywhere by prioritizing resources. This reduces the resources reserved for a single workload peak and plays an important role in resource scheduling.
3) Virtual data center
The result of information resource virtualization is like a huge data center, which can continuously output content on demand, which can also be called "data virtualization" in a narrow sense.
On the basis of storage and server virtualization, cloud computing focuses on providing packaged general services and resources to users. The processing of heterogeneous resources does not rely on middleware, but does different processing for different resources. When responding to the program, it allocates a CPU, memory and software instead of heterogeneous resources. This facilitates management and saves costs. Therefore, the resources in the virtual data center can be grouped together with similar attributes according to isomorphic resources, and then integrated through physical-to-logical mapping.
The virtual data center can import data from different data sources into an abstracted service layer, which helps to reduce the need for physical storage systems and provide data for all applications that use data (especially business intelligence systems, analysis systems and transaction system) provides a unified interface.
4) Virtual resource management layer
To achieve on-demand, dynamic and effective provisioning, various virtualization methods must be organized reasonably, and the management layer is responsible for storage management, scheduling monitoring, desktop instantiation, QoS evaluation and security, etc.
After the virtualization of servers, etc., the scale increases, and its migration characteristics make it difficult to visualize the physical location of virtual servers in the network. The management layer can introduce resource view and virtual topology to manage resources. Through the virtual resource view, you can view the resource affiliation information of physical servers, virtual switches, VMs, and network configuration capabilities; virtual topology data aggregates all nodes into physical server nodes , and can reflect the virtual world inside the physical server.
The monitor is responsible for viewing the availability and resource usage rights of the virtual machine and monitoring the resource storage operation status after receiving the request. When it is found that the storage node has failed, the control node can transfer the workload to the normal storage node to complete.
Desktop instantiation is a virtual desktop, which can integrate the display windows of all software instances to truly present a virtualized experience for users. It enables the fusion of local and virtual desktops through the process of requesting, authenticating, connecting, enabling list, applying, and disconnecting. End-user devices become lightweight computers that only handle keyboard, mouse, monitor, and locally attached scanners and printers, allowing them to truly be used anywhere. Compared with the traditional "fat desktop", its advantages are firstly lower cost, and improved manageability, security, flexibility and resettability; secondly, only the required application windows are pushed to customers; thirdly, dynamic allocation Resources, high performance and load balancing; the fourth is to have a protocol that controls the interaction between the client and the server.
Security management performs the tasks of third-party authentication, authorization, and verification of user identities, and can also dynamically detect changes in user loyalty through file information to protect sensitive data.
5) Virtual resource execution layer
The core function of this layer is to support the execution of virtual resource tasks.
Resource scheduling is an important link to improve resource utilization efficiency in a cloud environment. For each service, real-time request volume is predicted based on load models, historical data analysis, and external event signs to meet resource requirements at a given point in time. Resource scheduling generally includes four steps, namely resource request, resource detection, resource selection and resource monitoring.
Firstly, user needs and resources are detected, and resources are evaluated according to the detected resource indicators and the predefined resource scheduling strategy. That is, select the optimal resource from the list of candidate resources, and perform corresponding actions according to the strategy and evaluation results. Then start the virtual machine to a suitable machine, so that the resources in the resource pool can be used reasonably. The scheduling migration strategy can reasonably shut down idle servers or start multiple virtual machines to balance the load when completing tasks with relatively heavy loads according to user needs.
Resources in the virtual execution environment are not aware of the existence of the virtualization layer, but will run as in the traditional computing environment, providing an independent environment for virtual resources. For software resources, virtual software can be dynamically deployed as long as part of it is not even installed in the system.
3. Physical service layer
The physical service layer mainly solves the problem of unified standardization of resources and unified call interface. Resource service encapsulation is a method of virtualization.
The first step is to describe the resource, that is, to select the corresponding resource description template. And fill in the corresponding resource attribute information as required to form a resource attribute document in XML format; the second is to package and form resource implementation classes as needed; the third is to deploy resources, that is, call the interface of the resource adapter to join the resource adapter. The resource adapter will automatically generate resources and obtain information about resource implementation classes. In this way, the service-oriented encapsulation of resources is completed, and a unified call interface is presented to the outside world.
There are three types of resource-to-service mapping. One is one-to-one. The functions that resources can complete are relatively simple, and they are directly encapsulated in the form of services. The second is many-to-one. Multiple combined resources are expressed as a single logical representation that provides a single interface. form; the third is one-to-many, for relatively powerful resources. Each function is independent of each other, and can be packaged into services that can complete different functions according to the functions.
4. Logical service layer
The logical service layer abstracts service functions from specific services and describes them in the form of logical services, thus forming a logical service layer to meet dynamically changing requirements or specific business needs.
The description of physical services and logical services is mainly described from two aspects: functional and non-functional attributes. The functional attribute description is the internal processing logic of the service, describing what the service can do; the non-functional attribute is also called "service quality" (Qos) , describing the external performance of the service when in use, such as performance, price, reliability, availability, and security.
There are two types of mapping from physical services to the logical layer. One is multiple physical resources with the same function and different non-functional attribute values. These physical services can complete the same business function and are the same kind of service.
Virtualize it into a logical service, and select the appropriate physical resource to use according to the specific non-functional attribute requirements during actual operation. The second is multiple physical resources with the same function and the same non-functional attributes. In order to increase fault tolerance or solve problems such as load balancing, multiple copies of a physical service are deployed on multiple machines. When invoking a physical service, one can be dynamically selected according to the current service operation status.
The above model basically covers the virtualization implementation methods of hardware, software, and data. The layers from top to bottom are not clearly defined and function independently, but complement each other and penetrate each other.
3. Resource virtualization design and implementation
1. How cloud computing realizes the virtualization of resources
According to the service model definition of Infrastructure as a Service (IaaS), service providers need to provide tenants with pay-as-you-go standardized elastic resource services, including elastic computing, elastic storage, elastic broadband, and virtual machines.
Cloud computing converts all hardware resources in the VDC provider's physical computer room into a huge resource pool through virtualization and standardization, and all virtual facilities in it are products that the provider can provide services, and are packaged in a standardized IaaS manner. Standard templates are rented out to users. Tenants can apply online and on-demand for the resources they need, and obtain access and use rights to the resources they apply for in a short period of time.
The following figure shows the hierarchical architecture of cloud computing to realize resource virtualization:
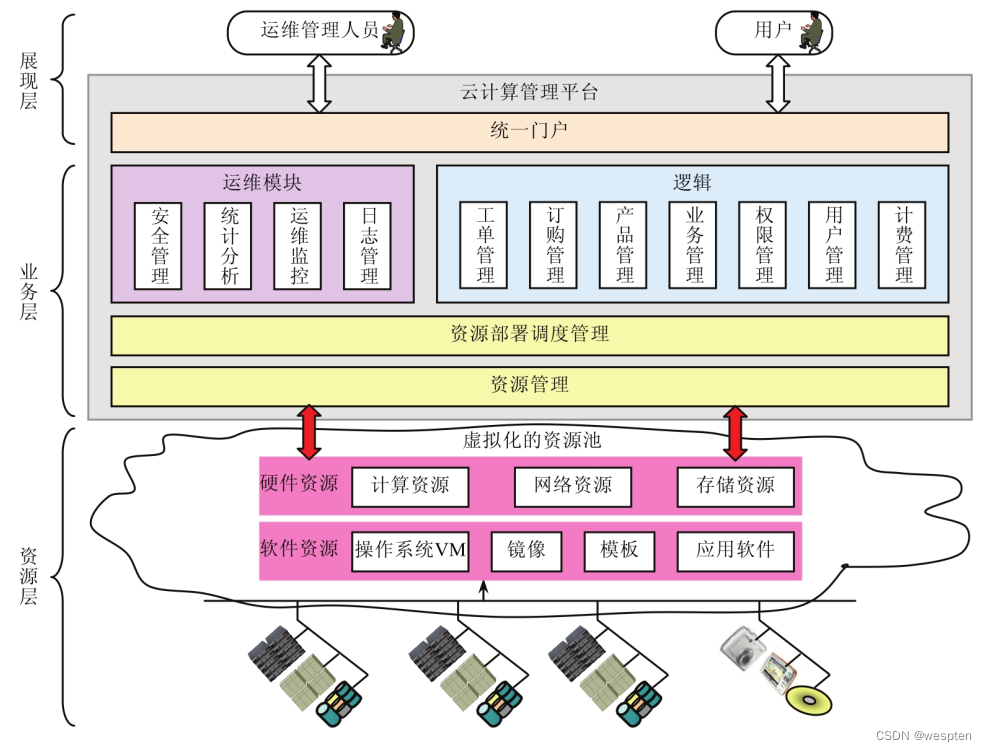
Administrators and ordinary users log in to the cloud computing management platform through the unified portal, and the services provided by the cloud computing management platform that each user can use according to different authorization levels are also different. What VDC tenants care about is how to apply for required resources on the cloud management platform, and view resource usage status, bills, and historical records.
At the resource level, the cloud management platform implements virtualization of hardware resources through a virtual machine monitor (VMM), including CPU, memory, input/output (I/O) and network virtualization. Virtualized hardware resources are collected by different hypervisors and packaged into virtual machines (VMs) according to the instructions of the business layer.
2. Static and dynamic allocation algorithms for virtual resources
The virtualized operating environment in the cloud computing platform adopts an innovative computing model to enable users to obtain almost unlimited computing power through the Internet at any time, so that users can freely use computing and services and charge according to volume. The scalability and flexibility of virtualization technology greatly help the virtualized operating environment to improve resource utilization, and simplify the management and maintenance of resources and services.
By integrating the physical resources of tens of thousands of servers to build a resource pool, it is finally provided to users on demand in the form of services. And it provides the virtual running environment of mainstream operating systems commonly used in Linux and Windows series, so that users can use the virtual machine in the virtual and running environment just like using a local physical machine. For various topologies and access control mechanisms, dynamic resource allocation of virtual networks requires persistent virtual network monitoring and dynamic update of physical node and link capacity.
The following figure shows the dynamic and static resource allocation algorithm:
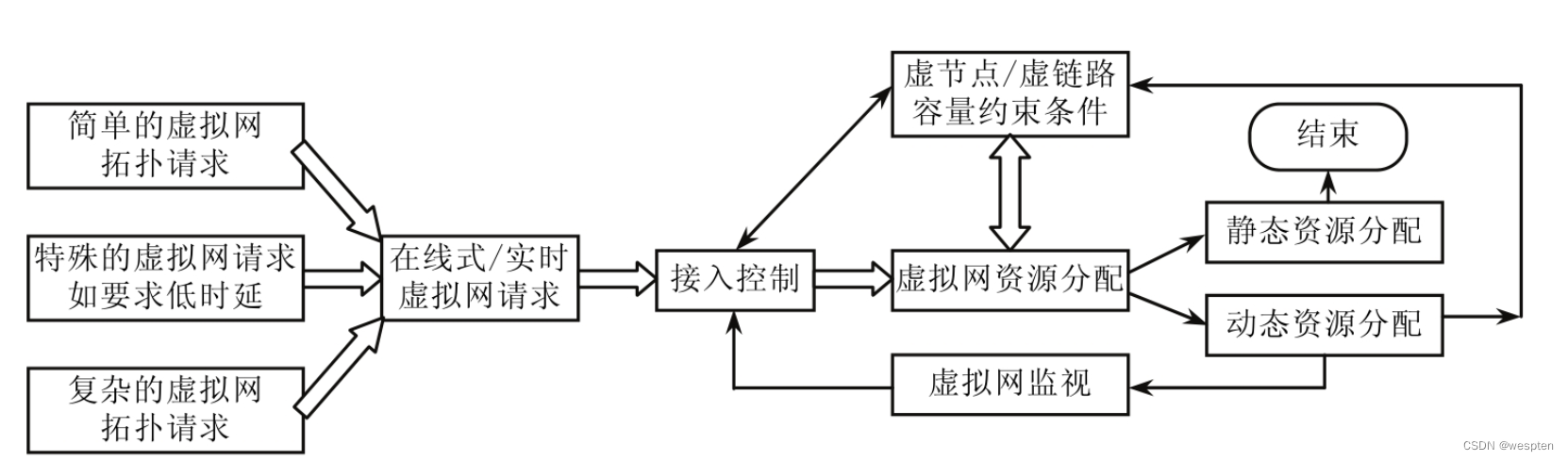
1. Static algorithm
Static virtual network mapping algorithms can be divided into the following two categories.
1) Two-stage virtual network mapping algorithm
The two-stage virtual network mapping algorithm separates node mapping and link mapping and executes them sequentially. Even if the offline virtual network mapping problem can be transformed into a demultiplexer problem, it is still an NP-hard problem. In the case of completed node mapping, virtual link mapping in the case of inseparable flows is also an NP-hard problem.
Therefore, the existing virtual network mapping algorithms all use greedy node mapping combined with a heuristic-based link mapping scheme to map the virtual network. Separate mapping of nodes and links can simplify the processing of the problem.
2) Virtual network mapping algorithm for one-step solution
The one-step virtual network mapping algorithm maps virtual network nodes and links at the same time to obtain the optimal mapping effect. Several common one-step virtual network mapping algorithms are as follows.
- Distributed Cooperative Segmentation Algorithm
In order to reduce the complexity and delay of the virtual network mapping algorithm, the distributed cooperative virtual network mapping algorithm divides the virtual network into several star topologies, that is, the hub-and-spoke topology. The algorithm uses a multi-agent-based scheme to simultaneously map the nodes and links of the star topology. The node mapping scheme also uses a greedy method to allocate the physical nodes with the largest available resources into hub nodes, and uses the shortest path algorithm to select connecting hub nodes. and the physical path of the spoke node. The distributed mapping method can obtain the advantages of no single point of failure and parallel processing of virtual network requests, but compared with the centralized mapping algorithm, its performance in terms of response time and global optimal resource allocation is poor.
Algorithms that aim to simultaneously map nodes and links can get stuck in multiple local optima if they need to recompute costs when network conditions change.
- Mapping algorithm based on business constraints
In order to narrow the search space, the VN topology is restricted to the back-bone Star structure. Some of these nodes are back-bone nodes and others are access nodes. The back-bone node is the center of the star topology, and access nodes are connected to the back-bone nodes.
In order to further reduce the complexity of the problem, the back-bone nodes are limited to a fully interconnected structure, that is, the entire virtual network topology is a complete graph composed of stars and rings. This virtual network mapping algorithm with the optimization goal of minimizing the virtual network mapping cost is only solved for one virtual network request, and the topology generated by the algorithm is not optimal, but the search space is narrowed.
This method transforms the mapping of back-bone nodes into a mixed integer quadratic programming model by limiting the topology of the virtual network, and uses the flow constraints between nodes to find the virtual network mapping scheme with the minimum mapping cost through an iterative method. However, the calculation of the algorithm is complex, and the generality of the virtual network topology design for a specific structure is poor.
- Algorithms that only consider embedded virtual links
The resource allocation of virtual private network (VPN) can be regarded as the earliest and relatively simple virtual network mapping problem. These virtual private network mapping algorithms only consider the bandwidth constraints of virtual links to simplify the virtual network mapping problem.
This simplifies the processing of the path selection phase since the constraints of virtual nodes are ignored. Simulated annealing method can also be used to map virtual nodes, the only restriction on node mapping is assuming that different virtual nodes are mapped to different physical nodes. This algorithm is an exclusive node resource allocation method with low resource utilization.
2. Dynamic algorithm
In the static algorithm, the virtual network mapping does not change with time, while the dynamic algorithm refers to the reallocation of mapped resources during the operation of the virtual network to optimize the use of underlying physical network resources. Static algorithms typically lead to low utilization of physical resources. To solve this problem, dynamic mapping algorithms can be designed. That is to organize scattered resources into whole manageable resources, so as to release the resources of some bottleneck nodes or bottleneck links in the network and ensure the connectivity of the network.
1) Selective virtual network remapping algorithm
Given the rerouting mechanisms of circuit-switched networks, the virtual network map is periodically and selectively reconfigured to optimize overloaded portions of the physical network. However, the virtual network resource redistribution problem is more complicated than the flow rerouting problem. The virtual network resource reconfiguration leads to obvious node/link mapping changes in the physical network.
In order to quantify the cost of virtual network remapping, the virtual network remapping cost is defined as the weighted sum of virtual network, node and link remapping rates. The number of reconfigured virtual networks will affect the stability of the network and computing overhead, so a selective reconfiguration process is used to select virtual networks with higher loads for reconfiguration.
The selective virtual resource reconfiguration algorithm depends on two steps, one is to periodically identify the bottleneck physical nodes or links; the other is to reconfigure and monitor the performance of each virtual network.
2) Topology-aware virtual network remapping algorithm
There are two differences between the mapping algorithm of resource reallocation and the periodic remapping method. One is to quantify the cost of remapping; the other is to trigger the remapping mechanism. The method of quantifying the remapping cost is to calculate the difference of the mapping cost before and after virtual network remapping. The periodic remapping mechanism can keep all virtual network requests in the optimal state at all times, but it will cause more virtual nodes and virtual links to be remapped.
The network overhead and computing overhead are increased, so the algorithm only adjusts the virtual network remapping when the virtual network request cannot be mapped. In addition, not all bottleneck nodes and bottleneck links are remapped, but only virtual network requests with lower priority on bottleneck nodes and bottleneck links are remapped to reduce resource usage pressure. The algorithm designs the remapping mechanism of nodes and links, which improves the acceptance ratio of virtual network mapping. However, virtual links associated with the virtual nodes also need to be migrated while migrating the virtual nodes, so the overall calculation cost is relatively large.
3) DaVinei arithmetic
The DaVinei algorithm is a dynamic adaptive virtual network mapping algorithm proposed for the customized Internet. This algorithm periodically redistributes the bandwidth between virtual links sharing the same physical link among multiple virtual networks.
In addition, each virtual network also runs its own distributed protocol and maximizes its own objective function. The architecture supports multipath, which allows multiple physical paths to reach other nodes, thus creating packet reordering issues. Another defect of this architecture is that the links in the physical network need to know the performance objective functions of all virtual networks in advance, which is difficult to achieve in reality, and this algorithm does not consider the allocation of virtual network nodes.
4) QoSMap mechanism
The QoSMap mechanism strictly considers the QoS requirements and topology elasticity of the virtual network when establishing a virtual network, and meets the QoS requirements of the virtual network by selecting high-quality guaranteed physical links.
In addition, the mechanism also builds backup one-hop routes through intermediate nodes to provide elastic guarantees for virtual network link mapping. When considering allocating resources for a virtual network that needs to strictly guarantee message transmission delay and packet loss rate, the experimental results show that this algorithm can obtain better service quality and better elasticity than the virtual network establishment scheme that only considers QoS ensure. However, because the algorithm pre-reserves link bandwidth resources for virtual link protection, the utilization rate of physical network resources is low.
3. Core module design of cloud computing architecture in a virtualized environment
1. Technical Architecture of Cloud Computing
As we all know, on-demand deployment is the core of cloud computing. To solve this problem, it is necessary to solve the dynamic reconfiguration, monitoring and automatic deployment of resources, etc., which in turn need to be based on technologies such as virtualization, high-performance storage, processors and high-speed Internet.
In order to effectively support cloud computing, the architecture of cloud computing must support several key features. First, the system must be autonomous, that is, it needs to be embedded with automation technology to reduce or eliminate manual deployment and management tasks, and allow the platform to intelligently respond to application changes. Second, the structure of cloud computing must be agile, able to respond quickly to demand signals or changes, and the embedded virtualization technology and clustering technology can cope with rapid changes in growth or service-level requirements.
The architecture of the general cloud computing platform is shown in the figure below:
- User interface: Provides an interactive interface for cloud users to request services, and is also the entrance for users to use the cloud. Users can register, log in, customize services, configure and manage users through a web browser, and opening an application instance is the same as operating a desktop system locally.
- Service catalog: Cloud users can select or customize service lists after obtaining corresponding permissions (payment or other restrictions), and can also unsubscribe existing services, and generate corresponding icons or lists on the cloud user interface to display related services. Serve.
- Management system: it is used to manage available computing resources and services, and can manage cloud users, that is, manage user authorization, authentication and login, and manage available computing resources and services; at the same time, it receives requests sent by users and forwards them to corresponding applications according to user requests program.
- Deployment tool: It is autonomous, intelligently and dynamically deploying resources and applications according to user requests, as well as configuring and reclaiming resources.
- Monitoring: Monitor and meter usage of cloud system resources for rapid response. Complete node synchronization configuration, load balancing and resource monitoring to ensure that resources can be allocated to appropriate users smoothly.
- Server cluster: Virtual or physical servers are managed by the management system and are responsible for high-concurrency user request processing, large-scale computing processing, and user Web application services. The corresponding data cutting algorithm is adopted for cloud data storage, and large-capacity data is uploaded and downloaded in parallel.
Cloud computing technology architecture and cloud computing architecture are not a concept. The latter divides the cloud from the perspective of services, which mainly highlights what cloud services can bring to users; the former mainly explains the cloud from the perspective of system attributes and design ideas, which is an explanation of the role played by software and hardware resources in cloud computing technology .
Cloud computing contains multiple functions, as shown in the figure below, which shows the technical architecture for building cloud computing infrastructure.
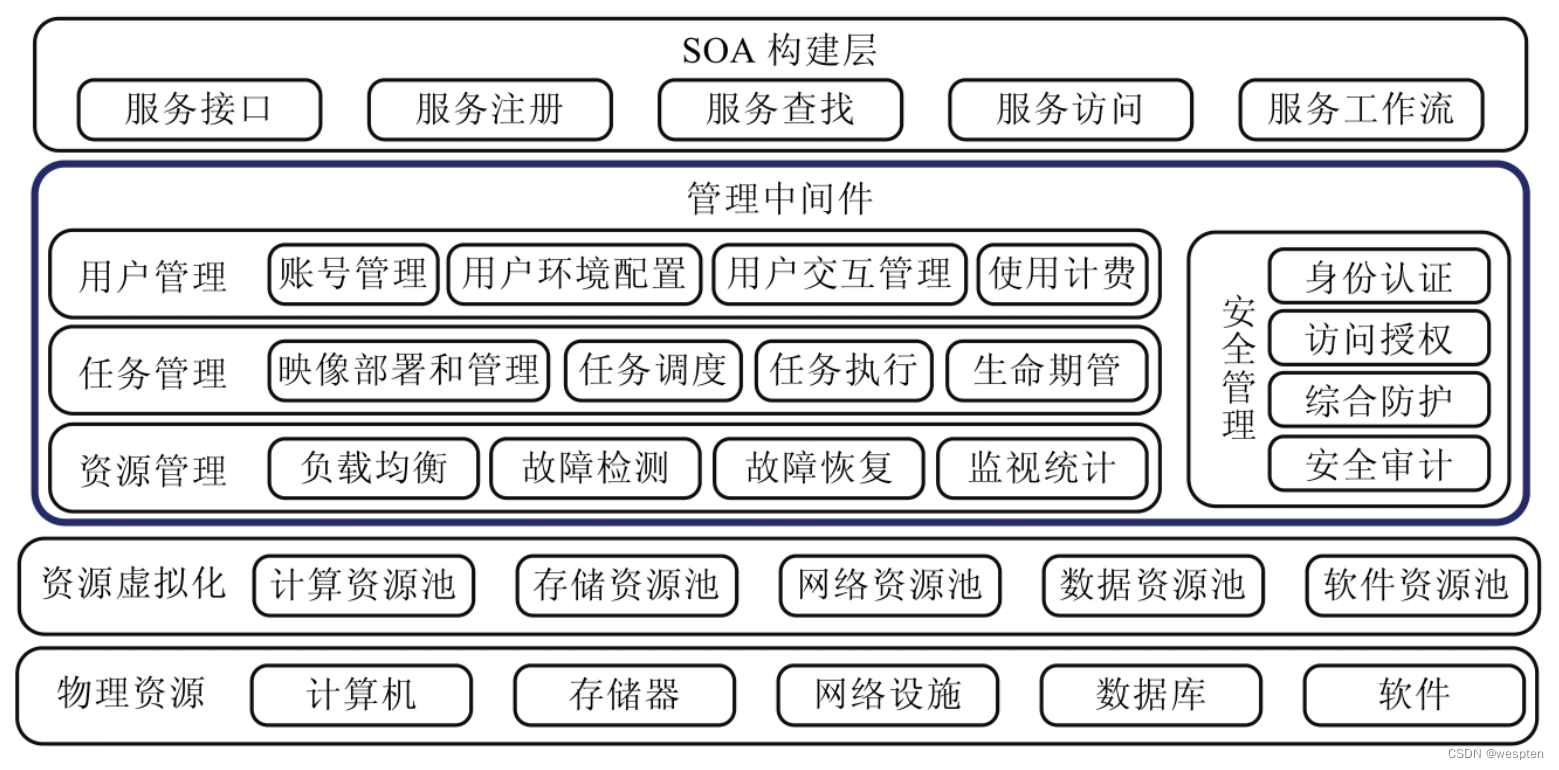
This architecture can be divided into four layers, namely the physical resource layer, resource virtualization layer, management middleware layer and service-oriented architecture (Service-Oriented Architecture, SOA) construction layer.
At the physical resource layer, physical facilities are virtualized to provide a flexible resource pool to improve resource utilization; the management layer is responsible for the management, deployment, monitoring, alarm and security of physical resources and virtual resource pools; the service provider layer combines the management layer Functions provide various forms of service.
- Physical resources: mainly refers to some hardware devices and technologies that can support the normal operation of computers, which can be cheap PCs, expensive servers and disk arrays, etc., and can be distributed through existing networks, parallel and distributed technologies. Computers form a cluster that can provide super functions for cloud computing operations such as computing and storage. In the era of cloud computing, local computers may no longer need a hard disk with sufficient space, a high-power processor, and a large-capacity memory like traditional computers, but only need some necessary hardware devices, such as network devices and basic input and output devices.
- Resource virtualization: Refers to resource pools that can realize certain operations and have certain functions to form a large number of resources of the same type into isomorphic or nearly isomorphic resource pools, such as computing resource pools and data resource pools. The construction of resource pools is more about physical resources. Integrate and manage jobs. Cloud administrators feed demand back to servers and see idle resources directly through server virtualization software. These resources can be established as a resource pool in a few minutes, and then presented to the user, who can use it after paying according to the charging standard of the cloud service provider. During use, administrators can increase or decrease resources based on user needs, which is a kind of change management. If there are not enough resources to start renting, the administrator can add idle resources to the user's resource pool; if the user's resources decrease and the administrator sees that there are still many idle resources, and the user wants to reduce costs, they can release them anytime and anywhere A part of idle resources may be released to the large resource pool of the IaaS service provider to provide services for other users. In this way, the cost of the user and the service side is reduced, and the convenience of service is also provided.
- Management middleware: In cloud computing technology, middleware is located between services and server clusters, and is responsible for resource management, task management, user management, and security management. Standardize services such as identification, authentication, authorization, directory and security, and provide unified standardized program interfaces and protocols for applications. And hide the heterogeneity of the underlying hardware, operating system and network, and manage network resources in a unified manner. Its resource management is responsible for using cloud resource nodes in a balanced manner, detecting node failures and trying to recover or shield them, and monitoring and statistics on resource usage; task management is responsible for executing tasks submitted by users, including completing the deployment and management of user tasks, task Scheduling, task execution, and task lifecycle management. User management is an essential part of realizing the cloud computing business model, including providing user exchange interfaces, managing and identifying user identities, creating an execution environment for user programs, and charging users for usage, etc.; security management guarantees cloud computing The overall security of the facility, including identity authentication, access authorization, comprehensive protection, and security auditing.
- SOA construction: Unified regulations for using computers in the era of cloud computing and various standards for cloud computing services, etc. The portal for interoperability between the client and the cloud can complete user or service registration, customization and use of services, etc.
Administrators can log in through the login interface to remotely provide virtual machine storage, network, account, event, system, and configuration functions. Users can see the virtual machines and resource pools they use through the user interface. At the same time, users are faced with data resources that can be used and managed, as well as resource availability. Both users and administrators can perform adding operations on the cloud computing platform, and the operation results can affect users within the scope of authority.
The difference is that users can only see events related to themselves, while administrators can see events and alarms of all users; in addition, users can see the complete operating system information in the system, and can also log in to the virtual machine to perform related operations . The administrator can maintain and manage system resources, and can also complete the addition and modification of resources. The administrator can comprehensively manage user information in the cloud environment, and many specific parameters and configurations in the system can be set in the administrator configuration interface.
2. Cloud computing architecture from the perspective of virtualization
Virtualization technology is a very comprehensive technology, and most of the work in computer science is doing virtualization. The layer 7 protocol of the network is the virtualization of physical communication, the traditional operating system is the virtualization of a single computer physical hardware, the high-level computer language is the virtualization of machine language, and artificial intelligence is a more advanced virtualization technology.
The following diagram shows the virtualization hierarchy for computer science:
Nodes and network physical hardware form an elastic virtual resource pool integrating computing, storage, and network bandwidth through the logical simplification process of multi-layer virtualization, which is the so-called cloud computing model.
It can be seen that the concept of cloud computing is formed by abstracting the underlying physical hardware through multiple virtualizations, which also explains why cloud computing is the direction of technological development in the next few years. Because the development of technology is a process of continuous abstraction and simplification, the higher the technical logic is, the higher the logic is. This logic stands on the shoulders of many "giants", and these "giants" are the underlying virtualization technology.
1) Look at the resources included in the cloud computing resource pool from the perspective of virtualization
Generally, the resource pool formed by cloud computing only includes computing and storage, but it can be seen from the figure that the resource pool of cloud computing has network bandwidth in addition to computing and storage. Since the nodes of the cloud computing system are distributed, the cloud center can be more than just one place. The cloud computing system can realize the effective coordination of bandwidth resources, thus bringing the resource of bandwidth into the resource pool. Of course, the resource pool of an open general-purpose cloud computing system also includes the services accessed by the system platform. As an application access platform, the cloud computing platform can realize the access and integration of a large number of applications. Perhaps services should also become resource virtualization technologies. into the resource pool.
2) Looking at the industry chain of cloud computing from the perspective of virtualization
The largest virtualization products are the existing operating system software Window and Linux. More strictly speaking, more than 90% of IT companies are doing virtualization. For example, Cisco is doing network layer virtualization, Intel is doing hardware layer virtualization, and a large number of software companies are doing application layer virtualization.
Each virtualization layer in the above figure can also be divided into more detailed, and each virtualization layer represents a link in the cloud computing industry chain. Chip manufacturers, hardware manufacturers, network equipment manufacturers, cloud computing platform providers, cloud application platform providers, storage technology providers, operating system and bandwidth providers, etc. will inevitably enter the cloud computing industry chain, and in different Different virtualization logic layers work differently to support the highest layer of cloud computing applications.
The cloud computing standard needs to establish a virtualized logical protocol stack, so that different enterprises in the industry chain can effectively work under the same logical recursive relationship.
The figure below shows the simplified protocol stack of cloud computing, where each layer also includes many sub-layers. The concept of cloud computing is an upper-level concept derived from multiple logical protocol layers in the lower layer.

3) Looking at cloud computing platforms from the perspective of virtualization
Virtualization is the cornerstone of cloud computing, as shown in the figure below is a typical cloud computing platform.
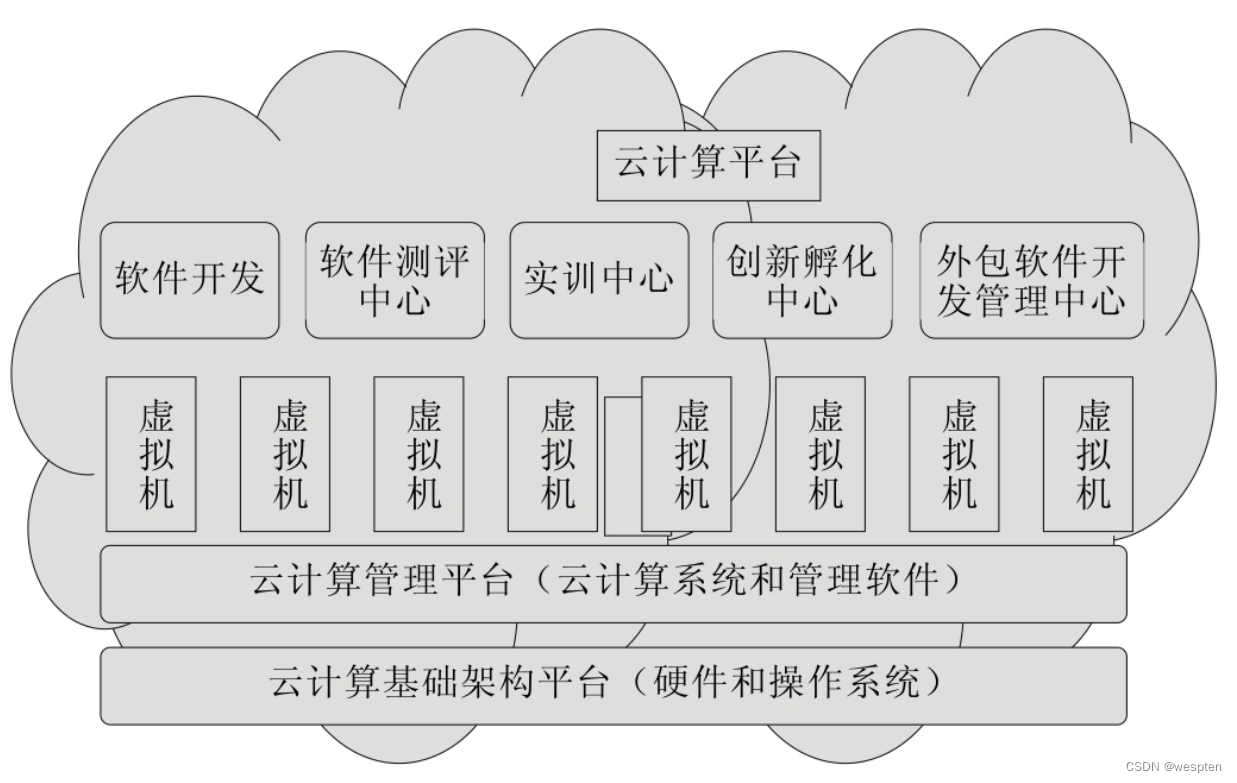
In this platform, the virtualized hardware platform composed of several virtual machines jointly supports the services provided by all software layers.
In such an overall architecture composed of virtualization and cloud computing, virtualization effectively separates hardware and software, while cloud computing allows people to concentrate more on the services provided by the software.
Cloud computing must be virtualized, and virtualization provides a solid foundation for cloud computing. But the usefulness of virtualization is not limited to cloud computing, which is only part of its powerful capabilities.
So far, most of the cloud computing infrastructure consists of reliable services delivered through the data center and different layers of virtualization technology built on the server. Virtualization provides a good underlying technology platform for cloud computing, and cloud computing is the final product.
3. The core module design of the virtualized operating environment in the cloud computing platform
The virtualized operating environment system in the cloud computing platform includes four modules: resource management, node scheduling, virtual machine life cycle management and virtual machine monitoring.
The resource management module realizes the management and virtualization of heterogeneous and distributed physical resources (CPU, memory and hard disk, etc.), and realizes the on-demand use of these physical resources; the node scheduling module realizes the selection of the optimal node controller according to the scheduling strategy; the virtual machine The life cycle management module realizes the management of the virtual machine in the life cycle of the virtual machine; the virtual machine monitoring module realizes the real-time monitoring of the virtual machines in all node controllers in the cloud computing platform. The cooperation of the four modules enables the system to fully and rationally use and share the resources in the system to maximize the utilization.
1) The architecture of the operating environment
The virtualized operating environment in the cloud computing platform consists of a cluster controller and multiple node controllers, and its architecture is shown in the figure below.
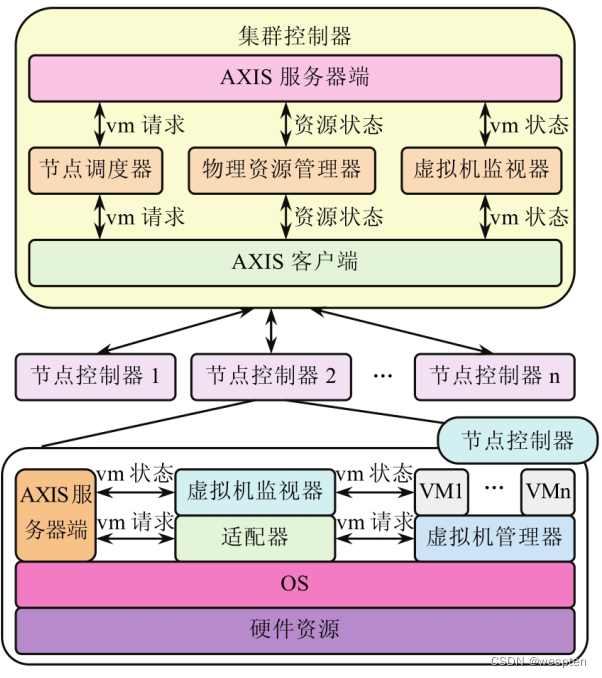
The cluster controller is mainly responsible for node scheduling, monitoring the status of virtual machines in the system, and the CPU, memory and storage resource occupancy of all node controllers; the node controller virtualizes physical resources into virtual machine resources through the virtual machine manager and allocates them to Virtual machines, and manage and monitor virtual machines during their life cycle. Each node controller is divided into three layers, namely hardware resources (CPU, memory and hard disk), virtual machine manager (KVM+Qemu, Xen or virtualBox) and virtual machines.
Among them, the virtual machine manager completes the virtualization of physical resources to virtual resources, and processes the I/O requests of virtual machines; the adapter module of the node controller is responsible for receiving requests from the cluster controller, adapting to different virtual machine managers and managing virtual machines Wait. In this system, the node controller uses Axis2/C, that is, the Apache Extensible Interaction System (AXIS) to publish services; the cluster controller sends requests to the node controller through the Axis2/C client and obtains responses.
2) Resource management
(1) Resource virtualization
The resource virtualization of the virtualized operating environment in the cloud computing platform is mainly realized by the virtual machine manager in the node controller, which virtualizes the CPU, memory and hard disk resources on the node controller into virtual resources for use by the virtual machine. This system supports 3 kinds of virtual machine managers, namely KVM+Qemu, Xen and VirtualBox.
KVM is a fully virtualized virtual machine monitor (VMM), which consists of two parts: KVM driver and Qemu (a widely used open source computer emulator and virtual machine, as well as a virtual machine management system). Among them, the KVM driver has been embedded into the kernel as a kernel module of Linux, and its main responsibilities are to create virtual machines, allocate virtual machine memory, read and write virtual CPU registers, and run virtual CPUs; Qemu provides I/O devices for virtual machines The way the emulator accesses peripherals.
The following figure shows the basic architecture of KVM (Libkvm is the application program interface provided by KVM to Qemu):
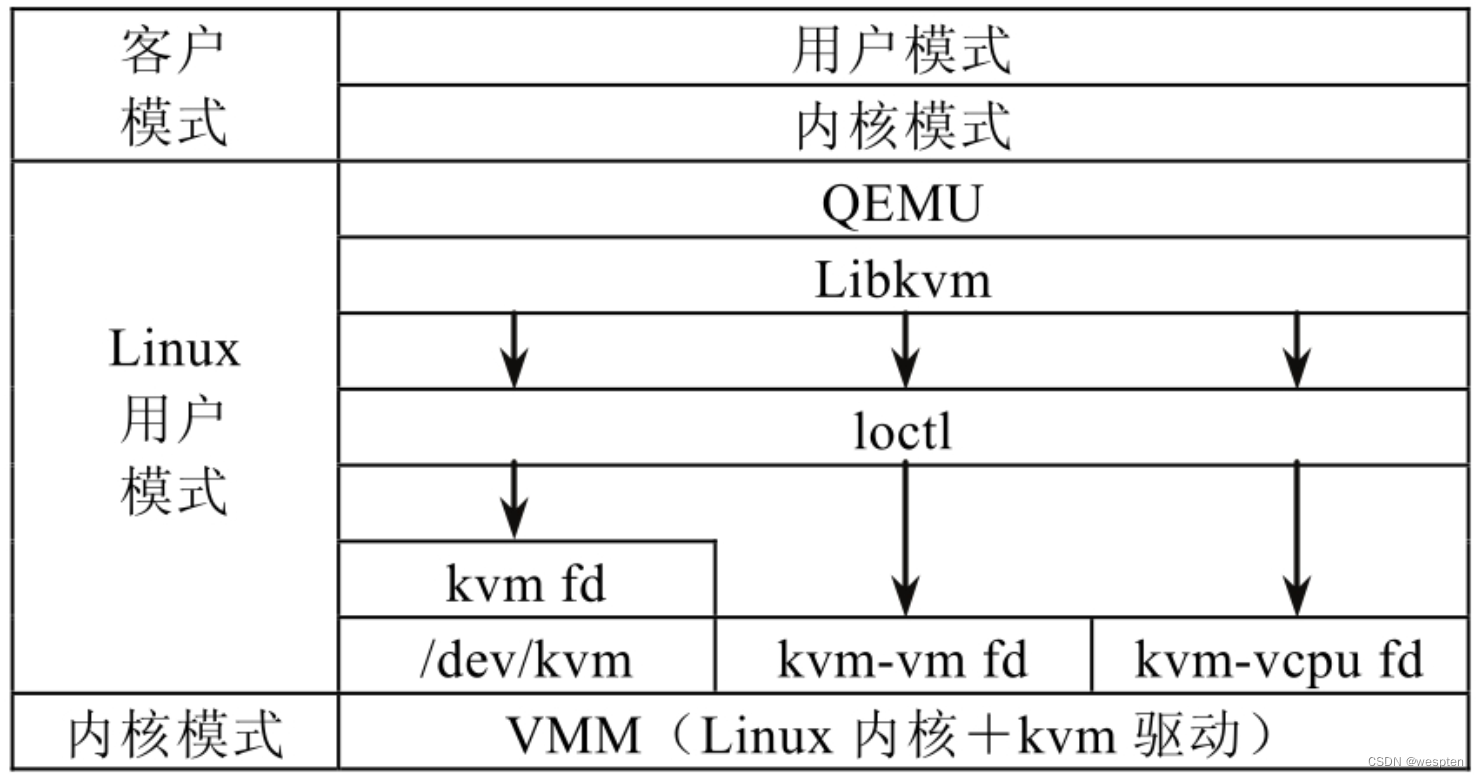
The KVM driver is added to the standard Linux kernel and is organized as a standard character device (/dev/kvm) in Linux. Qemu in user mode can access /dev/kvm through system calls when creating and running virtual machines. The addition of the KVM driver makes the entire Linux kernel a VMM, and adds a client mode (with its own kernel and user mode) based on the original two Linux execution modes (user and kernel mode).
(2) Resource monitoring
The virtualized operating environment realizes the unified abstraction and logical representation of resources including CPU, memory, and hard disk. The abstracted virtual machine resources are composed of one or more virtual machines, and the final platform is presented to users in the form of virtual machines. Therefore, effective real-time monitoring of resources to ensure reasonable allocation of resources is an important responsibility of the virtualized operating environment.
The cluster controller will obtain the latest resource information of the platform every 60 seconds. The specific process is to first check whether the configuration file has been modified, and send a request describing resource information to each node controller according to the latest configuration file information.
When the node controller receives the request, it will provide the resource occupancy and remaining status receipt including CPU, memory and hard disk to the cluster controller, and then the cluster controller will count all the responses received, so as to understand the resources on the platform occupancy and remainder. In addition, when a user applies for a virtual machine, the virtualization operating environment will allocate resources to the virtual machine according to the current remaining resources, and when the user closes the virtual machine, the system will also reclaim the resources in time.
3) Node scheduling
The virtualized operating environment in the cloud computing platform is composed of a cluster controller and multiple node controllers, and each node controller is installed with a virtual machine manager, on which one or more virtual machines can run. When a user applies for a virtual machine, the cluster controller selects a node controller according to a certain scheduling strategy, so as to ensure a reasonable allocation of resources and load balancing under the premise of sufficient resources.
The virtualized operating environment in the cloud computing platform provides three scheduling methods to select the node controller, namely, GREEDY (select the first available node whose resources can meet the demand each time), ROUNDROBIN (queue the nodes, and order them according to the polling method) Select an available node) and POWERSAVE (when there is no virtual machine running on the node, it is in a sleeping state, and each time it selects an available non-sleeping node with resources that meet the requirements. If there is no non-sleeping node that meets the requirements, wake up the available sleeping node).
When the node scheduler receives a request to apply for a virtual machine, it will select a node controller according to one of the scheduling strategies, and at the same time send a request to apply for a virtual machine to the node controller.
In addition, when the user requests to shut down or restart the virtual machine and the system monitors the virtual machine in real time, the system needs to be able to schedule nodes to determine the node controller where the virtual machine is located, so as to send a request to the node controller to perform subsequent operations.
(1) Node scheduling when starting a virtual machine
When the system receives a request to start a virtual machine, the cluster controller will call the node scheduling strategy to find a node controller that meets the application requirements in resources for the virtual machine, and will send a request to start the virtual machine to the node controller after finding it. The process is as shown in the figure below shown.
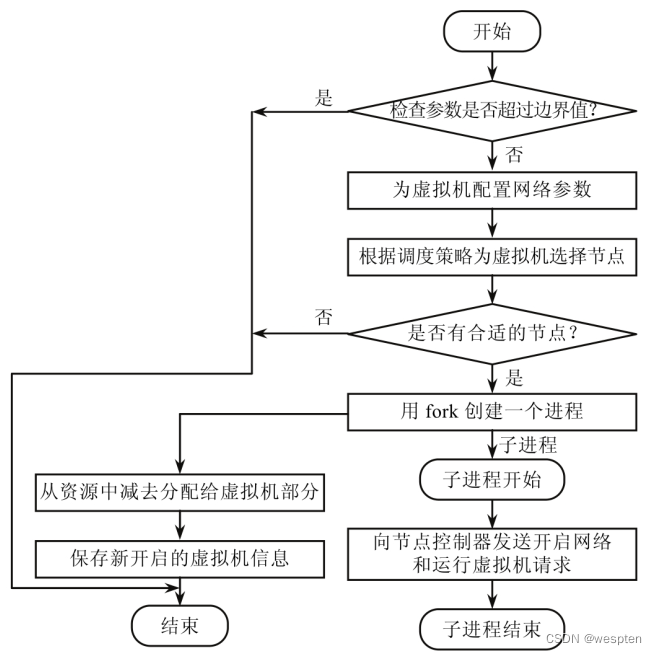
Each node controller of the cluster controller has 4 states, RESASLEEP, RESDOWN, RESUP, and RESWAKING. The sleeping node controller is in the RESASLEEP state, the awakening node controller is in the RESWAKING state, the awakened node controller is in the RESUP state, and the temporarily inaccessible node controller is in the RESDOWN state for some reason.
When no virtual machine is running in the node controller, the node controller will sleep. When the cluster controller receives an application for starting a virtual machine, it first selects a node controller whose remaining resources meet the application requirements from the non-sleeping node controllers. If not, select a node controller that meets the requirements from the sleep state, and wake up the node controller.
(2) Node scheduling when the virtual machine is turned off
After receiving the request to shut down the virtual machine, the cluster controller searches for the corresponding virtual machine according to the list of virtual machines to be shut down. If the virtual machine is found and the virtual machine can be terminated, it obtains the service address of the node controller where it is located, and sends the request to the virtual machine. The node controller sends a service request to shut down the virtual machine. Otherwise, send a service request to shut down the virtual machine to all node controllers. The node scheduling process when shutting down the virtual machine is shown in the figure below.
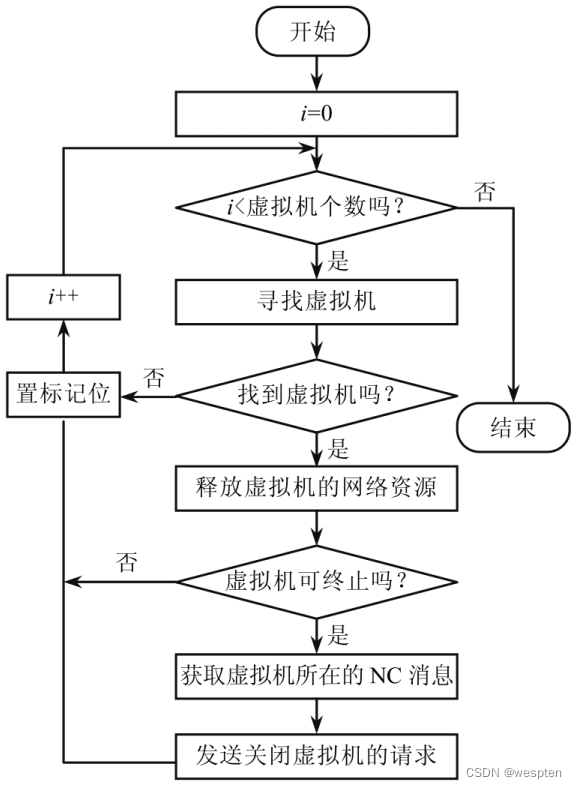
(3) Node scheduling when restarting the virtual machine
After receiving the request to restart the virtual machine, the cluster controller will search for the corresponding virtual machine according to the list of restarted virtual machines. If found, it will obtain the service address of the node controller where the virtual machine is located and send the restart virtual machine to the node controller. Service request; otherwise, send a service request to restart this virtual machine to all node controllers.
The node scheduling flow chart when restarting the virtual machine is shown in the figure below.
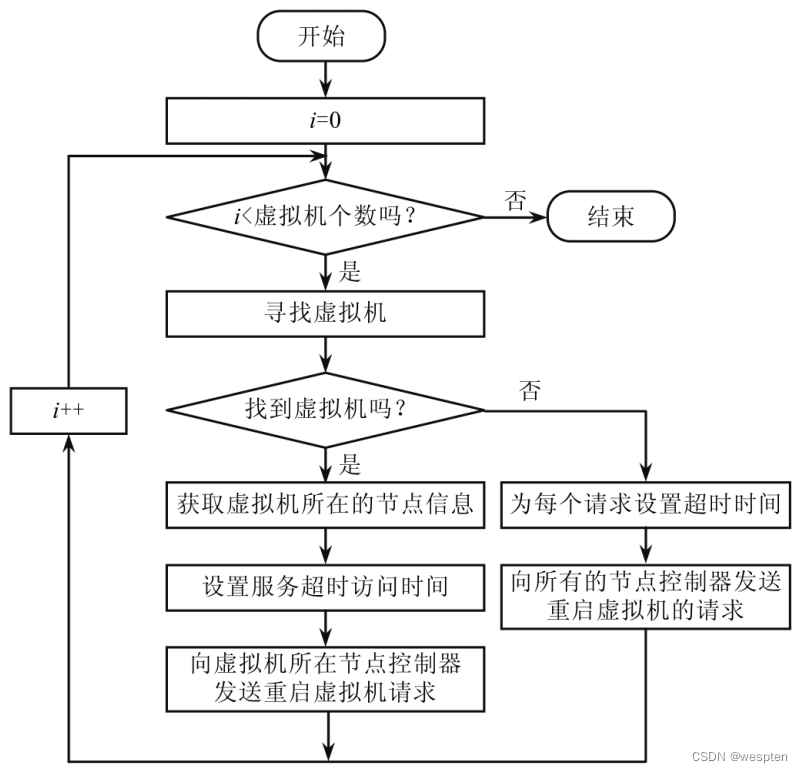
(4) Node scheduling when migrating virtual machines
After receiving the request for migrating virtual machines, the cluster controller will search for the corresponding virtual machine according to the list of migrating virtual machines. If found, it will obtain the service address of the node controller where the virtual machine is located and send the migration virtual machine address to the node controller. Service request; otherwise, send a service request to migrate this virtual machine to all node controllers.
The node scheduling process when migrating virtual machines is shown in the figure below.
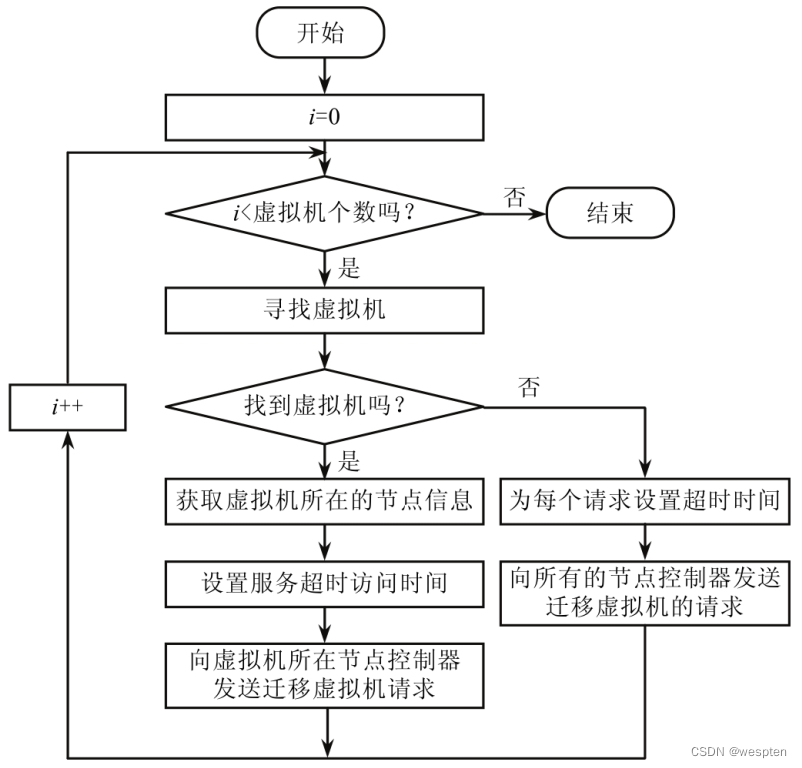
4) Virtual machine lifecycle management
The life cycle of a virtual machine refers to the entire time period from when the user applies for a virtual machine to when the user shuts down the virtual machine. During this time period, the virtualized operating environment can start, restart, shut down, and migrate the virtual machine according to the user's request. During the entire life cycle of the virtual machine, the virtual machine is owned by the applicant, and no one, including the platform administrator, can perform any operations on the virtual machine.
(1) Start the virtual machine
After the node controller receives the request to apply for a virtual machine, the adapter queries the resource manager whether there are enough hardware resources allocated to the virtual machine, and if so, prepares mirroring resources for the virtual machine and starts the XML file of the virtual machine. The image resource refers to the image file required to start the virtual machine, in which the operating system and common software required by the user have been installed according to the user's requirements. Then call the API of the Libvirt virtualization library to start the virtual machine, and send the service response to the cluster controller. When the virtual machine is started, it will obtain an IP address through DHCP or the address pool configured by the cluster controller. After the virtual machine is successfully started, the user can access the virtual machine.
(2) Shut down the virtual machine
After the node controller receives the request from the cluster controller to shut down the virtual machine, it first searches for the corresponding virtual machine from the virtual machine list, and if found, it detects whether it is connected to the virtual machine management program; otherwise, it uses the Libvirt virtualization library API to connect to the virtual machine hypervisor. Then find the corresponding virtual machine through the virtual machine name and call the Libvirt virtualization library API to shut down the virtual machine, and then send the service response to the cluster controller.
(3) Restart the virtual machine
After receiving the virtual machine restart request sent by the cluster controller, the node controller first searches for the corresponding virtual machine from the virtual machine list, and if found, detects whether it is connected to the virtual machine monitoring program. If not connected, use the Libvirt virtualization library API to connect to the hypervisor to find the corresponding virtual machine. Then call the Libvirt virtualization library API to restart the virtual machine, and return the service response to the cluster controller.
(4) Migrating virtual machines
After receiving the virtual machine migration request sent by the cluster controller, the node controller first searches for the corresponding virtual machine from the virtual machine list, and if found, detects whether it is connected to the virtual machine monitoring program. If not connected, use the Libvirt virtualization library API to connect to the hypervisor to find the corresponding virtual machine. Then call the Libvirt virtualization library API to migrate the virtual machine, and return the service response to the cluster controller.
5) Virtual machine monitoring
The virtualized operating environment virtualizes physical resources into virtual resources through virtualization technology, and finally presents each virtual machine to the user. Therefore, it is an important function of the virtualized operating environment in the cloud computing platform to monitor the virtual machine to grasp the status of the virtual machine in real time and judge whether it is running normally.
The virtual monitoring of this system is divided into two parts, one is that the node controller monitors the virtual machines running on it, and understands its latest status; the other is that the cluster controller monitors all virtual machines on the platform, Send a describe virtual machine state request to get the latest state information for all virtual machines.
Similar to resource monitoring, the cluster controller will obtain the latest virtual machine status information of the platform every 60 seconds. The main process of virtual machine monitoring is to obtain all node controller information, and then send a virtual machine status request to all node controllers. After receiving the response, the relevant data structures are updated to save the latest information about the virtual machine. The node controller updates the status information of the virtual machine running on the node controller every 5 seconds, so as to ensure that the response sent to the cluster controller is the latest status information of the virtual machine.
The virtual machine monitoring process is shown in the figure.
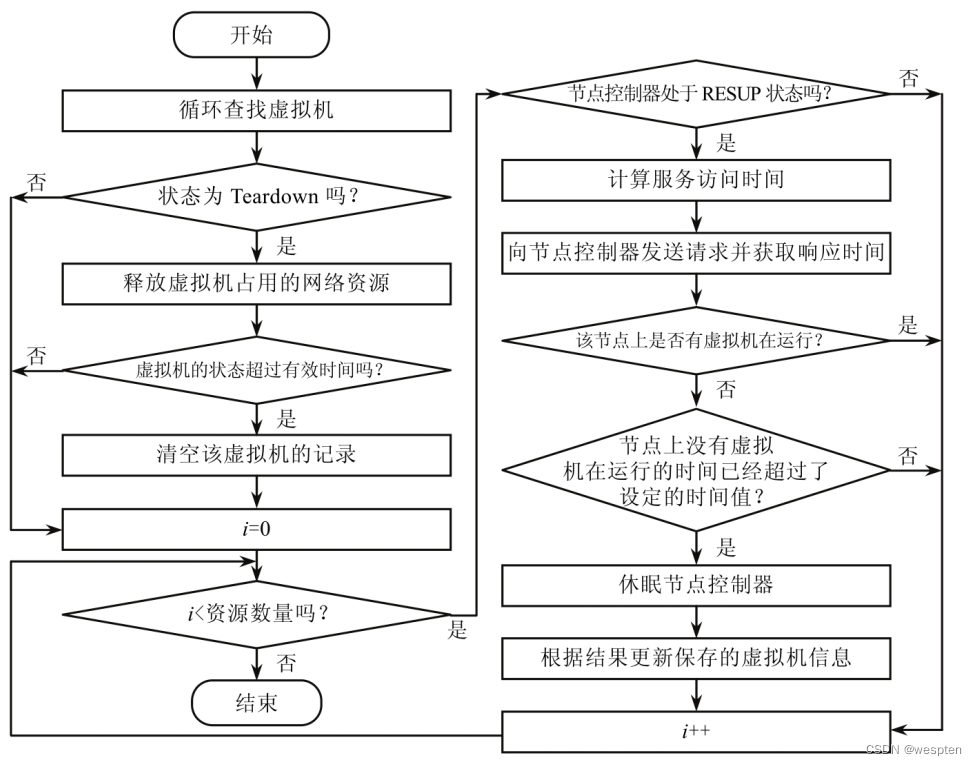
4. Resource virtualization implementation case
Virtualization technology can centralize computing, network and storage resources to form a dynamically allocated resource pool (Resource Pool), which can cope with the simultaneous high-speed access of a large number of computing units, and dynamically expand capacity without affecting system performance, and has high reliability. resilience and resilience.
The effective utilization of resources can be realized by building a unified data service virtualization platform model. On the basis of safety, reliability and massive computing storage, the computing, network and storage resources are concentrated in the dynamic resource pool to form an efficient application software development and operation platform. .
1. System architecture design
Based on cloud computing, the virtualization platform can support a variety of typical application types based on cloud computing. The whole system architecture is divided into resource pool management platform, resource pool unified scheduling, host resource pool, storage resource pool and network resource pool, as shown in the figure below.
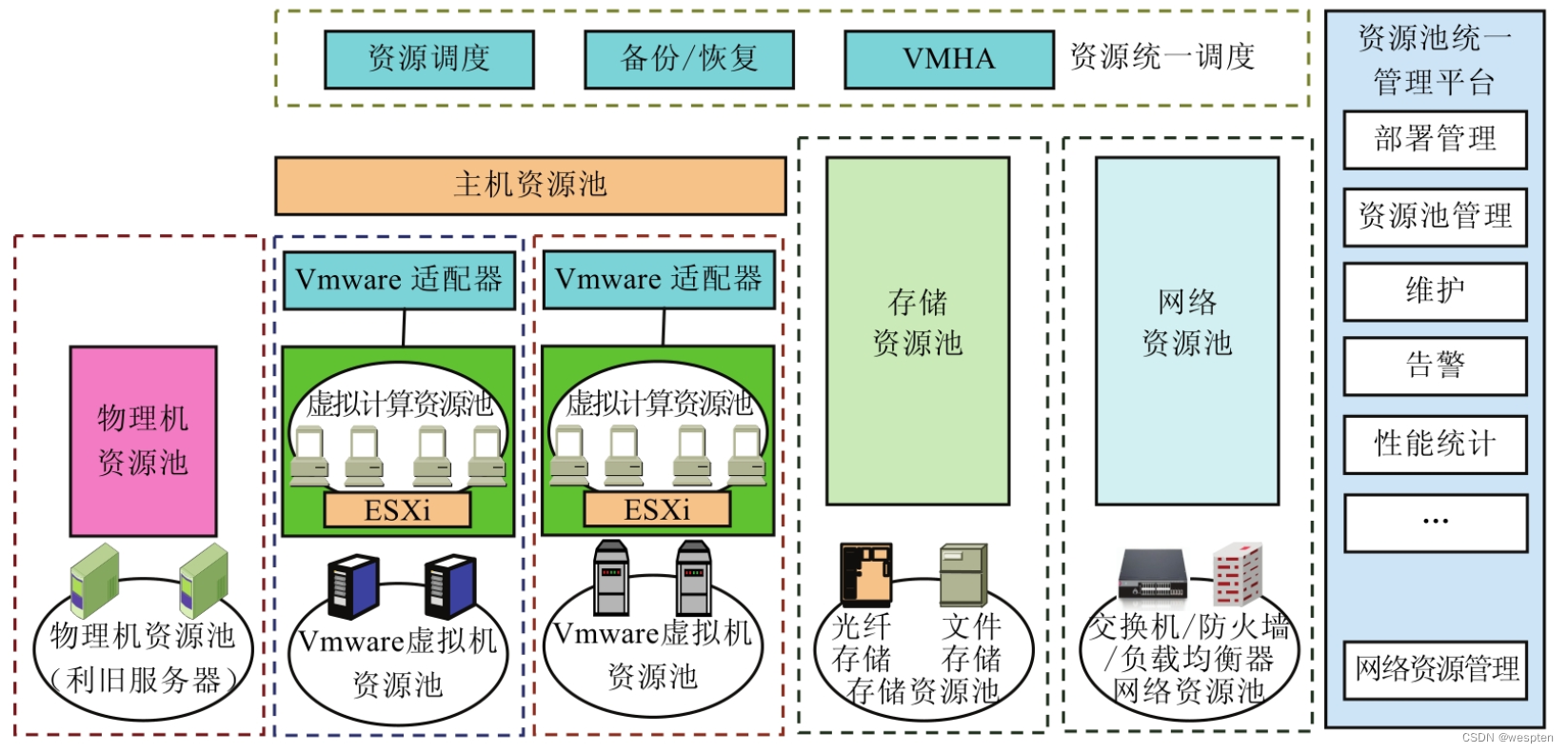
- Resource pool management platform: also known as "resource operation management platform". As the core module of the unified virtualization platform, it is responsible for the unified management and scheduling of the entire resource pool resources, that is, it is responsible for the operation monitoring, operation and maintenance of the entire platform and the business of the entire resource. Operational process support.
- Resource pool unified scheduling module: Unify all resource presentation and management entities in the platform, and receive instructions from the resource pool operation management platform.
- Host resource pool: responsible for the management and scheduling of all computing resources in the resource pool. Resource pool management includes virtual machine resources and physical machine resources. VMware vSphere Hypervisor (ESXi) is VMware's embedded hypervisor, a bare-metal virtualization hypervisor architecture that installs directly on server hardware. Starting with VMware vSphere 5, ESXi is the only hypervisor available for deploying vSphere. Since VMware ESXi is not dependent on a general-purpose operating system and has a smaller code base, it is more reliable and safer to choose. Embedded in mainstream physical servers, the program simplifies and speeds up deployment, and its menu-prompted startup and automatic configuration capabilities make it the easiest way to get started with VMware virtualization.
- Storage resource pool: responsible for the management and scheduling of all storage resources in the resource pool, including block storage and file storage. Block storage resource virtualization supports the heterogeneity of SAN devices from different manufacturers, and shields the hardware differences of various devices; file storage uses the mature and popular cloud storage technology in the industry to shield the differences in storage locations, and provides on-demand allocation and elastic expansion for business platforms storage service.
- Network resource pool: responsible for the management and scheduling of all network resources in the resource pool, and providing business platforms with network connection services required for external access, device access, business management, and network isolation.
A unified application system must guarantee the system's response speed and service quality to users, so the system needs high reliability. It can ensure the accuracy, integrity and consistency of data and have the ability to recover quickly after a system failure or interruption caused by an accident.
Performance issues must be fully considered when designing the system architecture, application design, database design, and system deployment. At the same time, the system needs to have good openness to ensure that the system has a long vitality and meet the requirements of future system development.
2. Implementation technology
The platform model adopts microkernel design technology, in which the kernel of the operating system only needs to provide the most basic and core part of operations. Other hypervisors are placed outside the kernel to the greatest extent, making the internal structure of the operating system simple and clear, and the maintenance of program codes is very convenient. The external program can run independently, and only when the program needs the assistance of the kernel, it sends a request call to the kernel through the relevant interface, so that it is convenient to expand and add other power supply components.
The rule configuration is implemented in the python language, which has a concise and clear syntax and a powerful class library, which can easily combine various modules written in other languages. Then rewrite the parts with special needs in a more suitable language, and the clear and consistent style ensures the high scalability and customizability of the product.
The Open Service Gateway Initiative (OSGI) plug-in framework adopted by the platform is different from most current multivariate counter (Multiple Variate Counter, MVC)-based layered designs. It is highly reusable and efficient, and can Dynamically change system behavior. The hot-swappable plug-in architecture can easily insert third-party plug-ins, and develop specific plug-ins for specific software for monitoring and management.
The data service virtualization platform adopts Java Management Extensions (JMX) monitoring and configuration, which can span a series of heterogeneous operating system platforms, system architectures and network transmission protocols. And flexibly develop seamlessly integrated system, network and service management applications, which improves the manageability of the system.
3. Development and Implementation Ideas
The unified data service virtualization platform can provide various views of resources for various personnel to view, and can provide various functions to manage and use resource pools. The data service virtualization platform is divided into a management portal and a service portal. The management portal is used by various administrators of the unified platform; the service portal is mainly for various users of the unified platform.
Device management is used to access and manage various physical devices in the resource pool of the unified platform, including hosts, storage and network devices. Each physical device in the resource pool is brought into the unified management of the management platform after basic configuration on the management portal.
In order to meet the various needs of users for resources and achieve the purpose of resource sharing and decoupling of software and hardware, various devices in the resource pool are virtualized and brought into the resource pool for users to use. The management platform can manage the existing mainstream virtualization products, and provide virtual machines of various specifications through these virtualization products.
According to different attributes, various physical resources and virtual resources in a resource pool can form different resource pools. The management platform manages, monitors, and schedules the resource pool in a unified manner to meet the user's resource usage requirements. The platform can monitor and record the operation and operation of various resources in the system, and provide basis for the daily maintenance of the system, including resource pool topology display, resource monitoring, alarm management, log management, backup and recovery, etc.
So far, by building a unified data service virtualization platform model to realize the effective use of resources and integrate existing network resources, so as to provide a feasible solution for the unification, centralization, intelligent scheduling and management of all resources. At the same time, considering the requirements of system security, load balancing and data backup, etc., it fully supports the smooth cutover and elastic expansion of the business platform, so as to achieve the purpose of reusing old equipment and revitalizing it.
4. Virtual resource management
Cloud data centers contain large numbers of computers and are expensive to run. Effectively integrating virtual resources to build a dynamic virtual resource pool to improve resource utilization, save energy and reduce operating costs is a hot spot in cloud data centers.
It is an important task of virtual resource management to realize automatic deployment, dynamic expansion and on-demand allocation of cloud computing virtual resources, and enable users to obtain virtual resources in an on-demand and pay-as-you-go manner.
1. The function of virtual resource management
Virtualization resource management is not expressed in terms of geographic location, implementation, or encapsulation of resources. It provides a logical view rather than a physical view for resources such as data, computing power, storage, and networks. Each management model provides a virtual resource management service, including system-level resource services such as virtualized storage services, virtualized server services, virtualized file system services, virtualized cluster system services, and virtualized user system services.
A consumer of virtualized resource management can be an end user, an application, or a service that accesses or interacts with a resource. Through virtualized resource management, users can simplify the process of resource usage without paying attention to the details of physical resource implementation and distribution. Service providers can effectively and uniformly manage distributed resources through resource virtualization management, efficiently complete user requests, simplify the service process and improve service efficiency.
Resource management needs to manage various distributed heterogeneous virtual resources in the cloud computing network virtualization environment, and provide users with a simple resource access interface. And the sharing and use of virtual resources should be coordinated, and various virtual resources in the network virtualization environment should be utilized as efficiently as possible to realize extensive sharing among virtual resources. Virtual resource management is a set of operations that control how virtual resources provide available capabilities to other entities such as users or applications. It focuses on controlling the service provision capabilities of virtual network resources. That is, you don't care about the specific function of the resource, but how the function is performed.
The core function of virtual resource management is to maintain and schedule virtual resources, discover and identify virtual resources, find and allocate virtual resources, provide and deploy virtual resources, monitor the operation of virtual resources and physical resources, and realize the virtual resource life cycle. Management and management of virtual resource lifecycle, etc.
Virtual resource management not only needs to manage the use process of virtual resources, but also needs to manage the entire life cycle of virtual resources. The entire life cycle of virtual resources includes processes such as virtual resource registration, virtual resource discovery, virtual resource scheduling, virtual resource reservation, and virtual resource recycling, as shown in the following figure.
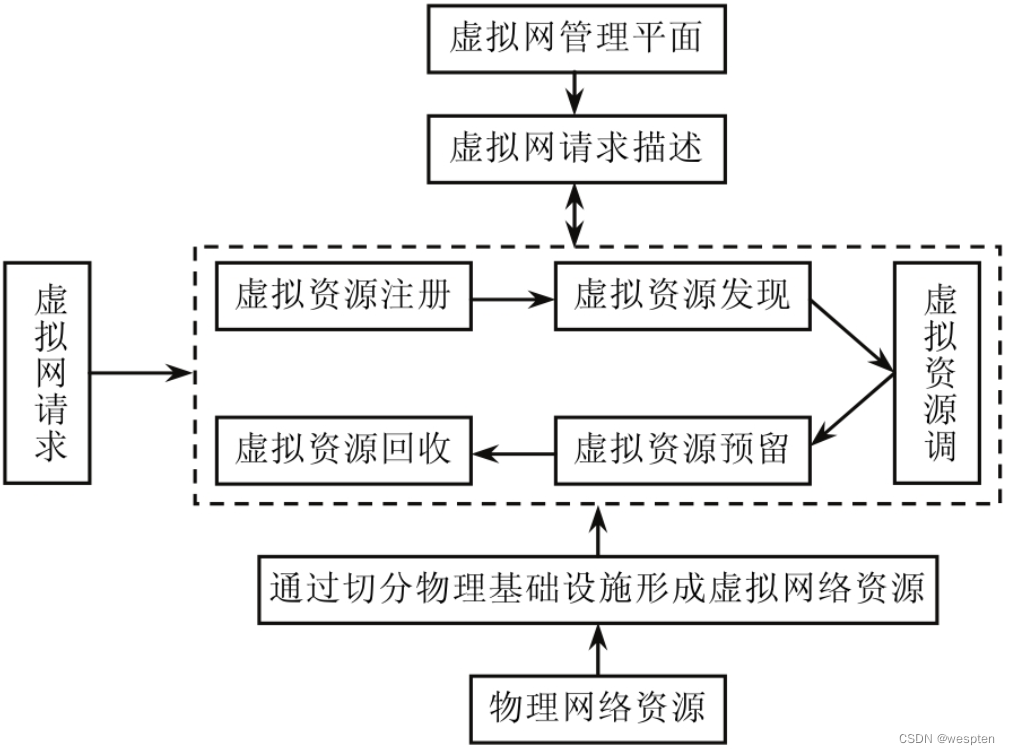
1. Virtual resource registration
The infrastructure provider is responsible for laying and building the basic physical network, divides the physical network resources through the abstraction and isolation mechanism to form sliced virtual network resources, and is the owner of the resources. As a resource provider, it should register local virtual resources for the management system, so that local virtual resources can be managed by the system.
The registration information of virtual resources includes resource attribute information, such as static information such as the operating system type of the node, the virtual machine environment, and the network protocol stack used, as well as dynamic information such as the remaining CPU resources of the node and the remaining bandwidth of the connection link. Information will be saved in the resource information database.
2. Virtual resource discovery
Virtual resource discovery is the process of finding available resources that meet the virtual network user's request from the virtual resource information collection according to the required resource description information submitted by the virtual network user's request. It is an operation that provides a set of candidate resources for virtual resource scheduling processing, and is used to timely discover virtual resources suitable for user applications and automatically discover and apply the association between virtual resources and physical resources. A typical implementation of resource information storage and resource matching operations exists in the form of a distributed system.
3. Virtual resource scheduling
Virtual resource scheduling is the process of assigning appropriate resources to virtual network requests, that is, the process of realizing the sharing of physical resources by multiple virtual network users. It uses different strategies to allocate the required resources to the corresponding user tasks. The problem to be solved is to find the best matching virtual resource from the candidate resource set provided by the resource discovery step according to the resource demand constraints proposed by the virtual network user.
In the network virtualization environment, there are various types of heterogeneous virtual resources, and there are also various virtual network applications that require virtual resources. As infrastructure providers who provide virtual resources and virtual network users who use virtual resources, they have their own strategies and interfaces for using resources. Resource scheduling needs to not only meet the needs of users, but also maximize the utilization of underlying physical network resources.
4. Virtual resource reservation
When the resource management system finds suitable resources for virtual network users, it needs to notify the infrastructure provider to perform the corresponding reservation operation, that is, the infrastructure provider is required to set aside The resources are reserved for the virtual network users; meanwhile, the infrastructure provider is required to authorize the virtual network users with certain access rights to configuration resources. The resource reservation strategy can provide the required resources within a specific time for the user's complex application requirements, so as to ensure the user's requirements for SLA and QoS.
Each reservation application has 8 different states, and the transition process between states is shown in the figure below.
- After the reservation application is submitted, it enters the resource query verification stage. If the user's application meets the requirements, the reservation request is accepted; otherwise, the application is rejected.
- During the verification process, if the user finds that the reservation application cannot meet the requirements, the user can cancel the resource reservation application. However, if the cloud administrator thinks that the cancellation is inappropriate and the remaining resources can meet the user's needs, the application will still enter the approval state; otherwise, it will be cancelled.
- If the user does not cancel the submitted resource reservation application after it is approved, it will enter the valid state and the required resources will be reserved; otherwise, it will enter the canceled state.
- When the submitted resource reservation application is approved or is in the effective state, since the time reserved by the user is about to expire, the resource reservation will be transferred to the state of about to expire.
- When users find that their reserved resources are about to expire, they can choose to re-reserve resources or end the resources they are using.
- When the end time of resource reservation is reached, it enters the expired state and reclaims the reserved resources.
5. Virtual resource reclamation
When the virtual network life cycle ends and the resources used need to be released, the infrastructure provider regains the right to manage the resources and waits to provide virtual resources for the next virtual network. The virtual network arrives and leaves in real time, and virtual resources are occupied or released. Virtual resource management needs to implement a reasonable scheduling strategy for the dynamic changes of such resources, and integrate scattered resources to optimize the use of underlying physical network resources.
Some basic operations of the above-mentioned virtual network resource management are completed under the supervision of the virtual network resource management system, but all virtualized resource management often also includes resource abstraction, resource monitoring, load management, data management and resource dynamic deployment.
2. Virtual resource provision and automatic deployment
The characteristics of cloud data center virtual resource management are virtual flexible provision, automatic deployment, centralized management, distributed use, centralized monitoring, dynamic optimization, energy saving and low consumption, among which virtual resource provision and automatic deployment are the basis and important aspects of cloud computing resource management. content.
1. Resource provision strategy
Typical cloud computing resource provisioning strategies include those based on lease theory and dynamic multi-level resource pools, resource provisioning strategies based on economic principles, resource provisioning strategies based on general optimization algorithms, and optimal resource provisioning strategies based on random integer programming.
- Provisioning strategy based on lease theory and multi-level resource pool: This is a resource scheduling strategy that combines lease theory and dynamic multi-level resource pool, which virtualizes resources into multiple slots. According to a common characteristic of resources, resources are classified into resource pools and multi-level resource pools are established. One of the resource pools acts as a server to provide services such as interaction with the outside of the cloud, maintenance of resource pool load balancing, and assignment of tasks; combined with sharing , Private, Borrow and Return, and Redeclare strategies to complete the scheduling of resources. It realizes the allocation of virtual resources through resource division and resource reservation strategy, ensures the effectiveness of users' use of virtual resources, and utilizes a borrow/lent scheduling strategy to maximize the utilization of virtual resources.
- Cloud computing resource provision strategy based on economics: According to the concept of economics, the cloud computing environment is regarded as a cloud market. That is, resources are regarded as commodities, multiple computing clouds and storage clouds are abstracted as resource providers, and cloud computing users are regarded as consumers of resources. This strategy provides feedback on economic incentives for cloud consumers and suppliers, improves resource utilization, and helps to achieve efficient management and optimal allocation of resources in cloud computing environments; at the same time, it satisfies user service quality requirements to the greatest extent. However, this strategy is based on an economic point of view and does not provide relevant strategies for saving customer costs, nor does it consider the dynamics of resources and prices.
- Optimal Resource Provisioning Strategy Based on Random Integer Programming: This is a method to optimize resource provisioning using stochastic integer programming. In cloud computing, cloud providers can provide users with resources in two ways, that is, subscription and pay-as-you-go. The former can effectively reduce the cost of users, but because of the uncertainty of user needs and resource prices, it is difficult to obtain resources completely through reservations to meet user requirements. Using heuristic methods or K-proximity algorithms can predict the resources required by users . This strategy provides a dynamic resource provision scheme to meet the needs of customers, and considers the resource cost of each stage of resource provision, so as to minimize the resource cost of users.
2. Automatic deployment of virtual resources
The automatic deployment of virtual resources refers to the transformation of virtual resources from the original state to the usable state through automatic installation and deployment, which is an important functional requirement of the data center. An important function of resource management after the cloud computing data center adopts virtualization technology is to build a virtual resource pool and deploy virtual machines on different physical machines to achieve effective and unified management of large-scale basic resources.
Embodied in cloud computing is the process of dividing, installing and deploying resources in a virtual resource pool to provide users with various services and applications, including hardware (servers), software (software and configuration required by users), and network and storage. There are multiple steps in the deployment of system resources. Automatic deployment realizes the automatic configuration of device management tools from different vendors and the deployment and configuration of application software by calling scripts. Ensuring that these calling processes can be implemented in a default way saves a lot of human-computer interaction, making the deployment process no longer dependent on manual operations.
The entire deployment process is implemented based on workflow, as shown in the figure below.
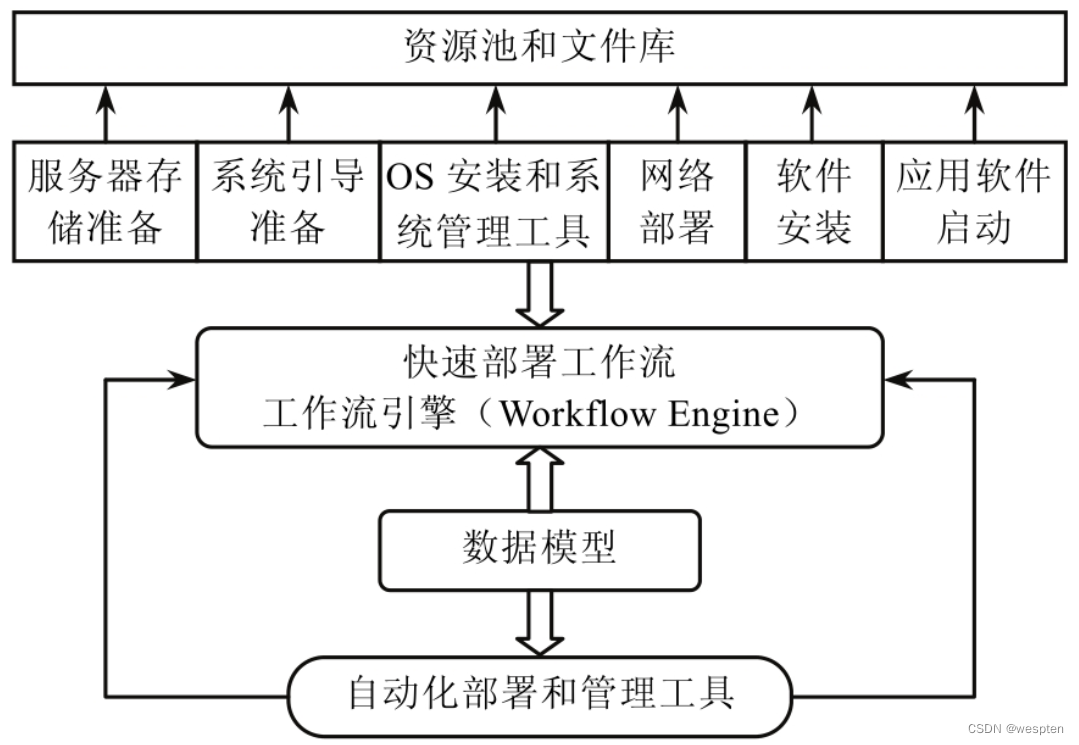
The workflow engine and data model are the functional modules involved in the automated deployment management tool. By defining specific software, hardware, and even logical concepts in the data model, the management tool can identify and schedule these resources in the workflow and implement classification manage. The workflow engine is the core mechanism for invoking and triggering workflows to implement deployment automation. It automatically integrates different types of script processes into a centralized and reusable workflow database. These workflows can automatically complete the server that originally required manual completion. , operating system, middleware, application, storage, and network device configuration tasks.
Virtual machine deployment is a complex issue. On the one hand, resources and applications in the cloud environment not only have a wide range of changes, but also are highly dynamic. The services required by users are mainly deployed on-demand; on the other hand, different cloud data centers and different levels of cloud The deployment modes of services in the computing environment are different, the software systems supported by the deployment process are in various forms and the system structures are different, and the deployment strategies are diverse.
Resource deployment generally starts with the deployment of computing resources. The resource deployer considers allocating appropriate resources for storage and network resource pools on the premise that the computing resources required by the virtualization solution can be guaranteed. If the computing resources of a single physical server cannot meet the requirements of solution services, multiple server resources are required. At this time, the load balancing of virtual machines becomes a very important factor, that is, it can ensure that the resources allocated during the deployment phase can be fully utilized. Of course, I/O load balancing of storage resources and bandwidth balancing of network resources also need to be considered.
3. Deploy the virtual device
Deploying virtual devices is the most important link in the process of delivering solutions supported by virtual devices to users, that is, the stage of virtual machine instantiation. The work to be done in the deployment phase is to adapt the virtual device to the new virtualization environment and deliver the solution it carries to the user.
The process of deploying virtual devices is shown in the following figure:
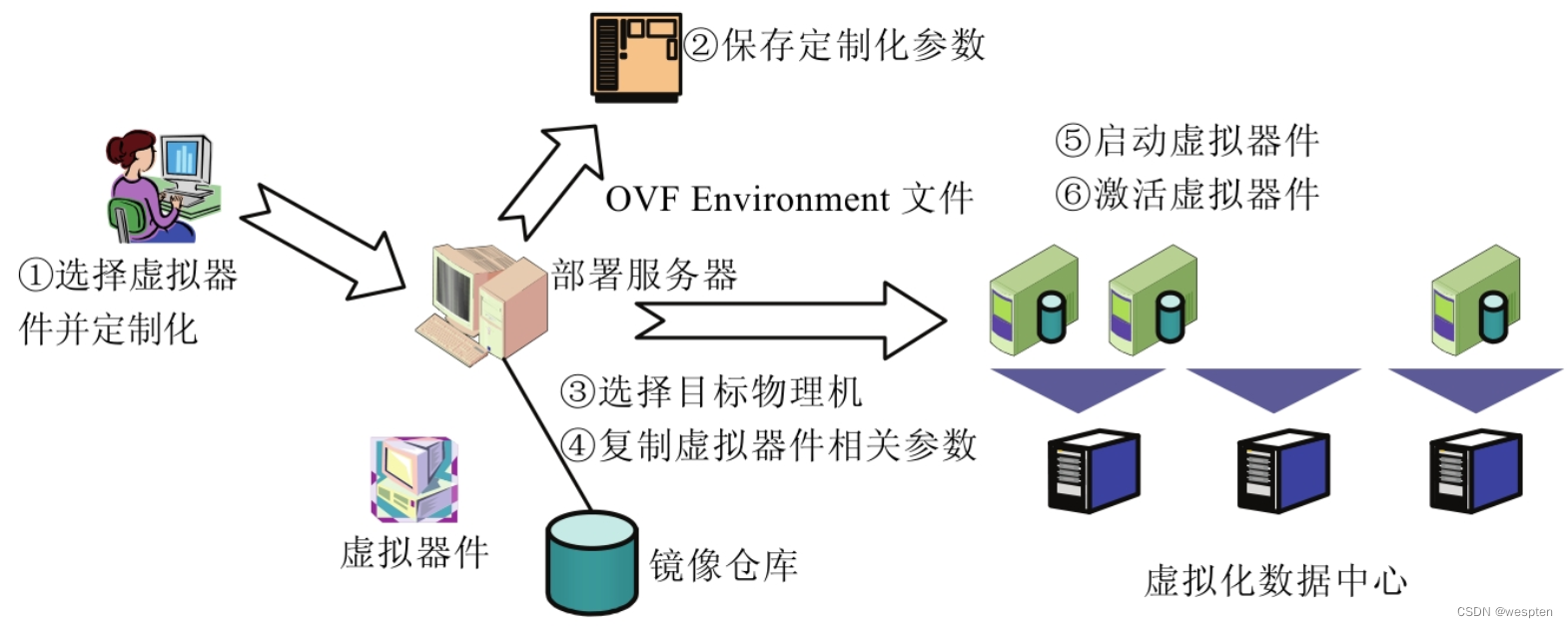
1) Select a virtual device and customize it
Before deploying a virtual device, the user must first select the virtual device to be deployed and input configuration parameters. The parameter information that the user can configure includes the virtual hardware information (CPU and memory, etc.) of the virtual machine, and a small amount of software information.
Software information refers to the configuration related to the virtual machine's internal software stack (operating system, middleware, and application programs), among which network and account-related parameters are essential. Network parameters are important information for connecting each virtual device to form an overall solution, including IP address, subnet mask, DNS server, host name, domain name and port, etc. They can be assigned manually by the user, or automatically assigned by the deployment tool; account parameters mainly include the user name and password of the virtual machine, the user name and password of a certain software, or the user name and password of a certain data source. For security reasons, these parameters generally need to be specified by the user instead of default values.
2) Save the customized parameter file
Generally speaking, the customized information is saved as two files, one file saves the hardware configuration information of the virtual machine, which is called by the virtualization platform to start the virtual machine; the other file saves the software customization information in the virtual device. The virtual machine configuration file is related to the platform of the virtual machine, so it needs to follow the file format specification specified by the manufacturer. As for the software customization information of virtual devices, since each vendor independently developed its own deployment tools in the initial stage of virtualization technology, the ways of saving customized parameters are different. For example, some vendors use text configuration files and others use XML files. At present, major manufacturers will save customized information in the format of OVF environment file.
The OVF environment file defines how the software in the virtual machine interacts with the deployment platform, allowing these software to obtain information related to the deployment platform. For example, user-specified attribute values while the attributes themselves are defined in the OVF file. The OVF environment specification is divided into two parts. That is, the protocol and transmission part. The protocol part defines the format and semantics of the XML document that can be obtained by the software on the virtual machine; the transmission part defines how information is communicated between the virtual machine software and the deployment platform. In general, the description information of the template of the virtual device, the attribute item information that can be configured by the user and the default value of the attribute are described in the OVF file. The customized information filled in by the customer in step 1 is described in the OVF environment file, and the two files are matched by using the name of the attribute as a keyword.
3) Select the target physical machine server for deployment
The target machine needs to meet at least a number of conditions, such as a smooth network, enough disk space to place the virtual image file, physical resources that meet the hardware resource requirements of the virtual machine (sufficient CPU and memory), and a virtualization platform compatible with the format of the virtual device (For example, the Xen platform supports the Xen virtual device and the VMware platform supports the VMware virtual device), and the current deployment tools can automatically check the above conditions.
Specifically, the deployment tool connects to the target server over the network. After the connection is successful, execute the system command to check the CPU, memory, disk space and virtualization platform in the server, and return the information that can be deployed to the user after passing; in addition, some deployment tools can provide more advanced and smarter deployment capabilities, allowing users to A list of servers entered in advance forms a server pool.
When the user chooses to deploy a virtual device, the deployment system automatically selects a server that satisfies the conditions from the server pool as the target machine for deployment according to the above conditions. The deployment tool can also consider the user's customization requirements and deploy the virtual device to a server with a better network, or to a server with better hardware performance, or to a server that does not run other virtual machines, or to consider multiple virtual devices in a solution. virtual devices, and deploy them to the same server or multiple different servers.
4) Copy the relevant files of the virtual device
After the user completes parameter customization and selects the target physical machine, the deployment tool can extract the OVF package of the virtual device selected by the user from the virtual device library, and then copy them together with the OVF environment file and virtual machine configuration file generated in step 2 to the target physical machine.
Mirror streaming is similar to streaming media for online video playback, that is, users can download audio and video files while playing the downloaded part through streaming media technology. The advantage of this is that the user does not need to wait for the entire file to be downloaded and played, which saves time and optimizes user experience. A typical virtual device includes an operating system, middleware, application software, and the remaining space that users need to use. When the user starts the virtual device, he mainly starts its operating system, middleware and application software. These parts only take up a small part of the entire virtual device file. Through the image streaming technology, the virtual machine can be started immediately without downloading the entire virtual device.
In simple terms, when the virtual device is started, the virtual device is transmitted from the image storage server to the virtualization platform through stream transmission, and the virtual device can start the startup process after receiving a part of it. The remaining part of the virtual device can be obtained from the image storage server on demand, thereby reducing the deployment time of the virtual device, so that the total deployment time only takes tens of seconds to a few minutes, and the process of assembling and packaging virtual device files is omitted The overall deployment time can be further shortened.
5) Start the deployed virtual device on the target machine
The deployment tool will execute a set of commands in the target machine through a remote connection to complete the startup of the virtual device. A key point in the startup process is to transfer the software configuration parameter file generated in step 2 to the virtual device.
At present, the method of virtual disk is used to transfer, that is, the OVF environment file is packaged into an ISO image file and a virtual disk configuration item is added to the configuration file of the virtual device, pointing it to the packaged ISO image file. In this way, after the virtual device is started, a disk device can be seen inside the virtual device, in which the OVF environment file is stored. In general, the operations required in this step are to package the OVF environment file into an ISO file, modify the virtual device configuration file to create a virtual disk item, register the virtual device information on the virtual machine management platform, and start the virtual device.
6) Activate the virtual device
The information in the OVF environment file is read inside the virtual device, and the software in the virtual device is customized according to the information. This process is called "activation of the virtual device". According to the automation degree and function of activation, it can be divided into completely manual activation, script-based manual activation, automatic activation of a single virtual device, and coordinated activation of multiple virtual devices that make up the solution.
Completely manual activation is applicable to all virtual devices. Users read the content of the OVF environment file inside the virtual device to determine which software the configuration items belong to, and configure the software according to their own knowledge. Obviously, this scenario has high requirements for users, who are required to understand the format of the OVF environment file, be able to read the content, and have configuration knowledge of various operating systems, middleware, and application software. Even if the user has this knowledge, the activation may fail due to misoperation or abnormal system termination due to the complex configuration process.
Scripting technology can simplify the activation process, and scripts are compiled by creators and publishers of virtual devices. During the activation process, the user only needs to call the configuration script and use the configuration information in the OVF environment file as the input parameter of the script to complete the activation. Users do not need to understand the workflow of activation scripts, nor do they need to have configuration knowledge of various software products. However, this method still has certain requirements for users. First, users need to understand the content of the OVF environment file; second, users need to understand the interface format exposed by the activation script, and pass the corresponding content of the OVF environment file to the script; third, Users need to understand and coordinate the execution process of multiple scripts, because the activation of multiple software may need to follow a certain order during activation.
The working principle of a typical tool for automatically activating a single virtual device is that the activation tool obtains the OVF environment file from the virtual disk during the startup process of the virtual device. Read the parameters in the OVF environment file according to the order of activation, execute the activation script and configure the software in the virtual device, and obtain a customized and available virtual device without user intervention.
This deployment method improves the traditional software installation and deployment method, eliminating those time-consuming and error-prone deployment steps, such as compilation, compatibility and optimized configuration. This method can be fully automated with the support of intelligent management of virtual resource pools, and is very suitable for rapid deployment of software and services in a virtualized environment. At present, the virtual devices developed by many companies have built-in simple activation tools. For example, the IBM activation engine, as an automatic activation tool, has been widely used in the virtual devices released by IBM.
Multiple virtual devices will be combined into a solution, and these virtual devices may have configuration parameter dependencies and activation sequence relationships during the activation process. By implanting an activation tool with network communication functions inside the virtual device, the activation process of the entire solution can be coordinated and the activation of the solution can be completed collaboratively. Of course, this requires the use of the parameter dependencies and activation sequence defined in the existing OVF file.
3. Virtual resource scheduling model, algorithm and process
Resource scheduling is a process of resource adjustment among different resource users according to certain resource usage rules. Different resource users correspond to different computing tasks, and each computing task corresponds to one or more processes in the operating system. The purpose of resource scheduling is to allocate user tasks to appropriate resources, so that the task completion time is as small as possible and the resource utilization rate is as high as possible while meeting user needs.
Resource scheduling ultimately needs to achieve the optimal goals of time span, service quality, load balancing and economic principles. Because the cloud infrastructures of different vendor architectures are different, there is no uniform international standard for resource management and scheduling. Therefore, there are many scheduling algorithms based on various scheduling infrastructures and scheduling models.
1. Resource Scheduling Model
The task scheduling model is divided into application model, computing platform model and performance target model. The application model involves how to divide the application into tasks and how to consider the attributes and characteristics of tasks. Typical task models include dependent task model DAG, independent task model IND and Separable task model DLM.
The computing platform model is an abstraction of resources in the system, the most important of which are processor resources and network resources; performance index models can be divided into two types based on system goals and user-based goals, and system-based performance models focus on the entire system Throughput, resource utilization, efficiency, and fairness, user-based performance indicators include the shortest application completion time, turnaround time, average delay, and weighted completion time.
The resource management scheduling model can be divided into a unified resource agent scheduling model and a multi-resource agent scheduling model according to the relationship between scheduling entities, and can be divided into a centralized scheduling model, a hierarchical scheduling model, and a non-centralized scheduling model according to the organizational scheduling form of resources. In a centralized environment all resources are scheduled by a central scheduler, and information about all available systems is gathered in the central computer. In a hierarchical scheduling model there is a centralized scheduler to which jobs are submitted. While each resource uses an independent scheduler for local scheduling, the main advantage of this structure is that different strategies are used for local and global job scheduling; in a non-centralized system, the distributed scheduler interacts and Submitted to the remote system, the failure of a single component will not affect the entire cloud computing system, with higher fault tolerance and reliability. However, since all parts of a parallel program may be allocated on resources in different domains, different schedulers must synchronize jobs and ensure that they run at the same time, which makes the optimization of the scheduling system quite difficult.
The resource management scheduling model can be divided into hierarchical model, abstract owner model and market economy model according to different architectures. The hierarchical model divides the management system into several functional layers, which is beneficial to the management of resources with site autonomy and underlying heterogeneity. It can realize joint allocation of resources to a certain extent, and has strong applicability.
The abstract owner model uses resource brokers as resource owners to interact and negotiate with users, and follow the ordering and delivery model similar to fast food restaurants in the resource sharing process. The computational economic model combines the core features of the hierarchical model and the abstract owner model. It can not only use the relatively mature technology in the hierarchical model, but also clearly emphasizes resource management and scheduling based on economics. The investment return mechanism based on the principle of supply and demand promotes the improvement of the quality of computing services and the upgrading of resources, and the economy is the most important mechanism to adjust the relationship between supply and demand. It provides a fair price mechanism for users who access grid resources, and allows all resources to be traded. Establish a user-centric rather than system-centric scheduling policy, thus providing an effective mechanism for resource allocation and management.
2. Resource scheduling algorithm
Aiming at different resource scheduling models, many scholars have proposed their own different algorithms. The objective functions based on algorithms typically include time-optimized algorithms, cost-optimized algorithms, and time-cost-optimized algorithms. The starting point of the time optimal algorithm is to complete the task as quickly as possible within the budget, and estimate the completion time of a task for each resource considering the previously assigned tasks and completion rate. And sort the resources in ascending order according to the completion time, and then take the resources out of the queue one by one.
If the task's cost is less than or equal to the task's budget, the task is assigned to this resource. The cost-optimized algorithm tries to complete the task within the completion deadline with the minimum cost. The basic idea is to first sort the resources in ascending order of price, and assign as many tasks as possible to each resource in the queue within the scope of the completion deadline; time cost The optimal algorithm combines the advantages of the above two algorithms to optimize the processing time without adding additional processing costs.
Considering the different scheduling strategies and objective functions of the algorithm, resource scheduling algorithms can be classified according to different standards as follows.
- Traditional scheduling algorithms: such as round robin scheduling, minimum connection scheduling, target address hash scheduling, and source address hash scheduling, etc., are simple in algorithm but poor in performance.
- Heuristic mapping scheduling algorithm: Due to the complexity of resource scheduling factors, heuristic algorithms are usually used. According to the running time of the scheduling algorithm, the heuristic mapping scheduling algorithm can be divided into static mapping and dynamic mapping. Dynamic scheduling algorithms are divided into online mode and batch mode. Typical online mode heuristic algorithms include minimum completion time (Minimum Completion Time, MCT), minimum execution time (Minimum Execution Time, MET), switching algorithm (Switching Algorithm, SA), K-Percent Best Heuristic (KPB) and Opportunistic Load Balancing (OLB), etc.; typical batch mode heuristic algorithms include min-min algorithm, max-min algorithm, fast greedy algorithm, greedy algorithm, endurance algorithm and aging algorithm, etc.
- Scheduling algorithm based on economic model: Based on the commodity market model, pricing model, bargaining model, bidding/contract network model and auction model in economics, it is realized by using objective functions such as optimal cost, optimal time or time cost. Optimal resource scheduling.
- Scheduling algorithm based on intelligent agents: each resource node is encapsulated into an intelligent agent, the resource management system becomes a collection of multi-level intelligent agent systems, and the scheduling problem is simplified as how to match computing tasks among intelligent agents and at any time according to The changes of the intelligent agent should be adjusted, and how to continue to allocate subtasks in the intelligent agent.
- Algorithms based on the nature of tasks and the correlation between tasks: the scheduling algorithms can be divided into independent task scheduling algorithms, separable task scheduling algorithms, dependent task scheduling algorithms, and multi-dimensional QoS requirements and load balancing task scheduling algorithms.
- Resource scheduling algorithm based on game theory: Game theory is an important theoretical method in economics. Due to the similarity between resource allocation and social and economic activities, game theory is also widely used in resource allocation research.
- Other scheduling algorithms: In addition to the resource scheduling algorithms introduced above, there are some improved and comprehensive scheduling algorithms, such as trusted resource scheduling algorithms based on trust models, task-dependent scheduling algorithms, multi-dimensional QoS requirement scheduling algorithms, and load-balanced scheduling Algorithms and resource scheduling algorithms based on energy consumption, etc.
The cloud resource scheduling algorithm can learn from the research results in grid computing and distributed computing, and pay attention to the characteristics of cloud computing resource scheduling. The characteristics of cloud data center resource scheduling are resource virtualization and user-oriented scheduling performance optimization. The emergence of virtual machines enables all computing tasks to be encapsulated inside a virtual machine.
Due to the isolation of the virtual machine, the dynamic migration technology of the virtual machine can be used to complete the migration of computing tasks and realize resource optimization. In a traditional distributed computing environment, resources are free, and the optimal overall performance of the system is often the optimization goal of scheduling; in a cloud computing environment, cloud service providers provide resources and services, and users pay on demand. That is, you only need to pay for the resources or services used, so the scheduling problem in the cloud environment must consider the cost constraints of task execution.
In addition, cost-related factors such as task completion time, compensation rate and user payment are also important constraints that need to be considered in cloud computing scheduling problems. In the traditional distributed environment, the optimization goals of scheduling are system-centric and mainly oriented to system performance, such as system throughput and CPU utilization, while less consideration is given to users' QoS requirements. In the cloud computing environment, it not only pays attention to the improvement of resource utilization and system performance, but also pays attention to ensuring the QoS requirements of users, so as to realize the win-win situation of resource supply and resource consumption.
3. Abstract relationship and general steps of resource scheduling
For cloud computing, resource scheduling is a very important component. The resources of different clouds are different, and the corresponding scheduling policies are also different. How to design a relatively common framework for these different scheduling, so that different clouds can define their own policies and behaviors according to their own needs is the difficulty of cloud computing resource scheduling.
A common resource management system generally consists of a resource consumer interface, a resource provider interface, a resource manager support interface, and a peer interface, as shown in the following figure.
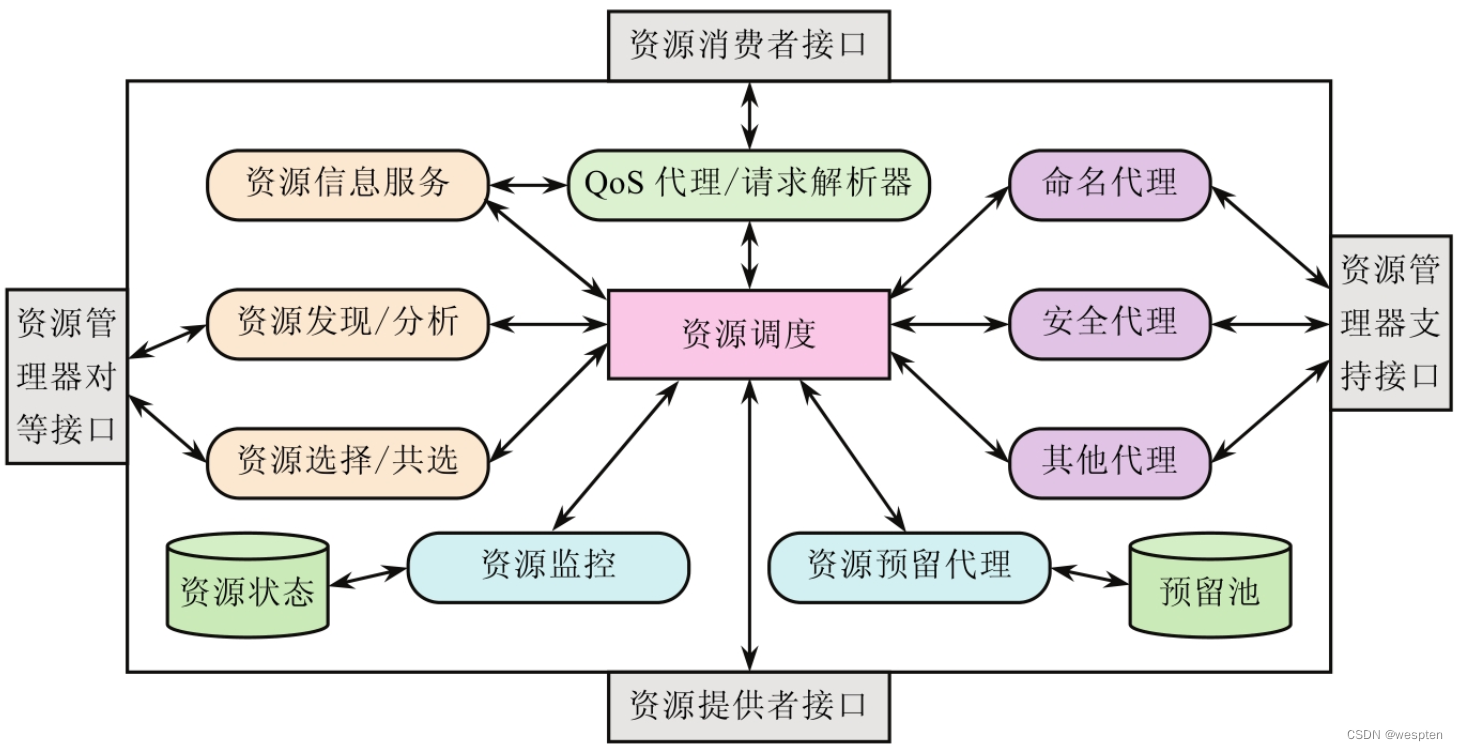
In grid computing and cloud computing, the resource scheduling system is the core, and its basic function is to receive resource requests, and then allocate resources that meet the requirements from the resource pool or cloud to the requester. Resource scheduling generally includes the following four steps.
- Resource request: The resource consumer submits the requested resource requirement information to the resource management system. The resource requirement information is composed of multiple component elements. In virtualization-based cloud computing products, each component is a resource of a virtual machine or a physical machine. A collection of description information.
- Resource detection: search for resources according to certain requirements, and obtain a list of all eligible resources through detection. Resource detection mainly involves three aspects: resource information storage format, resource release (transfer) method, and resource discovery method.
- Resource selection: select the optimal resource from the candidate resource list according to the resource selection strategy, and allocate the resource to the requester. Resource selection includes two aspects. One is to define the objective of selection optimization (utility function), which is the criterion for evaluating candidate resources; the other is to choose an appropriate algorithm, which can select the optimal resource from candidate resources according to the utility function. resource.
- Resource monitoring: The final stage of resource management is to deliver the selected optimal resources to resource requesters and monitor the resources. When the resource is abnormal, it can be reassigned to the requester resource to ensure the availability of the resource to the requester; after the resource is used, cleanup work should be performed to recover the resource, such as deleting the virtual machine file.
4. System architecture and engine design of virtualized resource management directory
1. The overall design idea of resource directory service
The system architecture design of the virtual resource management directory follows the following ideas.
- Strict hierarchical relationship: the system implements strict stratification, and stratification can continue within each layer.
- Top-down and progressive refinement: Design and implement from the top of the system to the bottom.
- Virtual implementation: When the upper layer is implemented, it is assumed that the lower layers it depends on have been implemented, but in order to keep the system running, only "empty" implementations are given for the lower layer functions that have not been realized, and they are asked to directly return the predetermined test data or directly return to the operation status flags.
2. Overall system architecture design
System architecture refers to the internal structure of the system, that is, the implementation structure above the system's algorithm and basic data structure. The architecture is transparent to the user and determines the performance of the system.
The following figure shows the overall architecture design of the system:
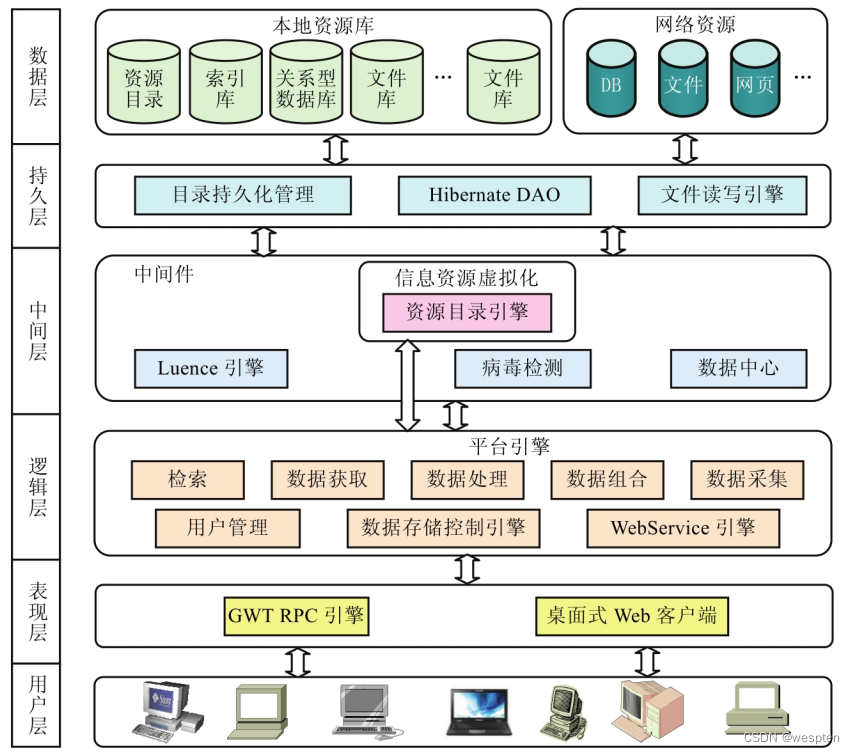
The system architecture design diagram is divided into 6 parts, from the bottom layer to the high layer is divided into data layer, persistence layer, middle layer, logic layer, presentation layer and user layer.
1) Data layer
The data storage layer of the system includes local data and network data. Local data includes system logs, resource directories, server-type databases and file libraries, etc.; network data includes all structured, semi-structured and unstructured information resources.
- Server-type databases store structured data and system data tables. Structured data includes format data collected by various institutions, such as data on regions, industries, indicators, and time; system data tables include user data tables and user personalized record tables.
- Since content management accounts for the majority in the resource information management system, the load pressure on file libraries is relatively high, so multiple file libraries are used to store content. That is to realize sub-library storage and reduce the load pressure of each file library; in addition, there are resource directory libraries and log file libraries. The resource directory uses eXtensible Markup Language (eXtensible Markup Language, XML) file storage to realize the platform independence of the resource directory , can be plug and play.
2) Persistence layer
Including resource directory persistence manager, Hibernate data access object (Data Access Objects, DAO) and file read and write engine, etc.
- Resource Directory Persistence Manager: Persist and read resource directories, using XML as the storage format of resource directories. The XML-based feature maximizes the support for hot plugging of resource directories, making it possible to synchronize heterogeneous resource directories. In addition, the cost of resource directory exchange on heterogeneous platforms is minimized, and resources can be connected to another heterogeneous platform without any modification.
- Hibernate DAO: used for persistence of relational databases and supports access to structured data. And it has good flexibility, scalability, platform independence and configurability, and is in line with plug-in features. Information resources include relational database resources, and the persistence and access of these resources depend on this DAO; at the same time, the system provides functions such as user management, interface plate customization, flow review and user functions. The data of these functions are all stored in the relational database, and the persistence and access to these data all depend on this DAO, and the engine that operates this DAO may include a data acquisition engine, a data processing engine, a data combination engine, a data acquisition engine and a data acquisition engine. center etc.
- File reading and writing engine: used for the persistence of content resources, which belongs to the calling engine; at the same time, it is responsible for dynamically evaluating the load of the file library to achieve load balancing of each file library.
3) Middle layer
Including resource directory engine, Luence (an open source search engine framework, originally Java version, .net, C++ and Pascal and other languages have corresponding versions) search engine, virus detection and data center, etc.
- Resource directory engine: It is a server-type engine that provides services such as inserting, updating, deleting, reading, importing, and exporting resource directories. This is a key module of this system, which can provide indexing of resources and provide services such as security, version control, pipeline and locking. The core of the resource directory engine is the resource directory tree, and it provides a series of functional interfaces for operating the directory tree, and provides directory services for the information resource directory platform.
- Luence search engine: provides services for resource full-text search, and it cooperates with the resource directory engine. The resource directory is the data source of the Luence search engine, and the engine updates the index library according to changes in the resource directory. In order to realize the full-text search, it is necessary to segment the resource content, and build an index after obtaining the keywords.
- In order to prevent the resource library from being invaded by malicious viruses, it is necessary to perform virus detection on the stored resource content. The virus detection layer appears as a middleware to provide virus detection service in the middle layer, which belongs to the calling server.
- Data center: In the server-type database, the data in various institutions or centralized servers is not synchronized. In many cases, it is necessary to synchronize the server-type databases of each institution in order to perform comprehensive analysis and other operations on the data; at the same time, due to the server platforms used by each institution, Web servers, server databases, and data tables are not guaranteed to be isomorphic, and the problem of synchronizing heterogeneous database tables needs to be solved. Therefore, the data center is responsible for the synchronization and data exchange of heterogeneous databases.
4) Logic layer
Including user management, retrieval, data acquisition, data processing, data combination, data acquisition, data storage control engine and Web Service engine and other modules, called "information resource directory platform engine".
- User management: including user rights management and system access control management, realizing single sign-on, multi-system shared login, and page function authority control to resource node level authority control.
- Retrieval: including full-text search, professional search and secondary search, etc. Full-text search is a general general search; professional search realizes the customization of search conditions.
- Data acquisition: including reading resource directories, resource content and log files, etc., encapsulating resource data to make it transparent to application services.
- Data processing: The main abstract operations include transformation, cleaning, screening, updating, synchronization, replacement, storage, and data classification (according to the Chinese library method, statistical yearbook method and custom classification method, etc.).
- Data combination: Reorganize, merge and multi-dimensionally process the data in the resource pool according to the strategy, and form new data resources in the resource pool.
- Data collection: Collect external data into the system according to the strategy, including Web and local information resource collection. Web collection automatically downloads Web pages to the system by defining a certain strategy.
- Data access control engine: receives operation instructions for the use portal of each functional module, and schedules relevant modules to perform corresponding operations; at the same time, it is responsible for the maintenance of the entire buffer pool and the life cycle management of each functional module. Resource content may be local or network, and may be structured, semi-structured or unstructured data, etc. For this reason, the engine shields the path differences of information resource content outward, and provides a consistent read and write interface; internally, it assigns and pulls resource content according to the path of information resource content.
- Web Service Engine: The open Web Service-oriented interface of the information resource directory platform engine provides support for remote access. The information resource directory platform integrates applications such as resource access control, resource access, resource combination, resource processing, resource collection, and resource cleaning. . In order to meet the growing and diversified needs of users for network services, it is necessary to provide Web Service support for the platform engine. That is to provide a cross-platform and programming language-independent method to support communication between systems, so it is necessary to provide a Web Service access interface for the platform engine, that is, the Web Service engine.
5) Presentation layer
Including window-style Web client and Google World Wide Web Toolkit (Google Web Toolkit, GWT) remote processing call (Remote Procedure Call, RPC) engine.
- The windowed Web client provides an interactive interface similar to Windows Explorer, with better user experience.
- The GWT RPC engine provides a rich interface of AJAX remote call for communication between the fat client and the server. All data communication of the Web client of this system will realize the transmission of uplink and downlink data through these interfaces.
3. Engine design
The information resource directory platform includes a variety of applications for information resource management, such as acquisition, combination, processing, collection, cleaning and screening applications. In order to integrate these applications to provide services for remote users, a loosely coupled and platform-independent framework is needed to manage these services. The platform engine based on Service-Oriented Architecture (SOA) system can provide remote users with commands and data Serve.
1) Engine architecture based on Web Service
Web Services-based application integration is currently the most advanced method of enterprise application integration. It can provide access methods through Internet distributed servers or central servers. Enterprises and users can discover, describe and use through standard interfaces and some public services. These shared series of services.
Web Service is an implementation technology of SOA. Here, Web Service is used to realize the integration and loose coupling of enterprise applications in the Internet environment. According to the Universal Description Discovery and Integration (UDDI) standard, the Web Services standard uses names and directories to locate services and describe them using the WSDL language specification, and these message objects use the Simple Object Access Protocol SOAP.
For the original application of the system, the architecture based on Web Services only needs to add a SOAP interface on the basis of the original system without modifying the original system and without affecting the original application. System interconnection realized by different technologies provides mutual data exchange and access operations, and various systems can cooperate with each other to form a more powerful system.
The following figure shows the structure of the information resource virtualization management engine:
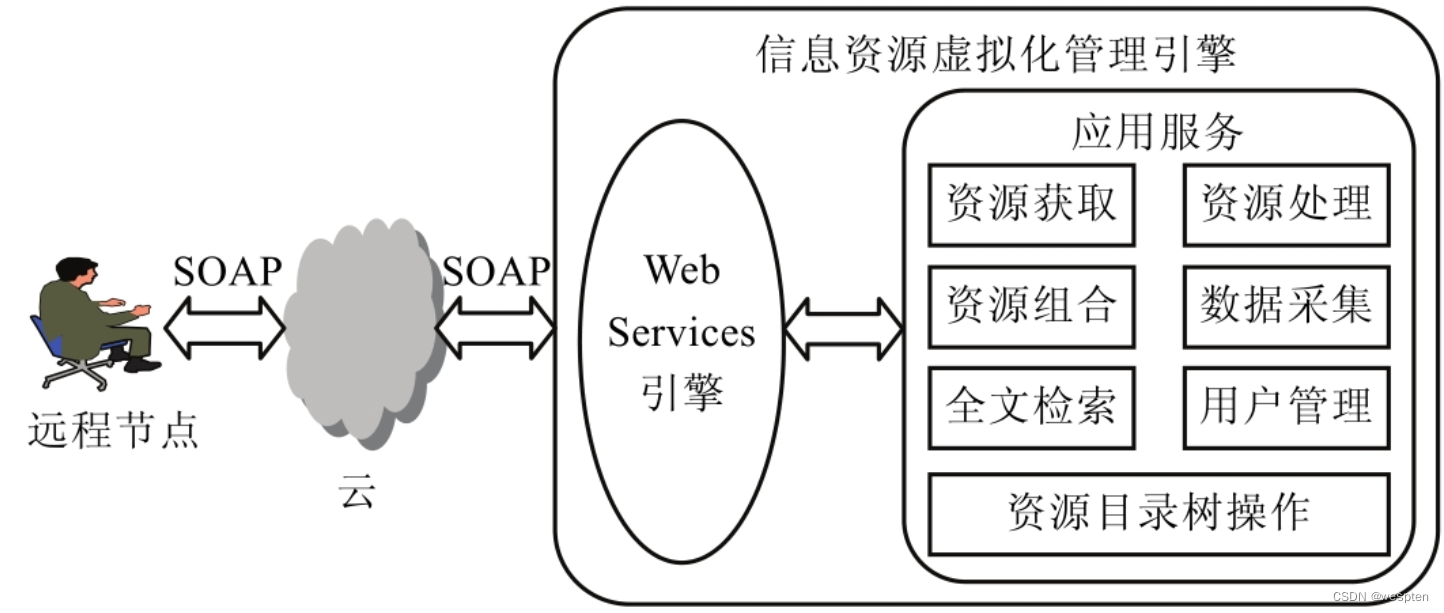
2) Protocol specification
In the engine framework based on Web Services, various access items need to be supported between engines, such as login, logout, access to directories, list subdirectories and resources under the current working directory, create directories, delete directories, write resources, query resources, Update resources, delete resources, and import, export, help, etc.
When designing, it is necessary to design command names, options and related parameters that are easy to understand, and will not be detailed here.
5. Typical virtual resource manager framework
According to the characteristics and requirements of virtual resource management, the description of virtual resources is more difficult and complicated than that of traditional physical resources. Ontology is a theory about existence, essence and law, and its purpose is to acquire knowledge in the field and achieve a common understanding of knowledge or concepts in the field. And determine the unity of vocabulary in the field, and give a clear definition of the relationship between vocabulary from different levels of formalization and standardization. Therefore, the ontology-based resource virtualization method is used to analyze the case below.
To realize the rational use of virtual resources, we must first be able to manage resources. In order to effectively manage virtual resources, it is necessary to establish a corresponding virtual resource manager, as shown in the following figure is the established virtual resource manager framework.
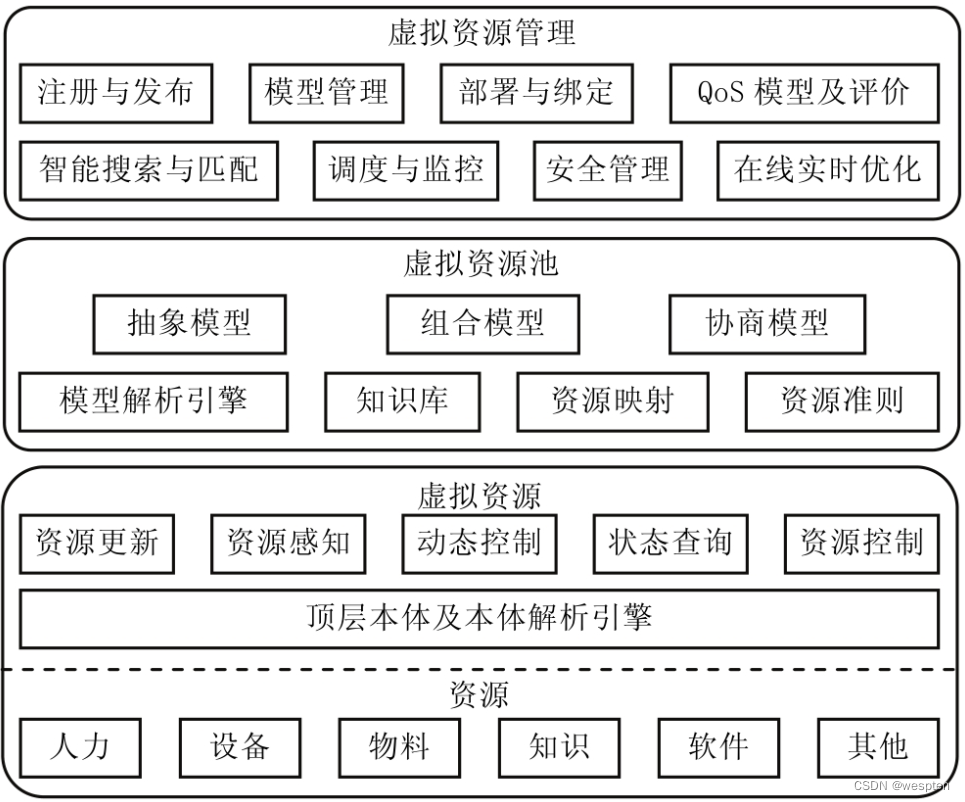
The virtual resource manager mainly includes three layers, namely the virtual resource layer, the virtual resource pool layer and the virtual resource management layer.
The following will be explained respectively:
1. Virtual resource layer
On the basis of real resources, the aforementioned methods are used to realize the virtualization and encapsulation of resources, and the ontology analysis engine can update, perceive and query the information and status of virtual resources, and monitor and dynamically control resources in real time.
2. Virtual resource pool
Including virtual resource abstract model, virtual resource combination model, virtual resource negotiation model, and corresponding model analysis engine, knowledge base, resource mapping and resource criterion, etc. Establishing a virtual resource pool requires defining a mapping relationship between physical and virtual resources to construct a set of virtual resource mapping models.
The mapping relationship between physical resources and virtual resources can be divided into three basic types. One is one-to-one mapping, which belongs to the most basic resource mapping relationship. For example, a physical device with a single function can only be mapped to a virtual device; the other is One-to-many mapping, suitable for physical resources with multiple functions. A single function can be mapped as an independent virtual resource, for example, a software tool with multiple functional modules can be mapped as multiple virtual software tools. The third is many-to-one mapping, which mainly maps multiple physical resource elements into a virtual resource according to certain logical relationships and constraints for the combination and coordination of multiple physical resources.
For example, for the simulation calculation tasks of complex products, high-performance computing system resources are often required, and storage resources, computing resources, and simulation software can be combined and mapped into a virtual machine; for physical resource combinations with logical relationships, it can be Combine the functional interfaces of multiple product software tools into a virtual design software, and the combined process logic, constraints and collaboration rules need to be defined at the same time.
3. Virtual resource management layer
It mainly provides corresponding functions for virtual resource users, including virtual resource encapsulation, registration/release management, model management, deployment and binding, QoS model and evaluation management, intelligent search and matching management, scheduling and monitoring management, and security management and online real-time dynamic optimization management, etc. Encapsulation/registration/release management is used for the encapsulation of virtual resources, as well as the registration and release management in the virtual resource pool directory.
Model management is used to manage the mapping model between physical and virtual resources, as well as the abstract description template of virtual resources. Before the cloud service needs to call specific resources, the virtual resource template needs to be instantiated according to the mapping model, and the deployment and deployment of the operating environment must be completed. bound.
QoS model and evaluation management are used for model management of service quality of virtual resources and physical resources, and evaluation of various indicators. Intelligent search and matching management is used to find and obtain a suitable virtual resource template or virtual resource instance from the virtual resource pool according to the resource requirements of cloud services. Scheduling and monitoring management is used for resource status acquisition, event notification, task scheduling, and resource monitoring and control management. Security management is used for the management of user authentication, access control and security audit of the virtual resource pool. Online real-time dynamic optimization management is used for the management of multi-objective multi-constraint optimal scheduling, dynamic replacement of resource combinations, load balancing, and fault-tolerant migration.
Based on the virtual resource manager, the virtual resource search and scheduling process based on ontology description can be realized, as shown in the following figure.
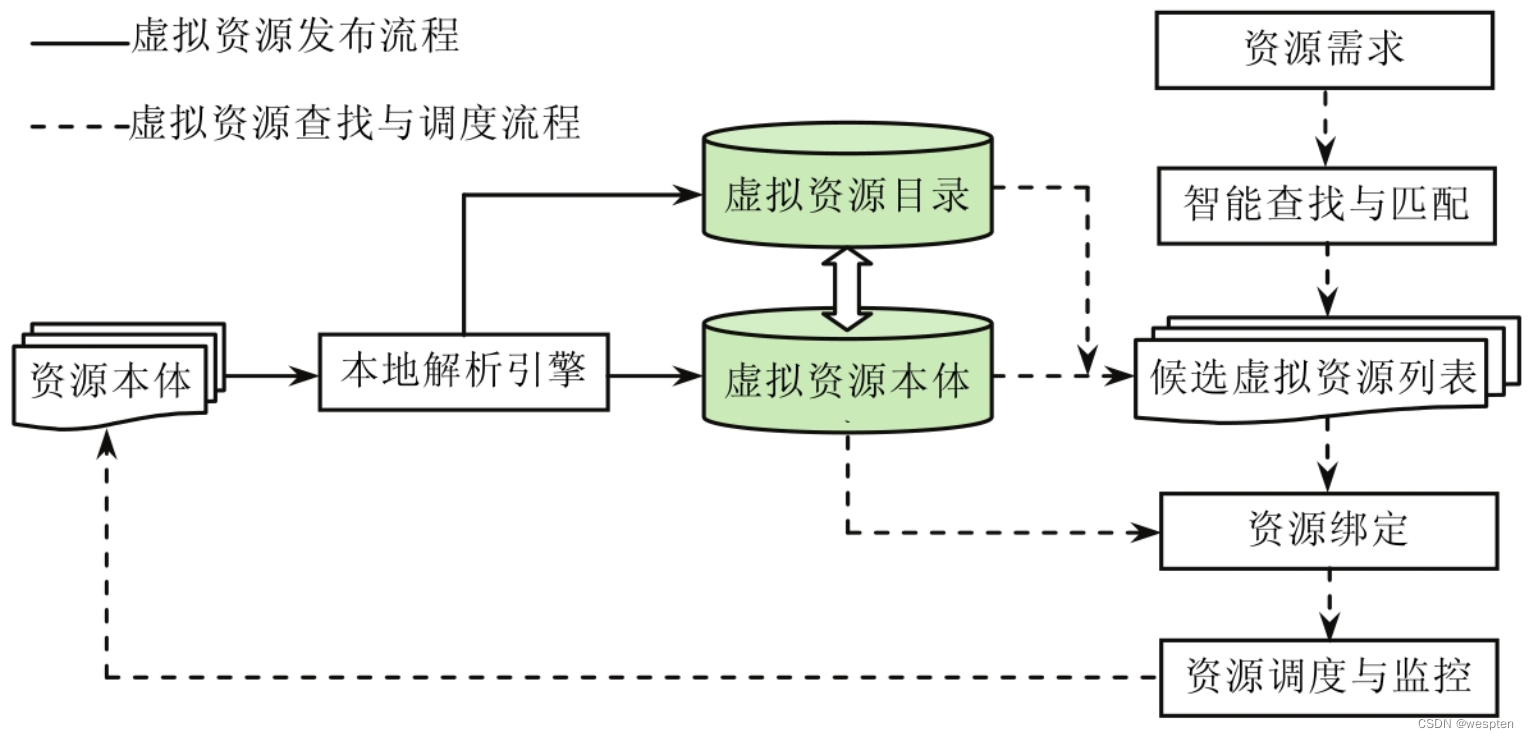
The process is mainly divided into two parts: the virtual resource release process and the virtual resource search and scheduling process, which are described in detail as follows.
- The resource provider describes the resources as resource ontology according to the top-level ontology mapping rules and submits the resource ontology to the virtual resource management by using the resource registration and publishing functions.
- The resource ontology is then parsed by the ontology parsing engine in the system according to the top-level ontology mapping rules. Here, the ontology language for services (Web Ontology Language for Services, OWL-S) parsing engine is used. After parsing, it enters the virtual resource ontology library.
- In order to ensure that virtual resources can be retrieved accurately, the analyzed ontology will also add corresponding virtual resource information in the virtual resource directory, mainly including basic information such as virtual resource ID, name, and attribute. So far, the virtual resource ontology library and virtual resource directory have been formed, and the release process and corresponding review process of virtual resources have been completed.
- Virtual resource users describe resource attributes, functions and non-functions and other use requirement information in a format that the system can parse and submit it to the virtual resource manager.
- After receiving the virtual resource requirements, the virtual resource manager will call the intelligent search and matching function to find resources, which is one of the core functions of the virtual resource manager. Match the description information of the resources in the virtual resource directory with the requirements through ontology-based similarity, including basic attributes, classifications, functions, input and output preconditions and effects (Input Output Precondition Effect, IOPE) matching, etc., and the corresponding matching algorithms include Text matching, fuzzy function matching, hierarchical analysis matching and structure tree matching algorithms, etc. After similarity comparison, a list of candidate virtual resources that usually can only meet functional requirements is obtained. However, non-functional requirements, such as QoS requirements, have not been considered, so the intelligent search and matching function further performs non-functional matching on the previous candidate virtual resource list. By comparing the virtual resources in the virtual resource ontology library, including non-functional descriptions such as QoS and SLA, with the requirements, a list of candidate virtual resources that meets both functional and non-functional requirements of the user is finally obtained and returned to the user.
- There may be more than one list of candidate virtual resources obtained through automatic intelligent search and matching by the system. Therefore, in addition to considering the default virtual resources, users can also manually select according to their own needs. After determining the selected resources, obtain the corresponding resource binding information from the virtual resource ontology library, and bind the requirements or tasks to specific physical resources to realize the requirements or complete the tasks.
- After the resource binding is completed, the system transmits the task or demand information to the real physical resources, and the real resources complete the task.
- Real resources can complete the task with the agreed service level after receiving the resource requirements or tasks, and must accept the corresponding resource monitoring during the use process. Information such as resource use process and resource status and capabilities after use may change, and the changed information will be re-described as ontology information, and the virtual resource directory and virtual resource ontology information will be updated. The application case of virtual resource search and scheduling based on ontology description verifies that the proposed resource virtualization method can meet the requirements.
The above work only considered the virtualization description of a single resource. In fact, there is a corresponding combination relationship between virtual resources in the cloud manufacturing environment. Therefore, how to use the ontology model proposed in this section to describe the virtual resources after combination, and how to use The above-mentioned resource model to realize the automatic aggregation of virtual resources according to the characteristics of tasks and make the search and matching of virtual resources more efficient are all problems to be solved in the next step.
In terms of virtual resource management, the main contents to be further studied in the future are as follows.
- Multi-stage dynamic resource allocation: Since users can use cloud resources in multiple ways such as resource reservation and pay-as-you-go, the implementation of data center resource provision will be divided into different stages. And because the demand for resources is uncertain, it is necessary to consider how to improve the revenue and resource utilization of the cloud data center under the dynamic uncertainty of user demand.
- QoS constraints: The diversity of cloud applications makes cloud users have different requirements for QoS. It is necessary to provide users with cloud application services with different SLAs and establish SLA measurement, monitoring and punishment mechanisms to ensure that users' QoS requirements are met.
- Resource allocation of multiple data centers: By combining data centers of multiple different manufacturers and enterprises, a larger dynamic scaling resource pool can be established to expand the provision of resources.