Section 1 Introduction to Jsoup
1. jsoup is a Java HTML parser, which can directly parse a URL address and HTML text content. It provides a very low-effort API for fetching and manipulating data through DOM, CSS, and jQuery-like manipulation methods.
2. Create a maven project
Add jar package to pom
<!-- https://mvnrepository.com/artifact/org.apache.httpcomponents/httpclient --> <dependency> <groupId>org.apache.httpcomponents</groupId> <artifactId>httpclient</artifactId> <version>4.5.2</version> </dependency> <!-- https://mvnrepository.com/artifact/org.jsoup/jsoup --> <dependency> <groupId>org.jsoup</groupId> <artifactId>jsoup</artifactId> <version>1.8.3</version> </dependency>
Take blog garden as an example

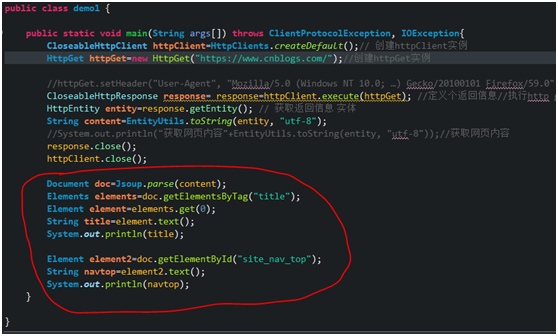
result

mistake:
Description Resource Path Location Type
Missing artifact commons-codec:commons-codec:jar:1.10 pom.xml /Jsoup line 1 Maven Dependency Problem
Solution: add a <dependencyManagement> tag
<dependencyManagement>
<dependencies>
Dependency package
</dependencies>
</dependencyManagement>
The second section Jsoup finds DOM elements
getElementById(String id) Query DOM according to id
getElementsByTag(String tagName) Query the DOM according to the tag name
getElementsByClass(String className) Query the DOM according to the style name getElementsByAttribute(String key) Query the DOM according to the attribute name getElementsByAttributeValue(String key,String value) Query the DOM according to the attribute name and attribute value
Still take the blog garden as an example
1. getElementsByClass(String className) Query the DOM according to the style name
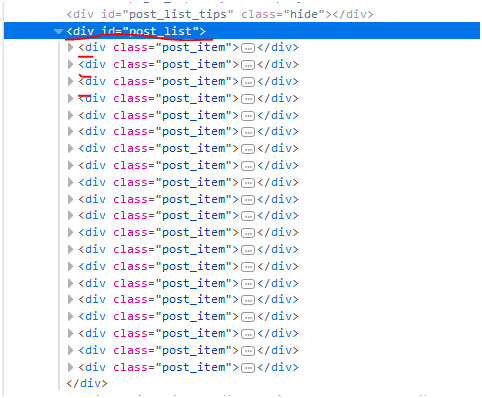
Each poem_item corresponds to a blog title
code show as below
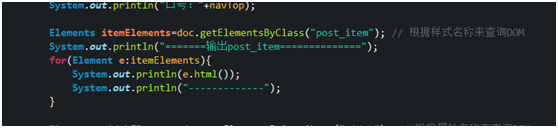
result
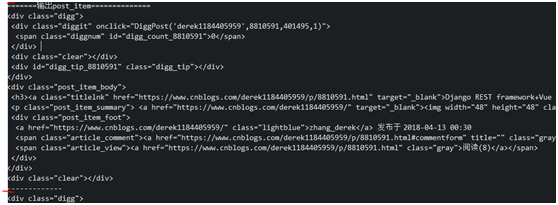
2. getElementsByAttribute(String key) Query the DOM according to the attribute name

The circle marks the attribute name, and the horizontal line marks the attribute value

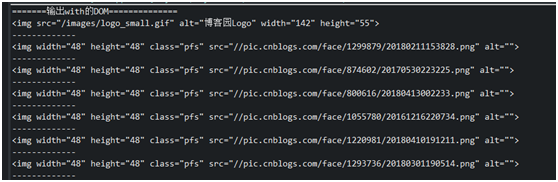
3. getElementsByAttributeValue(String key,String value) Query the DOM according to the attribute name and attribute value
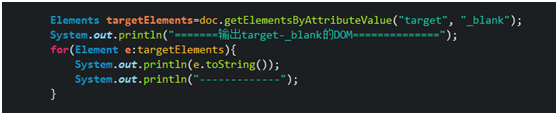

It will climb to the tag where the attribute name is located and all attributes of the tag
Section 3 Jsoup uses selector syntax to find DOM
Find hierarchical relationships, such as multiple divs nested under divs
Add the # class attribute before the Id. Add nothing before the label
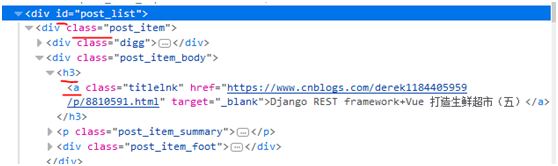
1. Get the title link of all blogs
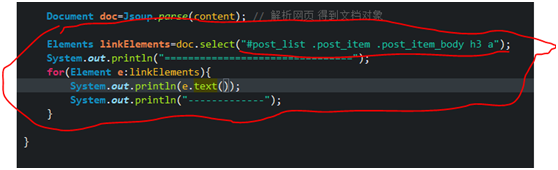

How to get the link of the <a> tag href? See Section 4
2、
a[href] a tag with href attribute
img[src$=.png] image tag with png suffix
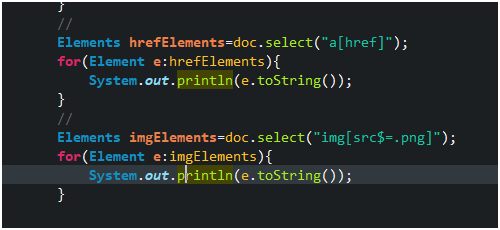
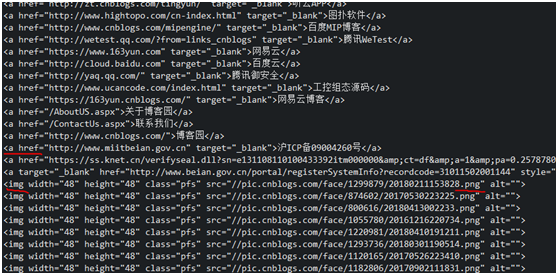
3. Get the first element of the collection
Previously used get(0)
Elements elements=doc.getElementsByTag("title"); // Get all DOM elements whose tag is title
Element element=elements.get(0); // get the first element
Now using a method first() encapsulated
Elementelement=doc.getElementsByTag("title").first();
Of course, there is also the last
The fourth section Jsoup gets the attribute value of the DOM element
1. How to get the attribute value of the href attribute of the a tag

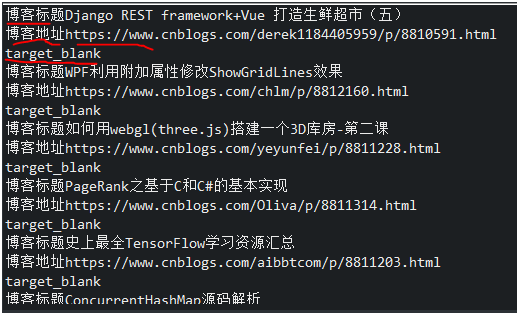
.text() remove html from plain text

.html() get html including text
