Original title: Deep Reinforcement Adversarial Learning against Botnet Evasion Attacks
0x01 Too long to read the version
Network traffic classifiers obtained by supervised learning are easily circumvented and cannot face novel attacks.
To make the classifier more robust, DRL is used to automatically generate realistic attack samples, which are then thrown into the dataset to strengthen the classifier. At this point, we can even face attacks that haven't been seen before.
0x02 intro
Adversarial attacks against ML-based detectors hope to generate adversarial samples that can fool the detector , i.e. true attack samples are identified as harmless.
These adversarial examples can be introduced during training or during classification. We consider the case of introducing adversarial examples when doing classification. This kind of thing has been done badly in the field of images and speech.
The scenario we considered is shown in the following figure: Enterprise network. Contains many hosts, at least one becomes a bot. Network traffic is monitored by NIDS. This is a gray-box model, because it is not realistic for an attacker to know the internal network configuration, including the detection configuration, all the time.
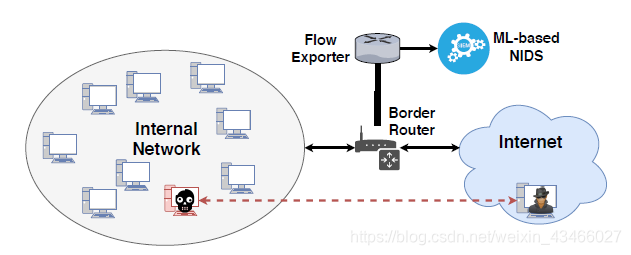
The attacker does not know what the IDS is used for training, but the attacker can guess what kind of data the IDS uses for training.
In fact, the characteristics considered by the offensive and defensive sides do have a great overlap.
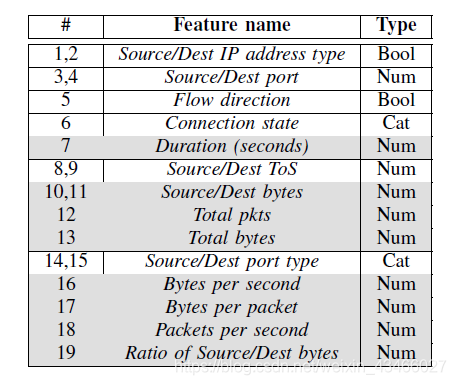
For example, properties in gray are properties used by attackers. Attackers try to slightly modify botnet properties to evade detection. These modifications will slightly change the original traffic characteristics, but do not change the properties of the botnet. For example, adding a little communication delay or throwing some garbage packets will do, and only need to change the control logic of the botnet slightly.
0x03 Solution
The original text uses DRL to generate realistic adversarial samples, so that maliciousness is preserved, but not detected.
This solution is divided into three stages.
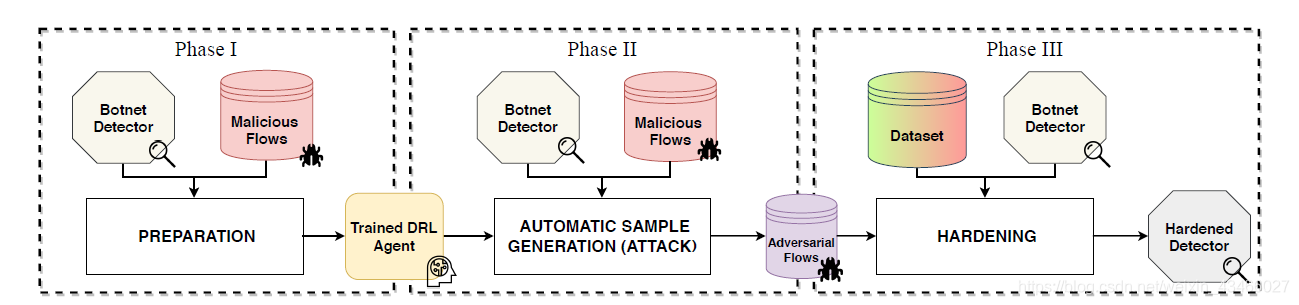
Stage 1: Preparation
Create a DRL agent that can generate adversarial examples based on the network flow of the botnet.
We believe that the underlying logic of the botnet software will not change, and the number of samples submitted by the attacker detection model is also limited.
The agent will learn how to submit as many escape attack samples as possible.
The environment consists of two parts:
- A state generator, which translates the input stream into a state s that can be recognized by the agent;
- botnet detector, used for intrusion detection.
The reward is to judge the generated samples right or wrong. The agent will continue to modify the sample until the generation of the sample can escape detection or keep failing.
Actions are small changes to the data flow. The agent changes the following characteristics: duration, bytes sent, bytes received, packets sent (that is, the grayed out characteristics in the table).
DDQN is used mainly to prevent overestimation. DDQN produces samples that are significantly different from the initial variant.
SARSA was used in an effort to avoid detection.
In summary, the output of stage one is DRL agent A(b), where b is the botnet. This agent is used to generate malicious adversarial samples.
Stage 2: Automatically generate samples
A(b) is used to generate malicious samples. Proceed as follows:
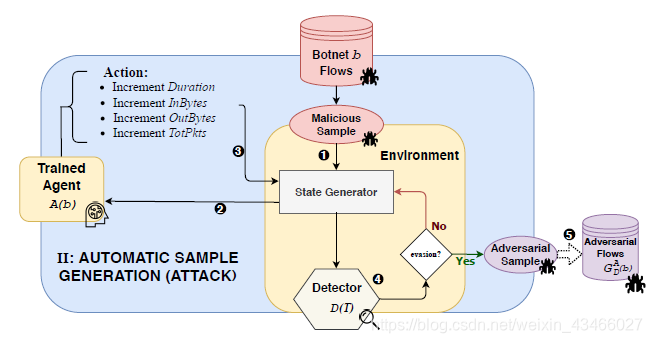
- The system receives the malicious stream of b as input and sends it to the state generator to generate the state;
- The status is sent to agent A(b);
- The agent transmits the best action to the generator, and then generates the modified sample;
- The modified sample is handed over to the detector for judgment,
- If the detector is successfully fooled, this data is used by the detector for learning; otherwise, the state is passed back to the generator and repeats 2-4 to further modify the packet.
The agent does not get any benefit in this process.
In this process, malicious flows will be obtained, which are the magic version of b's malicious flows.
Phase 3: Enhancement
Train the detector using the augmented training set. Its classification threshold is the ratio of malicious samples in the augmented dataset.