Search engine overview inverted index
Consider the device for personal use in the future. It will be a mechanized personal library. It needs a name to attract people's attention: "MEMEX" is fine. MEMEX is such a mechanized device in which people can store books, records and letters , At the same time, it can complete retrieval with high speed and strong flexibility. As an auxiliary device, it is the infinite expansion of the human brain. ——Bush, 1945
When it comes to improving retrieval efficiency, the index must be mentioned. Today I will tell you about the most common indexing method in search engines-the inverted index.
In the age of no index, you have
entered a bookstore. The books in this bookstore are just arranged in a mess. Now you want to find a book called "Spring in action". What do you want to do? Hmm...Yes, you can only read book by book until you reach this book. As a result, you turned to the last one to find that this bookstore did not have the book you wanted. You have spent a whole day here (fortunately, this bookstore is not big), you cursed "fucking" with exhaustion and left this bookstore.
This way of retrieving information (or searching) without any index, we can call it grep. The grep command we generally use in UNIX-like systems is used to search in a similar way, as is the text search (Ctrl+F) commonly used in win systems. For a computer, the speed of scanning the entire file will be much faster than that of a person flipping through the entire bookstore, so it is sufficient when retrieving a small amount of information (for example, the information of a single text file). But when the amount of information becomes very large, it will become very slow. For example, the grep command in UNIX-like systems may be unbearably slow when scanning large folders.
Traditional Index
You really need the book "Spring in Action", and today you have come to a library that looks very old. This library has a lot of books, but there is no library management information system, but they have their own index system-title and bibliographic retrieval cabinet. It's probably something like this:

When you recall, you seem to have seen this thing when you were young (probably, at the end of the last century). Each drawer on this cabinet corresponds to a category, such as history, law, computer, and so on. You find the computer sorting drawer, and then you open the drawer, and you see a lot of cards in it:

These cards are separated by large lettered card groups, which are divided into 26 groups. You know this means that each group is information about books whose titles start with a certain letter or a certain pinyin. These cards are called index cards. These cards are sorted in alphabetical or pinyin order. With this sorting, you will soon find the book "Spring in action" from the S group. Then according to the instructions on the storage location of the book on the index card, the book was quickly found. You went home contented~
This indexing technology is actually the same as the traditional indexing technology on the computer. This is equivalent to indexing the classification information and title information of the books. And it is also a joint index. We also found a limitation of the joint index, that is, the joint index is sequential. For example, you index the classification first, and then index the book title. At this time, when you are searching, if you do not search the category first, but search the title of the book first, this index will not work. Another enlightenment for us is that the reason why the index is fast is because of order (from a computer perspective, order can use binary search, which is very efficient).
Vocabulary document matrix After
reading "Spring in Action", you still want to learn more about dependency injection, but you don't know what book will cover this part. You want to go to the library and look for it again. Then you came to the old library again, you opened the computer sorting drawer again, looked at the thousands of cards, and fell into deep contemplation...I can't find it at all...this and What's the difference between the bookstore? What's more, you may not see much by looking at the title.
We found that your needs have changed at this moment. You are not looking for a specific book, you are looking for a book with a certain topic. The subject may be a sentence or a word. And we found that the smallest composition granularity of a sentence is also a word (or word). So we found that what we ultimately need to do is to index words. So what are we going to do? First, we can make a "word-document matrix", the abscissa is the document id, and the ordinate is the specific vocabulary:
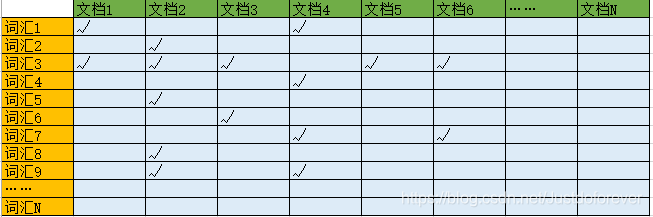
We can arrange the vocabulary on the ordinate in an orderly manner (for example, in alphabetical/pinyin order), so that we can quickly locate a vocabulary. Then we go to find out which documents correspond to these vocabulary. But the "word-document matrix" is just a conceptual model. How do we use data structures to implement this concept in a computer?
The easiest way is to save it directly. First store an ordered array of document ids, and then store a vocabulary array. Then create a two-dimensional array, the length of the abscissa of the array is the same as the length of the document id array, and the length of the ordinate is the same as the vocabulary array, and then store 1 or 0 in the elements of this two-dimensional array. 1 means that the document at the corresponding position contains the corresponding position Vocabulary, 0 means not included. as the picture shows:
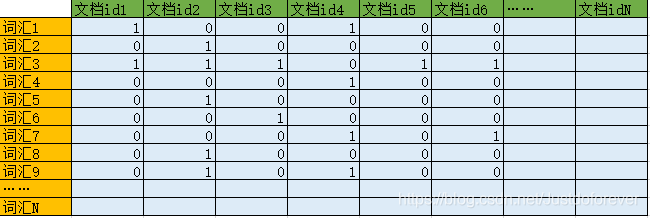
This implementation method is very simple, but it has a huge flaw. If we have 500,000 vocabularies and 1 million documents (this number is not large today), then we need at least 500,000 * 1 million = 500 billion bytes of storage space, which is At least 465gb of information, which is much larger than the amount of memory in a computer. This is simply unbearable.
Inverted index
So how do we optimize this structure? It is not difficult to find that this matrix actually has a high degree of sparsity (a large number of values are 0). After all, it is impossible for every book to have 500,000 different words. If you consider a large number of papers or blogs, it may not be easy to have 1,000 different words in an average document. This means that 99% of the elements in this matrix are 0. In this way, it is easy for us to think that we can only record those 1's. In other words, we only need to record documents that contain this vocabulary according to the vocabulary. In this way, we also need to maintain a vocabulary array, and then each element (that is, each vocabulary) in the vocabulary array will correspond to a document list. In this document list, the id of the document with this vocabulary is stored. This greatly saves storage space. The structure is as follows:
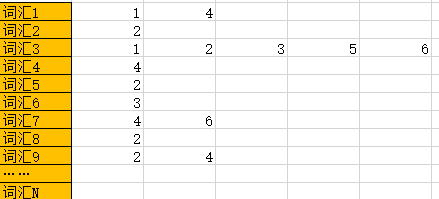
The above are some basic concepts of inverted index. In fact, the inverted index is an index model that was invented a long time ago. In 1958, IBM demonstrated an "automatic indexing machine" at a conference. Although this indexing method was born very early, it is still one of the important foundations of full-text indexing.