Recently, when a reader chatted with me privately, they found that there are many fresh graduates and beginners. They have great troubles in how to learn big data, how to interview for big data, and how to write resumes. Today we will talk about big data. some things.
Written in the front: Everyone's learning methods may be different, and it is best to find the one that suits you. The following are just some of my summary and experience when learning big data. Bear with each other, learn from each other, and make progress together, thank you very much!
I answered a similar question on Zhihu before. Someone asked 大数据工程师的日常工作内容是干嘛?me. After I saw it, I answered it at will. I first talked about what big data does in my daily life, and then I talked about how to prepare for big data interviews and how to study for university. Data and so on, I didn't expect the response to be quite good, screenshots of some comments:



Today, I will answer a wave of my heart, and reorganize the content of Zhihu's answer.

1. Big data learning
How to learn big data, what to learn, and what not to learn is one of the most frequently asked questions by everyone. Many students also ask training institutions that there are too many frameworks, whether they should master them, and then we will analyze them one by one.
Since Hadoop became Apache's top-level project in 2008, big data has ushered in a systematic and rapid development. It has been more than a dozen years now. In these years, big data frameworks have emerged one after another, which can be described as "flowers gradually become charming". , There are so many frameworks, how should I learn?
We can think about what the whole big data process is, from data collection -> data storage -> data processing -> data application , plus a task scheduling . There are many corresponding big data frameworks for each process. It is more important for us to learn one or two of them, that is, the frameworks that enterprises use more.
Data collection : It is to collect data from other platforms to our big data platform. It is only responsible for collecting data. Therefore, the framework requirements for this process are to be able to use it. Log collection tools such as Flume , big data platforms and traditional databases (mysql, Postgresql...) to transfer data between tools such as Sqoop , we can use it, this tool is also very quick to use, and it does not have too complicated functions.
Data storage : Data storage is more important. The popularity of big data has a lot to do with the rapid development of large-scale distributed data storage. Of course, there are many data storage frameworks. Different frameworks have different functions. One: Hadoop HDFS , distributed file system, the birth of HDFS, solved the storage problem of massive data, but an excellent data storage system needs to consider both data storage and access issues, for example, you want to be able to access data randomly , this is what traditional relational databases are good at, but not what distributed file systems are good at. Is there a storage solution that can combine the advantages of distributed file systems and relational databases at the same time? Based on this requirement, HBase , MongoDB , etc. were produced .
Data processing : The most important part of big data is data processing. Data processing is usually divided into two types: batch processing and stream processing.
-
Batch processing: Unified processing of massive offline data for a period of time, the corresponding processing frameworks include Hadoop MapReduce , Spark , Flink , etc.;
-
Stream processing: Process the data in motion, that is, process the data while receiving it. The corresponding processing frameworks include Spark Streaming , Flink , etc.
Batch processing and stream processing have their own applicable scenarios. Batch processing can be used because time is insensitive or hardware resources are limited.
Stream processing can be used when time sensitivity and timeliness requirements are high. As the price of server hardware is getting lower and lower and everyone's requirements for timeliness are getting higher and higher, stream processing is becoming more and more common, such as stock price forecasting and e-commerce operation data analysis.
Big data is a very complete ecosystem, and there are solutions when there is demand. In order to enable people who are familiar with SQL to perform data processing and analysis, query and analysis frameworks have emerged, such as Hive , Spark SQL , Flink SQL , Phoenix , etc. These frameworks can use standard SQL or SQL-like syntax to flexibly query and analyze data.
These SQLs are parsed and optimized and converted into corresponding job programs to run. For example, Hive essentially converts SQL into MapReduce or Spark jobs, and Phoenix converts SQL queries into one or more HBase Scans.
Another framework that is widely used in big data stream processing is Kafka . Kafka is a high-throughput distributed publish-subscribe messaging system. It can be used to reduce peaks and avoid concurrent data damage to stream processing programs in scenarios such as spikes. shock.
Data application : The processed data can be output for applications, such as visual display, driving business decisions, recommendation algorithms, machine learning, etc.
Task scheduling : Another significant problem in complex big data processing is how to schedule multiple complex and dependent jobs? Based on this demand, workflow scheduling frameworks such as Azkaban and Oozie were produced .
At the same time, for the needs of cluster resource management, Hadoop YARN , a resource scheduling framework, is derived.
To ensure the high availability of the cluster, ZooKeeper is required . ZooKeeper is the most commonly used distributed coordination service. It can solve most cluster problems, including leader election, failure recovery, metadata storage and its consistency guarantee.
Above, in the analysis of the big data processing process, we have talked about the commonly used frameworks, which are basically the most commonly used frameworks in big data, try to master them all.
Most of the above frameworks are written in Java, and some are written in Scala, so the languages we must master are Java and Scala , so that we can develop related applications and read source code.
Summarize
We summarize the key frameworks below:
- Language: Java and Scala (languages are mainly these two and need to be mastered)
- Linux (requires some understanding of Linux)
- Hadoop (need to understand the bottom layer and be able to understand the source code)
- Hive (will use, understand the underlying SQL conversion principles and optimization)
- Spark (can develop. Have an understanding of the source code)
- Kafka (will use, understand the underlying principles)
- Flink (can develop. Have an understanding of the source code)
- HBase (understand the underlying principles)
- Zookeeper (will use, it is best to understand the principle)
- Sqoop , Flume , Oozie/Azkaban (you can use it)
If you go in the direction of several warehouses, you need to master the following skills:
- Offline data warehouse construction (build data warehouse, data warehouse modeling specification)
- Dimensional modeling (modeling methods commonly used include paradigm modeling and dimensional modeling, focusing on dimensional modeling)
- Real-time data warehouse architecture (two data warehouse architectures: Lambda architecture and Kappa architecture)
Whether offline or real-time, the top priority is: SQL . Find some more SQL questions to practice!
After work, there is time to learn the more popular OLAP query engine:
Impala Presto 、 Druid 、 Kudu 、 ClickHouse Doris
If you still have time, learn about data quality and data governance !
There are also metadata management tools: Atlas
Data Lake-Data Lake Three Musketeers: Delta, Hudi, Iceberg
2. Big data employment direction
Because the knowledge involved in big data is relatively extensive, and it is too difficult to learn all of them, so now companies will subdivide big data positions when recruiting and focus on recruiting in a certain direction, so first find out what jobs are there for big data direction, and then focus on which part you are more interested in in the subsequent learning process
Look at a picture from the perspective of God to understand the location of big data and its relationship with related positions
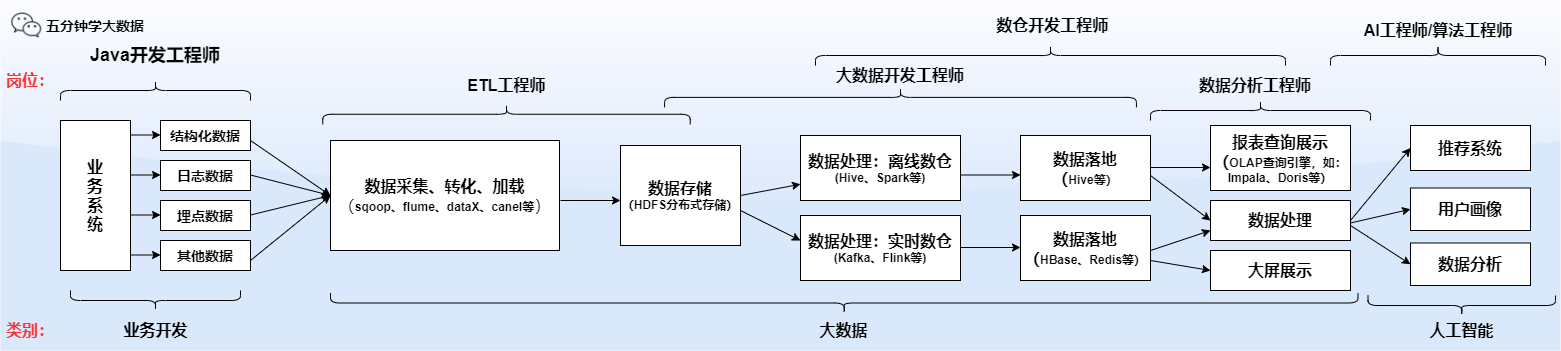
- Data warehouse engineer (full name: data warehouse engineer)
The daily work of data warehouse engineers is generally not to write code, mainly to write SQL!
Data warehouse engineers are the most recruited positions by companies in the big data field, and the salary is also high, so they need to focus on!
Data warehouses are divided into offline data warehouses and real-time data warehouses, but most companies require both when recruiting. After entering the company, they may focus on one of offline or real-time data.
At present, most enterprises still focus on offline data warehouses, but the future trend is definitely based on real-time data warehouses. Therefore, when studying, in order to find a job now, you need to learn offline data warehouses. For future development, you need to learn how to use offline data warehouses. Learn to count warehouses in real time. Therefore, both offline and real-time are our focus!
Required skills:
Whether offline or real-time, the top priority is: SQL
SQL syntax and tuning must be mastered. The SQL mentioned here includes sql in mysql, hive sql in hive, spark sql in spark, and flink sql in flink.
In the notes and interviews of corporate recruitment, the general questions about sql are mainly hive sql, so please pay attention!
In addition to sql, you also need to master the following skills, which are divided into offline and real-time
Skills that need to be mastered in offline data warehouses:
- Hadoop(HDFS,MapReduce,YARN)
- Hive (focus, including the underlying principles of hive, hive SQL and tuning)
- Spark (Spark will use and understand the underlying principles)
- Oozie (scheduling tool, you can use it)
- Offline data warehouse construction (build data warehouse, data warehouse modeling specification)
- Dimensional modeling (modeling methods commonly used include paradigm modeling and dimensional modeling, focusing on dimensional modeling)
Skills that need to be mastered in real-time data warehouse:
- Hadoop (this is the foundation of big data, it must be mastered regardless of offline and real-time)
- Kafka (key point, the only message queue in the field of big data)
- Flink (top priority, needless to say, the absolute king in the real-time computing framework)
- HBase (will use, understand the underlying principles)
- Druid (will use, understand the underlying principles)
- Real-time data warehouse architecture (two data warehouse architectures: Lambda architecture and Kappa architecture)
- Big data development engineer
Data development engineers generally write code, mainly Java and Scala.
Big data development is divided into two categories. The first category is to write Hadoop, Spark, and Flink applications. The second category is to develop the big data processing system itself, such as the extension development of open source frameworks, the development of data middle platforms, etc.!
Skills to be mastered:
- Language: Java and Scala (languages are mainly these two and need to be mastered)
- Linux (requires some understanding of Linux)
- Hadoop (need to understand the bottom layer and be able to understand the source code)
- Hive (will use, can carry out secondary development)
- Spark (can develop. Have an understanding of the source code)
- Kafka (will use, understand the underlying principles)
- Flink (can develop. Have an understanding of the source code)
- HBase (understand the underlying principles)
Through the above skills, we can also see that the skills of data development and data warehouse development have a high repetition rate, so many companies recruit big data development and data warehouse construction is not so detailed, data development includes data warehouse work!
- ETL engineer
ETL is the first letter of three words, Chinese means extraction, conversion, loading
It can also be seen from the figure at the beginning that ETL engineers are the interface between business and data, so they need to deal with the relationship between upstream and downstream.
For the upstream, it is necessary to deal with the people of the business system frequently, so it is necessary to be familiar with the business system. For example, they have various interfaces, whether it is API level or database interface, which requires ETL engineers to understand very well. The second is its downstream, which means you're dealing with a lot of data development engineers, data scientists. For example, the prepared data (data cleaning, sorting, and fusion) will be handed over to downstream data development and data scientists.
Skills that need to be mastered
- Language: Java/Python (will be basic)
- Shell script (requires familiarity with shell)
- Linux (will use basic commands)
- Kettle (requires mastery)
- Sqoop (will use)
- Flume (will use)
- MySQL (familiar)
- Hive (familiar)
- HDFS (familiar)
- Oozie (task scheduling framework will use one of them, others such as azkaban, airflow)
- data analysis engineer
After the data engineer prepares the data and maintains the data warehouse, the data analyst comes into play.
Analysts will analyze and draw conclusions based on data and business conditions, formulate business strategies or build models to create new business value and support the efficient operation of the business.
At the same time, data analysts have three branches in the later stage: data crawlers, data mining and algorithm engineers.
Skills to be mastered:
- Mathematical knowledge (mathematical knowledge is the basic knowledge of data analysts, and needs to master statistics, linear algebra and other courses)
- Programming language (requires Python, R language)
- Analysis tools (Excel is a must, and visualization tools such as Tableau are also required)
- Data sensitivity (you must be sensitive to data, you can see its use and what value it can bring when you see it)
3. Big Data Interview
If you ask me to hire a big data engineer, the first thing I look at is not technology, but whether you have the ability to think independently, give you a project that you are not familiar with, whether you can quickly sort out the business logic, and whether you can complete the requirements. I’m repeating it again, because this is too important, our company has recruited two big data juniors. I don’t know if it’s a cross-industry reason or something else. The demand is always understood a little bit, or our business is more complicated. But the demand is not understood in place, and the technology is useless.
But then again, there is no way for you to review the demand in advance. You can only know what to do when the demand comes. Therefore, you can only examine the technology and your past project experience during the interview. You can see your opinion on this project through the projects you have done before. It mainly depends on whether or not the interviewer has a good relationship with the interviewer. There is no specific standard, because each person's project may be different. You can talk more about what you know in your project, and you can't talk less or don't talk at all. If the interviewer feels that you speak well, you have hope

But there are standards for technology. If you ask you a certain technical point, you will be yes, and no, you will not be
But when learning technology, you need to think more about why this technical point is implemented in this way and what are the benefits? Thinking more will make the brain more flexible. For example, Flink supports precise processing of semantics at one time, but everyone think deeply about how flink's precise processing is Some people say that it is achieved through a two-phase submission protocol. Yes, it is through this protocol. Then, think about the main content of this protocol and how the underlying algorithm is implemented. Think down step by step. , you will discover a new world.
Having said so much above, there are actually two points. The interview mainly examines technology and projects . Projects are also very important. On the one hand, you can check your technical mastery through projects, and on the other hand, you can check your understanding of projects. If you are not familiar with the projects in your resume, and you are stumbling, then you enter After the company, how can you quickly become familiar with the business in a short period of time?
Therefore, be sure to write the project on your resume, and be very familiar with the project!
Five minutes to learn big data public account dialog box: Interview , there will be a super full big data interview question with analysis!
4. Big Data Resume
For many fresh graduates, many of them write their resumes with student thinking, which is not only useless for job hunting, but also digs a lot of holes for themselves. Losing at the resume level is equivalent to losing a marathon at the starting line, and it will end before it starts.
Resume taboos:
- Haitou resume
Don't send one resume intact to dozens of businesses. The result of this is often a dead end.
Job-hunting emphasizes "person-post matching" , that is, the personal quality of the interviewee is highly consistent with the job requirements. It is necessary to modify the resume appropriately according to the job requirements to improve the job matching degree.
- Resume is pointless
An excellent resume should be one that knows how to "give up" . You don't need to list all the events and experiences of your university in the past few years, but you should choose according to the needs of the company and the position, select the most matching experience and present it in a large space.
How to write a resume:
Here comes the point! ! ! When writing a resume, you must use the four principles and the STAR rule !
What are the four principles and what is the STAR rule, then we will analyze it item by item:
Four principles :
- keyword principle
The keyword principle refers to using more industry terms or professional vocabulary into your experience description to highlight your professionalism and familiarity with the industry.
- verb principle
Verbs are the soul of a sentence and one of the most important criteria for interviewers to judge whether your personal experience is true. In the experience description, pay attention to the choice of verbs , and the most accurate verbs can convey the value of your experience.
For example, the verbs "engage", "accumulate" and "get" that indicate one's own behavior seem to be used in all jobs, but the uniqueness of this experience cannot be seen at all.
To demonstrate the truth and value of your experience, verbs that are sufficiently specialized are a plus.
- number principle
The use of numbers is actually a good plus point for your resume. The meaning of numbers is to quantify your experience. Rich numbers are more convincing than flashy adjectives .
Numbers can generally be used in three dimensions: value, time, and quantity.
Remember, quantify everything that can be quantified, and use data to show your rich experience.
- result principle
Many students ignore the final result of their experience when describing their experience, but the result is one of the important evidences to prove the value of your experience .
STAR Law 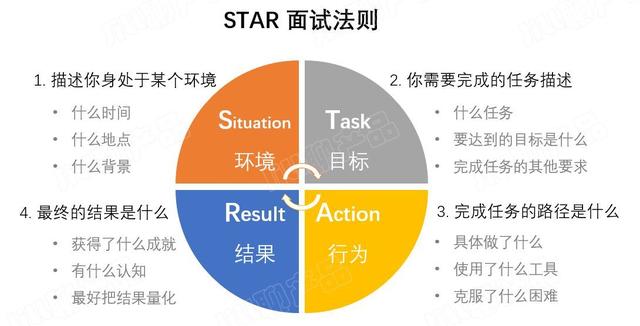 Situation Project Background
Situation Project Background
Tell us about how good your platform and team are to demonstrate how well you've been recognized.
Task project goal
Introduce your specific goals and vision for this activity, sometimes combined with the previous section.
Action what did you do
Explain what kind of efforts you have made in the team, what role you have played, and what role you have played, so as to show your personal strength and your growth and experience in the team. This part is often the most important.
Result what is the result
Explain what kind of work you have finally achieved, and you can refer to the "Four Principles" in the previous section.
Five minutes to learn big data public account dialog box: resume , there will be dozens of big data resume templates for your reference!
Finally, I will give you some high-profile keywords and verbs, just for entertainment :

Note: The following words can be used in resumes and interviews, but don’t overdo them!
High-quality nouns: life cycle, value transformation, strengthening cognition, resource tilting, improving logic, abstracting and transparent transmission, multiplexing, business model, rapid response, qualitative and quantitative, critical path, decentralization, result-oriented, Verticals, Attribution Analysis, Experience Metrics, Information Barriers, Resource Integration
High-force verbs: review, empower, support, precipitate, push back, land, connect, collaborate, feed back, be compatible, package, reorganize, perform, respond, quantify, layout, link, subdivide, sort, output, accelerate , co-construction, support, fusion, aggregation, integration, benchmarking, focusing, grasping, dismantling, abstracting, exploring, refining, opening up, penetrating, penetrating, migrating, distributing, distributing, radiating, surrounding, reusing, Penetration, expansion, development, solid, co-creation, co-construction, decoupling, integration, alignment, alignment, focus, give, get, die
What do you think of these words.

Finally, here comes an interviewer's death question:
What is the underlying logic of your question? Where is the top-level design? What is the final delivered value? Where is the starting point of the process? How to ensure the answer is closed loop? Where do you stand out from others? Where are the advantages? What are your thoughts and precipitations? Would it be different for me to ask this question? Where is your unique value?

Discuss
What is the reason you are engaged in big data work, because of this major in university? Big data is more popular and learning? Big data pays high wages to change careers? Welcome to leave your message in the comment area!