computer executes the program, each instruction is executed in the CPU, and the process of executing the instruction will inevitably involve the reading and writing of data. Since the temporary data during the running of the program is stored in the main memory (physical memory), there is a problem at this time. Because the CPU executes very fast, the process of reading data from the memory and writing data to the memory is the same as that of the CPU. The speed of executing instructions is much slower than that, so if the operation of data is performed through interaction with memory at any time, it will greatly reduce the speed of instruction execution. So there is a cache in the CPU.
That is, when the program is running, it will copy the data needed for the operation from the main memory to the cache of the CPU, then the CPU can directly read data from its cache and write to it when performing calculations. After the operation is completed, the data in the cache is flushed to the main memory.
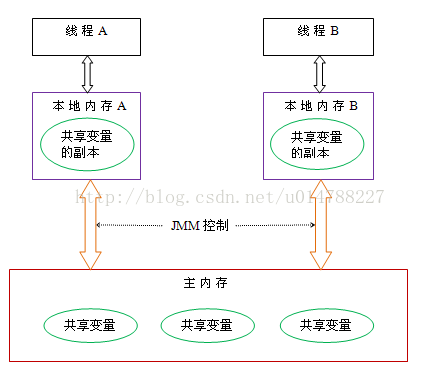
In the case of multiple threads, each thread has its own copy of the shared variable. For
example , the following code:
i = i + 1;
when the thread executes this statement, it will first read the value of i from the main memory, and then Copy a copy to the cache (the local memory in the above figure), then the CPU executes the instruction to add 1 to i, then writes the data to the cache, and finally flushes the latest value of i in the cache to the main memory.
Thread unsafe situation: Initially, two threads read the value of i and store it in the cache of their respective CPUs, then thread 1 adds 1, and then writes the latest value of i, 1, to memory. At this time, the value of i in the cache of thread 2 is still 0. After adding 1, the value of i is 1, and then thread 2 writes the value of i into memory.
The final result i has the value 1, not 2. This is the well-known cache coherency problem. Such variables that are accessed by multiple threads are often called shared variables.
Therefore, the premise of the thread safety problem:
the write operation of the shared variable If each thread operates its own variable and the modification of the variable does not affect it, there is no variable safety problem.
There is no thread safety problem in multi-threading and single-threading. The atomic operation of
non- atomic operations is not interrupted. In the case of multi-threading, only one thread operates, which is equivalent to a natural lock, but the execution speed is fast and the performance has little impact. It should be compiled with the underlying
Thread unsafe solution:
1) By adding LOCK lock to the bus, only one thread can access the lock, and other threads wait, and the performance is inversely proportional to the lock granularity.
Locks are the easiest way to do concurrency, but of course they are also the most expensive. The kernel state lock requires the operating system to perform a context switch. Locking and releasing the lock will cause more context switching and scheduling delays, and the thread waiting for the lock will be suspended until the lock is released. During context switching, the instructions and data previously cached by the CPU will be invalidated, resulting in a great loss of performance. The OS judging multithreaded locks is like two sisters arguing over a toy, and then the OS is the parent who can decide who can get their hands on the toy, which is slow. Userland locks avoid these problems, but they are only effective when there is no real contention.
Java used the synchronized keyword to ensure synchronization before JDK1.5. By using a consistent locking protocol to coordinate access to the shared state, it can ensure that no matter which thread holds the lock of the guard variable, it adopts an exclusive way to To access these variables, if multiple threads access the lock at the same time, the first thread will be suspended. When the thread resumes execution, it must wait for other threads to execute their time slices before they can be scheduled for execution. There is a significant overhead in the recovery execution process. Locks have other drawbacks as well. While a thread is waiting for a lock, it cannot do anything. If a thread is delayed while holding a lock, all threads that need the lock cannot continue to execute. If the blocked thread has a high priority and the thread holding the lock has a low priority, Priority Inversion will result.
Optimistic locking and pessimistic locking
An exclusive lock is a pessimistic lock, and synchronized is an exclusive lock, which assumes the worst case, and executes only when it is guaranteed that other threads will not interfere, which will cause all other threads that need the lock to hang, waiting for a hold. The thread that has the lock releases the lock. Another more efficient lock is optimistic locking. The so-called optimistic locking is to complete an operation without locking each time but assuming that there is no conflict. If it fails due to a conflict, it will retry until it succeeds.
2) Through the cache coherence protocol The
core idea is: when the CPU writes data, if it finds that the variable being operated is a shared variable, that is, a copy of the variable exists in other CPUs, it will send a signal to notify other CPUs to cache the variable. The row is set to an invalid state, so when another CPU needs to read this variable and finds that the cache line that caches the variable in its own cache is invalid, it will re-read it from memory.
3) Lock-free and non-lease blocking algorithm There are many ways
to achieve a lock-free non-blocking algorithm, among which CAS (Compare and swap) is a well-known lock-free algorithm. CAS, CPU instruction, is used in most processor architectures, including IA32 and Space. The semantics of CAS are "I think the value of V should be A, if it is, then update the value of V to B, Otherwise, do not modify and tell what the value of V actually is", CAS is an optimistic locking technology, when multiple threads try to use CAS to update the same variable at the same time, only one of the threads can update the value of the variable, and all other threads fail, The failed thread is not suspended, but is told to fail this race and can try again. CAS has 3 operands, the memory value V, the old expected value A, and the new value B to be modified. Modify memory value V to B if and only if expected value A and memory value V are the same, otherwise do nothing.
The CAS operation is based on the assumption that the shared data will not be modified, and adopts a mode similar to the commit-retry of the database. This assumption can lead to a large performance improvement when the chance of synchronization conflicts is rare.
CAS is a CPU instruction-level operation, with only one atomic operation, so it is very fast. But there is a case of cache miss.
Related concepts
synchronized keyword
The synchronized keyword is to prevent multiple threads from executing a piece of code at the same time, which will greatly affect the efficiency of program execution.
Synchronized achieve thread safety is also conditional
The sample code is as follows:
Public synchronized void methodAAA()
{
//….
}
This is also the synchronization method, which object is synchronized locked at this time? It locks the object that calls this synchronized method. That is, when an object P1 is in a different thread
When this synchronization method is executed, mutual exclusion will be formed between them to achieve the effect of synchronization. However, another object P2 generated by the Class to which this object belongs can call this object arbitrarily.
Synchronized keyword method.
The sample code above is equivalent to the following code:
public void methodAAA()
{
synchronized (this) // (1)
{
//…..
}
}
What does this in (1) refer to? It refers to the object on which this method is called, such as P1. It can be seen that the essence of the synchronization method is to apply synchronized to the object reference. --that
The thread that has obtained the P1 object lock can call the synchronization method of P1, but for P2, the P1 lock has nothing to do with it, and the program may also get rid of the control of the synchronization mechanism in this case, causing
data clutter
For specific analysis, see http://www.cnblogs.com/GnagWang/archive/2011/02/27/1966606.html
volatile variables
Compared to locks, volatile variables are a more lightweight synchronization mechanism because operations such as context switching and thread scheduling do not occur when using these variables, but volatile variables also have some limitations: they cannot be used to build atomic , so you can't use a volatile variable when a variable depends on an old value. Volatile variables can achieve thread safety (in certain cases), but their applications are limited.
Prerequisites
for Write operations to variables do not depend on the current value.
The variable is not contained in an invariant with other variables.
Volatile can only guarantee the visibility of variables to individual threads, but not atomicity.
Variables modified by the volatile keyword are not optimized by instruction reordering.
Visibility means that when multiple threads access the same variable, one thread modifies the value of the variable, and other threads can immediately see the modified value. When multiple threads need to determine which thread can execute based on a certain condition, make sure that this condition is visible between threads. Therefore, it can be decorated with volatile.
Ordered: The order in which the program is executed is executed in the order of the code. Generally speaking, in order to improve the efficiency of the program, the processor may optimize the input code. It does not guarantee that the execution order of each statement in the program is the same as the order in the code, but it will guarantee the final execution result of the program and the order of code execution. The results are consistent. In certain cases this can also lead to thread safety related issues.
Do not use volatile in getAndOperate situations (this situation is not atomic and needs to be locked again), only set or get scenarios are suitable for volatile.
For example, if you let a volatile integer increment (i++), it is actually divided into 3 steps: 1) read the value of the volatile variable to the local; 2) increase the value of the variable; 3) write the value of the local back to make it visible to other threads . The jvm instructions for these 3 steps are:
mov 0xc(%r10),%r8d ; Load
inc %r8d ; Increment
mov %r8d,0xc(%r10) ; Store
lock addl $0x0,(%rsp) ; StoreLoad Barrier
Note that the last step is a memory barrier.
A memory barrier is a CPU instruction. Basically, it's an instruction that: a) ensures the order in which some specific operations are performed; b) affects the visibility of some data (perhaps the result of some instructions). Compilers and CPUs can reorder instructions to optimize performance while maintaining the same output. Inserting a memory barrier is equivalent to telling the CPU and the compiler that those that precede this command must be executed first, and those that follow this command must be executed. Another function of the memory barrier is to force the cache of a different CPU to be updated once. For example, a write barrier flushes the data written before the barrier to the cache, so that any thread that tries to read the data will get the latest value, regardless of which CPU core or which CPU is executing it.
What is the relationship between memory barrier and volatile? As mentioned in the virtual machine instructions above, if your field is volatile, the Java memory model will insert a write barrier instruction after the write operation and a read barrier instruction before the read operation. This means that if you are writing to a volatile field, you must know: 1. Once you are done writing, any thread accessing the field will get the latest value. 2. Before you write, it is guaranteed that everything that happened before has happened, and any updated data values are also visible, because the memory barrier will flush the previously written values to the cache.
Comparison of volatile and synchronized
①volatile is lightweight and can only modify variables. Synchronized heavyweight, can also modify methods
②volatile can only guarantee the visibility of data and cannot be used for synchronization, because concurrent access to volatile-modified variables by multiple threads will not block.
Synchronized not only guarantees visibility, but also guarantees atomicity, because only the thread that has acquired the lock can enter the critical section, thus ensuring that all statements in the critical section are executed. Blocking occurs when multiple threads compete for synchronized lock objects.
Optimizing lock or lock-free design ideas in a high concurrency environment Three performance killers of
server -side programming: 1. Thread switching overhead caused by a large number of threads. 2. Lock. 3, unnecessary memory copy.
Under high concurrency, for pure memory operations, single thread is faster than multithreading. You can compare the sy and ni percentages of cpu under stress test for multithreaded programs. To achieve high throughput and thread safety in a high concurrency environment, there are two ideas: one is to use optimized locks, and the other is a lock-free lock-free structure. But non-blocking algorithms are much more complicated than lock-based algorithms. Developing a non-blocking algorithm is quite professional training, and it is extremely difficult to prove the correctness of the algorithm, which is not only related to the specific target machine platform and compiler, but also requires complex skills and rigorous testing. Although Lock-Free programming is very difficult, it can often lead to higher throughput than lock-based programming. So LockFree programming is a promising technology. It performs well in thread abort, priority inversion, and signal safety.
Example of optimized lock implementation: ConcurrentHashMap in Java, cleverly designed, uses a bucket-granular lock and lock separation mechanism to avoid locking the entire map in put and get, especially in get, only one HashEntry is locked. The improvement is obvious (for a detailed analysis, see "Exploring the Implementation Mechanism of ConcurrentHashMap High Concurrency").
Lock-free lock-free examples: the utilization of CAS (CPU's Compare-AndSwap instruction) and LMAX's disruptor lock-free message queue data structure, etc.
ConcurrentLinkedQueue uses CAS instructions, but its performance is not high because there are too many CAS operations
Reference :
http://www.cnblogs.com/Mainz/p/3546347.html
http://www.cnblogs.com/lucifer1982/archive/ 2008/03/23/1116981.html
http://www.cnblogs.com/Mainz/p/3556430.html
http://www.cnblogs.com/hapjin/p/5492880.html
http://blog.csdn.net/li295214001/article/details/48135939/
JAVA CAS principle in-depth analysis of concurrent implementation: http://blog.csdn.net/xinyuan_java/article/details/52161101