This article quickly analyzes the basic principles of RPS/RFS.
RPS-Receive Packet Steering
The following is the principle of RPS:
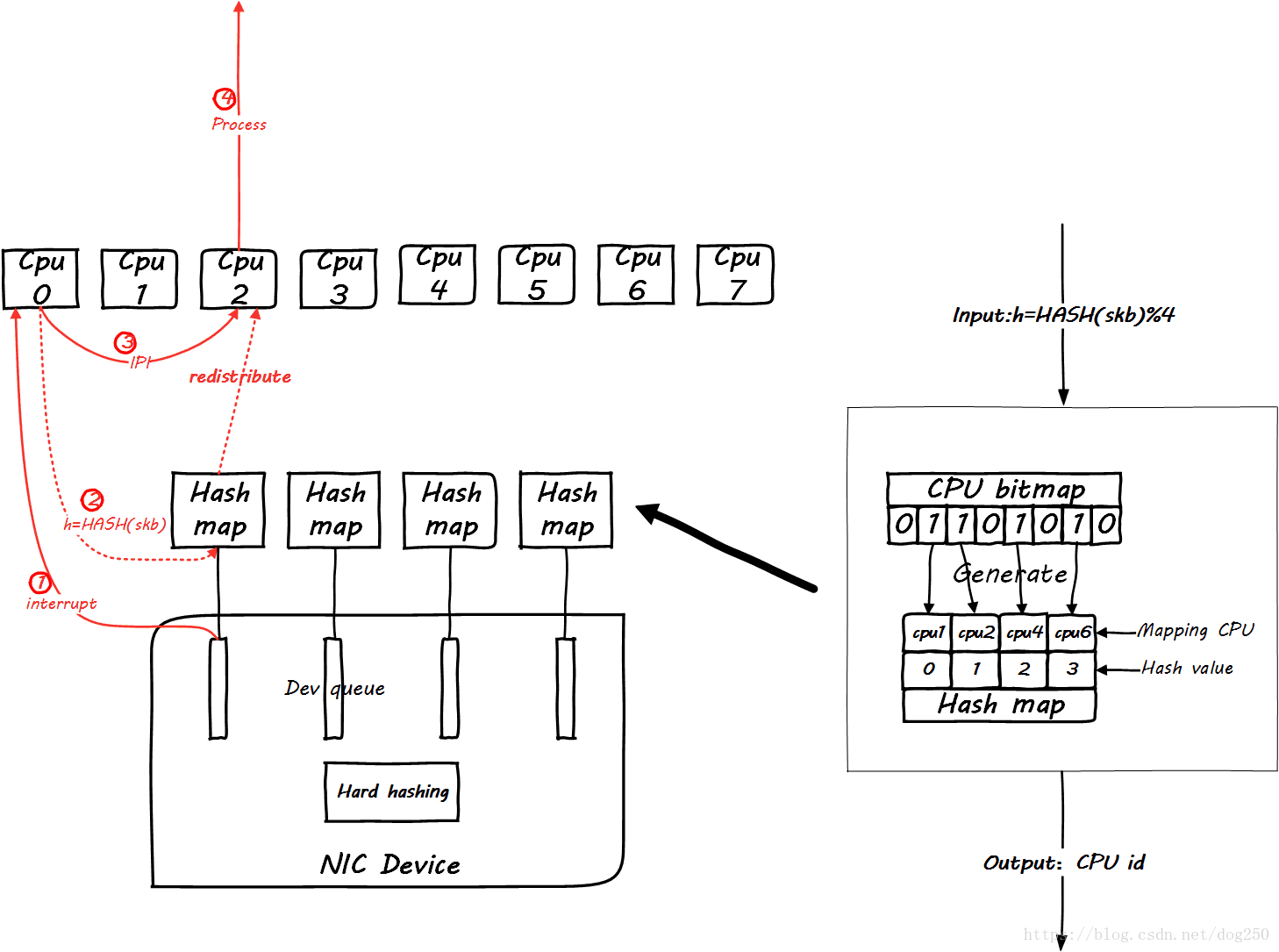
In fact, it is a mechanism for software to redistribute the CPU load . Its enabling point is at the beginning of the CPU processing the soft interrupt, that is, the following places:
netif_rx_internal
netif_receive_skb_internal- 1
- 2
RFS-Receive Flow Steering
On the basis of RPS, RFS fully considers the consistency of processing CPU between the same five-tuple flow process context and soft interrupt context , so there must be corresponding processing at the socket level.
Unfortunately, a picture cannot express all of this, so we will proceed in stages, first look at the arrival of the first packet of the same quintuple flow:
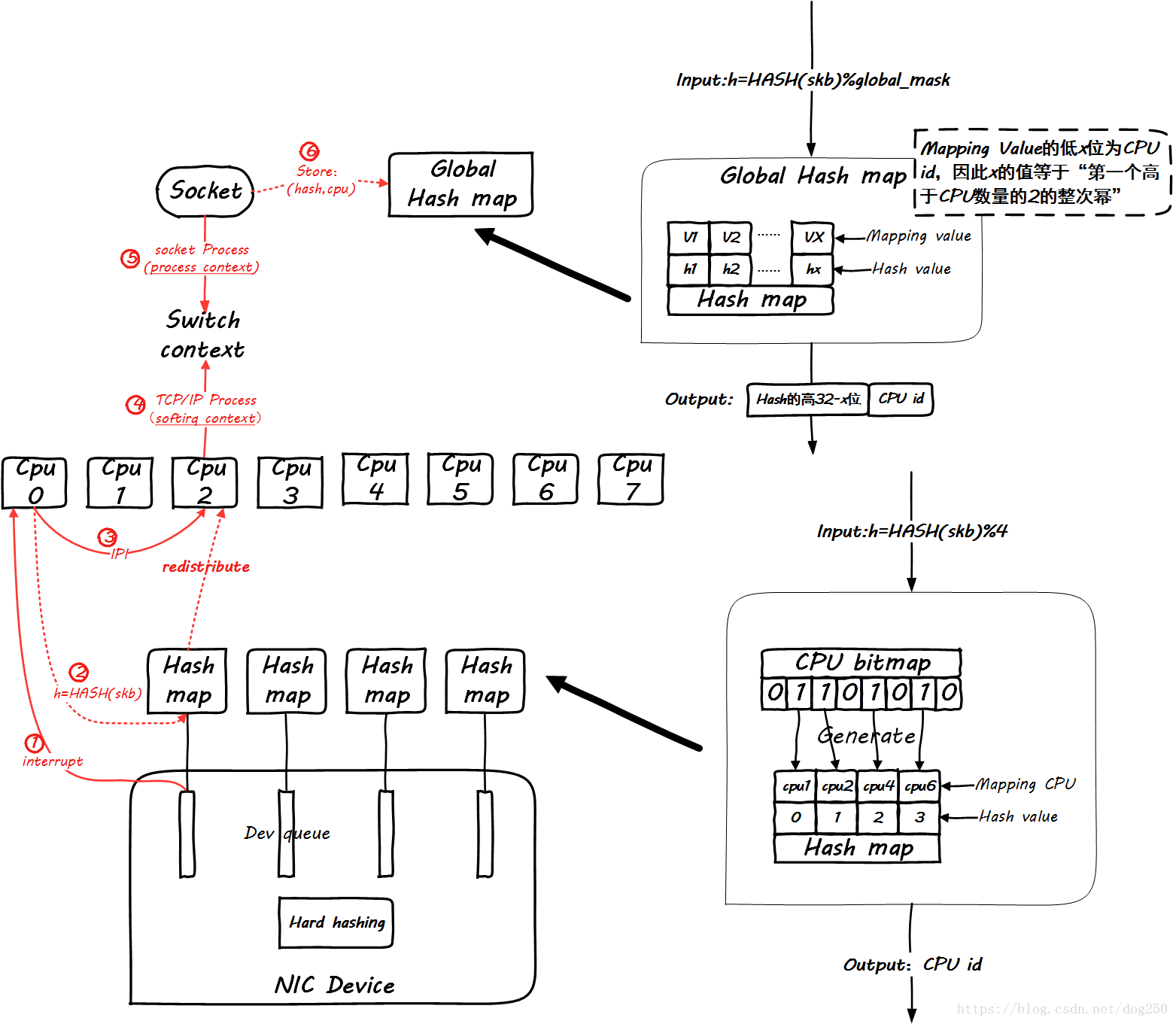
Obviously, as a global mapping, the space must be large enough to accommodate enough streams, otherwise they will overwrite each other. I recommend setting it to 2 times the maximum number of concurrent connections.
Then, when subsequent packages of the same flow arrive, let's see how global mapping works. Let's first look at the scene when the first package arrives:
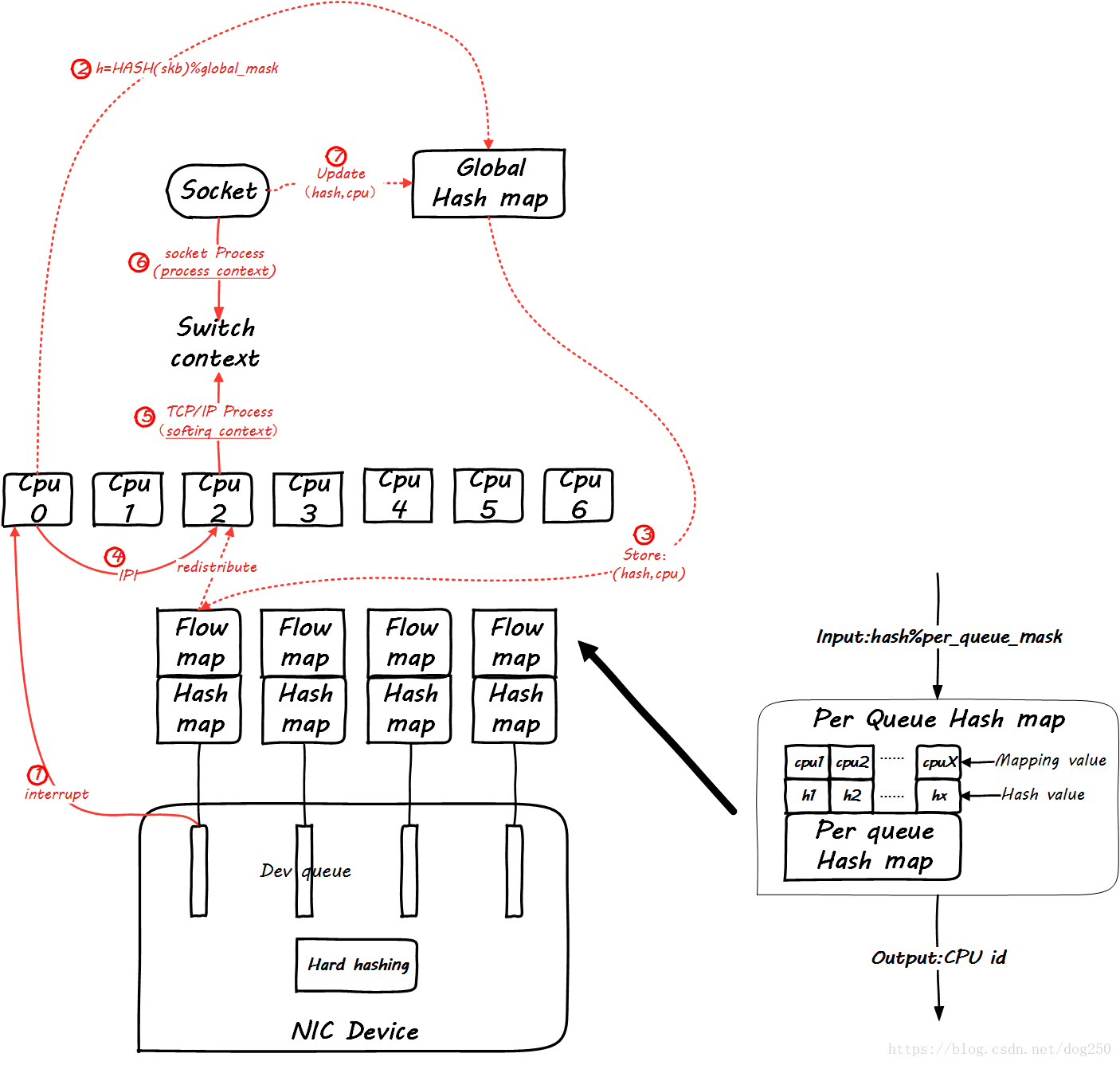
Looking at the picture carefully, a Per Queue Hash map is added here. These maps are generated from the global map. When the subsequent data packets arrive, you can check this map:
However, this does not show the difference between RFS and RPS.
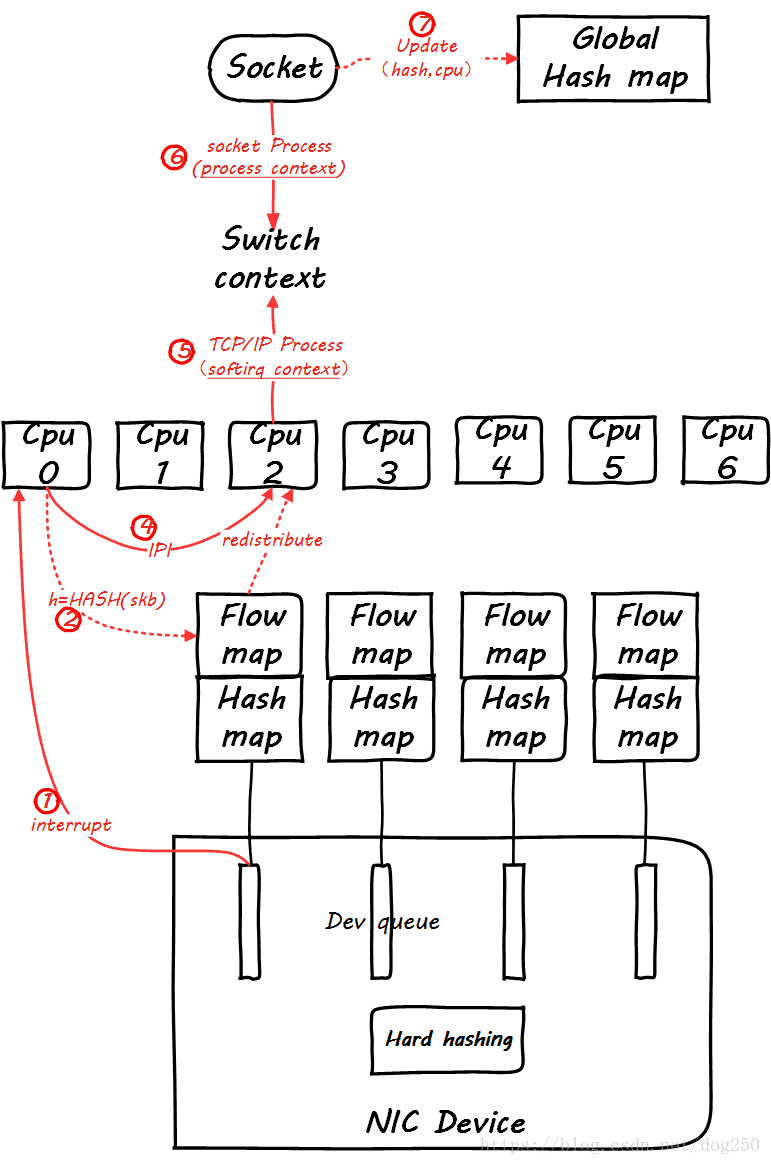
Can you guarantee that it is the same CPU that handles the softirq and the socket? You can't, it is possible that tcp_v4_rcv is being processed by CPU0, and then the socket process is woken up in data_ready, but the scheduler wakeup the process to CPU1, so when the global hash map is updated, a different CPU will be updated. At this time The role of RFS is reflected. RFS will also update the Per Queue Hash Map, and then all subsequent packets will be redirected to the new CPU, but RPS will not do this.
RFS does not switch unconditionally as long as it finds that the CPU has changed, but to meet a condition, that is:
all the packets from the same stream enqueue to the old CPU last time are processed,
so that the seriality of the same stream processing can be guaranteed, and at the same time You can also take advantage of the Hotleyouzxgw.com cacheline when processing protocol headers.
Accelerated RFS
Basically, the configuration discovered by the software can be reversely injected into the hardware , which requires hardware support, not much to say.
This article only talks about the principle. If you want to know the Howto, please refer to the documentation /networking/scaling.txt file of the kernel source package.
trick and tips
Sometimes being too even and equal is not a good thing.
When the CPU runs heavy user-mode business logic, hitting the interrupt to the same CPU has a natural current limiting effect. Pay attention to find out where the bottleneck is first. If the bottleneck is the processing of business logic, then when you enable RPS/RFS, you will find that the user-mode service indicators have no improvement, and you will find that the softirq is soaring, which is not a good thing.
Refer to the illustration below:
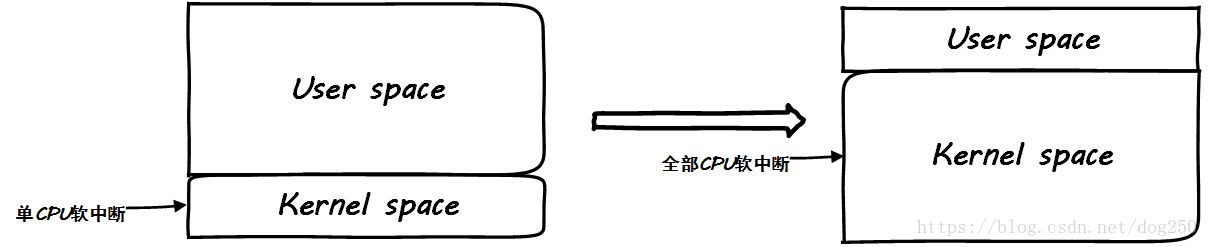
is this okay? For the so-called graceful balance of kernel mode processing, the CPU time of user mode is squeezed. This is a typical behavior of beginners . To optimize the kernel for the sake of the kernel is a typical property beating the owner!
In fact, the role of the OS kernel is only one, which is to serve the processing of user-mode business logic!
Not much to say.