I think most people know what steps it has gone through from a source file (.c) to an executable program. I don't think many people can explain clearly what each step has done. ,clear and direct.
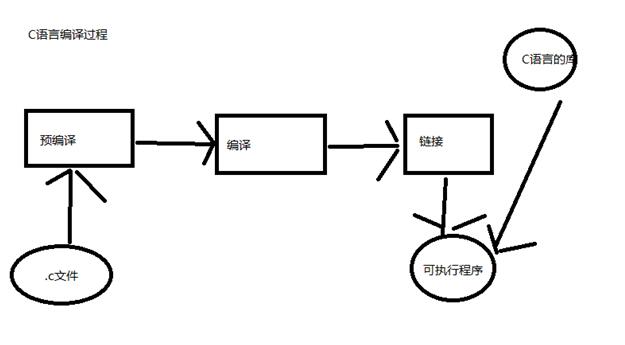
In fact, the general process is like this.
[First step] Edit hello.c

1 #include <stdio.h> 2 #include <stdlib.h> 3 int main() 4 { 5 printf("hello world!\n"); 6 return 0; 7 }
【Step 2】Preprocessing
The preprocessing process is essentially processing "#", directly copying the header file included in #include to hell.c; replacing the macro defined by #define, and deleting the useless comment part in the code, etc.
The specific things are as follows:
(1) Delete all #defines and expand all macro definitions. To put it bluntly, it is character replacement
(2) Process all conditional compilation instructions, #ifdef #ifndef #endif, etc., those with #
(3) Process #include and insert the file pointed to by #include into the line
(4) delete all comments
(5) Add line numbers and file labels, so that when debugging and compiling errors, you will know which line of which file it is.
(6) #pragma compiler directives are reserved, as the compiler needs to use them.
gcc -E hello.c -o ac can generate preprocessed files. By looking at the file content and file size, you can know that ac speaks stdio.h and stdlib.h are included.

【Step 3】Compile
The compilation process is essentially the process of translating high-level language into machine language, that is, doing these things for ac
(1) Lexical analysis,
(2) Syntax analysis
(3) Semantic Analysis
(4) Generate corresponding assembly code after optimization
From High Level Language -> Assembly Language -> Machine Language (Binary)
gcc -S hello.c -o as can generate assembly code

The assembly code is as follows.
1 .file "hello.c" 2 .section .rodata 3 .LC0: 4 .string "hello world!" 5 .text 6 .globl main 7 .type main, @function 8 main: 9 .LFB0: 10 .cfi_startproc 11 pushl %ebp 12 .cfi_def_cfa_offset 8 13 .cfi_offset 5, -8 14 movl %esp, %ebp 15 .cfi_def_cfa_register 5 16 andl $-16, %esp 17 subl $16, %esp 18 movl $.LC0, (%esp) 19 call puts 20 movl $0, %eax 21 leave 22 .cfi_restore 5 23 .cfi_def_cfa 4, 4 24 ret 25 .cfi_endproc 26 .LFE0: 27 .size main, .-main 28 .ident "GCC: (Ubuntu/Linaro 4.6.3-1ubuntu5) 4.6.3" 29 .section .note.GNU-stack,"",@progbits
gcc -c hello.c -o a.o将源文件翻译成二进制文件。类Uinx系统编译的结果生生成.o文件,Windows系统是生成.obj文件。
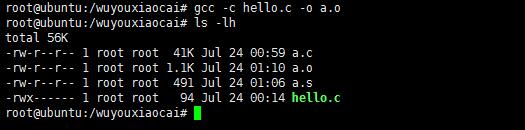
编译的过程就是把hello.c翻译成二进制文件
【第四步】链接
就像刚才的hello.c它使用到了C标准库的东西“printf”,但是编译过程只是把源文件翻译成二进制而已,这个二进制还不能直接执行,这个时候就需要做一个动作,
将翻译成的二进制与需要用到库绑定在一块。打个比方编译的过程就向你对你老婆说,我要吃雪糕。你只是给你老婆发出了你要吃雪糕的诉求而已,但是雪糕还没有到。
绑定就是说你要吃的雪糕你的老婆已经给你买了,你可以happy。
gcc hello.c -o a可以生成可执行程序。即gcc不带任何参数。ldd就可以看到你的可执行程序依赖的库。
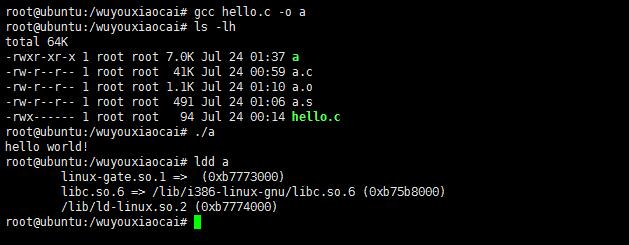
可以看到a.o的大小是1.1k,毕竟他只是把源文件翻译成二进制文件。a却有7k,应该是他多了很多“绳子”吧。在运行的时候这些“绳子”就将对应的库函数“牵过来”。很形象的比喻是不是?哈哈。libc.so.6 中就对咱们用的printf进行了定义。
I turned to an article and looked at the compilation process of c, and tried it manually. Recently, I was watching the java virtual machine. Since it involves the writing of jvm in c language, by the way, understanding c is also good for the operation of java!