This article mainly introduces Batch Normalization in deep learning from the aspects of theory and actual combat, and
uses the MNIST dataset as a practical explanation. By comparing the performance of the network before and after adding Batch Normalization, everyone can have a more intuitive understanding of the role and effect of Batch Normalization. feel.
Batch Normalization, referred to as BN,
the original paper "Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift"
1 Overview
Normalization is a large class of methods used to make the samples input into a machine learning model more similar to each other, which helps the model learn and generalize to new data.
The most common form of data normalization: subtracting the data by its mean to center it at 0, then dividing the data by its standard deviation to make it a standard deviation of 1. In practice, this approach assumes that the data follows a normal distribution (also known as a Gaussian distribution ), and ensures that the distribution is centered at 0 and scaled to have a variance of 1.
normalized_data = (data - np.mean(data, axis=...)) / np.std(data, axis=...)
The most common data standardization is to standardize the data before inputting the data into the model, but if the output data changes after each transformation of the network, data standardization should be considered.
2. Batch Normalization
Batch normalization is a type of layer proposed by Ioffe and Szegedy in 2015, which can adaptively normalize the data output by each layer even if the mean and variance change over time during training.
Batch normalization works by internally keeping an exponential moving average of the mean and variance of each batch of data reads during training. The main effect of batch normalization is that it facilitates gradient propagation (much like residual connections), thus allowing deeper networks. For some particularly deep networks, training can only be performed if multiple BatchNormalization layers are included. For example, BatchNormalization is widely used in many advanced convolutional neural network
architectures built into Keras, such as ResNet50, Inception V3, and Xception.
**Internal Covariate Shift
The author of the BN paper believes that the continuous change of parameters in the network training process leads to changes in the input distribution of each subsequent layer, and the learning process must make each layer adapt to the input distribution, so we have to reduce the learning rate and initialize carefully. . The author calls the change in distribution an internal covariate shift .
In deep learning, due to the complexity of the problem, we often use a deeper network for training. As the training progresses, the parameters in the network are constantly updated as the gradient drops.
On the one hand, when the parameters in the underlying network change slightly, due to the linear transformation and nonlinear activation mapping in each layer, these weak changes are amplified as the number of network layers deepens (similar to the butterfly effect);
On the other hand, changes in parameters lead to changes in the input distribution of each layer, and the upper network needs to constantly adapt to these distribution changes, making our model training difficult. The above phenomenon is called Internal Covariate Shift.
Since the upper network needs to be continuously adjusted to adapt to changes in the distribution of input data, the learning speed of the network is reduced. To alleviate the problem of ICS, it is necessary to understand the cause of it. The reason is that the distribution of input values in each layer of the network is changed due to parameter updates, and it becomes more serious as the number of network layers deepens. Therefore, We can mitigate the ICS problem by fixing the distribution of network input values at each layer .
3. Algorithm definition and introduction
In deep learning, since the training method of loading data at one time requires a lot of memory, and the training time of each round is too long, it is generally used to divide the data and train the network with mini-batch. Therefore, Batch Normalization is also calculated on the basis of mini-batch.
The traditional neural network just standardizes x (subtracts the mean and divides the standard deviation) before inputting the sample x into the input layer to reduce the variability between samples. On this basis, BN not only standardizes the input data x of the input layer, but also standardizes the input of each hidden layer, as shown in the figure below:

We focus on the jth dimension of the current layer, that is, the jth neuron Meta node, normalize the current dimension:

Through the above transformation, we normalize the data in a more simplified way, so that the distribution mean of each feature of the input of the L layer is 0, and the variance is 1.
Although the above operations have alleviated the ICS problem and stabilized the input data distribution of each layer of the network, it has led to the lack of data expression ability.
On the one hand, the representation ability of the network is changed through the transformation operation, so that the parameter information learned by the underlying network is lost. On the other hand, by making the mean value of the input distribution of each layer 0 and the variance 1, the input will easily fall into the linear region of the nonlinear activation function when passing through the sigmoid or tanh activation function.
Therefore, BN introduces two learnable parameters γ and β. The introduction of these two parameters is to restore the expressive ability of the data itself and perform linear transformation on the normalized data: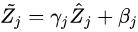
The above two steps are the algorithmic process of the entire Batch Normalization in model training, which ensures the expressiveness of the input data.
4. Advantages of Batch Normalization
(1) BN makes the distribution of input data of each layer in the network relatively stable, and accelerates the learning speed of the model;
BN makes the mean and variance of the input data of each layer of the network within a certain range through normalization and linear transformation, so that the latter layer of network does not have to constantly adapt to changes in the input of the underlying network, thus realizing the network between layers. Decoupling allows each layer to learn independently, which is beneficial to improve the learning speed of the entire neural network.
(2) BN allows the network to use saturated activation functions (such as sigmoid, tanh, etc.) to alleviate the problem of gradient disappearance;
(3) BN has a certain regularization effect and can discard Dropout
In Batch Normalization, since we use the mean and variance of the mini-batch as an estimate of the mean and variance of the overall training sample, although the data in each batch is sampled from the overall sample, the mean and variance of different mini-batch The variance will be different, which adds random noise to the learning process of the network, which is similar to the noise that Dropout brings to network training by turning off neurons, and it has a regularizing effect on the model to a certain extent.
The original author also proved that after the network is added to BN, Dropout can be discarded, and the model also has a good generalization effect.
5. Actual combat
The actual combat part uses the MNIST data set, and uses the Batch Normalization structure in TensorFlow to implement BN. The specific code is as follows:
import numpy as np
import pandas as pd
import tensorflow as tf
import tqdm
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings("ignore")
%matplotlib inline
#tensorflow.examples.tutorials is now deprecated and
# it is recommended to use tensorflow.keras.datasets
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True) #此方法将被启用
# mnist = tf.keras.datasets.mnist #推荐使用此方法
# (X_train, y_train), (X_test, y_test) = mnist.load_data()
Build a model
Define the class of the neural network, which mainly includes the following methods:
build_network: forward calculation
fully_connected: fully connected calculation
train: training model
test: test model
class NeuralNetWork():
def __init__(self, initial_weights, activation_fn, use_batch_norm):
"""
初始化网络对象
:param initial_weights: 权重初始化值,是一个list,list中每一个元素是一个权重矩阵
:param activation_fn: 隐层激活函数
:param user_batch_norm: 是否使用batch normalization
"""
self.use_batch_norm = use_batch_norm
self.name = "With Batch Norm" if use_batch_norm else "Without Batch Norm"
self.is_training = tf.placeholder(tf.bool, name='is_training')
# 存储训练准确率
self.training_accuracies = []
self.build_network(initial_weights, activation_fn)
def build_network(self, initial_weights, activation_fn):
"""
构建网络图
:param initial_weights: 权重初始化,是一个list
:param activation_fn: 隐层激活函数
"""
self.input_layer = tf.placeholder(tf.float32, [None, initial_weights[0].shape[0]])
layer_in = self.input_layer
# 前向计算(不计算最后输出层)
for layer_weights in initial_weights[:-1]:
layer_in = self.fully_connected(layer_in, layer_weights, activation_fn)
# 输出层
self.output_layer = self.fully_connected(layer_in, initial_weights[-1])
def fully_connected(self, layer_in, layer_weights, activation_fn=None):
"""
抽象出的全连接层计算
"""
# 如果使用BN与激活函数
if self.use_batch_norm and activation_fn:
weights = tf.Variable(layer_weights)
linear_output = tf.matmul(layer_in, weights)
# 调用BN接口
batch_normalized_output = tf.layers.batch_normalization(linear_output, training=self.is_training)
return activation_fn(batch_normalized_output)
# 如果不使用BN或激活函数(即普通隐层)
else:
weights = tf.Variable(layer_weights)
bias = tf.Variable(tf.zeros([layer_weights.shape[-1]]))
linear_output = tf.add(tf.matmul(layer_in, weights), bias)
return activation_fn(linear_output) if activation_fn else linear_output
def train(self, sess, learning_rate, training_batches, batches_per_validate_data, save_model=None):
"""
训练模型
:param sess: TensorFlow Session
:param learning_rate: 学习率
:param training_batches: 用于训练的batch数
:param batches_per_validate_data: 训练多少个batch对validation数据进行一次验证
:param save_model: 存储模型
"""
# 定义输出label
labels = tf.placeholder(tf.float32, [None, 10])
# 定义损失函数
cross_entropy = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits_v2(labels=labels,
logits=self.output_layer))
# 准确率
correct_prediction = tf.equal(tf.argmax(self.output_layer, 1), tf.argmax(labels, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
#
if self.use_batch_norm:
with tf.control_dependencies(tf.get_collection(tf.GraphKeys.UPDATE_OPS)):
train_step = tf.train.GradientDescentOptimizer(learning_rate).minimize(cross_entropy)
else:
train_step = tf.train.GradientDescentOptimizer(learning_rate).minimize(cross_entropy)
# 显示进度条
for i in tqdm.tqdm(range(training_batches)):
batch_x, batch_y = mnist.train.next_batch(60)
sess.run(train_step, feed_dict={
self.input_layer: batch_x,
labels: batch_y,
self.is_training: True})
if i % batches_per_validate_data == 0:
val_accuracy = sess.run(accuracy, feed_dict={
self.input_layer: mnist.validation.images,
labels: mnist.validation.labels,
self.is_training: False})
self.training_accuracies.append(val_accuracy)
print("{}: The final accuracy on validation data is {}".format(self.name, val_accuracy))
# 存储模型
if save_model:
tf.train.Saver().save(sess, save_model)
def test(self, sess, test_training_accuracy=False, restore=None):
# 定义label
labels = tf.placeholder(tf.float32, [None, 10])
# 准确率
correct_prediction = tf.equal(tf.argmax(self.output_layer, 1), tf.argmax(labels, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
# 是否加载模型
if restore:
tf.train.Saver().restore(sess, restore)
test_accuracy = sess.run(accuracy, feed_dict={
self.input_layer: mnist.test.images,
labels: mnist.test.labels,
self.is_training: False})
print("{}: The final accuracy on test data is {}".format(self.name, test_accuracy))
Add the auxiliary function train_and_test and the plot drawing function to start testing BN:
def train_and_test(use_larger_weights, learning_rate, activation_fn, training_batches=50000, batches_per_validate_data=500):
"""
使用相同的权重初始化生成两个网络对象,其中一个使用BN,另一个不使用BN
:param use_larger_weights: 是否使用更大的权重
:param learning_rate: 学习率
:param activation_fn: 激活函数
:param training_batches: 训练阶段使用的batch数(默认为50000)
:param batches_per_validate_data: 训练多少个batch后在validation数据上进行测试
"""
if use_larger_weights:
# 较大初始化权重,标准差为10
# 构造一个4层神经网络,输入层结点数784,三个隐层均为128维,输出层10个结点
weights = [np.random.normal(size=(784,128), scale=10.0).astype(np.float32),
np.random.normal(size=(128,128), scale=10.0).astype(np.float32),
np.random.normal(size=(128,128), scale=10.0).astype(np.float32),
np.random.normal(size=(128,10), scale=10.0).astype(np.float32)
]
else:
# 较小初始化权重,标准差为0.05
weights = [np.random.normal(size=(784,128), scale=0.05).astype(np.float32),
np.random.normal(size=(128,128), scale=0.05).astype(np.float32),
np.random.normal(size=(128,128), scale=0.05).astype(np.float32),
np.random.normal(size=(128,10), scale=0.05).astype(np.float32)
]
tf.reset_default_graph()
nn = NeuralNetWork(weights, activation_fn, use_batch_norm=False) # Without BN
bn = NeuralNetWork(weights, activation_fn, use_batch_norm=True) # With BN
with tf.Session() as sess:
tf.global_variables_initializer().run()
print("【Training Result:】\n")
nn.train(sess, learning_rate, training_batches, batches_per_validate_data)
bn.train(sess, learning_rate, training_batches, batches_per_validate_data)
print("\n【Testing Result:】\n")
nn.test(sess)
bn.test(sess)
plot_training_accuracies(nn, bn, batches_per_validate_data=batches_per_validate_data)
Full code address:
https://colab.research.google.com/drive/1UoWhUMrlqSz91Y4BIdU45wuaW7GXUBgr#scrollTo=YKuk7rsYozgy
Mainly control three variables:
- Weight matrix (smaller initialization weights, standard deviation is 0.05; larger initialization weights, standard deviation is 10)
- Learning rate (minimum learning rate: 0.01; maximum learning rate: 2)
- Hidden layer activation function (relu, sigmoid)
Using different weights and learning rates, the test results are as follows:
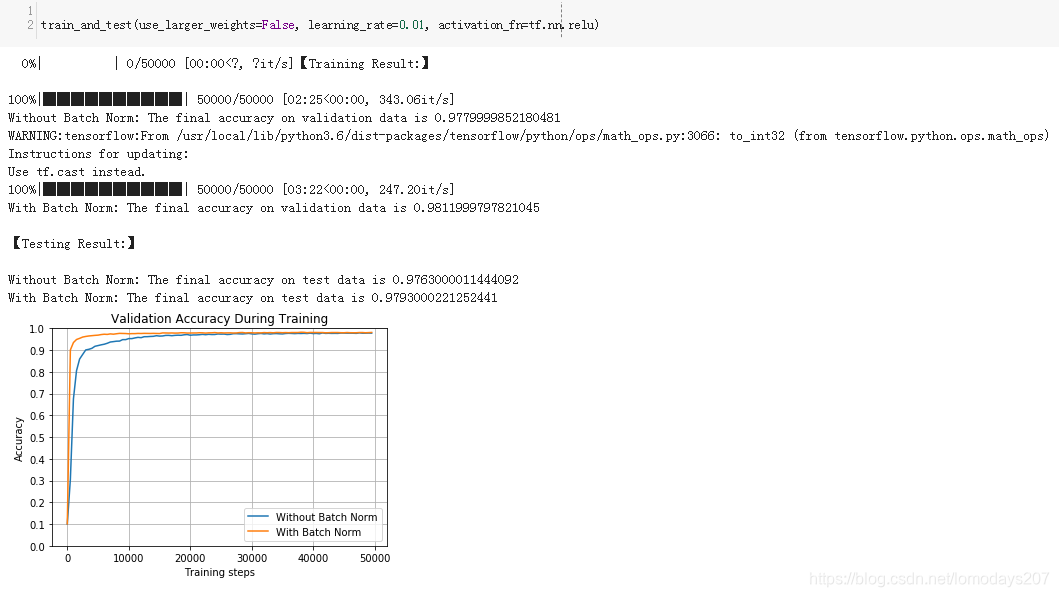
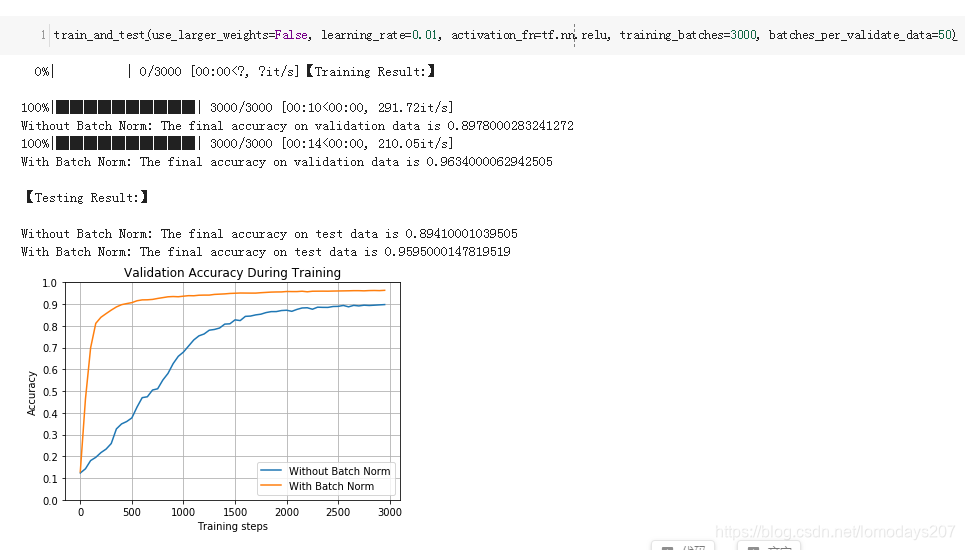
5 References
【1】Batch Normalization principle and practice
https://zhuanlan.zhihu.com/p/34879333
[2] Batch Normalization in Deep Learning
https://blog.csdn.net/whitesilence/article/details/75667002
【3】《Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift》
