Hash table related concepts
Hash technology establishes a definite correspondence f between the storage location of the record and its key, so that each key key corresponds to a storage location f(key). The mapping relationship between keywords and storage locations is established, and the formula is as follows:
存储位置 = f(关键字)Here, this correspondence f is called a hash function, also known as a hash (Hash) function.
Hash technology is used to store records in a continuous storage space, which is called a hash table or hash table. Then, the record storage location corresponding to the key is called the hash address.
Hashing is both a storage method and a lookup method. There is no logical relationship between the records of hashing technology, it is only related to keywords, so hashing is mainly a search-oriented storage structure.How to construct a hash function
2.1 Direct addressing method
The so-called direct addressing method means that a certain linear function value of the keyword is taken as the hash address, that is, the
advantages are : simple and uniform, and no conflict will occur.
Disadvantages: Need to know the distribution of keywords in advance, suitable for small and continuous lookup tables.
Due to such limitations, in real-world applications, this method is simple, but not commonly used.2.2 Numerical Analysis
If the keyword is a number with more digits, such as the 11-digit mobile phone number "130****1234", the first three digits are the access number; the middle four digits are the HLR identification number, indicating the attribution of the user number; The last four are the real user numbers. As shown below.
If you want to store the registration form of a company now, if you use the mobile phone number as the keyword, it is very likely that the first 7 digits are the same, and it is a good choice to choose the last 4 digits as the hash address. If conflicts are prone to occur, the extracted numbers are reversed, right ring displacement, etc. are performed. The overall purpose is to provide a hash function that can reasonably assign keys to various positions in the hash table.
The numerical analysis method is suitable for dealing with the situation that the number of keywords is relatively large. If the distribution of keywords is known in advance and the distribution of several bits of the keywords is relatively uniform, this method can be considered.
2.3 The method of taking the middle of the square The calculation of
this method is very simple. Suppose the keyword is 1234, then its square is 1522756, and then the middle 3 bits are extracted to be 227, which is used as the hash address.
The square method is more suitable for the case where the distribution of keywords is unknown and the number of digits is not very large.2.4 Folding method
Folding method is to divide the keyword into several parts with equal number of digits from left to right (note that the last part can be shorter when the number of digits is not enough), then superimpose these parts and sum them up, and press the length of the hash table, Take the last few bits as the hash address.
For example, the keyword is 9876543210, and the hash table is three digits long. Divide it into four groups, 987|654|321|0, then add them to sum 987 + 654 + 321 + 0 = 1962, and then find the last three digits Get the hash address 962.
The folding method does not need to know the distribution of keywords in advance, and is suitable for the case of a large number of keywords.2.5 Divide the remainder method
This method is the most commonly used method for constructing a hash function. For a hash function whose hash table length is m, the formula is:
mod means taking the modulo (remainder). In fact, this method can not only take the modulo directly on the keyword, but also fold it, square it and then take the modulo.
Obviously, the key to this method is to choose a suitable p. If p is not selected properly, conflicts may easily occur.
According to the experience of predecessors, if the table length of the hash table is m, usually p is the smallest prime number less than or equal to the table length (preferably close to m) or a composite number that does not contain prime factors less than 20.2.6 Random number method
Select a random number and take the random function value of the keyword as its hash address. That is f(key) = random(key). Here random is the random function. When the length of the keywords is not equal, it is more appropriate to use this method to construct the hash function.
In short, in reality, different hash functions should be used according to different situations. Here, only some considerations can be given for reference:
(1) The time required to calculate the hash address
(2) The length of the keyword;
( 3) The length of the hash table;
(4) The distribution of keywords;
(5) The frequency of record searches.
Combining the above factors, it is possible to decide which hash function is more suitable.Methods of Handling Hash Collision
In an ideal situation, the address calculated by the hash function for each keyword is different, but in reality, this is just an ideal. The market will encounter two keywords key1 != key2, but there are f(key1) = f(key2), this phenomenon is called conflict. The occurrence of collisions will cause search errors, so the collisions can be as few as possible by carefully designing the hash function, but they cannot be completely avoided.
3.1 Open addressing method The
so-called open addressing method is to search for the next empty hash address once a conflict occurs. As long as the hash table is large enough, the empty hash address can always be found and the record is stored.
Its formula is:
For example, the keyword set is {12, 67, 56, 16, 25, 37, 22, 29, 15, 47, 48, 34}, and the table length is 12. Hash function f(key) = key mod 12.
When calculating the first 5 numbers {12, 67, 56, 16, 25}, they are all hash addresses without conflict and are stored directly, as shown in the following table.
When calculating key = 37, it is found that f(37) = 1, which conflicts with the position of 25. Then apply the above formula f(37) = (f(37) + 1) mod 12 =2,. So 37 is stored in the position with the subscript 2. as shown in the table below.
The next 22, 29, 15, and 47 have no conflicts and are deposited normally, as shown in the following subscript.
When it reaches 48, it is calculated that f(48) = 0, which conflicts with the 0 position where 12 is located. It doesn't matter, we f(48) = (f(48) + 1) mod 12 = 1, which is at the same time as 25. conflict. So f(48) = (f(48) + 2) mod 12 = 2, still a conflict... Until f(48) = (f(48) + 6) mod 12 = 6, there is no space, as shown in the following table shown.
This conflict-solving open addressing method is called a linear probing method.Consider a step further, if this happens, when the last key = 34, f(key) = 10, which conflicts with the position of 22, but there is no empty position after 22, but there is an empty position in front of it, although it can be The result is obtained after continuously calculating the remainder, but the efficiency is very poor. Therefore, di=12, -12, 22, -22... q2, -q2 (q<= m/2) can be improved, which is equivalent to finding possible empty positions in both directions. For 34, take di = -1 to find an empty position. In addition, the purpose of adding the square operation is to prevent the keywords from gathering in a certain area. This method is called the quadratic detection method.
There is another method, in the event of conflict, the displacement amount di is calculated by using a random function, which is called a random detection method.
Since it is random, isn't di generated randomly when searching? How to get the same address? The random here is actually a pseudo-random number. Pseudo-random number means that if the random seed is set to be the same, the random function can be continuously called to generate a sequence that will not repeat. When searching, using the same random seed, the sequence it gets every time is figured out. The same di is of course. The same hash address can be obtained.
In short, as long as the hash table is not full, the open addressing method can always find an address that does not conflict, and is a commonly used method to resolve conflicts.
3.2 Re-hash function method
For the hash table, multiple hash functions can be prepared in advance.
Here RHi is a different hash function, which can be used in all of the above-mentioned division and remainder, folding, and square. Whenever a hash address collision occurs, another hash function is calculated.
This method can make the keywords not clustered, but it also increases the calculation time accordingly.
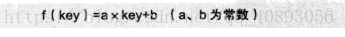










3.3 Chain address
method All the records whose keywords are synonyms are stored in a single linked list, which is called a synonym sub-table, and only the pointers in front of all the synonym sub-tables are stored in the hash table. For the keyword set {12, 67, 56, 16, 25, 37, 22, 29, 15, 47, 48, 34}, use the same 12 as the remainder and perform the remainder method to obtain the following structure.
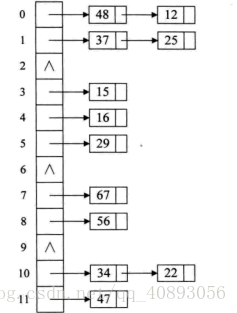
At this point, there is no longer any conflict to change addresses. No matter how many conflicts there are, it is just a matter of adding nodes to the singly linked list at the current position.
The chain address method provides the guarantee that the address will never be found for hash functions that may cause many collisions. Of course, this also brings the performance loss of traversing the singly linked list when searching.
3.4 Public overflow area method
This method is actually better to understand, do you conflict? Then find you an address again. Create a common overflow area for all conflicting keywords.

When searching, after calculating the hash address of the given value through the hash function, it is first compared with the corresponding position in the basic table. If they are equal, the search is successful; if they are not equal, the sequence search is performed in the overflow table. If there are few conflicting data relative to the base table, the structure of the common overflow area is still very high for the search performance.
- Hash table lookup implementation
#include<stdio.h>
#include<stdlib.h>
typedef struct hash{
int *elem; //数据元素存储基地址,动态分配数组
int count;
}HashTable;
//初始化散列表
void Init_HashTable(HashTable *h,int m)
{
int i;
h->elem=(int *)malloc(sizeof(int)*m);
if(!h->elem)
{
printf("散列表长度不能为0\n");
}
for(i=0;i<m;i++)
{
h->elem[i]=NULL;
}
}
//散列函数(采用的是除留余数法)
int Hash(int key,int m)
{
return key%m;
}
//将数组插入到散列表
void Insert_HashTable(HashTable *h,int key,int m)
{
int addr = Hash(key,m);
//开放地址法的线性探测
int i;
for(i=1;h->elem[addr];i++)
{
if(!i%2)
{
i=i/2;
}
addr=(key+((-1)^i)*i^2)%m;
}
h->elem[addr]=key;
}
//散列表查找关键字
void Search_HashTable(HashTable *h,int key,int m)
{
int addr = Hash(key,m);
int i=1;
for(;h->elem[addr]&&h->elem[addr]!=key;i++) //哈希表位置为addr的值不为空,且不等于key,则线性探测
{
if(!i%2)
{
i=i/2;
}
addr=(key+((-1)^i)*i^2)%m;
}
if(h->elem[addr]==key)
{
printf("the %d is at the %d of the HashTable\n",key,addr);
}else{
printf("no found\n");
}
}
int main(void)
{
int m = 10,key,i;
HashTable *h;
int a[8]={10,15,29,36,59,46,68,58};
printf("请输入要查找的数");
scanf("%d",&key);
Init_HashTable(h,m);
for(i=0;i<8;i++)
{
Insert_HashTable(h,a[i],m);
}
Search_HashTable(h,key,m);
for(i=0;i<m;i++)
{
printf("%5d",h->elem[i]);
}
return 0;
} 5. Performance Analysis of Hash Tables
If there are no collisions, hash lookups are the most efficient of the lookups described. Because its time complexity is O(1). However, a collision-free hash is just an ideal, and in practical applications, collisions are inevitable.
What factors does the average lookup length of a hash lookup depend on?
(1) Is the hash function
uniform ? The quality of the hash function directly affects the frequency of conflicts. However, different hash functions have the same probability of conflict for the same set of random keywords (why?? ), so its effect on the average lookup length can be ignored.
(2) The method of dealing with the conflict The
same keyword and the same hash function, but the method of dealing with the conflict is different, the average search length will be different. For example, the linear detection method may generate accumulation in dealing with conflicts, which is obviously not as good as secondary detection, while the chain address method will not generate any accumulation in dealing with conflicts, so it has better average search performance.
(3) The filling factor of the hash table The
so-called filling factor a = the number of records filled in the table/the length of the hash table. a indicates the fullness of the hash table. When more records are filled, the larger a is, the greater the possibility of conflict. That is, the average lookup length of a hash table depends on the fill factor, not the number of records in the lookup set.
No matter how large the number of records n is, an appropriate filling factor can always be selected to limit the average search length within a range. At this time, the search time complexity of the hash table is O(1). For this purpose, the space of the hash table is usually set larger than the set of lookup tables.
6. Adaptive range of
hash table The most suitable solution for hashing is to find records that are equal to a given value. For search, the comparison process is simplified, and the efficiency will be greatly improved.
However, hashing technology does not have the ability of many conventional data structures, such as the
same keyword, corresponding to many records, is not suitable for hashing technology;
hash table is also not suitable for range search and so on.