Light up ⭐️ Star · Light up the road to open source
GitHub:https://github.com/apache/dolphinscheduler

Wonderful review
Recently, Shan Geyao, the data platform engineer of Shixing Fresh, shared a speech on the community online Meetup with the theme "The Implementation of Apache Dolphinscheduler in Shixing Fresh".
With the further development of big data, both offline tasks and real-time tasks are becoming more and more, and the requirements for the scheduling system are getting higher and higher.
Apache Dolphinscheduler is a very popular and easy-to-use scheduling system. First of all it is distributed and decentralized, and secondly it has a very nice page that makes scheduling tasks very easy to get started with.
Instructors

Shan Geyao
Shixing Fresh Data Platform Engineer
Article finishing: Shuopan Technology - Liu Bulong
Today's talk will focus on the following three points:
-
Background introduction
-
Implementation
-
Metadata system Datahub integrated with Dolphinscheduler
Background introduction
Our company Shixing Fresh is a new retail enterprise that adopts the "reservation system" model and provides users with high-quality fresh food services through the whole process of cold chain distribution and the self-pickup method of community smart freezers.
With the development of the business, a large number of offline synchronization and computing tasks began to challenge the usability and stability of our data architecture.
01 Data Architecture
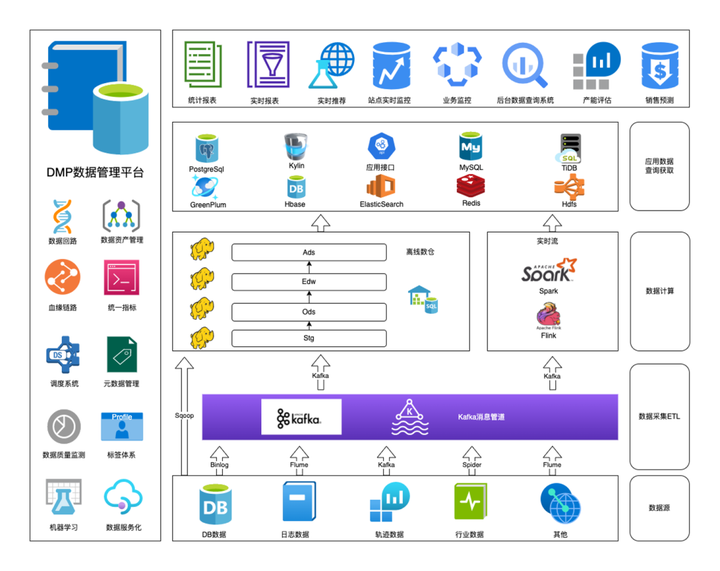
The picture above is our current infrastructure system, mainly batch and stream processing. Batch processing is mainly based on the hierarchical calculation of the full number of warehouses based on Hive and Spark. Stream processing is mainly based on Flink, which is mainly used for real-time ETL and real-time business monitoring of user trajectories. Currently, the open source giant whale platform of Meiyou is used, and it will be migrated to StreamPark, a new Apache project. A series of out-of-the-box connectors greatly reduce the complexity of developing and deploying real-time tasks.
Our data sources include MySQL, PostgreSQL, SQL Server data on the logistics supply chain, peer data and risk control data. The corresponding log data is very large and complex, so the data types are also varied.
There are two types of business entities: the data generated by the business , such as the user's order, the user's various balances, and coupons; the track data of the tracking system, such as the user's click, order, Enter product details and other behavioral trajectory operations;
Generally speaking, the data of T+1 is calculated offline, and the trajectory data is calculated in real time.
The number extraction tool is mainly Sqoop, followed by binlog consumption. For some unsupported data sources , Apache SeaTunnel is used.
After the complex calculation of the data warehouse, the OLAP scenarios of our downstream data are mainly TiDB and GreenPlum.
TiDB is used for business queries , such as querying the purchase volume of a product in the past 7 days;
GreenPlum is mainly based on internal Kanban boards . For example, the core financial indicators of the group, the operational results and performance indicators of the operation department; in addition, HBase will be used to store some dimensions, and ElasticSearch will store the portrait results trained by some algorithm models.
**Kylin is used in the indicator system. **It serves our internal indicator calculation. For example, the monitoring of site status shows various dimensions of business results. For example, in today's real-time order situation, whether it is necessary to send more manpower to the supply chain, and whether there is a sharp increase in the data flow of recent orders, etc., so as to adjust the sales strategy.
02 Capability and composition of DMP
With the growing number of tasks, the management of data assets and the monitoring of data quality are becoming more and more serious, and the demand for DMP (Data Management Platform) emerges as the times require.
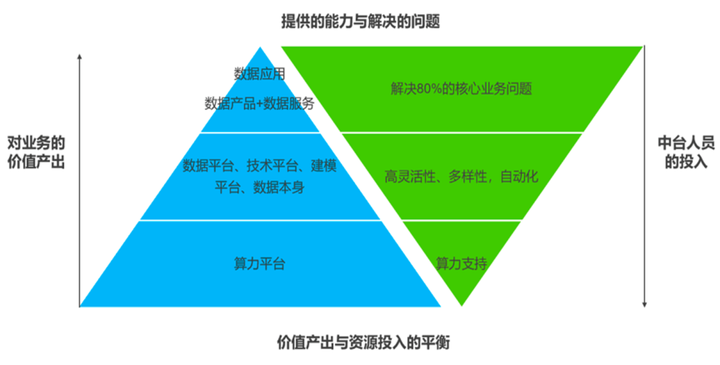
In general, DMP derives data applications that include the following capabilities:
**Decision support categories: **Thematic reports (monthly/quarterly/yearly/special topics), public opinion monitoring, hot spot discovery, large-screen data visualization display, etc.;
**Data analysis:**Interactive business intelligence, OLAP analysis, data mining, data-driven machine learning, etc.;
**Data retrieval category:**Full text retrieval, log analysis, data lineage analysis, data map, etc.;
**User related: **User portrait service, user growth/churn analysis and prediction, CTR prediction, intelligent recommendation, etc.;
**Market related: **Data serves search engines, data serves recommendation engines, hot spot discovery, public opinion monitoring, etc.;
** Manufacturing production related: ** Predictive maintenance, real-time data monitoring of production process, digital twin, etc.;
Implementation
The growing business system data has created high availability requirements for the scheduling system, and the original self-developed single-node scheduling system is no longer suitable for our current business volume.
We began to investigate new scheduling tools on the market. However, we not only need the scheduling system to be distributed and highly available , but also easy to use, provide a friendly interactive experience for analysts without programming experience , and support high- end developers. Scalability , it is convenient to expand the supported task types and cluster scale as the business grows.
01 Choose Apache DolphinScheduler
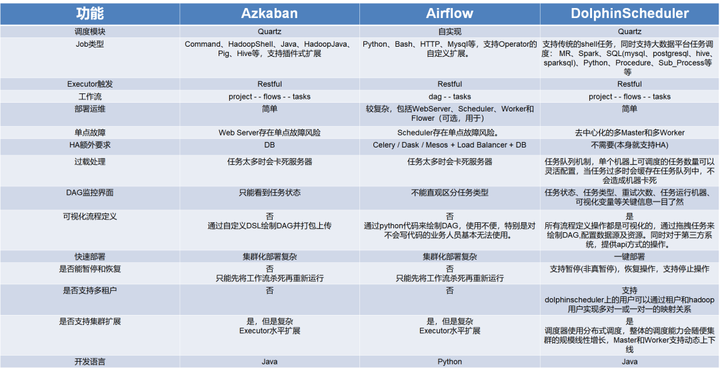
In the end, we chose Dolphin Scheduling , but we have experienced the migration of several tools for the development of our scheduling system.
At first, Azkaban was used. Due to some historical reasons, Azkaban was subsequently abandoned. Then, a scheduling system was developed by itself. With the surge of business data, a fatal problem in the self-developed system: the system is a single-point type. , there is no way to expand resources, only stand-alone operation ;
Last June, we did a survey on AirFlow and Dolphinscheduler. In the face of business scenarios, we hope to define flow in the form of SQL; we hope that the system will run in a distributed form instead of a single machine, so as to solve the bottleneck problem of a single machine;
AirFlow's technology stack is Python, and the company is mainly Java;
After a comparison, we finally settled on Dolphinscheduler.
02 Implementation
In June last year, the 1.3.6 version of DolphinScheduler was connected to the production environment for the first time . After business tempering and community co-construction, it has been successfully updated to 3.0.0. So far, it has served our company for more than a year, with an average daily stability . Run 6000+ tasks .
03 Task execution
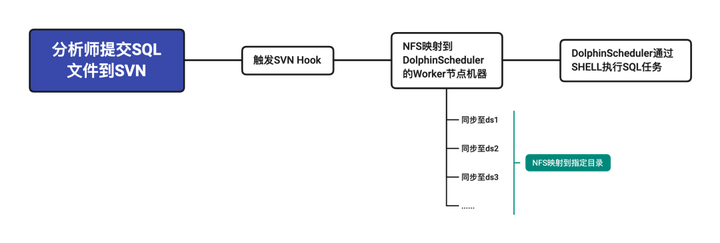
When we use DolphinScheduler, we mainly use its Shell component, which encapsulates Hadoop related Tools internally, is used to submit related SQL through Shell, and specifies the Yarn resource queue for task submission.
We have also created five corresponding Yarn resource queues according to the five priorities HIGHEST, HIGH, MEDIUM, LOW, and LOWEST within DolphinScheduler, which are convenient to submit to the specified priority queue according to the priority of the process, so as to better utilize and resource allocation.
In the waiting queue of the original Worker thread pool, the PriorityBlockingQueue is converted from the original LinkedBlockingQueue, so that the exec-threads of the super Worker can be reordered according to the priority set, so that the high-priority task can be reordered when an exception occurs. The "queue cut" effect can be achieved when the resources are full .
04 Alert Policy
DolphinScheduler provides various alerting components out of the box.
-
Email alert notification
-
DingTalk DingTalk group chat robot alarms, and related parameter configuration can refer to DingTalk robot documentation.
-
EnterpriseWeChat Enterprise WeChat alarm notification related parameter configuration can refer to the enterprise WeChat robot documentation.
-
Script We have implemented the shell script alarm, and transparently transmit the relevant alarm parameters to the script, and implement the relevant alarm logic in the shell. If you need to connect to the internal alarm application, this is a good method.
-
FeiShu Feishu Alert Notification
-
Slack Slack alert notification
-
PagerDuty PagerDuty Alert Notification
-
WebexTeams WebexTeams alarm notification related parameter configuration can refer to WebexTeams documentation.
-
Telegram Telegram alarm notification related parameter configuration can refer to the Telegram documentation.
-
HTTP Http alarm, calling most of the alarm plug-ins is ultimately an Http request. According to the design of Alert SPI, two plug-ins are extended for it: internal OA notification + Aliyun phone alarm to ensure the availability of services and the timeliness of data output. The Alert SPI design of DolphinScheduler is quite excellent. When we add plugins, we only need to focus on extending org.apache.dolphinscheduler.alert.api.AlertChannelFactory. In addition, DolphinScheduler has a wide range of alarm coverage scenarios . The timeout period can be set according to the usual completion time of the workflow and tasks. Combined with the new data quality module, the timeliness and accuracy of the data can be better guaranteed.
Metadata system Datahub integrated with Dolphinscheduler
Open sourced by LinkedIn, Datahub was originally called WhereHows. After a period of development, Datahub was open sourced on Github in February 2020. First, let’s briefly introduce the Datahub system.
01 Overall Architecture
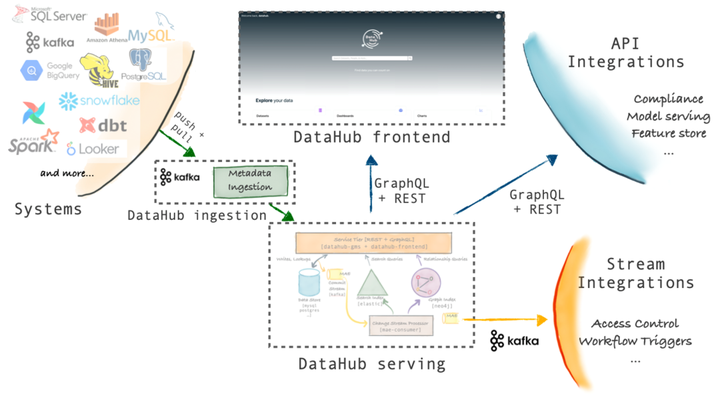
DataHub is a modern data catalog designed for end-to-end data discovery, data observability, and data governance.
This extensible metadata platform is built for developers to address the complexities of their rapidly evolving data ecosystems and to allow data practitioners to fully leverage the value of data within their organizations.
02 Search metadata
DataHub's unified-search supports displaying results across databases, data lakes, BI platforms, ML functional stores, orchestration tools, and more.
The supported sources are quite rich, as of v0.8.45
Airflow、Spark、Great Expectations、Protobuf Schemas、Athena、Azure AD、BigQuery、Business Glossary.ClickHouse.csv、dbt、Delta Lake、Druid、ElasticSearch.Feast、FileBased Lineage、File、Glue.SAP HANA、Hive、lceberg.Kafka Connect、Kafka、LDAP、Looker、MariaDB、Metabase、Mode、MongoDB、MicrosoftsQLServer、MySQL、Nifi、Okta、OpenAPI、Oracle,Postgres、PowerBl、Presto onHive、Pulsar、Redash.Redshift、S3 Data Lake.SageMaker、Salesforce、Snowflake、Other SQLAlchemydatabases、Superset.Tableau、Trino、Vertica等。
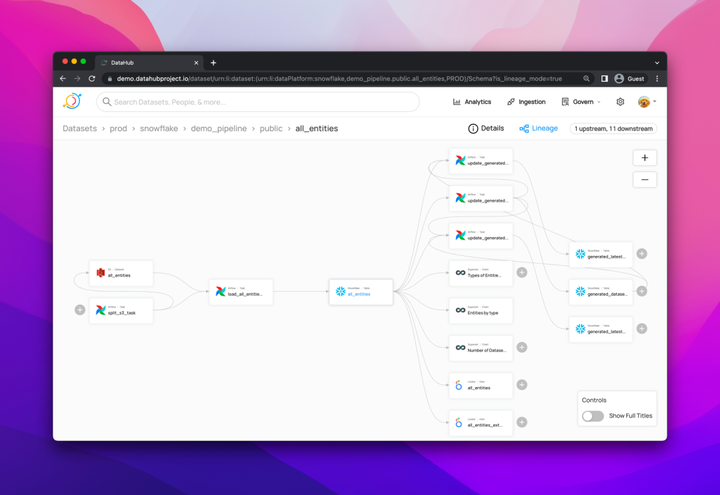
03 Blood support
Track bloodlines across platforms, datasets, ETL/ELT pipelines, charts, dashboards, etc., and quickly understand the end-to-end flow of data.
Unlike other metadata systems on the market, Datahub has always supported the tracking of the entire flow from dataset to B Kanban, and has provided us with metadata access to open source Kanban boards such as Redash and SuperSet .
04 Extraction steps of metadata
**The first step:** Enable the permission to collect metadata and create keys;
**Step 2:**Select the data source of the ingested bloodline (in addition to the currently supported ones, customization is also supported);

**Step 3:** Configure the bloodline collection table and downstream direction;
**Step 4:** Set the time zone and timing, the metadata collection will be like our scheduling system, and the collection will be completed by timing calls.
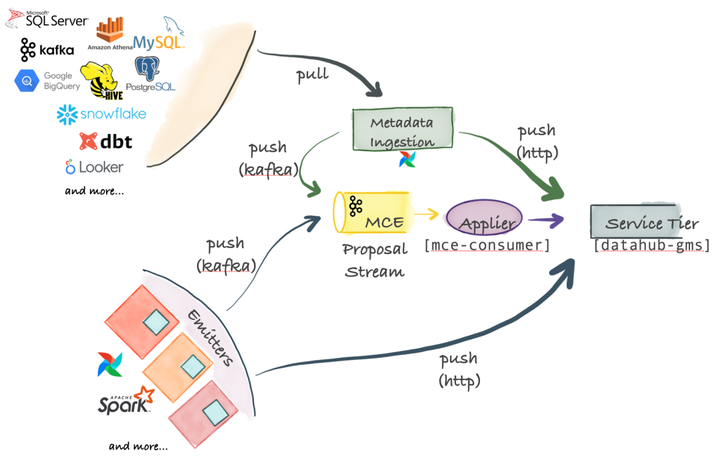
05 Metadata Ingestion Architecture
Pull-based lntegration
DataHub ships with a Python-based metadata ingestion system that can connect to different sources to extract metadata from them. This metadata is then pushed to the DataHub storage layer via Kafka or HTTP. Metadata ingestion pipelines can be integrated with Airflow to set up scheduled ingestion or capture lineages.
Push-based Integration
You can integrate any system with DataHub as long as you can issue Metadata Change Suggestion (MCP) events to Kafka or make REST calls over HTTP.
For convenience, DataHub also provides a simple Python emitter for you to integrate into your system to emit metadata changes (MCP-s) at the origin.
06 Datahub integrates with Dolphinscheduler
Scheme 1 Send a simple dataset to the bloodline of the dataset as a MetadataChangeEvent through Kafka
import datahub.emitter.mce_builder as builder
**Option 2: **Go to emit blood relationship through Rest.
import datahub.emitter.mce_builder as builder
The above form applies to all dataset-to-dataset kinship construction and can be used under any dataset processing.
Follow-up contribution plan in the community
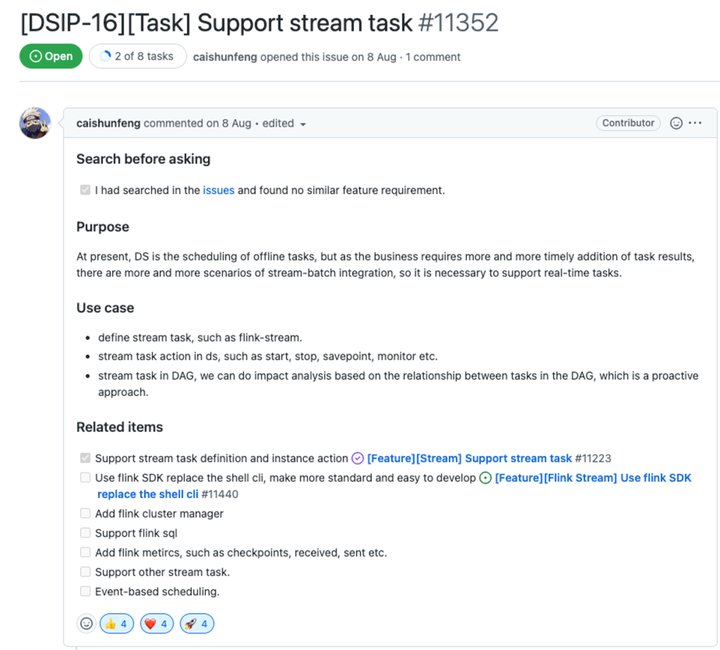
01 Support for stream processing (flink stream and debezium)
With the help of community PMC Cai Shunfeng, **now has completed the initial integration of convection tasks,** you can submit tasks to Yarn through Flink sdk, start, stop, savepoint visually, and intuitively see the Yarn of the task in the list Information such as Application ID and Job ID.
The next TODO LIST Shunfeng has been written in related items
-
flink cluster management
-
Support flink sql
-
Increase the metric of flink
-
Support for other streaming tasks (such as kafka connector)
-
Event-driven scheduling (the ultimate goal)
02 Integration with version management tools (GIT and SVN)
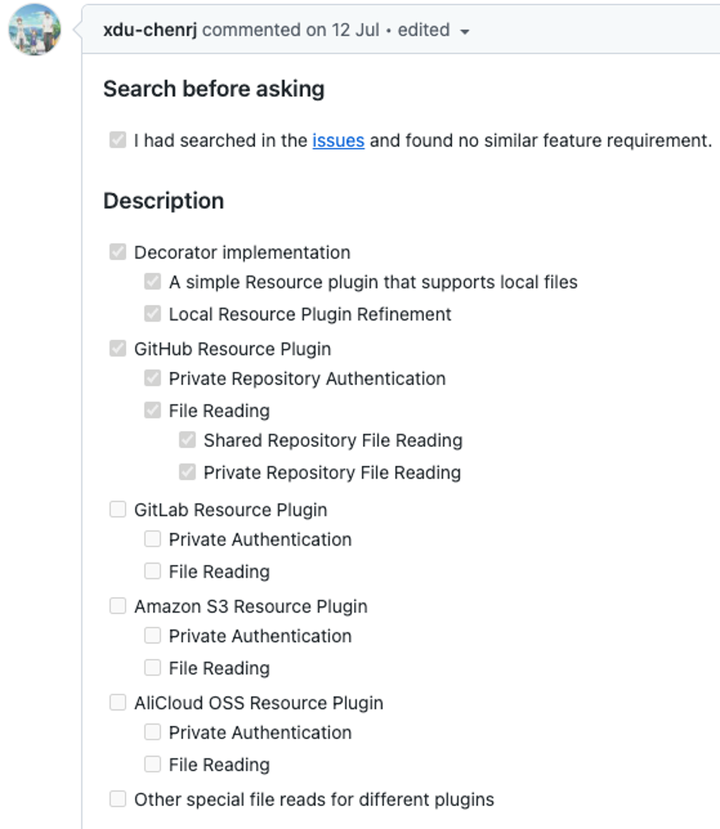
The community is indeed capable of producing in large numbers. For this RoadMap we prepared, I not only found the proposal in DSIP, but also mentioned the following resource plugins:
-
GitHub
-
GitLab
-
Amazon S3
-
AliCloud OSS
Of course, based on the existence of the underlying Decorator implementation, the Resource Plugin will be very easy to extend.
At that time, when preparing for the development of Data Quality , we were pleasantly surprised to find that the community had provided relevant proposals. We only made a slight change in 3.0.0 and put it into the use of the production environment, providing our data accuracy, timeliness, etc. Multiple guarantees.
We plan to expand the community's HiveCli plug- in on this basis , and gradually migrate our current projects from SVN to Git, so as to get rid of the current pure Shell use and let analysts focus more on business.
03 Better management and use of yarn clusters and queues
All our current resource scheduling is based on Yarn, including all MapReduce, Spark and Flink tasks, which are managed by Yarn.
Due to historical reasons and the isolation of test and production environments, there are currently multiple Yarn environments in the cluster, and the total resources and policy configurations of each Yarn are different, which makes management difficult.
Furthermore, based on the design of DolphinScheduler, the Yarn queue is bound to the executing user, and the user defines the default tenant and submission queue. This design does not meet the requirements of the production environment . The tenant defines the permissions of the data, and the queue defines the resources of the task. Later, we will use the queue as a configuration alone or directly bind the submission queue to the priority of the task.
In the multi-cluster management of the Yarn environment, tasks can be remotely submitted to the specified cluster in the later stage to replace the current solution. Later, in the scheduling process, the tasks in the scheduling system can be directly monitored in Yarn.
04 Better integration with DataHub

Provide you with a useful Python plugin , SqlLineage, which can parse the information in SQL statements.
Given a sql statement, sqllineage will tell you the source and target tables. If you want the graphical visualization of the blood relationship results, you can switch its toggle graphical visualization option, and a web will be launched to display the DAG diagram of the blood relationship results in the browser. At present, our company analyzes our version management tool based on this component. All the sql below, build our upstream and downstream bloodline on this basis.
In the later stage, we will expand and develop the Dolphinscheduler metadata component of Datahub according to the function of Datahub's Airflow component.
[lineage]
The Airflow bloodline configuration of Datahub is shown above. It can be found that Datahub provides out -of-the-box acryl-datahub[airflow] plugin for Airflow, which provides the following functions:
-
Airflow Pipeline (DAG) metadata
-
DAG and Task run information
-
Lineage information when present
We will expand the Python Gateway capabilities of Dolphinscheduler, and will give back to the community in the future , hoping to provide you with a better metadata system integration experience.
Participate and contribute
With the rapid rise of domestic open source, the Apache DolphinScheduler community has ushered in vigorous development. In order to make more usable and easy-to-use scheduling, we sincerely welcome partners who love open source to join the open source community and contribute to the rise of open source in China. , let local open source go global.
There are many ways to participate in the DolphinScheduler community, including:
Contributing the first PR (documentation, code) We also hope that it is simple, the first PR is used to get familiar with the submission process and community collaboration and to feel the friendliness of the community.
The community has put together the following list of issues for newbies: https://github.com/apache/dolphinscheduler/issues/5689
List of non-novice issues: https://github.com/apache/dolphinscheduler/issues?q=is%3Aopen+is%3Aissue+label%3A"volunteer+wanted"
How to contribute link: https://dolphinscheduler.apache.org/en-us/community/development/contribute.html
Come on, the DolphinScheduler open source community needs your participation and contribute to the rise of China's open source, even if it is just a small tile, the combined power is huge.