Let's Hello Worldstart with an example of:
package main
import "fmt"
func main() {
fmt.Println("hello world")
}
When we finish typing the above hello world code on the keyboard, the file saved on the hard disk hello.gois a byte sequence, and each byte represents a character.
Open the hello.go file with vim, and in command line mode, enter the command:
:%!xxd
You can view the file contents in hexadecimal in vim:

The leftmost column represents the address value, the middle column represents the ASCII characters corresponding to the text, and the rightmost column is our code. Then execute in the terminal man ascii:
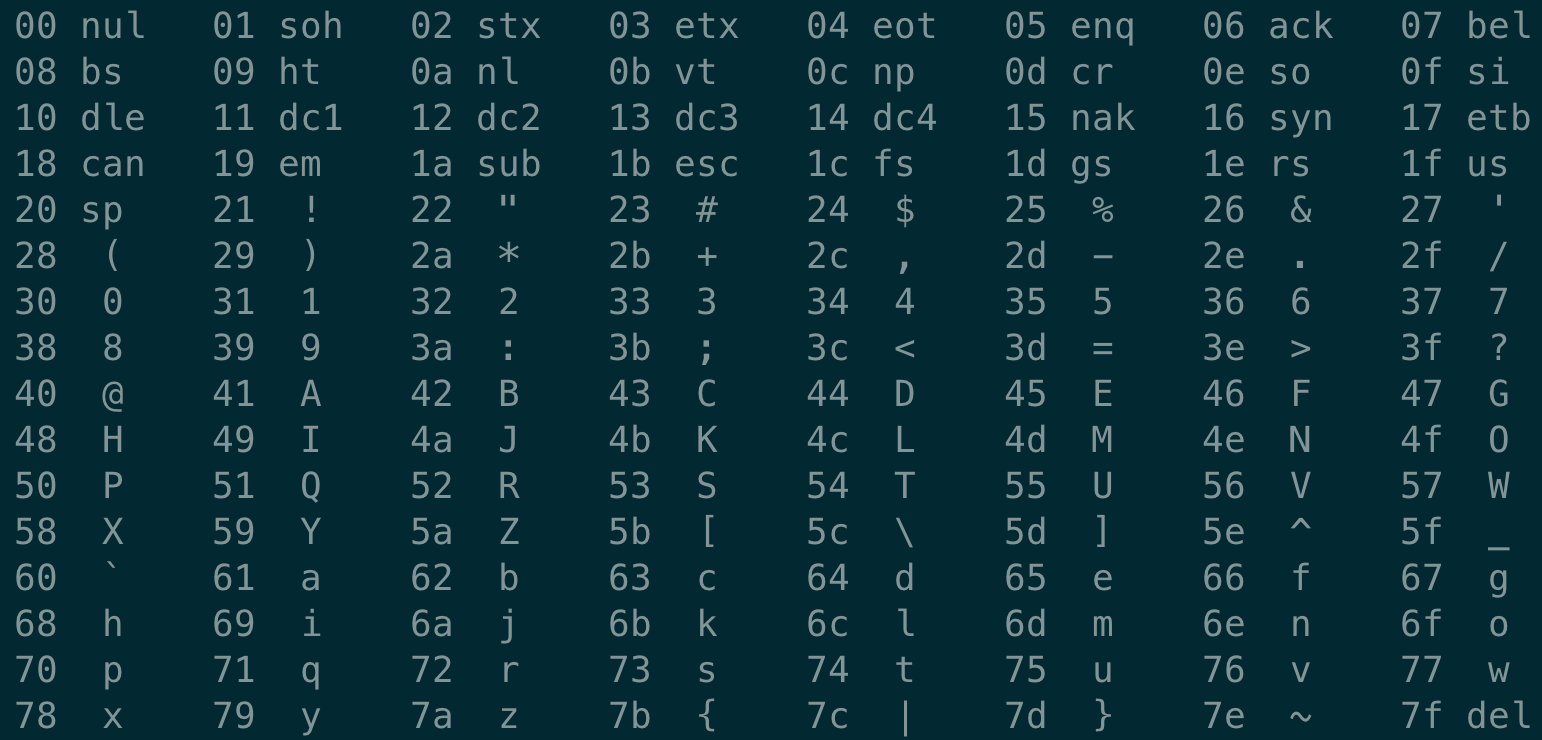
Comparing it with the ASCII character table, you can find that the middle column and the rightmost column are in one-to-one correspondence. In other words, the hello.go file just written is represented by ASCII characters, it is called 文本文件, and other files are called 二进制文件.
Of course, looking deeper, all data in the computer, such as disk files and data on the network, are actually composed of a string of bits, depending on how you look at it. In different situations, the same sequence of bytes may be represented as an integer, a floating point number, a string, or a machine instruction.
As for files like hello.go, 8 bits, that is, one byte is regarded as a unit (assuming that the characters in the source program are all ASCII codes), and is ultimately interpreted into Go source code that humans can read.
Go programs cannot be run directly. Each Go statement must be converted into a series of low-level machine language instructions, packaged together, and stored in the form of a binary disk file, which is an executable object file.
The conversion process from source files to executable target files:
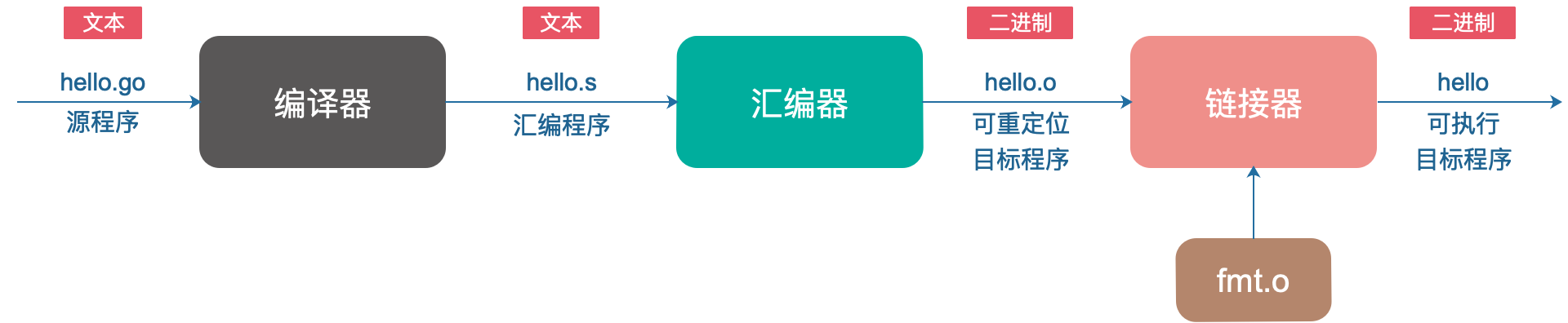
What completes the above stages is the Go compilation system. You must know the famous GCC (GNU Compile Collection), the Chinese name is GNU Compiler Suite. It supports C, C++, Java, Python, Objective-C, Ada, Fortran, Pascal, and can generate machine code for many different machines. .
Executable object files can be executed directly on the machine. Generally speaking, some initialization work is performed first; the entrance to the main function is found and the code written by the user is executed; after the execution is completed, the main function exits; then some finishing work is performed, and the whole process is completed.
In the next article, we will explore the process of 编译summing 运行.
The compiler source code in the Go source code is located src/cmd/compileunder the path, and the linker source code is located src/cmd/linkunder the path.
Compilation process
I prefer to use an IDE (Integrated Development Environment) to write code. Goland is used for Go source code. Sometimes I just click the "Run" button in the IDE menu bar and the program will run. This actually implies the process of compilation and linking. We usually combine compilation and linking together as a process called build.
The compilation process is to perform lexical analysis, syntax analysis, semantic analysis, and optimization on the source file, and finally generate an assembly code file as the .sfile suffix.
The assembler then converts the assembly code into instructions that the machine can execute. Since almost every assembly statement corresponds to a machine instruction, it is just a simple one-to-one correspondence, which is relatively simple. There is no syntax, semantic analysis, or optimization steps.
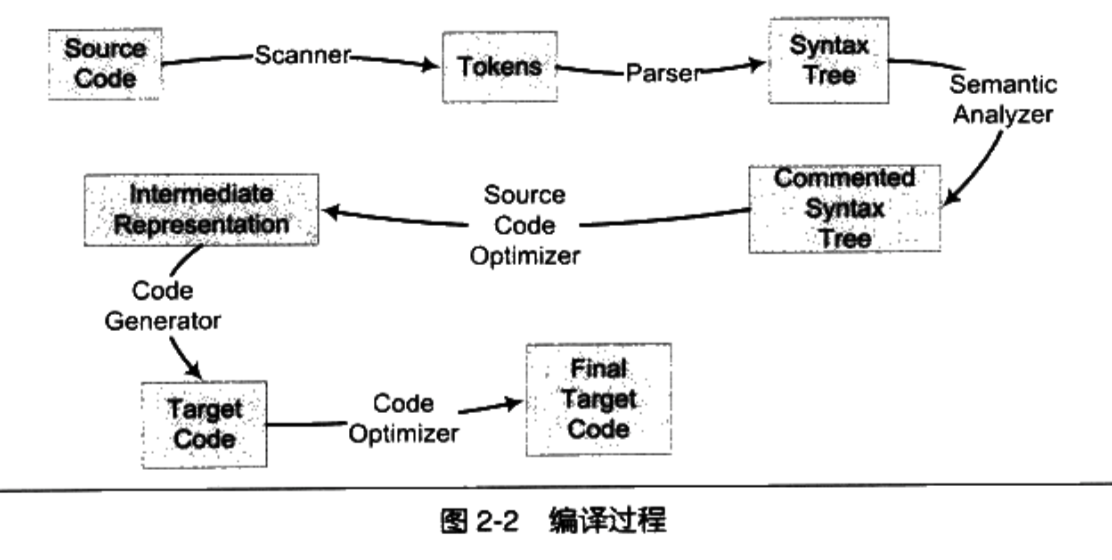
A compiler is a tool that translates high-level languages into machine language. The compilation process is generally divided into six steps: scanning, syntax analysis, semantic analysis, source code optimization, code generation, and target code optimization. The picture below is from "Programmer's Self-cultivation":
lexical analysis
From the previous example, we know that a Go program file is nothing more than a bunch of binary bits from the perspective of the machine. We can understand it because Goland encodes this bunch of binary bits according to ASCII code (actually UTF-8). For example, 8 bits are divided into a group, corresponding to a character, and can be found by comparing the ASCII code table.
When all binary bits are mapped to ASCII characters, we can see meaningful strings. It may be a keyword, such as package; it may be a string, such as "Hello World".
This is what lexical analysis actually does. The input is the original Go program file. From the perspective of the lexical analyzer, it is just a bunch of binary bits. It is unknown what they are. After its analysis, it turns into meaningful tokens. Simply put, lexical analysis is the process in computer science of converting a sequence of characters into a sequence of tokens.
Let’s take a look at the definition given on Wikipedia:
Lexical analysis is the process in computer science of converting a sequence of characters into a sequence of tokens. The program or function that performs lexical analysis is called a lexical analyzer (lexer for short), also called a scanner. Lexical analyzers generally exist in the form of functions for the syntax analyzer to call.
.goThe file is input to the scanner (Scanner), which uses an 有限状态机algorithm similar to that of the source code to split the character series of the source code into a series of tokens (Token).
Tokens are generally divided into these categories: keywords, identifiers, literals (including numbers and strings), and special symbols (such as plus sign, equal sign).
For example, for the following code:
slice[i] = i * (2 + 6)
Contains a total of 16 non-empty characters. After scanning,
| mark | type |
|---|---|
| slice | identifier |
| [ | left square bracket |
| i | identifier |
| ] | right square bracket |
| = | Assignment |
| i | identifier |
| * | Multiplication sign |
| ( | left parenthesis |
| 2 | number |
| + | plus |
| 6 | number |
| ) | right parenthesis |
The above example comes from "Programmer's Self-cultivation", which mainly explains the content related to compilation and linking. It is very exciting and is recommended to be read.
Go language (the Go version of this article is 1.9.2) Token supported by the scanner path in the source code:
src/cmd/compile/internal/syntax/token.go
Feel it:
var tokstrings = [...]string{
// source control
_EOF: "EOF",
// names and literals
_Name: "name",
_Literal: "literal",
// operators and operations
_Operator: "op",
_AssignOp: "op=",
_IncOp: "opop",
_Assign: "=",
_Define: ":=",
_Arrow: "<-",
_Star: "*",
// delimitors
_Lparen: "(",
_Lbrack: "[",
_Lbrace: "{",
_Rparen: ")",
_Rbrack: "]",
_Rbrace: "}",
_Comma: ",",
_Semi: ";",
_Colon: ":",
_Dot: ".",
_DotDotDot: "...",
// keywords
_Break: "break",
_Case: "case",
_Chan: "chan",
_Const: "const",
_Continue: "continue",
_Default: "default",
_Defer: "defer",
_Else: "else",
_Fallthrough: "fallthrough",
_For: "for",
_Func: "func",
_Go: "go",
_Goto: "goto",
_If: "if",
_Import: "import",
_Interface: "interface",
_Map: "map",
_Package: "package",
_Range: "range",
_Return: "return",
_Select: "select",
_Struct: "struct",
_Switch: "switch",
_Type: "type",
_Var: "var",
}
It is still relatively familiar, including names and literals, operators, delimiters and keywords.
And the path to the scanner is:
src/cmd/compile/internal/syntax/scanner.go
The most critical function is the next function, which continuously reads the next character (not the next byte, because the Go language supports Unicode encoding, not like the ASCII code example we gave earlier, where one character only has one byte) , until these characters can constitute a Token.
func (s *scanner) next() {
// ……
redo:
// skip white space
c := s.getr()
for c == ' ' || c == '\t' || c == '\n' && !nlsemi || c == '\r' {
c = s.getr()
}
// token start
s.line, s.col = s.source.line0, s.source.col0
if isLetter(c) || c >= utf8.RuneSelf && s.isIdentRune(c, true) {
s.ident()
return
}
switch c {
// ……
case '\n':
s.lit = "newline"
s.tok = _Semi
case '0', '1', '2', '3', '4', '5', '6', '7', '8', '9':
s.number(c)
// ……
default:
s.tok = 0
s.error(fmt.Sprintf("invalid character %#U", c))
goto redo
return
assignop:
if c == '=' {
s.tok = _AssignOp
return
}
s.ungetr()
s.tok = _Operator
}
The main logic of the code is to c := s.getr()obtain the next unparsed character through switch-caseToken, and record the relevant row and column numbers, thus completing a parsing process.
The lexical analyzer scanner in the current package only provides the next method for the upper layer. The lexical parsing process is lazy. Next will be called to obtain the latest Token only when the upper layer parser needs it.
Gramma analysis
The Token sequence generated in the previous step needs to be further processed 表达式to node 语法树.
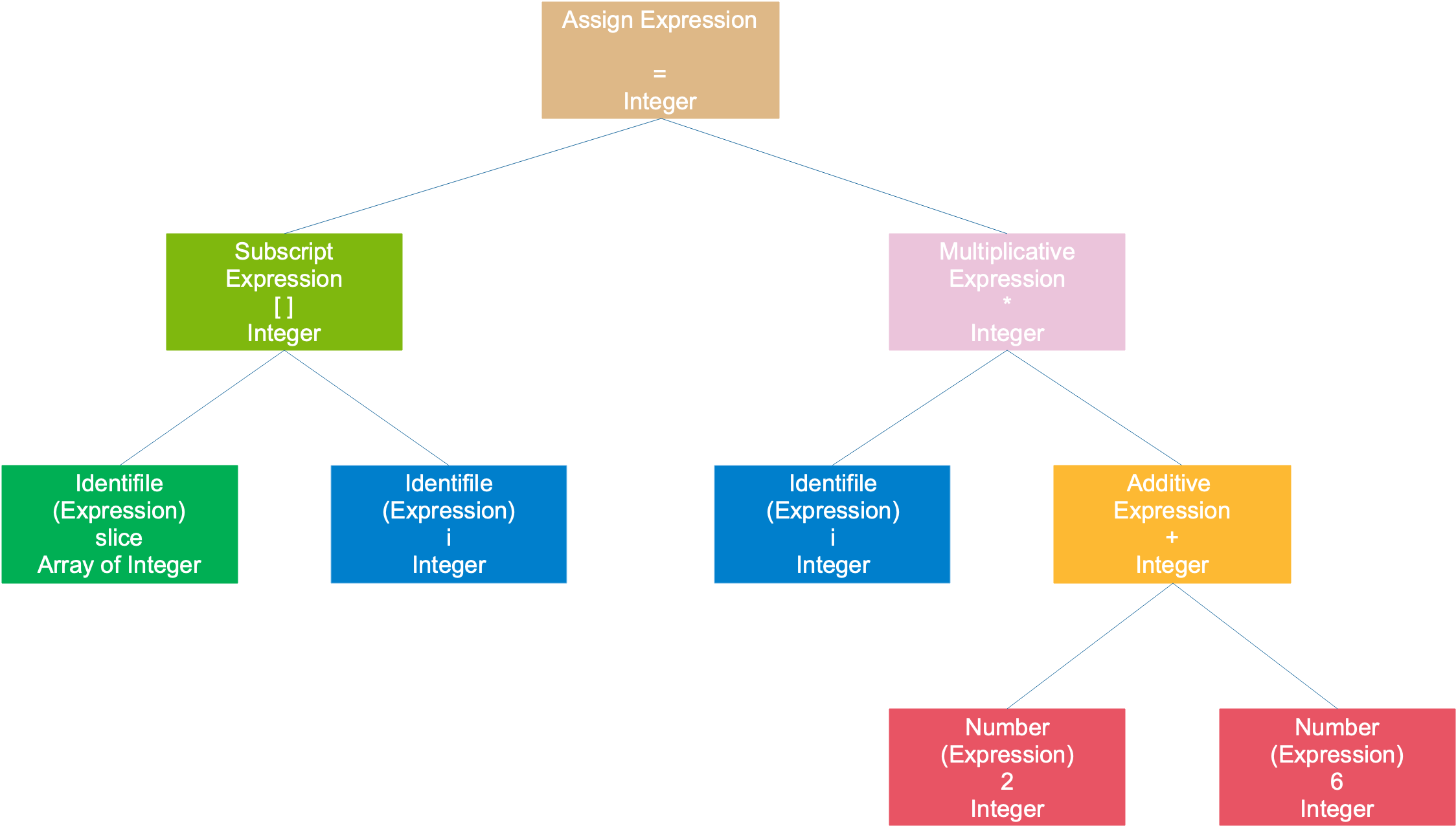
For example, in the first example, slice[i] = i * (2 + 6)the resulting syntax tree is as follows:

The entire statement is regarded as an assignment expression, the left subtree is an array expression, and the right subtree is a multiplication expression; the array expression consists of 2 symbolic expressions; the multiplication expression is composed of a symbolic expression It consists of an expression and a plus sign expression; the plus sign expression consists of two numbers. Symbols and numbers are the smallest expressions that can no longer be decomposed and usually serve as leaf nodes of a tree.
The process of syntax analysis can detect some formal errors, such as whether half of the parentheses are missing, +an expression is missing an operand, etc.
Grammar analysis is a process that analyzes the input text composed of Token sequences according to a specific formal grammar (Grammar) and determines its grammatical structure.
Semantic Analysis
After the grammatical analysis is completed, we do not know what the specific meaning of the statement is. If the two subtrees of the number above *are two pointers, this is illegal, but syntax analysis cannot detect it. This is what semantic analysis does.
What can be checked at compile time is static semantics, which can be considered to be in the "code" stage, including variable type matching, conversion, etc. For example, when assigning a floating point value to a pointer variable, if there is an obvious type mismatch, a compilation error will be reported. As for errors that only occur during runtime: if you accidentally add a 0, semantic analysis cannot detect it.
After the semantic analysis phase is completed, each node will be marked with a type:
In this phase, the Go compiler checks the types of constants, types, function declarations, and variable assignment statements, and then checks the types of keys in the hash. Functions that implement type checking are usually giant switch/case statements of several thousand lines.
Type checking is the second stage of Go language compilation. After lexical and syntactic analysis, we get the abstract syntax tree corresponding to each file. The subsequent type checking will traverse the nodes in the abstract syntax tree and perform the type check on each node. Check to find any grammatical errors.
The abstract syntax tree may also be rewritten during this process, which not only removes some code that will not be executed to optimize compilation and improve execution efficiency, but also modifies the operation types of nodes corresponding to keywords such as make and new.
For example, the more commonly used make keyword can be used to create various types, such as slice, map, channel, etc. At this step, for the make keyword, that is, the OMAKE node, its parameter type will be checked first, and depending on the type, the corresponding branch will be entered. If the parameter type is slice, it will enter the TSLICE case branch and check whether len and cap meet the requirements, such as len <= cap. Finally the node type will be changed from OMAKE to OMAKESLICE.
Intermediate code generation
We know that the compilation process can generally be divided into front-end and back-end. The front-end generates intermediate code that is independent of the platform, and the back-end generates different machine codes for different platforms.
The previous lexical analysis, syntax analysis, semantic analysis, etc. all belong to the compiler front-end, and the subsequent stages belong to the compiler back-end.
There are many optimization links in the compilation process, and this link refers to source code level optimization. It converts syntax trees into intermediate codes, which are sequential representations of syntax trees.
The intermediate code is generally independent of the target machine and runtime environment. It has several common forms: three-address code and P-code. For example, the most basic one 三地址码is this:
x = y op z
It means that after the variable y and variable z perform the op operation, they are assigned to x. op can be a mathematical operation such as addition, subtraction, multiplication and division.
The example we gave earlier can be written in the following form:
t1 = 2 + 6
t2 = i * t1
slice[i] = t2
Here 2 + 6 can be calculated directly, so that the temporary variable t1 is "optimized", and the t1 variable can be reused, so t2 can also be "optimized". After optimization:
t1 = i * 8
slice[i] = t1
The intermediate code representation of Go language is SSA (Static Single-Assignment, static single assignment). It is called single assignment because each name is assigned only once in SSA. .
At this stage, the corresponding variables used to generate intermediate code will be set according to the CPU architecture, such as the size of pointers and registers used by the compiler, the list of available registers, etc. The two parts, intermediate code generation and machine code generation, share the same settings.
Before generating intermediate code, some elements of nodes in the abstract syntax tree are replaced. Here is a picture from a blog related to "Faith-Oriented Programming" compilation principles:
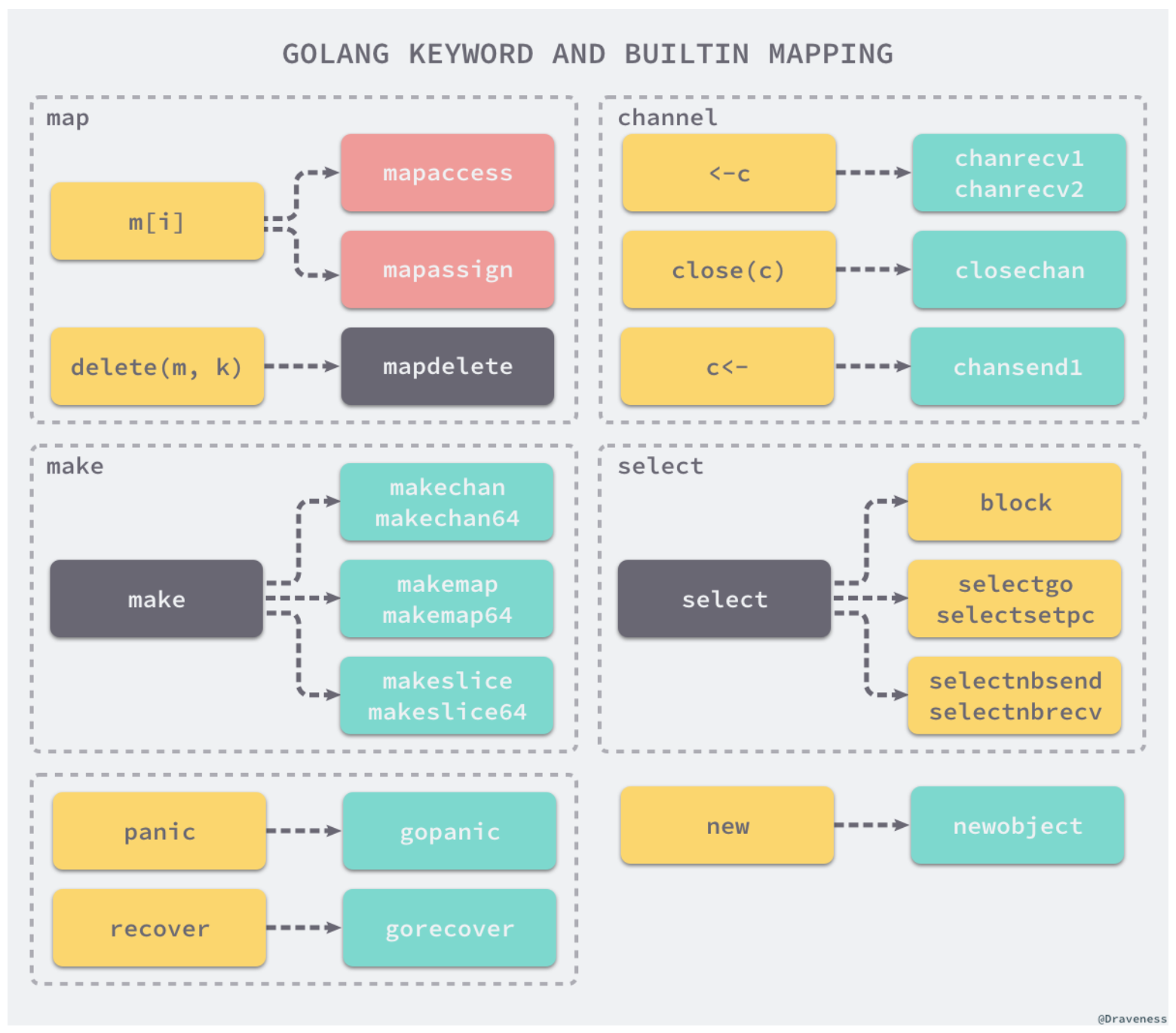
For example, the map operation m[i] will be converted into mapacess or mapassign here.
The main program of the Go language will call functions in the runtime when executed. In other words, the functions of keywords and built-in functions are actually completed by the language compiler and runtime.
The generation process of intermediate code is actually the conversion process from AST abstract syntax tree to SSA intermediate code. During this period, the keywords in the syntax tree will be updated once, and the updated syntax tree will undergo multiple rounds of processing to transform the final SSA. intermediate code.
Target code generation and optimization
Different machines have different machine word lengths, registers, etc., which means that the machine code running on different machines is different. The purpose of the final step is to generate code that can run on different CPU architectures.
In order to squeeze out every drop of oil and water from the machine, the target code optimizer will optimize some instructions, such as using shift instructions instead of multiplication instructions.
I really don’t have the ability to go deep into this area, but fortunately I don’t need to go deep. For software development engineers at the application layer, it is enough to understand it.
link process
The compilation process is carried out for a single file, and files inevitably refer to global variables or functions defined in other modules. The addresses of these variables or functions can only be determined at this stage.
The linking process is to link the object files generated by the compiler into executable files. The final file is divided into various segments, such as data segments, code segments, BSS segments, etc., and will be loaded into memory during runtime. Each segment has different read, write, and execution attributes, which protects the safe operation of the program.