Article directory
Pre-import
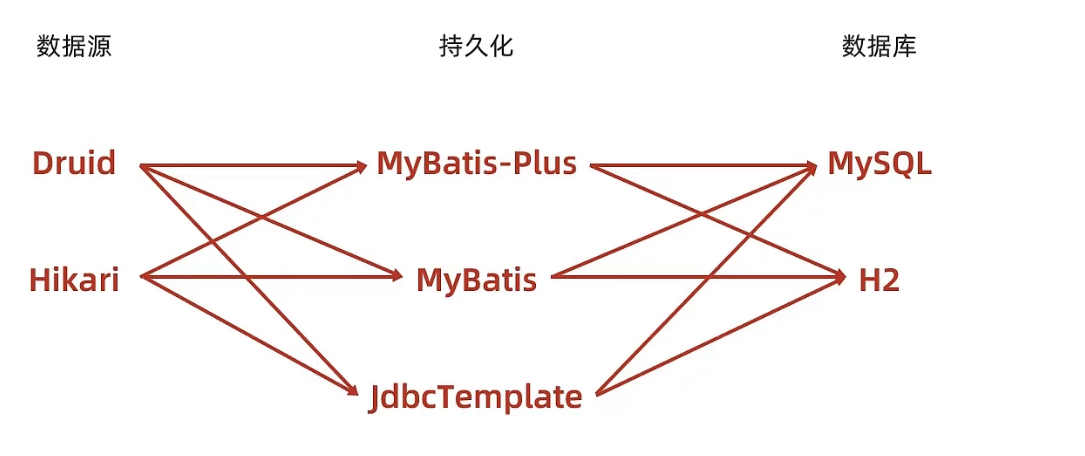
When doing SSMP integration before, the data layer solution involved, MySQL database and MyBatisPlus framework, and later involved the configuration of Druid data source, so now the data layer solution can be said to be Mysql+Druid+MyBatisPlus. The three technologies correspond to the three levels of data layer operations:
- Data source technology: Druid
- Persistence Technology: MyBatisPlus
- Database Technology: MySQL
The following research is divided into three levels for research. Corresponding to the three aspects listed above, let’s start with the first data source technology.
data source technology
At present, the data source technology we use is Druid, and the corresponding data source initialization information can be seen in the log at runtime, as follows:
INFO 28600 --- [ main] c.a.d.s.b.a.DruidDataSourceAutoConfigure : Init DruidDataSource
INFO 28600 --- [ main] com.alibaba.druid.pool.DruidDataSource : {dataSource-1} inited
If the Druid data source is not used, what does the program look like after running? Is it an independent database connection object or is it supported by other connection pooling technologies? Remove the starter corresponding to Druid technology and run the program again to find the following initialization information in the log:
INFO 31820 --- [ main] com.zaxxer.hikari.HikariDataSource : HikariPool-1 - Starting...
INFO 31820 --- [ main] com.zaxxer.hikari.HikariDataSource : HikariPool-1 - Start completed.
Although there is no information related to DruidDataSource, we found that there is information about HikariDataSource in the log. Even if you don’t understand what technology this is, you can see it by looking at the name. The name ending with DataSource must be a data source technology. We didn't add this technology manually, where did this technology come from? It is the springboot embedded data source.
Data layer technology is used by every enterprise-level application, in which database connection management must be performed. Springboot is based on the developer's habits. The developer provides the data source technology, just use what you provide, but the developer does not provide it. Then you can't manage each database connection object manually. What should I do? I'll just give you a default one, which saves you worry and trouble, and it's convenient for everyone.
springboot provides 3 embedded data source technologies, as follows:
- HikariCP
- Tomcat provides DataSource
- Commons DBCP
The first is HikartCP, which is the data source technology officially recommended by springboot.Use as default built-in data source. What do you mean? If you don't configure a data source, use this.
The second, the DataSource provided by Tomcat,If you don't want to use HikartCP and use tomcat as a web server for web program development, use this. Why Tomcat, not any other web server? Because after the web technology is imported into the starter, the embedded tomcat is used by default. Since it is the technology used by default, it is used to the end, and the data source also uses it. Someone proposed how to not use the default data source object provided by HikartCP with tomcat? It is OK to exclude the coordinates of HikartCP technology .
The third type, DBCP, the conditions for this use are even harsher.When neither HikartCP nor tomcat's DataSource is used, this is used by default for you.
Springboot’s worries are also broken. I’m afraid that you can’t manage the connection object yourself. I’ll give you a recommendation. It’s really the strongest assistant in the development world. Since they have given you milk, then you can use it. How to configure and use these things? When we configured druid before, the configuration corresponding to the starter of druid is as follows:
spring:
datasource:
druid:
url: jdbc:mysql://localhost:3306/ssm_db?serverTimezone=UTC
driver-class-name: com.mysql.cj.jdbc.Driver
username: root
password: ************
After changing to the default data source HikariCP, just delete the druid, as follows:
Note: This place also needs to delete the Druid starter.
spring:
datasource:
url: jdbc:mysql://localhost:3306/ssm_db?serverTimezone=UTC
driver-class-name: com.mysql.cj.jdbc.Driver
username: root
password: *****************
Of course, you can also write the configuration for hikari, but the url address should be configured separately, as follows (that is, another way of writing):
spring:
datasource:
url: jdbc:mysql://localhost:3306/ssm_db?serverTimezone=UTC
hikari:
driver-class-name: com.mysql.cj.jdbc.Driver
username: root
password: *************
This is how the hikari data source is configured. If you want to further configure hikari, you can continue to configure its independent properties. E.g:
spring:
datasource:
url: jdbc:mysql://localhost:3306/ssm_db?serverTimezone=UTC
hikari:
driver-class-name: com.mysql.cj.jdbc.Driver
username: root
password: **************
maximum-pool-size: 50
If you do not want to use the hikari data source, use the tomcat data source or the DBCP configuration format is the same. In the future, when we do the data layer, the selection of the data source object is no longer a single use of the druid data source technology, and can be selected according to the needs.
Summarize
- springboot technology provides 3 built-in data source technologies, namely Hikari, tomcat built-in data source, DBCP
Persistence Technology
After talking about the data source solution, let's talk about the persistence solution. Springboot gives full play to its strongest auxiliary features and provides developers with a set of ready-made data layer technology called JdbcTemplate. In fact, this technology cannot be said to be provided by springboot, because it can be used without the use of springboot technology. Who provides it? It is provided by spring technology, so in the category of springboot technology, this technology also exists. After all, springboot technology is created to accelerate the development of spring programs.
This technology is actually a return to the most primitive programming form of jdbc for data layer development. The following steps are directly performed:
Step 1 : Import the coordinates corresponding to jdbc, remember the starter
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
Step 2 : Automatically assemble the JdbcTemplate object
@SpringBootTest
class Springboot15SqlApplicationTests {
@Test
void testJdbcTemplate(@Autowired JdbcTemplate jdbcTemplate){
}
}
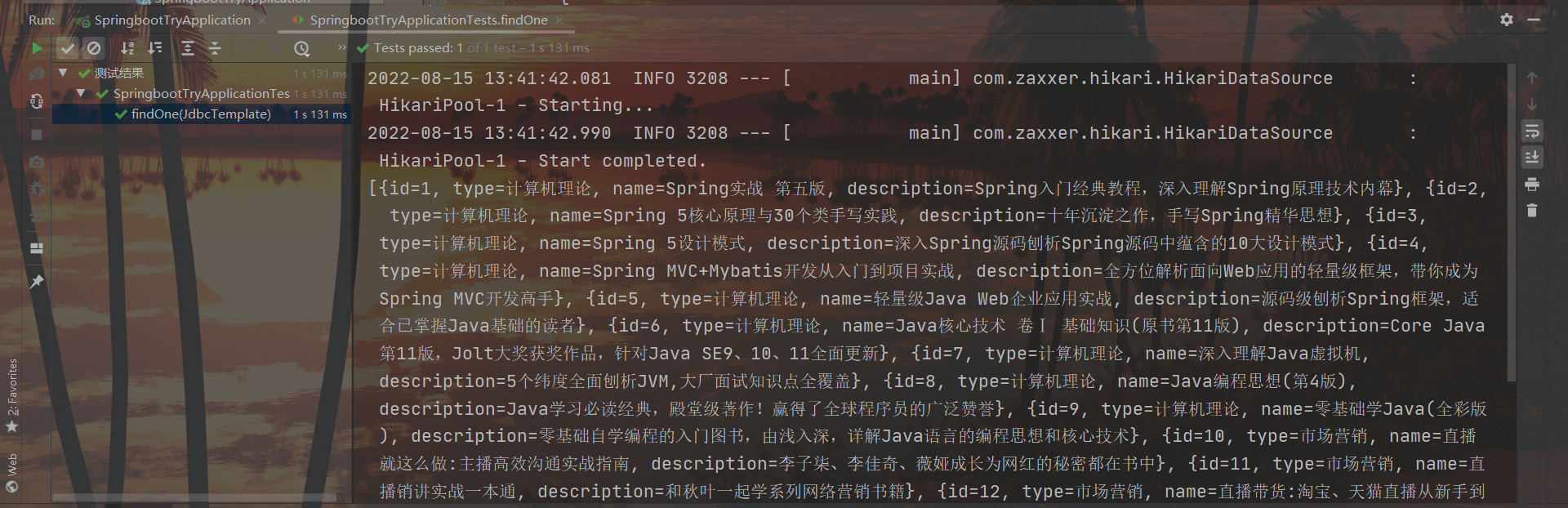
Step 3 : Use JdbcTemplate to implement query operations (query operations for non-entity class encapsulated data)
@Test
void testJdbcTemplate(@Autowired JdbcTemplate jdbcTemplate){
String sql = "select * from tbl_book";
List<Map<String, Object>> maps = jdbcTemplate.queryForList(sql);
System.out.println(maps);
}
result:
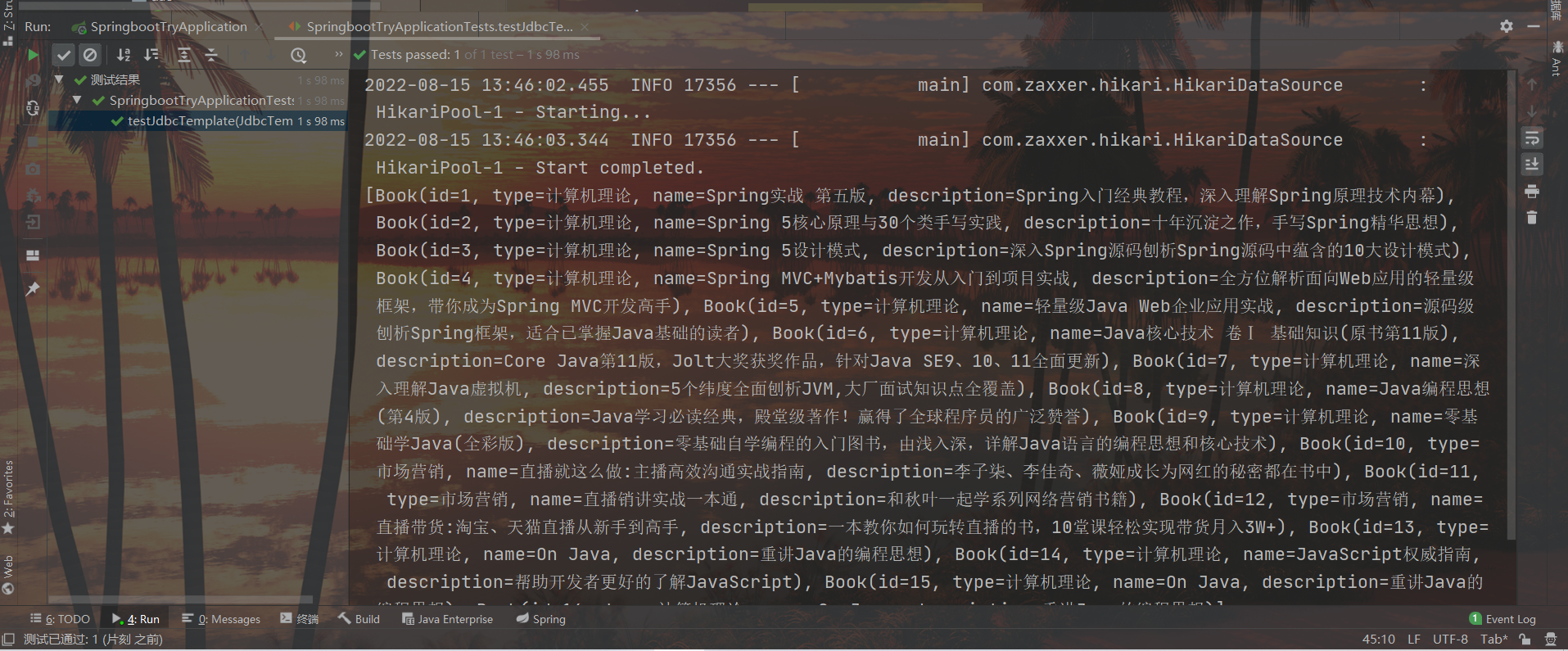
Step 4 : Use JdbcTemplate to implement query operations (entity classes encapsulate data query operations)
@Test
void testJdbcTemplate(@Autowired JdbcTemplate jdbcTemplate){
String sql = "select * from tbl_book";
RowMapper<Book> rm = new RowMapper<Book>() {
@Override
public Book mapRow(ResultSet rs, int rowNum) throws SQLException {
Book temp = new Book();
temp.setId(rs.getInt("id"));
temp.setName(rs.getString("name"));
temp.setType(rs.getString("type"));
temp.setDescription(rs.getString("description"));
return temp;
}
};
List<Book> list = jdbcTemplate.query(sql, rm);
System.out.println(list);
}
result:
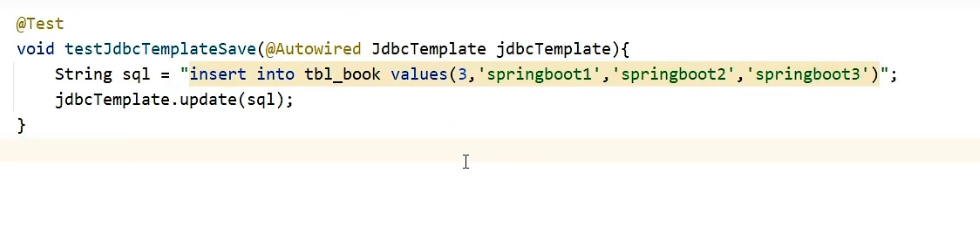
Step ⑤ : Use JdbcTemplate to implement addition, deletion and modification operations
@Test
void testJdbcTemplateSave(@Autowired JdbcTemplate jdbcTemplate){
String sql = "insert into tbl_book values(3,'springboot1','springboot2','springboot3')";
jdbcTemplate.update(sql);
}
If you want to configure the JdbcTemplate object, you can set it in the yml file, as follows:
spring:
jdbc:
template:
query-timeout: -1 # 查询超时时间
max-rows: 500 # 最大行数
fetch-size: -1 # 缓存行数
fetch-sizeCan improve our query performance. For example, now we check 10,000 pieces of data, how many pieces are given to us at a time? This canfetch-sizebe controlled by. If we give fifty at a time, and we also use these fifty, then the efficiency will be very high. And if we use more than 50, it will come again, and the efficiency will be reduced.
Summarize
- SpringBoot built-in JdbcTemplate persistence solution
- Using JdbcTemplate needs to import the coordinates of spring-boot-starter-jdbc
Database Technology
Up to now, springboot has provided developers with built-in data source solutions and persistence solutions. There is one database left in the three-piece data layer solution. Could it be that springboot also provides built-in solutions? There are, not one, but three
springboot provides 3 built-in databases, namely:
- H2
- HSQL
- Derby
In addition to the independent installation of the above . Embedded in the container to run, it must be a java object, yes, the bottom layer of these three databases are developed using the java language.
We have been using the MySQL database all the time, so why is there a need to use this?The reason is that these three databases can be run in the form of embedded containers. After the application is running, if we perform testing work, the data under test does not need to be stored on the disk, but it needs to be used for testing. Convenient, runs in memory, it's time to test, it's time to run, and when the server shuts down, everything disappears, which is great, saving you from maintaining an external database. This is also the biggest advantage of the embedded database, which is convenient for functional testing.
The following takes the H2 database as an example to explain how to use these embedded databases. The operation steps are also very simple. Simple is easy to use.
Step 1 : Import the coordinates corresponding to the H2 database, a total of 2
<dependency>
<groupId>com.h2database</groupId>
<artifactId>h2</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
Step 2 : Set the project as a web project, and start the H2 database when starting the project
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
Step ③ : Open the H2 database console access program through configuration, or use other database connection software to operate
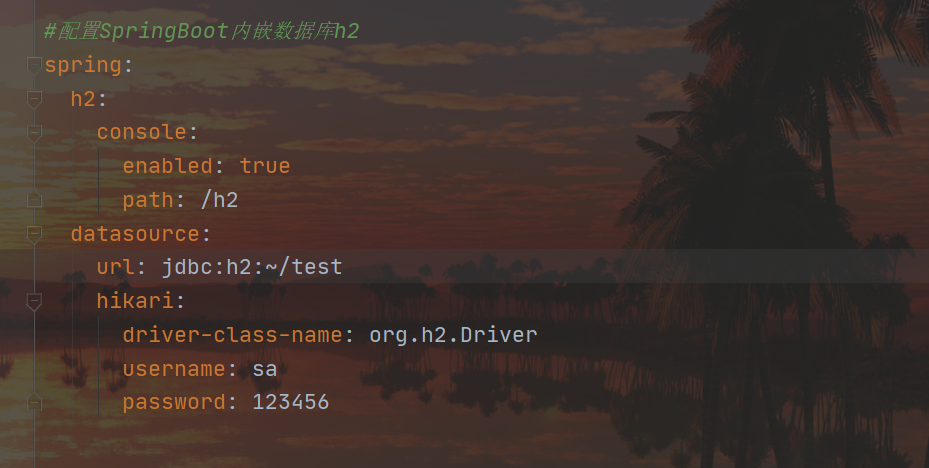
spring:
h2:
console:
enabled: true
path: /h2
After that, we start the server, and then access localhost/h2 (the port has been set to 80 in advance), the page displays:
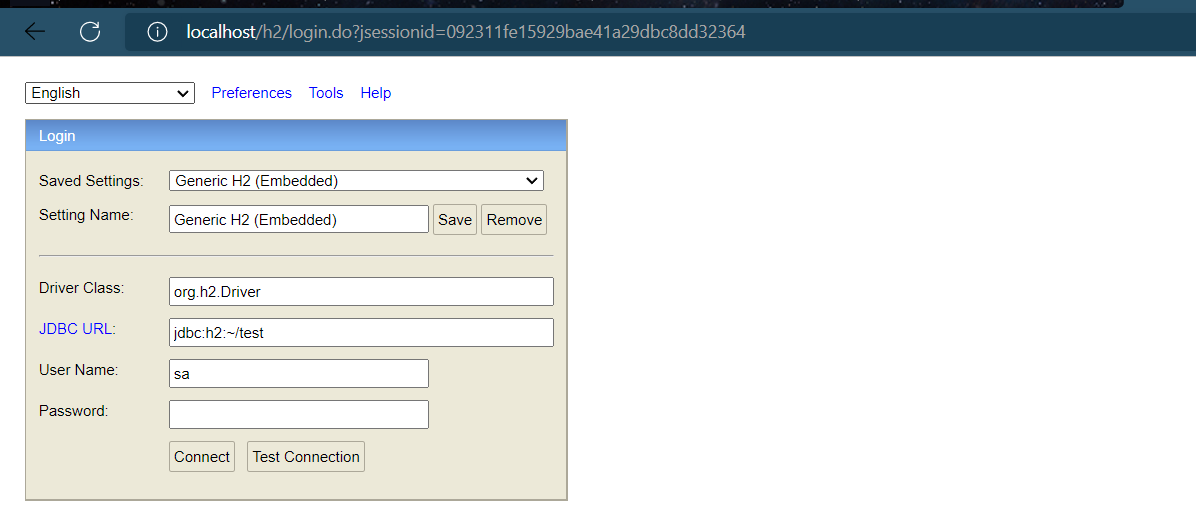
web side access path /h2, access password 123456, if the access fails, configure the following data sources first, after the startup program runs Access the /h2 path again and you can access it normally (after successful access, you can also remove the following content)
datasource:
url: jdbc:h2:~/test
hikari:
driver-class-name: org.h2.Driver
username: sa
password: 123456
Then we entered the following webpage:
We can create a table first:
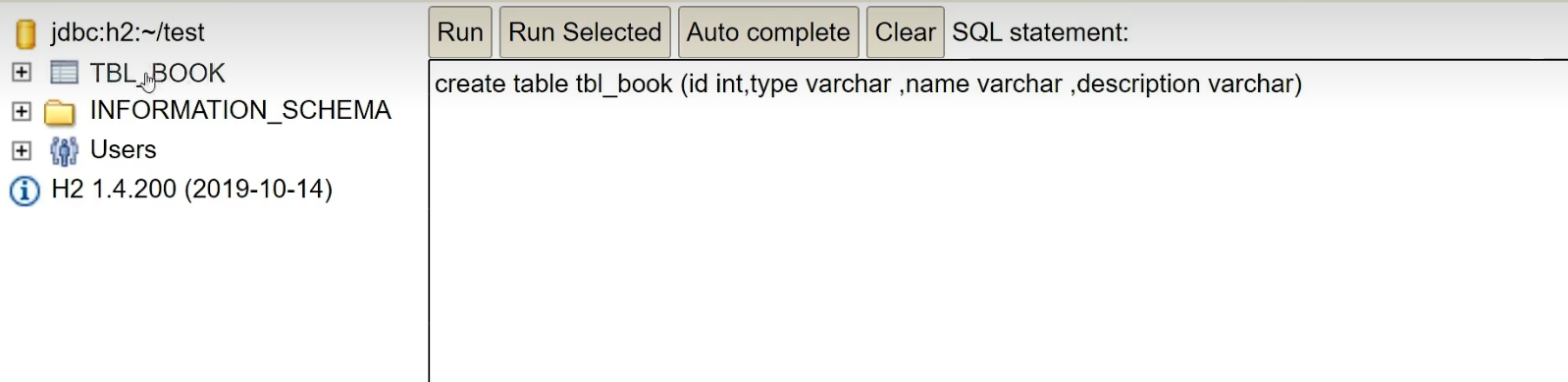
Then we look at the table:
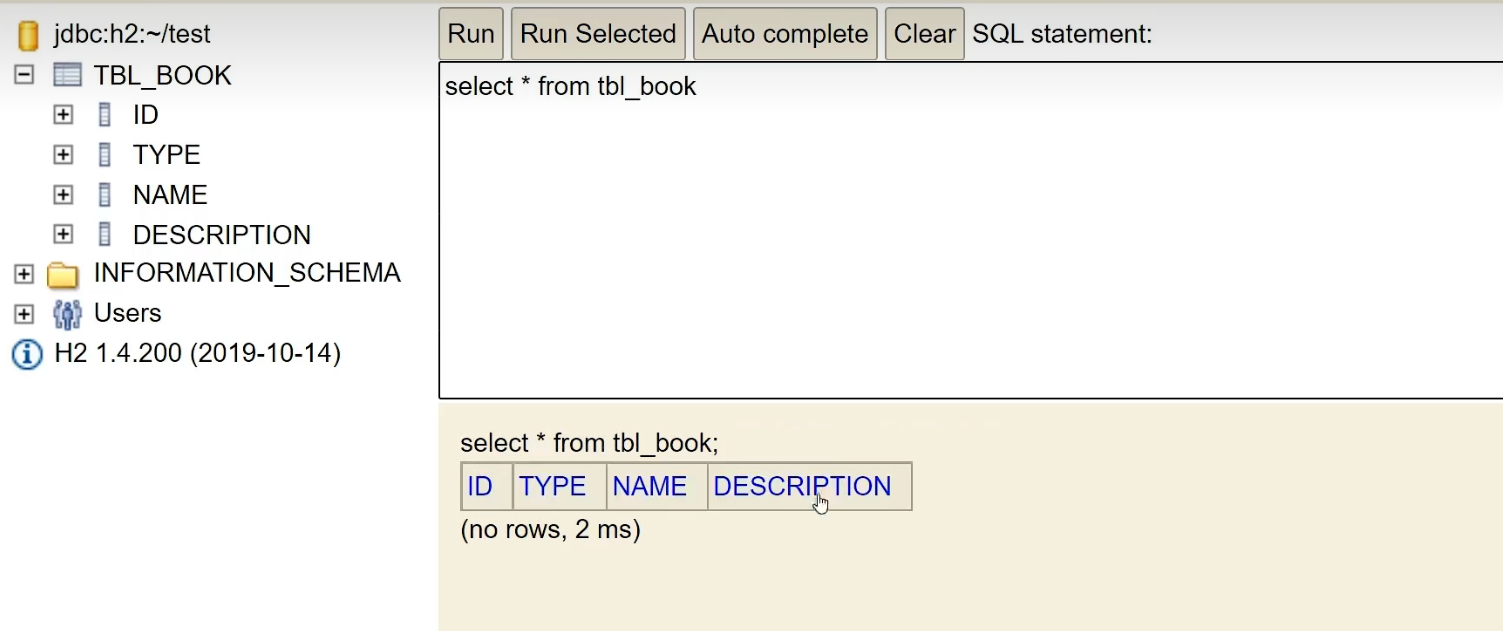
we add two pieces of data to it:
insert into tbl_book values(1,'springboot','springboot','springboot')
insert into tbl_book values(2,'springboot2','springboot2','springboot2')
Let's check the table again and find that the data has been successfully added:
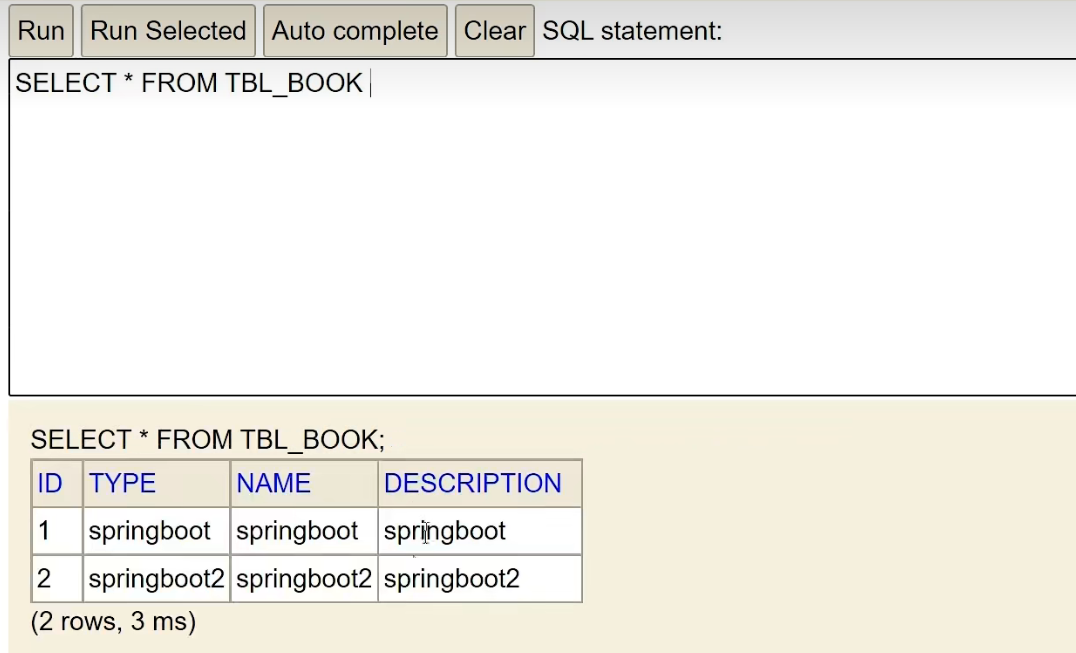
Step ④ : Use JdbcTemplate or MyBatisPlus technology to operate the database
Here we only talk about JdbcTemplate, MyBatisPlus technology is the same as before.
At this point, the data source should be written:
the configuration information of the data source is written when we first enter the h2 webpage
Let's test adding data to it:

In fact, we just changed a database, other things are not affected. An important reminder, don't forget, when going online, close the in-memory database and use the MySQL database as the data persistence scheme. The way to close it is to set the enabled attribute to false.

Summarize
- H2 embedded database startup method, add coordinates, add configuration
- Be sure to close the H2 database when it is running online
At this point, we have finished talking about SQL-related data layer solutions, and now the optional technologies are much richer.
- Data source technology: Druid, Hikari, tomcat DataSource, DBCP
- Persistence technology: MyBatisPlus, MyBatis, JdbcTemplate
- Database technology: MySQL, H2, HSQL, Derby
Now you can choose one of the above technologies to organize a database solution when developing a program.