I recently learned machine learning. The textbooks are mainly "Machine Learning" by Zhou Zhihua and "Machine Learning in Practice" by Peter Harrington. Teacher Zhou's book is more inclined to the explanation and derivation of algorithms, which is very theoretical, and "Machine Learning in Practice" is more The actual use of machine learning algorithms, as well as the implementation of Python code, is more intuitive. Together, the two books combine theory with practice, and you can learn a lot.
Today, let’s take a look at the relatively simple k-nearest neighbor algorithm. The k-nearest neighbor algorithm is a supervised learning method and is mainly used for classification. It is the representative of lazy learning. The so-called lazy learning means that there is no need to train the model, only the training The samples are stored and calculated when the samples to be tested are processed.
The principle of the k-nearest neighbor algorithm is relatively simple:
-
Prepare training sample data, each sample must have a label, indicating the category to which the sample belongs;
-
Input the tested sample data (without category labels), calculate the distance from each data in the training sample set, and extract the category labels of the first k training sample data with the closest distance;
-
Finally, the selected k category labels are voted, and the category with the most votes is selected, which is the category to which the tested sample belongs.
Let's start with an example. First, I need to fake some data. Here, let's assume that my data contains four columns. The first three columns are the proportions of meat, vegetables and fruits in the food of the day (value range [0, 1], It can actually be the amount of three foods), and the fourth column is a label of whether I liked the food of the day (0-like, 1-average, 2-dislike). I wrote a small program here to generate fake data, and the data will be written to data.json.
import random
import time
import json
data = []
random.seed(time.time())
for i in range(1000):
meat_ratio = random.uniform(0, 1)
vegetables_ratio = random.uniform(0, 1 - meat_ratio)
fruit_ratio = random.uniform(0, 1 - meat_ratio - vegetables_ratio)
if meat_ratio >= 0.4:
label = 0
elif meat_ratio < 0.4 and fruit_ratio >= 0.4:
label = 1
elif meat_ratio < 0.4 and fruit_ratio < 0.4:
label = 2
data.append([float('%.2f' % meat_ratio),
float('%.2f' % vegetables_ratio),
float('%.2f' % fruit_ratio), label])
json = json.dumps(data)
with open("data.json", "w") as f:
f.write(json)
This code can be run directly, mainly to generate 100 pieces of data. Of the 100 pieces of data, I will use 70 as the training set and 30 as the test set. The generated data is reserved in the data.json file as a backup. The content format of the generated data.json is as follows (your data may be different from mine due to random generation):
[[0.92, 0.07, 0.0, 0], [0.21, 0.12, 0.54, 1],...]
The k-nearest neighbor algorithm uses the program provided by "Machine Learning Practice". Here I have made some changes for Python3. Let's take a look at the content of the algorithm.
def classify0(in_x, data_set, labels, k=3):
# Calculate distance
data_set_size = data_set.shape[0]
diff_mat = np.tile(in_x, (data_set_size, 1)) - data_set
sq_diff_mat = diff_mat ** 2
sq_distances = sq_diff_mat.sum(axis=1)
distances = sq_distances ** 0.5
#Sort and get indicies
sorted_dist_indicies = distances.argsort()
#Find the first k labels and vote
class_count = {}
for i in range(k):
vote_i_label = labels[sorted_dist_indicies[i]]
class_count[vote_i_label] = class_count.get(vote_i_label, 0) + 1
sorted_class_count = sorted(class_count.items(),
key=operator.itemgetter(1), reverse=True)
return sorted_class_count[0][0]
Description of the input parameters of the algorithm:
in_x: a piece of sample data to be tested, the type is numpy array;
data_set: training set data, the type is numpy mat;
labels: the label set of the training set, the type is numpy array;
k: Take the class labels of the k closest samples to vote, the default is 3.
Next, we first calculate the distance, here we use the Euclidean distance for calculation, the formula is as follows:
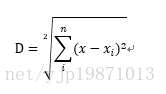
It is to square the difference between each eigenvalue of the tested data and the corresponding eigenvalue of the ith sample data of the training set, and then add all the squared values to obtain the ith sample of the tested data and the training set. Euclidean distance of the data.
Then the code sorts the calculated distances, and argsort returns the index of the distance-sorted list, which is convenient to correspond to labels. Finally, vote on the top k closest labels and get the class label with the most votes.
Let's now test how accurate the k-nearest neighbor algorithm is for our current problem. The following is the test program provided by "Machine Learning in Action":
def auto_norm(data_set):
min_vals = data_set.min (0)
max_vals = data_set.max(0)
ranges = max_vals - min_vals
m = data_set.shape[0]
norm_data_set = data_set - np.tile(min_vals, (m, 1))
norm_data_set = norm_data_set / np.tile(ranges, (m, 1))
return norm_data_set, ranges, min_vals
def dating_class_test(dating_data_mat, dating_labels, ho_radio=0.10, k=3):
norm_mat, ranges, min_vals = auto_norm (dating_data_mat)
m = norm_mat.shape[0]
num_test_vecs = int(m * ho_radio)
error_count = 0.0
for i in range(num_test_vecs):
classifier_result = classify0(norm_mat[i, :],
norm_mat[num_test_vecs:m, :],
dating_labels[num_test_vecs:m], k)
print("the classifier came back with: %d, the real answer is: %d"
% (classifier_result, dating_labels[i]))
if classifier_result != dating_labels[i]:
error_count += 1.0
print("the total error rate is: %f and error count is: %f"
% (error_count / float(num_test_vecs), error_count))
The auto_norm function is the normalization of the feature data. The feature data here has been normalized, so this step can be omitted, but for generality, I still keep this part of the code. Normalization can be done by Baidu. In simple terms, it is to map data that is not in the range of [0, 1] to the range of [0, 1]. If this processing is not done, the Euclidean distance formula is used. If a characteristic difference is squared If it is very large, the effect of other eigenvalues will be weakened.
dating_class_test is our test function, which uses the data set to test the error rate of the k-nearest neighbor algorithm, ho_radio is used to divide the data set, the default is 0.10, that is, 90% of the data is used as the training set, and 10% z is used as the test set. Let's test the error rate on the data.json data (your test error rate may be different from mine due to randomly generated data):
def read_data(filename):
with open(filename) as f:
data = json.load(f)
data_num = len (data)
data_set = np.zeros((data_num, 3))
data_labels = []
index = 0
for d in data:
data_set[index, :] = d[0:3]
data_labels.append(int(d[-1]))
index += 1
return data_set, data_labels
if __name__ == '__main__':
data_set, data_labels = read_data('data.json')
dating_class_test(data_set, data_labels, 0.3)
最后输出为:
the total error rate is: 0.016667 and error count is: 5.000000
错误率只有0.02,相当低,这样,我们就可以放心的将k-近邻算法使用在我们的问题上了。下面写一个程序,来实现我们的目的:
def is_like_this_food():
meat_ratio = float(input('input meat ratio: '))
vegetables_ratio = float(input('input vegetables ratio: '))
fruit_ratio = float(input('input fruit ratio: '))
in_x = np.array([meat_ratio, vegetables_ratio, fruit_ratio])
data_set, data_labels = read_data('data.json')
norm_mat, ranges, min_vals = auto_norm(data_set)
classifier_result = classify0((in_x - min_vals) / ranges,
norm_mat, data_labels)
result_list = ['like', 'normal', 'do not like']
print("This food: ",
result_list[classifier_result])
if __name__ == '__main__':
is_like_this_food()
输入三个比例(注意三个比例和为1,这里考虑代码简单,没有加入校验和相关的),然后会判断你是否喜欢这样的食物搭配。下面是一次测试的结果:
input meat ratio: 0.5
input vegetables ratio: 0.4
input fruit ratio: 0.1
This food: like
现在我们回头再看一下,k-近邻算法有什么优缺点:
优点:精度比较高,算法逻辑简单,无需训练模型;
缺点:计算量随着训练集样本数量的增加而增加,占用空间也较大。
