Here's a concrete example: Suppose you've learned from a 96x96 image the features of an 8x8 sample of it, assuming this is done by an autoencoder with 100 hidden units. In order to obtain convolution features, it is necessary to perform convolution operations on each 8x8 small image area of the 96x96 image. That is to say, extract an 8x8 small area, and mark it as (1, 1), (1, 2), ..., until (89, 89) from the starting coordinates, and then extract the extracted areas one by one. Run the trained sparse autoencoder to get the activations of the features. In this example, there are obviously 100 sets, each containing 89x89 convolutional features.
As shown in the figure below, it shows the process of convolution of a 3× 3 convolution kernel on a 5× 5 image. Each convolution is a feature extraction method, like a sieve, which filters out the parts of the image that meet the conditions (the larger the activation value, the better the conditions).

2: Speaking of pooling, in fact, pooling is very easy to understand, first look at the picture:
Reprinted from: http://blog.csdn.net/silence1214/article/details/11809947
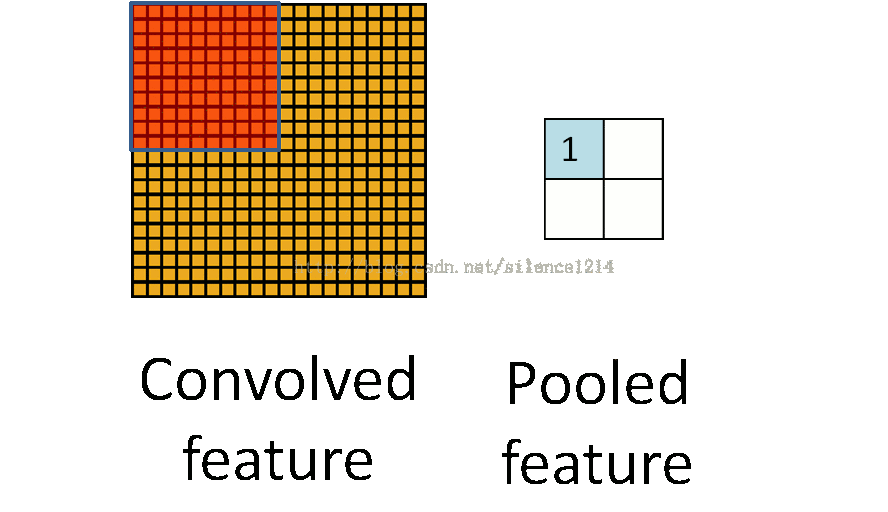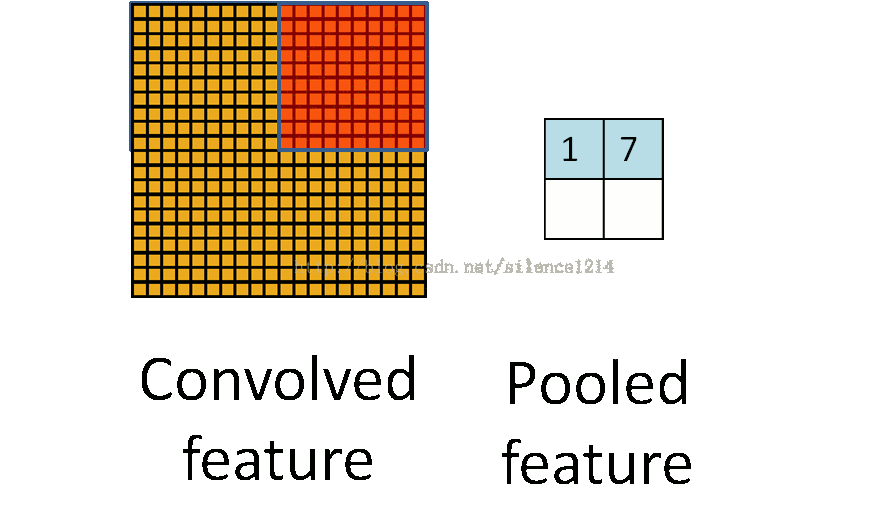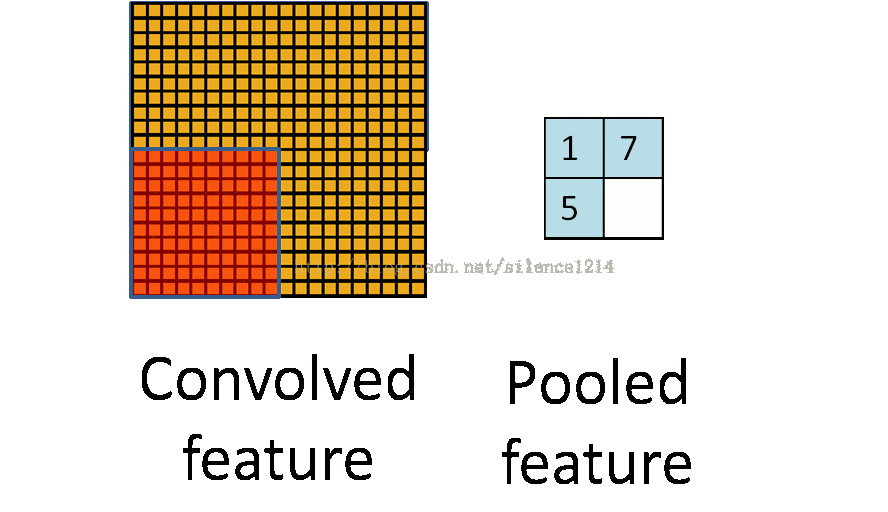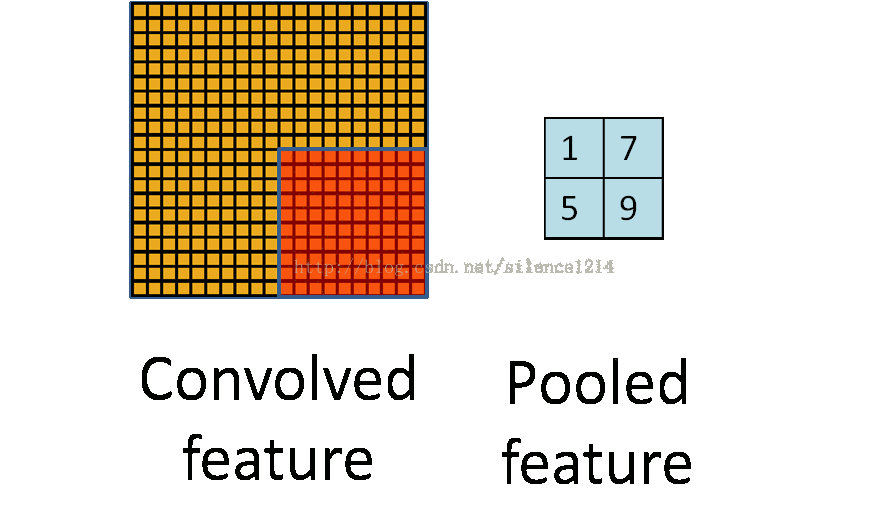
For example, the matrix A on the left above is a 20*20 matrix and needs to be pooled with a size of 10*10, then the red in the left figure is the size of 10*10, which corresponds to the matrix on the right, and the size of each element on the right is 10*10. The value is the value of each element of the red matrix on the left and the number of elements in the red matrix, that is, the pooling in the form of an average.
3: We talked about convolution and pooling above, and let’s talk about what we need to pay attention to in the calculation. The color map is used in the code, and the color map has 3 channels, so for each channel, convolution and pooling should be performed separately. A value corresponds to the 3 channels of a picture, so it needs to be added up after convolution of 3 channels, just to correspond to a neuron of a hidden layer, that is, a feature.