HDFS has the following advantages:
1. High fault tolerance
- Data is automatically saved in multiple copies. It improves fault tolerance by adding replicas.
- After a certain copy is lost, it can be automatically recovered, which is realized by the internal mechanism of HDFS, and we don't need to care about it.
2. Suitable for batch processing
- It is by mobile computing not mobile data.
- It exposes the data location to the computing framework.
3. Suitable for big data processing
- Process data at GB, TB, and even petabyte levels.
- It can handle the number of files over a million scale, which is quite large.
- Able to handle the scale of 10K nodes.
4. Streaming file access
- Write once, read many times. Once a file is written, it cannot be modified, only appended.
- It ensures data consistency.
5. Can be built on cheap machines
- It improves reliability through a multi-copy mechanism.
- It provides fault tolerance and recovery mechanisms. For example, if a copy is lost, it can be recovered by other copies.
Of course, HDFS also has its disadvantages and is not suitable for all occasions:
1. Low latency data access
- For example, to store data in milliseconds, this is not acceptable, it cannot be done.
- It is suitable for high throughput scenarios, that is, writing a large amount of data in a certain period of time. But it is not feasible in the case of low latency, such as reading data within milliseconds, so it is difficult to do.
2. Small file storage
- If you store a large number of small files (the small files here refer to files smaller than the block size of the HDFS system (default 64M)), it will occupy a lot of memory of the NameNode to store file, directory and block information. This is not desirable because the NameNode's memory is always limited.
- The seek time for small file storage can exceed the read time, which violates the design goals of HDFS.
3. Concurrent writing, random file modification
- A file can only have one write, and multiple threads are not allowed to write at the same time.
- Only data append (append) is supported, random modification of files is not supported.
How HDFS stores data
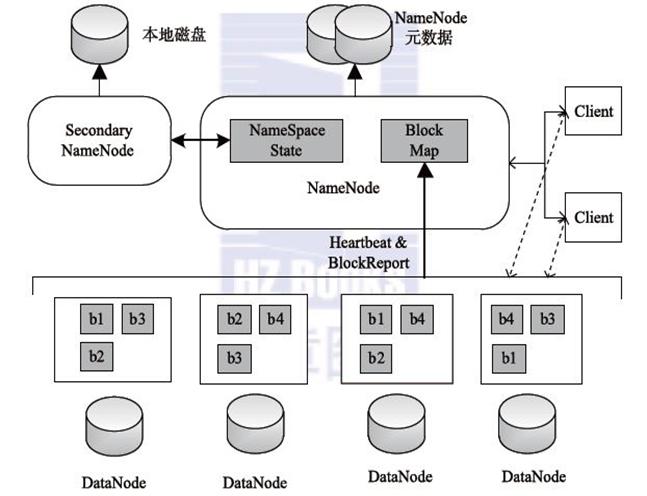

HDFS uses the Master/Slave architecture to store data. This architecture is mainly composed of four parts, namely HDFS Client, NameNode, DataNode and Secondary NameNode. Below we describe these four components
1. Client: It is the client.
- 文件切分。文件上传 HDFS 的时候,Client 将文件切分成 一个一个的Block,然后进行存储。
- 与 NameNode 交互,获取文件的位置信息。
- 与 DataNode 交互,读取或者写入数据。
- Client 提供一些命令来管理 HDFS,比如启动或者关闭HDFS。
- Client 可以通过一些命令来访问 HDFS。
2、NameNode:就是 master,它是一个主管、管理者。
- 管理 HDFS 的名称空间
- 管理数据块(Block)映射信息
- 配置副本策略
- 处理客户端读写请求。
3、DataNode:就是Slave。NameNode 下达命令,DataNode 执行实际的操作。
- 存储实际的数据块。
- 执行数据块的读/写操作。
4、Secondary NameNode:并非 NameNode 的热备。当NameNode 挂掉的时候,它并不能马上替换 NameNode 并提供服务。
- 辅助 NameNode,分担其工作量。
- 定期合并 fsimage和fsedits,并推送给NameNode。
- 在紧急情况下,可辅助恢复 NameNode。