I don't read much, so don't lie to me. This may be the best sentence for us. Last night, I chatted with the former Minister Cheung Tsai, and learned that he is now doing search engine optimization and works in that company, and he told me about his professional knowledge. But because I read too little books, I can't understand many professional terms. I even heard the word crawler for a while. Fortunately, I remember that crawler is a must for search engines. I checked it out today while reading the book on automata.
3. Grab strategy
In a crawler system, the queue of URLs to be crawled is an important part. The order in which the URLs in the queue of URLs to be crawled are arranged is also an important issue, because it involves which page to crawl first and which page to crawl later. The method of determining the order in which these URLs are arranged is called a crawling strategy. The following highlights several common crawling strategies:
1. Depth-first traversal strategy
The depth-first traversal strategy means that the web crawler will start from the start page, follow one link by one link, and then go to the next start page after processing the line, and continue to follow the link. Let's take the following figure as an example:
Path traversed: AFG EHI BCD
2. Breadth-first traversal strategy
The basic idea of breadth-first traversal is to insert links found in newly downloaded web pages directly at the end of the queue of URLs to be crawled. That is to say, the web crawler will first crawl all the webpages linked in the starting webpage, and then select one of the linked webpages, and continue to crawl all the webpages linked in this webpage. Or take the above picture as an example:
Traversal path: ABCDEF GHI
Well, the reptiles are here, and I was stunned for a while. Below is the inverted index.Forward and Inverted Indexes
Let's first look at what an inverted index is and the difference between an inverted index and a positive index:
We know that the key step for a search engine is to establish an inverted index. The so-called inverted index is generally expressed as a keyword, followed by its frequency (the number of times it appears), its location (in which article or webpage it appears, and information about the date, author, etc.), it is equivalent to making an index for hundreds of billions of web pages on the Internet, just like a book's table of contents and tags. Readers who want to see a chapter related to a topic can find the relevant page directly according to the table of contents. There is no need to search page by page from the first page to the last page of the book.
Next, explain the difference between the forward index and the inverted index:
General index (forward index)
正排表是以文档的ID为关键字,表中记录文档中每个字的位置信息,查找时扫描表中每个文档中字的信息直到找出所有包含查询关键字的文档。正排表结构如图1所示,这种组织方法在建立索引的时候结构比较简单,建立比较方便且易于维护;因为索引是基于文档建立的,若是有新的文档假如,直接为该文档建立一个新的索引块,挂接在原来索引文件的后面。若是有文档删除,则直接找到该文档号文档对因的索引信息,将其直接删除。但是在查询的时候需对所有的文档进行扫描以确保没有遗漏,这样就使得检索时间大大延长,检索效率低下。
尽管正排表的工作原理非常的简单,但是由于其检索效率太低,除非在特定情况下,否则实用性价值不大。
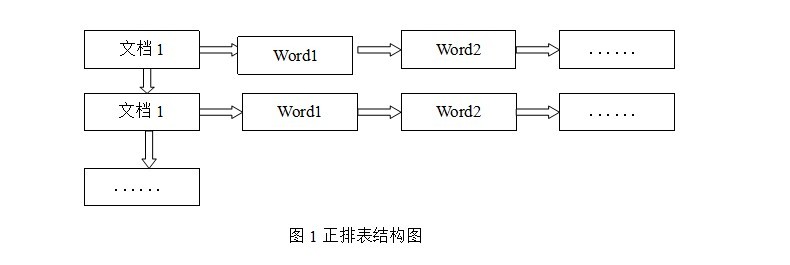
倒排索引
倒排表以字或词为关键字进行索引,表中关键字所对应的记录表项记录了出现这个字或词的所有文档,一个表项就是一个字表段,它记录该文档的ID和字符在该文档中出现的位置情况。由于每个字或词对应的文档数量在动态变化,所以倒排表的建立和维护都较为复杂,但是在查询的时候由于可以一次得到查询关键字所对应的所有文档,所以效率高于正排表。在全文检索中,检索的快速响应是一个最为关键的性能,而索引建立由于在后台进行,尽管效率相对低一些,但不会影响整个搜索引擎的效率。
倒排表的结构图如图2:
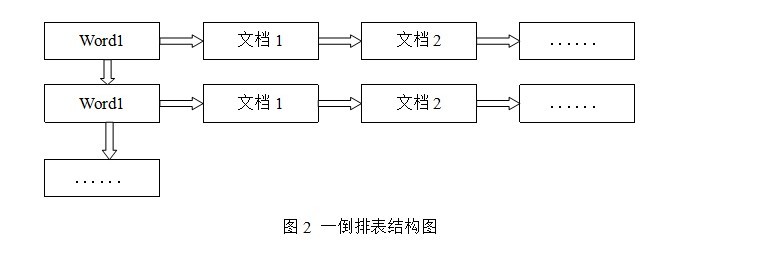
倒排表的索引信息保存的是字或词后继数组模型、互关联后继数组模型条在文档内的位置,在同一篇文档内相邻的字或词条的前后关系没有被保存到索引文件内。