It's Saturday morning again, and it's still my own time in the middle of the night. I got up, read a few ancient articles, and prepared to sort out the principles of Linux FQ and RPS. Just yesterday, someone asked me. This article starts with FQ.
enqueue entry process
Previous picture:
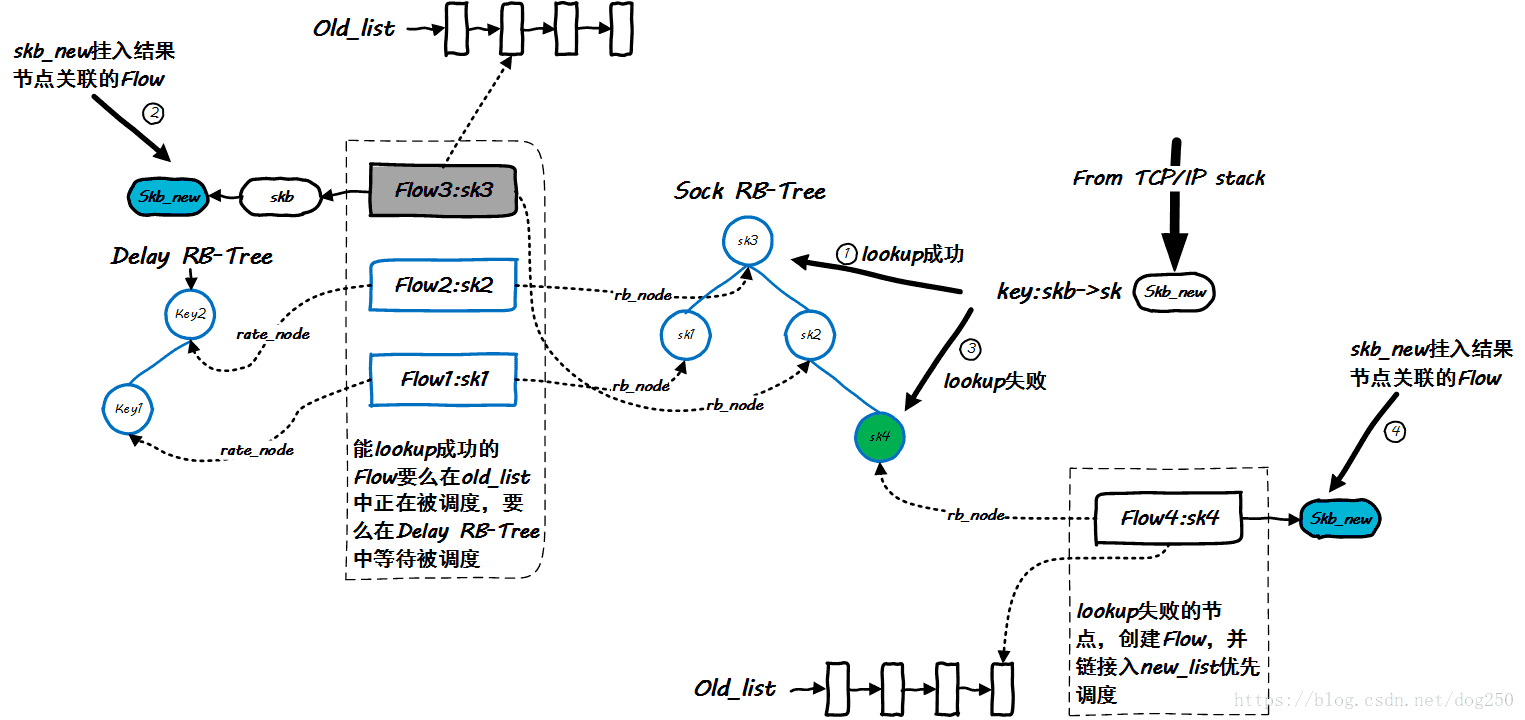
The enqueuing process of the fq queue is described in detail, with emphasis on understanding several data structures:
- Red-black tree with sock as key: used to associate skb and flow
- The red-black tree with next_time as the key: used to save the flow to be scheduled in the future, and determine the timer wake-up time to schedule the skb
- new_list: used to save the newly created flow list that has not yet been issued, used to schedule and trigger the first packet
- old_list: used to save the flow that is being scheduled.
dequeue scheduling process
The dequeue operation is more complicated than the enqueue operation. Let's look at a picture first:
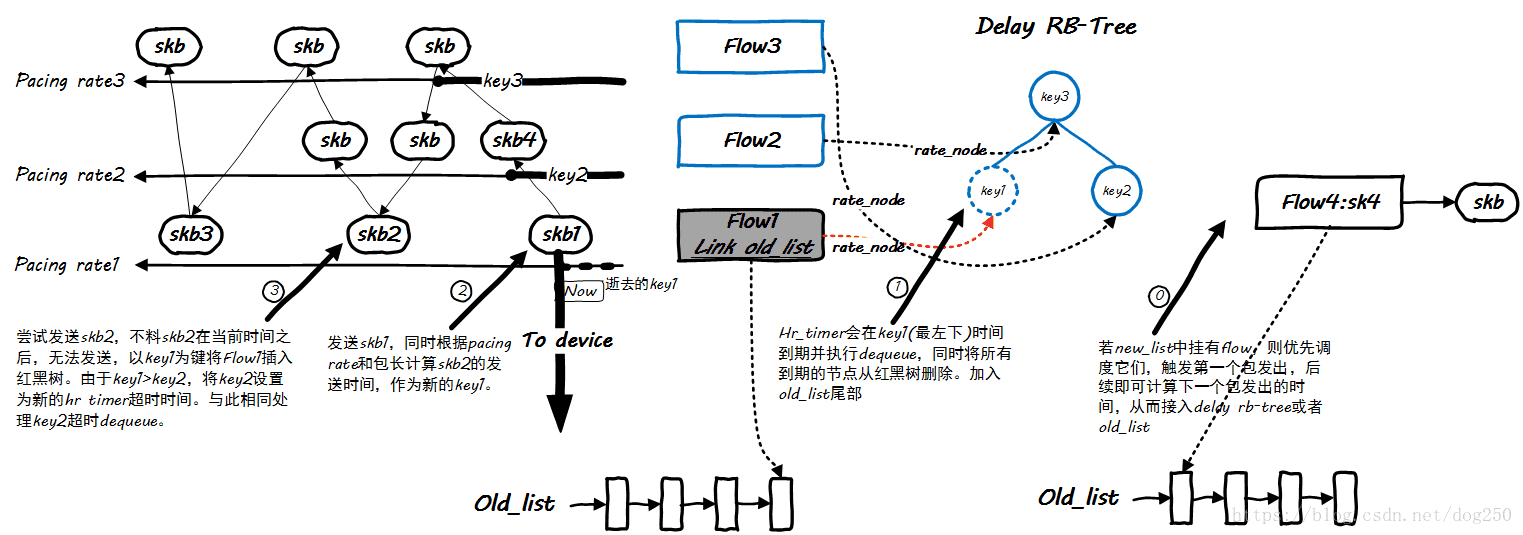
This is a relatively dynamic process, driven by Linux's hrtimer, and its timeout depends on the time of the most recent skb to be sent for each flow. The time among many flows is the smallest, which obviously tends to use the red-black tree to Implementation, let's take a look at the core code of dequeue:
static struct sk_buff *fq_dequeue(struct Qdisc *sch)
{
...
/* 将红黑树上已经到期的flow从红黑树上摘除,加入old_list准备开始被调度 */
fq_check_throttled(q, now);
begin:
/* 优先无条件调度新创建的flow上的skb,触发其第一包发送,以计算next_time */
head = &q->new_flows;
if (!head->first) {
/* 如果没有新创建的flow,则调度old_list已经创建且被调度的flow */
head = &q->old_flows;
if (!head->first) {
/* 设置最短的超时,延后执行dequeue */
qdisc_watchdog_schedule_ns(&q->watchdog,
q->time_next_delayed_flow);
return NULL;
}
}
/* 从head到tail的顺序调度 */
f = head->first;
if (unlikely(f->head && now < f->time_next_packet)) {
/* 同一个flow的skb链表依次被调度,然而由于pacing,当前skb允许发送的时间 */
/* 在当前时间之后,则终止当前flow,将其插入delay rb-tree,同时调度old_list */
/* 下一个flow */
head->first = f->next;
fq_flow_set_throttled(q, f); // 冒泡找到最近的expires
goto begin;
}
/* 取出被调度的skb,根据pacing rate计算下一个包发送的时间 */
skb = fq_dequeue_head(sch, f);
//if (f->credit > 0 || !q->rate_enable)
if (!q->rate_enable)
goto out;
rate = skb->sk->sk_pacing_rate;
plen = qdisc_pkt_len(skb);
len = (u64)plen * NSEC_PER_SEC;
do_div(len, rate);
f->time_next_packet = now + len;
out:
return skb;
}The core of this is
f->time_next_packetThis is the key value of the red-black tree node.
rate pacing rate
In Linux FQ, the pacing rate of a flow is given to calculate the time to send the next skb, and the traditional scheme is still used, that is, the time to send the next skb is calculated according to the length of the current skb , relying on the formula:
The obvious thing here is is the length of the current skb. The meaning of this formula is that it takes a total of At the time , Linux's implementation is clearly coarse-grained:
len = (u64)plen * NSEC_PER_SEC;
do_div(len, rate);
f->time_next_packet = now + len;It is sent based on skb for pacing, not based on bytes. This is also the contradiction between the host and the line, not much to say.
Compare with O(1) scheduler and CFS scheduler
In fact, the FQ mechanism, the CFS process scheduler and the fair queue of disk IO are completely consistent implementations:
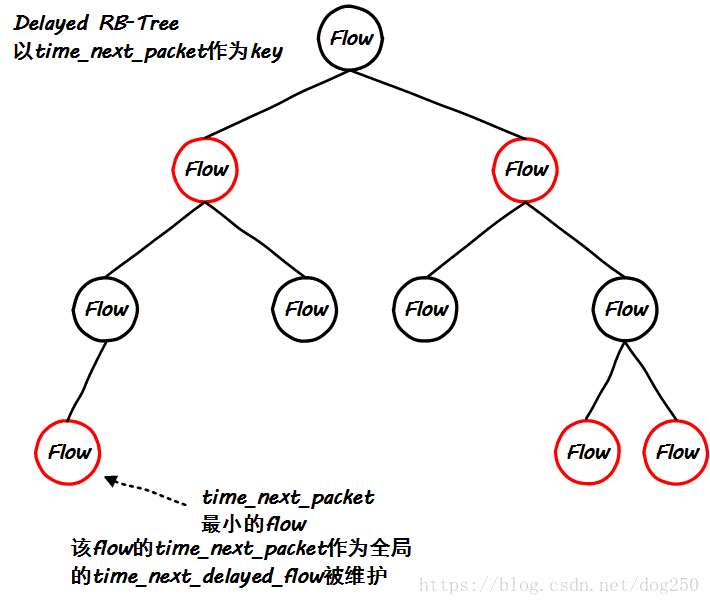
Different from CFS, FQ also maintains a flow queue that is being scheduled , namely old_list ( here we ignore the new_list as the opening function ). Obviously, in CFS, CPU time can only be allocated to one task at the same time, which is different. Observing this old_list, you will find that this is a static priority data structure, which is very similar to the O(1) scheduler:
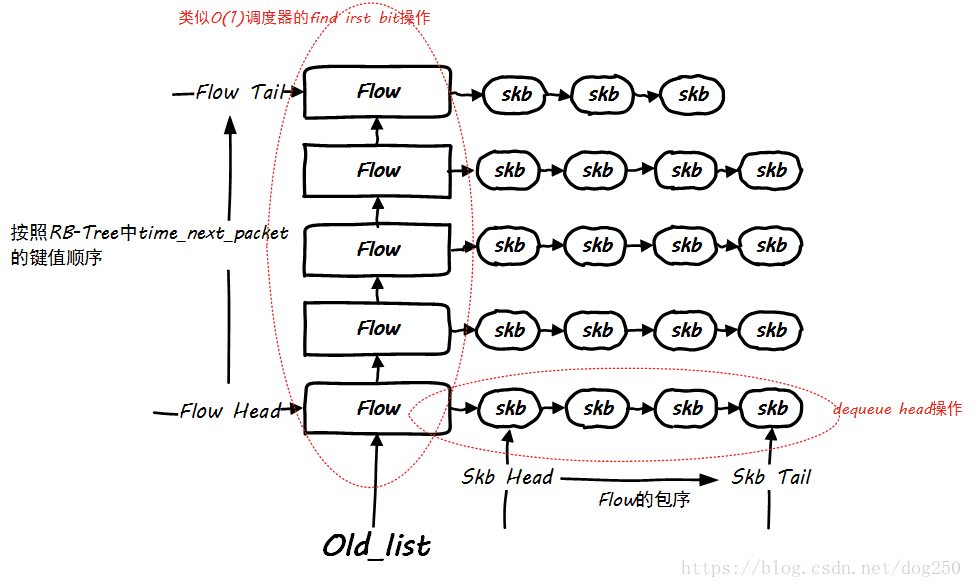
This is almost exactly the same as the disk IO fair queue, and the time slice can be allocated to multiple entries.
The next two sections talk about the implementation of pacing, not FQ. To put it bluntly, the implementation of pacing does not necessarily have to use FQ. The main problem of FQ is how to use a single timer to drive any number and flow, so that it can send data according to its own pacing . However, can we dump the blame on the Linux scheduler?
My own implementation of TCP Pacing mechanism
Speaking of FQ, I have to mention the Google BBR congestion control algorithm. I was fascinated by this Pacing suggestion when I first came into contact with BBR last year. To be honest, the Linux TCP Pacing mechanism and FQ have already existed, but it was not until BBR that they worked together. , I was thinking, since TCP itself is per flow, why should the Qdisc layer maintain another flow table, and I found that the fair queue implemented by this FQ has an inaccurate scheduling time when there is a high concurrent TCP flow, so I tend to implement Pacing directly at the TCP layer:
Thoroughly implement the Pacing sending logic of Linux TCP - ordinary timer version : https://blog.csdn.net/dog250/article/details/54424629
Thoroughly implement the Pacing sending logic of Linux TCP - high Accuracy hrtimer version : https://blog.csdn.net/dog250/article/details/54424751
At first I thought this was feasible because I felt that TCP has so many timers anyway, and there are not many more timers. However, two issues were overlooked:
- When the high-rate TCP
pacing rate is extremely large, the timer will frequently time out, putting pressure on the Linux scheduling subsystem. - High concurrent flow
Multiple TCP flow connection timeouts will continue to increase the burden on the Linux scheduling subsystem.
Therefore, the single-stream test is OK, it does not mean that it is really available.
OK, how to solve this problem?
Isn't it difficult for a timer to schedule 100,000 TCP connections? Isn't it difficult for the scheduler to schedule a TCP connection for each of 100,000 timers? It seems that it is not appropriate to simply dump the pot. The solution is, why not set up a fixed number of 10 timers , or 5, or 20, or 30, depending on your CPU configuration, as long as it is a fixed number of timers Just fine, take 10 timers as an example, a timer only needs to deal with 10,000 TCP streams on average, the difference of orders of magnitude!
FQ only needs to add one more level to solve the problem!
Community's internal TCP Pacing patch
You can read this first:
TCP Pacing : https://lwn.net/Articles/199644/
Then you will ask why the patch is not applied, please see my explanation in the previous section.
Well, after more than 10 years, here comes another one:
[v2,net-next] tcp: internal implementation for pacing : https://patchwork.ozlabs.org/patch/762899/
It's almost the same thing. Not much to say.
queuing strategy
FQ implements a queue-cutting strategy for retransmit packets:
// flow_queue_add
/* add skb to flow queue
* flow queue is a linked list, kind of FIFO, except for TCP retransmits
* We special case tcp retransmits to be transmitted before other packets.
* We rely on fact that TCP retransmits are unlikely, so we do not waste
* a separate queue or a pointer.
* head-> [retrans pkt 1]
* [retrans pkt 2]
* [ normal pkt 1]
* [ normal pkt 2]
* [ normal pkt 3]
* tail-> [ normal pkt 4]
*/Are there any other fancy queue-jumping or fancy avoidance strategies here? For example, for pure ACK, small packets, small packets in continuous large packets, large packets in continuous small packets. I won't go into detail about this. Let's compare it to a group of people in uniform when we queued up... Then there are special vehicles on the road. Well, we still have FQ's internal queue. It's useless. At the same time, can we? How about implementing several more similar queues?
I feel very relaxed this week, but I didn't think of any new idea, alas...