Note: old rules, do not disclose company information
5 kettle given Hadoop
5.1 mysql and hive data operations
5.1.1 mysql to hive
The first idea for transferring data from relational databases to hive is to directly extract the data from the MySQL source table to the hive target table through kettle extraction. The process is to first use the "table input" component to configure the database connection, take out the source table data, and then use the "table output" to configure the hive database connection, and load the obtained data into the target table built in hive. The Kettle conversion script is shown in Figure 5.1.

Figure 5.1 mysql to hive extraction
Test results: reading the source table data successfully, writing data to the hive table is slow, a piece of data takes ten minutes, which is not practical.
Reason: Kettle's support for relational databases directly to nosql databases is not particularly good.
5.1.2 MySQL goes to hdfs first and then hive
In order to solve the slow problem of directly extracting mysql data into hive table. You can first write the mysql data to hdfs in the form of text files, and then use the hive load data command to load the data into the pre-built hive table. The Kettle script is shown in Figure 5.2. The sql script is shown in Figure 5.3.

Figure 5.2 The process from mysql to hdfs to hive

Figure 5.3 sql of hive target table load data
First of all, the local execution reports an error, the error is Could not close the output stream for file "hdfs://spark:*** @xxxxx :xxxx/user/Administrator/orders4.txt". The reason is that the kettle and hadoop clusters are not caused by the same network segment. Configure the remote service of kettle on the hadoop cluster (see section 2.7), and the kettle script is successfully executed by remote execution. As shown in Figure 5.4.
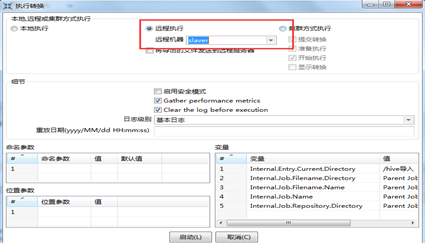
Figure 5.3 Job Remote Execution
5.1.3 hive-mysql
The schema of the MySQL target table that directly extracts data from the source table of the hive database. The same is the use of "table input" and "table output" mode.
Test results: fast and feasible.
5.2 hive-hive
The purpose of this operation is to verify that the cleaning operation on the table in the hive database is feasible. Using the structure of "table input" and "table output", there is no problem with connection, but there is also the problem of slow writing data directly to the hive table.
However, to solve this problem, you can create a job that executes the sql script.
5.3 mysql-Hbase data operation (slow)
5.3.1 mysql-hbase
Since the response speed and efficiency of hbase are more than 10 times that of hive, the data migration operation of hbase is also necessary. The Kettle job adopts the schema of "Table Input" and "HbaseOutput", as shown in Figure 5.4.
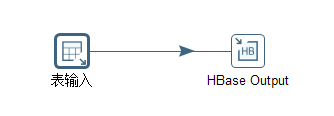
Figure 5.4 Data migration from mysql to hbase
The configuration information of Hbase components is shown in Figure 5.5-5.6.
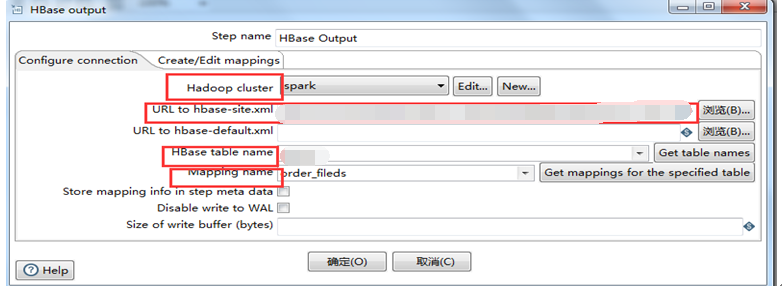
Figure 5.5 Connection Configuration
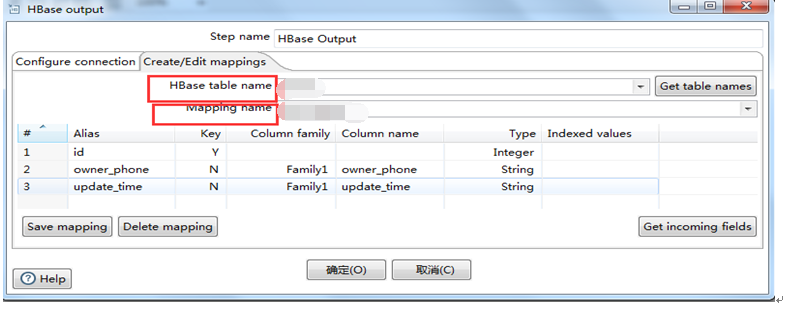
Figure 5.6 Map Edit
Figure 5.5 shows the Hadoop cluster, configuration file hbase-site.xml, table name and other information required to connect to hbase. Figure 5.6 configures the mapping relationship from the source table to the target table and the field type and column family of the target table.
Test error: 1. The node name UnknownHost exception could not be found
2. After identifying the Host, the node cannot be found
Solution: 1. Configure the hosts file on Windows and write the cluster ip and host name
2. Add file:/// before the path of hbase-site.xml, indicating that it is searched locally.
Note: Transfer Data Optimization
1. Before writing to hbase, pre-partition is required when creating a table
2. Pre-read mapping
3. Increase the write cache
4. Modify the hbase configuration file /conf/hbase-site.xml to increase the heap memory of hbase to 3GB (according to hardware resources)
Result: low transmission speed, 200/sec before optimization, 1700/sec after optimization.
5.3.2 hbase-mysql
The transformation adopts the modes of "HbaseInput" and "Table Output" to realize data extraction. As shown in Figure 5.7.
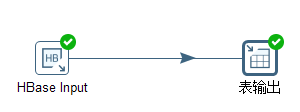
Figure 5.7 Hbase to mysql fetch
The configuration information of HbaseInput is shown in Figure 5.8-5.9.
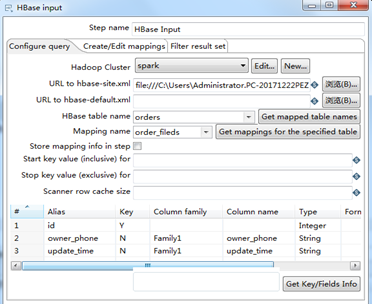
Figure 5.8 Hbase query configuration
Test results: fast and effective.
5.4 mysql-phoenix (slow)
Apache Phoenix is a relational database layer built on top of HBase, as an embedded client-side JDBC driver for low-latency access to data in HBase. Apache Phoenix will compile the SQL query written by the user into a series of scan operations, and finally generate a general JDBC result set and return it to the client. The metadata of the data table is stored in the HBase table and will be marked with a version number, so the correct schema will be automatically selected when querying. Using HBase's API directly, combined with coprocessors and custom filters, small-scale queries can be responded to in milliseconds, and tens of millions of data can be responded to in seconds. See http://blog.csdn.net/m_signals/article/details/53086602 for installation.
First, copy phoenix-*-client.jar, phoenix-core*.jar and guava-13.0.jar (downloaded from the Internet) in the phoenix installation directory to the lib folder of kettle. Then, configure the phoenix database connection, select Generic database for the link type, customize the link URL: jdbc:phoenix:xxxxxxxxx:/hbase, and customize the driver class name: org.apache.phoenix.jdbc.PhoenixDriver. As shown in Figure 5.9.
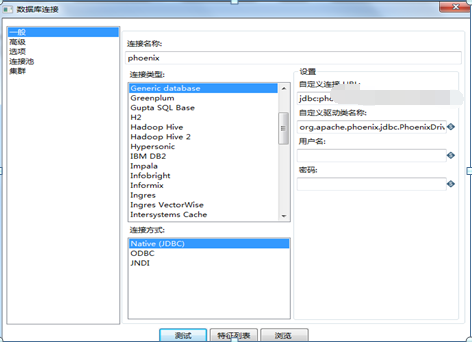
Figure 5.9 Phoenix database connection
Write MySQL data into hbase through phoenix, the conversion script is shown in Figure 5.10. The same script mode is used to write the data in hbase to mysql through phoenix.

Figure 5.10 Write a number script to hbase
Notice:
1. When the phoenix-*-client.jar required to connect to phoenix is put into the lib directory of kettle, it will affect the direct connection of kettle to hbase.
2. The transmission speed is low, the speed is 1750 pieces/second.
Similarly, taking the data from hbase through phoenix and writing it to mysql is just the reverse process. However, the test results show that the speed is not ideal, the results are shown in Figure 5.11.

Figure 5.11 phoenix-mysql test results
Performance analysis: Since hbase is stored in columns, this is its advantage. There are 60+ columns in the orders table of the test object. Although 6 column clusters have been created in advance, the fetching performance is still not ideal.
5.5 Kettle submits Spark job
Goal: Kettle implements operations on spark using the "spark sbumit" control. Instead of directly using kettle to write scala programs, we use prepared jar packages to operate spark. The Job script is shown in Figure 5.12, and Figure 5.13 is the setting information of "spark submit".
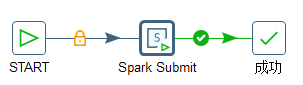
Figure 5.12 kettle operation spark

Figure 5.13 Settings for spark submit