After a few weeks of python crawler practice, the author has studied scrapy, a crawler framework, and now summarizes some basic knowledge and codes for later inspection.
1. Download and install scrapy
The common method is to use pip install scrapy (the latest version will be automatically downloaded if the version number is not specified). The installation in the following figure has been manually canceled because the author has it on his computer. . . .
Since the author also needs to use some packages for python data analysis, numpy, etc., so he is lazy and installs anaconda directly. Small partners without foundation can also use this method. The download and installation of anaconda is the same as that of ordinary software, and it comes with some Commonly used libraries, avoid installation troubles (so lazy)
2. Scrapy command line usage
Many blogs on the Internet have summaries in this part. You don't need to memorize them. You can use the main commands (startproject crawl fetch list genspider.....) to understand. Below are some commands in common scenarios. Pay attention to the project commands and global The difference between the commands is the difference between the literal meanings.
2.1startproject: This command is used to create a scrapy project. Enter the directory where you want to create the code in the console, and enter the command: scrapy startproject firstspide r can be created. After the project is created, files and files such as items pipeline spider are automatically generated folder, the detailed role of these files will be discussed later.
2.2 genspider: This command is used to create a crawler file. Enter the firstspider folder and you can see that there is a spider folder. This folder stores the specific crawler. The genspider command will create a crawler under the spider folder. Enter cd firstspider/firstspider in the created directory; ; The screenshot of the successful execution of the scrapy genspider -t basic spiderone command is as follows:
It needs to be explained here that the function of the -t parameter is to create your own crawler based on the built-in crawler template. There are four native templates: basic crawl xmlfeed and csvfeed, which can be viewed with the scrapy genspider -l command. Note, friends can understand through official documents, we generally choose basic or crawl.
2.3 list: This command is not difficult, the function is to check which crawlers are available under this scrapy project, try it yourself, you can see the spiderone created in 2.2
2.4 crawl: This command starts the crawler. After we create the spider file spiderone.py, we can use the command scrapy crawl spiderone to start execution after writing the code according to the functional requirements
2.5 fetch is used to display the crawling process. It is a global command that can be run regardless of whether there is a project. The example is as follows: scrapy fetch http://www.baidu.com
More commands can be viewed with scrapy -h. It is worth noting that the results seen with scrapy -h in the project folder are different from those seen outside the project folder, the difference between global and project commands.
3. Scrapy main file function
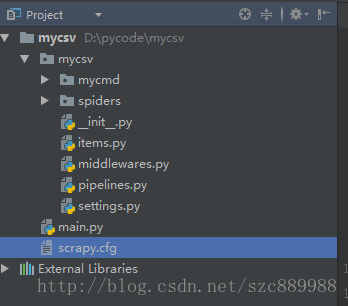
This is the basic structure of a scrapy project. The function of the file items.py is to save the crawled data into the item object, which is equivalent to a container for storing the crawled data. To store several fields, fieldize these fields respectively. Yes, for example:
name = scrapy.Field()
email = scrapy.Field()
settings.py is the control file for some configuration options of the project, such as the proxy IP pool, whether to follow the robot protocol of the crawled website, etc. The small partners will know when they encounter specific needs. The crawler file is in the spider folder, and main.py is a file created by the author to start the crawler. I said before that the crawl command can be started, but after editing pycharm, we want to run it in pycharm, so we create such a file as a driver. The content of main.py is as follows
# coding:utf-8
from scrapy import cmdline
cmdline.execute("scrapy crawl spiderone".split())
The essence is to call the crawl command through the console interface of python.
The basic introduction is here, take the time to write some crawler code that is actually applied to scrapy, and customize the method of creating commands.
Personal learning experience, if there is any mistake, light spray.