Magic Guide
The existing open source time series database influxdb only supports single-machine operation. When faced with a large amount of data writing, there will be slow queries, high machine load, and single-machine capacity limitations.
In order to solve this problem, the 360 infrastructure team developed a cluster version - QTSDB on the basis of the stand-alone influxdb
QTSDB brief description
QTSDB is a distributed time series database for processing massive data writing and querying . In terms of implementation, it is a distributed version developed based on the open source stand-alone time series database influxdb 1.7. In addition to the characteristics of influxdb itself, it also has cluster functions such as capacity expansion and replica fault tolerance .
The main features are as follows:
-
A high-performance data store specially written for time series data, taking into account both write performance and disk space usage;
-
SQL-like query statement, supports a variety of statistical aggregation functions;
-
Automatically clean up expired data;
-
Built-in continuous query, automatically complete the aggregation operation preset by the user;
-
Written in Golang, no other dependencies, easy to deploy and maintain;
-
Dynamic horizontal expansion of nodes to support massive data storage;
-
Replica redundant design, automatic failover, support high availability;
-
Optimize data writing to support high throughput;
system structure
Logical Storage Hierarchy

The highest level of the influxdb architecture is the database. The database is divided into different retension policies according to the data retention time, forming multiple storage containers under the database. Because the time series database is associated with the time dimension, the content of the same retention time is stored together. Easy to delete when expired. In addition, under the retension policy, the retention time of the retension policy is further subdivided, and the data of each time period is stored in a shard group, so that when the shard group of a certain segment expires, it will be Delete the entire data to avoid extracting part of the data from the storage engine. For example, the data under the database may be retained for 30 days or 7 days, and they will be stored under different retension policies. Assuming that the 7-day data will continue to be divided into 1 day, they will be stored in 7 shard groups respectively. When the data of the 8th day is generated, a new shard group will be created and written, and the shard group of the 1st day will be written. Delete the whole.
So far, under the same retension policy, the current time series data sent will only fall in the current time period, that is, only the latest shard group has data written. In order to increase the amount of concurrency, a shard group is divided into multiple Shards are globally unique and distributed on all physical nodes. Each shard corresponds to a tsm storage engine, which is responsible for storing data.
When requesting access to data, a certain database and retension policy can be locked through the requested information, and then a certain (some) shard group(s) can be locked according to the time period information in the request. In the case of writing, each piece of written data corresponds to a serieskey (this concept will be introduced later), and a shard can be locked for writing by hashing the serieskey modulo. On the other hand, shards have replicas. When writing, the strategy of unowned and multi-write is adopted to write to each replica at the same time. When querying, since there is no serieskey information in the query request, only the shards in the shard group can be queried once. For a shard, an available physical node will be selected in its replica for access.
So how many shards should a shard group have? In order to achieve the maximum concurrency without excessively interfering with the overall order of the data, after the number of physical nodes and the number of replicas are determined, the number of shards in a shard group is the number of machines divided by the number of replicas This ensures that the current data can be written to all physical nodes evenly, and the query efficiency will not be affected by too many shards. For example, the data cluster in the figure has 6 physical nodes, and the user specifies dual copies, so there are 3 shards.
Cluster structure
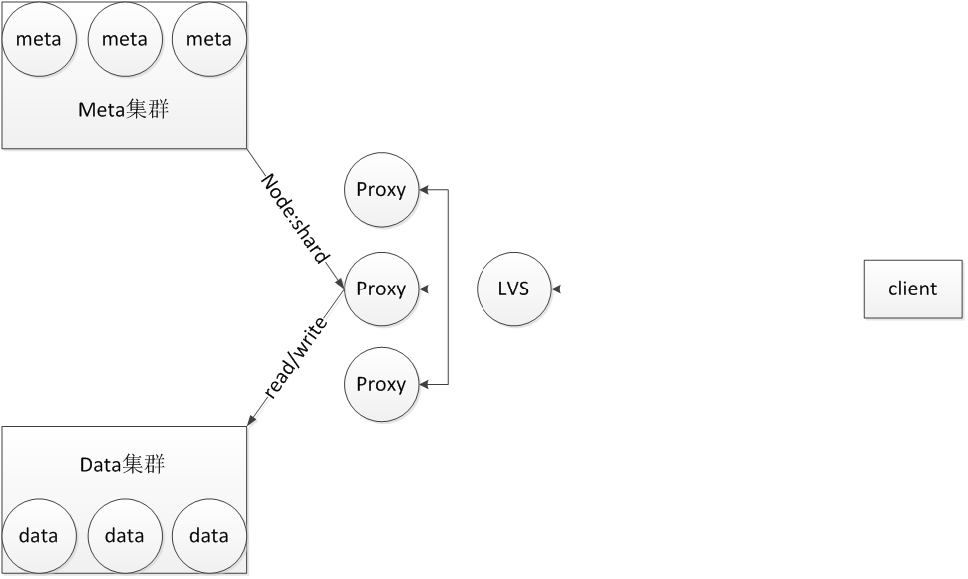
The whole system is divided into three parts: proxy, meta cluster, and data cluster. **proxy is responsible for receiving requests, stateless, and can be connected to lvs to support horizontal expansion. The meta cluster saves the above-mentioned logical storage levels and their corresponding relationships with physical nodes. The raft protocol ensures strong consistency of metadata. Here, meta information is stored in memory, and logs and snapshots are persisted to disk. The data cluster is a real data storage node. Data is stored on it in shard units, and each shard corresponds to a tsm storage engine.
When the request arrives, a proxy is locked by lvs. The proxy first searches the meta cluster for meta information according to the database, retension policy and time period, and finally obtains a mapping from shard to physical nodes, and then converts the mapping relationship into physical nodes to shards The mapping is returned to the proxy, and finally, according to this mapping relationship, the specific shard is accessed from the physical node specified by the data cluster. As for the data access under the shard, it will be introduced later.
data access
syntax format
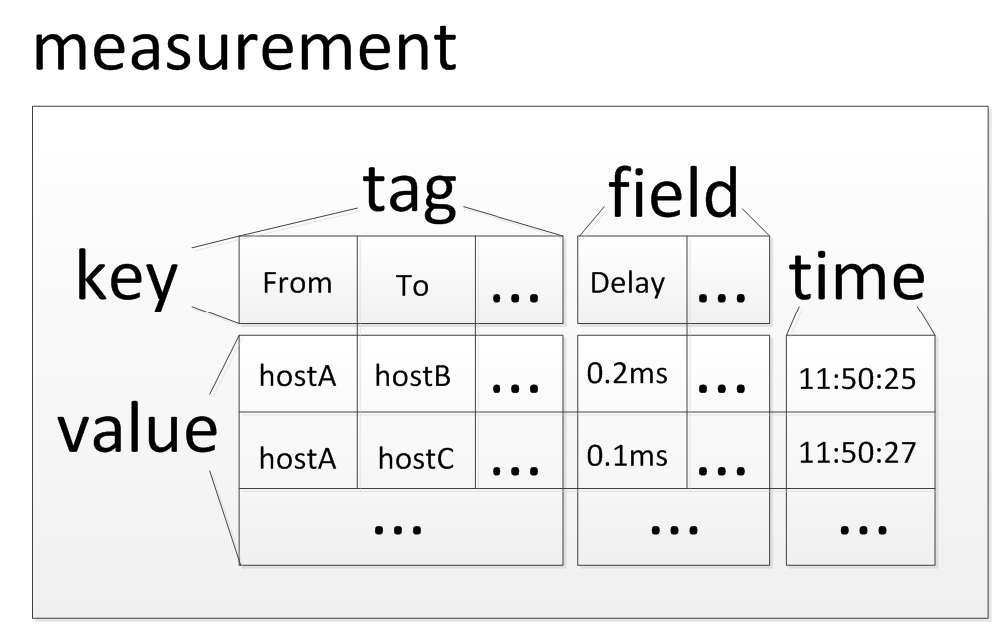
The query of influxdb provides a query method similar to a relational database, showing a relational table: measurement, the time of the time series database is used as an eternal column, and the other columns are divided into two categories:
1、field
One is field, which is the most critical data part of time series data, and its value will be continuously added with the flow of time, such as the delay between two machines at each time point.
2、tag
The other type is tags, they are some tags of a field value, so they are all string types, and the range of values is very limited. For example, the delay field value at a certain point in time is 2ms, which corresponds to two tag attributes and the delay from which machine to which machine. Therefore, two tags can be designed: from and to.
The measurement shows that the first line is the key, and the rest can be regarded as the value, so that the tag has tagkey, tagvalue, and the field has fieldkey and fieldvalue.
data read and write
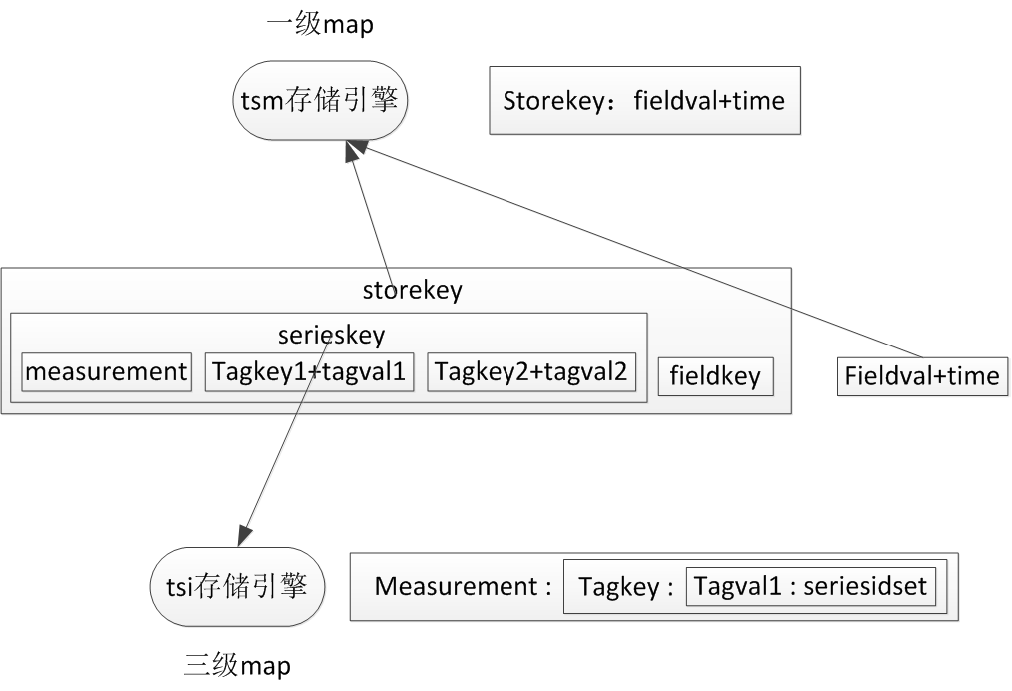
When a line of written data is received, it will be converted to the following format:
measurement+tagkey1+tagvalue1+tagkey2+tagvalue2+fieldkey+fieldvalue+time。
If there are multiple fields in a row, it will be divided into multiple such data stores. The storage engine of influxdb can be understood as a map, from measurement to fieldkey as storage key, followed by fieldvalue and time as storage value, these values will be continuously added, in the storage engine, these values will be stored together as a column, because It is data that changes over time, and saving them together can improve the compression effect. In addition, the remaining part after removing the fieldkey from the storage key is the serieskey mentioned above.
As mentioned above, how the access request locks the shard in the cluster, here is the access within a shard.

The query of influxdb is similar to the SQL syntax, but the scattered information of the SQL statement cannot directly query the storage engine, so some strategies are needed to convert the SQL statement into the storage key. Influxdb converts the tag information after where into a collection of all related serieskeys by building an inverted index, and then splices each serieskey with the fieldkey behind the select to form a storage key, so that the corresponding data can be retrieved by column.
By analyzing the serieskey in the key stored in the tsm storage engine, an inverted index can be constructed. The new version of influxdb persists the inverted index to each shard, which corresponds to the tsm storage engine that stores data, called the tsi storage engine. The inverted index is equivalent to a three-layer map, the key of the map is measure, the value is a two-layer map, the key of this two-layer map is tagkey, the corresponding value is a one-layer map, the value of this one-layer map is The key is tagval, and the corresponding value is a collection of serieskeys. Each serieskey string in this collection contains the measurement, tagkey and tagval on the map index path.
In this way, you can analyze the query sql, use the measurement after from to query the third-level map of the inverted index to obtain a second-level map, and then analyze the multiple filtering logic units after where. Take tagkey1=tagval1 as an example, and use these two information as the second-level map. The key of map, find the final value: the collection of serieskey, each serieskey string of this collection contains measure, tagkey1 and tagval1, they are the serieskey that satisfies the current filtering logic unit. According to the AND or logic of these logical units, the corresponding sets of serieskeys are intersected and merged, and finally all sets of serieskeys that conform to their logic are filtered out according to the semantics of sql, and then these serieskeys are spliced with the fieldkey behind the select, Once the final storage key is obtained, the data can be read.
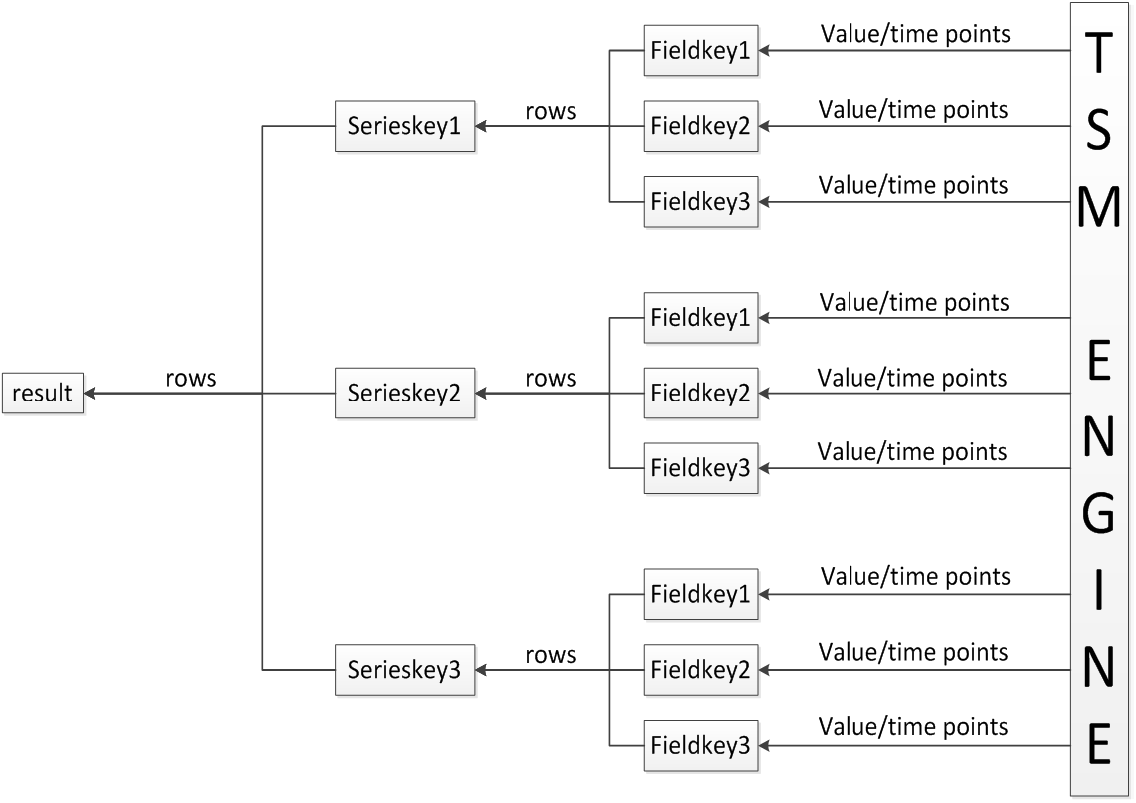
Query without aggregation function: As shown in the figure, for a serieskey, many fieldkeys need to be spliced, and then the data of multiple columns need to be spliced out. The problem they face after they come out is how to combine the data into a row. The row and column constraints of influxdb are relatively loose and cannot be simply Determines the row by offset within the column. Influxdb uses serieskey and time as the basis for judging that column data is a row. Multiple columns corresponding to each serieskey are aggregated into a data stream with multi-behavior granularity. The data streams corresponding to multiple serieskeys are aggregated into a data stream in a certain order, as The final result set is returned to the client.
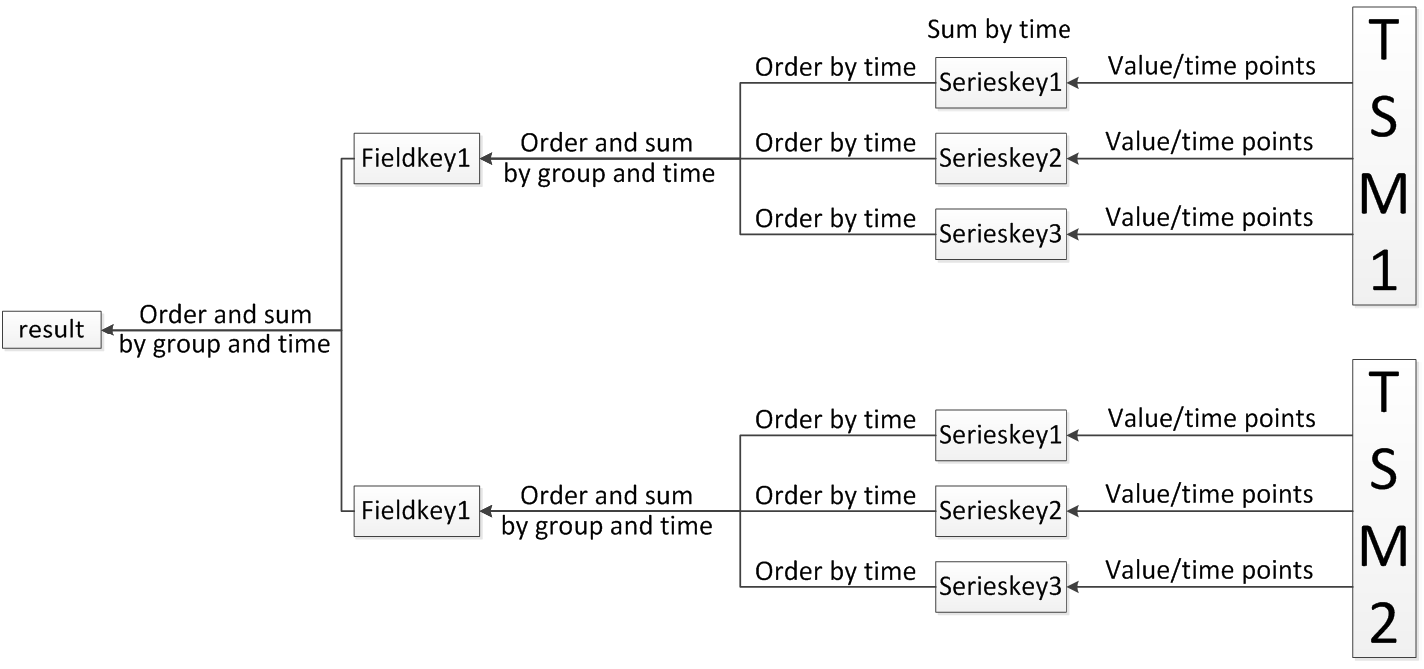
Query with aggregate function: This method is just the opposite of the above query. Here is the aggregation function parameter field, spliced with many serieskeys, of course, the final purpose is the same, to get the storage key, multiple storage keys can read multiple Data flow, these data flows are faced with two kinds of processing. First, they are aggregated into a data flow in a certain order, and then some adjacent data in this data flow are delineated according to a certain strategy for aggregation calculation, and then the final aggregated value is obtained. . The order and strategy here come from the aggregation method after group by in the sql statement.
The merging and aggregation method of multiple data streams is also applicable to query results on shards.
For writing, it is relatively simple, just update the data storage engine and the inverted index directly.
the entire process
The entire process of access has been mentioned above, here is a general overview: divided into two stages, the query above the shard, and the query below the shard.
First, the access request is locked to a proxy through lvs, and the proxy searches for meta information in the meta cluster. According to the request information, the database, retension policy and shard group are locked, and then numerous shards are obtained.
For write operations, a shard is locked for writing according to the serieskey at the time of writing. Since there are multiple copies of a shard, data needs to be written to multiple copies at the same time. For queries, the serieskey cannot be obtained through the request information, so it is necessary to query all shards, and select an available replica for each shard for access.
After the above processing, the mapping from shards to physical nodes is obtained, and then it is reversed to the mapping from physical nodes to shards, and returned to the proxy. The proxy can access the corresponding shard at a node in the data cluster.
For write access under shard, you need to disassemble the insert statement, combine it into a stored key-value pair and store it in the tsm storage engine, and then update the inverted index according to the combined serieskey.
Query access under the shard, analyze the SQL statement, query the inverted index, obtain its related serieskey set, splicing it into the field, form the final storage key, and perform data access. Then, many data are merged and aggregated on the data node on the shard, and the proxy on the data is merged and aggregated.
Finally, the proxy returns the access result to the client.
Troubleshooting
Strategy
As mentioned above, influxdb provides replica fault tolerance for shards. When writing data is sent to the proxy, the proxy sends the data to all shard replicas in the form of unowned multi-write. The meta cluster monitors whether the data node is online in the form of heartbeat. When reading, a read node is randomly selected from the online data nodes for the same shard to read.
If a data node is unavailable during writing, it will be written to a temporary file of the proxy, and the temporary data will be sent to the specified node when the network returns to normal.
deal with
data cluster expansion
When a new node joins the data cluster, it does not currently support automatic migration of existing data, but some efforts have been made to make the current written data apply to the new node as soon as possible. The time is used as the end time of the current shard group, and then a new shard group is created according to the number of new data nodes, so that the current amount of data can be equally distributed to each data node, and the meta information related to each shard group is stored in the meta cluster. , so it will not interfere with the reading of the previous data.
The data node is temporarily unavailable
If the data node is in a short-term unavailable state, including self-recovery after a short network failure, or the operation and maintenance personnel intervene after a hardware failure, and finally the data node still has the data before the disconnection, it can join the data cluster as the original identity. . For writing, the proxy will temporarily store the data of the data node during the period of unavailability, and will send this part of the data to the data node again when the data is added to the cluster to ensure that the data is eventually consistent.
The data node is unavailable for a long time
If the data node cannot or does not need to join the cluster with its original identity due to some reasons, and the operation and maintenance personnel need to manually disconnect the original unusable data node, then when the machine is available, it can join the cluster with a new data identity , this is equivalent to the expansion of the cluster.
Summarize
The implementation of the QTSDB cluster is: when writing, data is written to the specified shard according to the serieskey, but the serieskey cannot be predicted when reading, so each shard needs to be queried. Divide the entire reading process into two stages: read the storage engine on the data node and merge and aggregate multiple shards inside the node, summarize the data of multiple data nodes on the proxy node, and perform later merge and aggregation to form The final result set is returned to the client.
There are still imperfections in the existing cluster functions of QTSDB, which will be continuously improved in the future use.
(360 technology original content, please keep the QR code at the end of the article for reprinting, thank you~)

About 360 Technology
360 Technology is a technology sharing public account created by the 360 technology team, and pushes dry technical content every day
For more technical information, please pay attention to the WeChat public account of "360 Technology"