1. Introduction
XML (eXtensible Markup Language) refers to the extensible markup language, which is designed to transmit and store data. It has become the core of many new technologies and has different applications in different fields. It is an inevitable product of web development to a certain stage. It not only has the core characteristics of SGML, but also has the simple characteristics of HTML, and also has many new characteristics such as clarity and good structure.
There are three common ways for python to parse XML: one is the xml.dom.* module, which is the implementation of the W3C DOM API. If you need to process the DOM API, this module is very suitable. Note that there are many modules in the xml.dom package, which must be distinguished. The second is the xml.sax.* module, which is an implementation of the SAX API. This module sacrifices convenience for speed and memory usage. SAX is an event-based API, which means it can be "in the air" "Process a huge number of documents without fully loading them into memory; the third is the xml.etree.ElementTree module (ET for short), which provides a lightweight Python-style API, ET is much faster than DOM, and There are many pleasant APIs to use, ET's ET.iterparse also provides "in the air" processing compared to SAX, there is no need to load the entire document into memory, ET's average performance is about the same as SAX, but The API is a bit more efficient and easy to use.
2. Detailed explanation
The parsed xml file (country.xml):
View on CODE Snippet Derives to my snippet
<?xml version="1.0"?>
<data>
<country name="Singapore">
<rank>4</rank>
<year>2011</year>
<gdppc>59900</gdppc>
<neighbor name="Malaysia" direction="N"/>
</country>
<country name="Panama">
<rank>68</rank>
<year>2011</year>
<gdppc>13600</gdppc>
<neighbor name="Costa Rica" direction="W"/>
<neighbor name="Colombia" direction="E"/>
</country>
</data>
1、xml.etree.ElementTree
ElementTree was born to process XML, and it has two implementations in the Python standard library: a pure Python implementation, such as xml.etree.ElementTree, and the faster xml.etree.cElementTree. Note: try to use the C implementation as it is faster and consumes less memory.
Check out the CODE Snippets Derive to My Snippets.
try: import xml.etree.cElementTree as AND except ImportError: import xml.etree.ElementTree as AND
This is a common way to make different Python libraries use the same API, and since Python 3.3 the ElementTree module will automatically find available C libraries to speed up, so just import xml.etree.ElementTree.
View Code Slice Derives to My Code Slice on CODE
#! / usr / bin / evn python
#coding:utf-8
try:
import xml.etree.cElementTree as AND
except ImportError:
import xml.etree.ElementTree as AND
import sys
try:
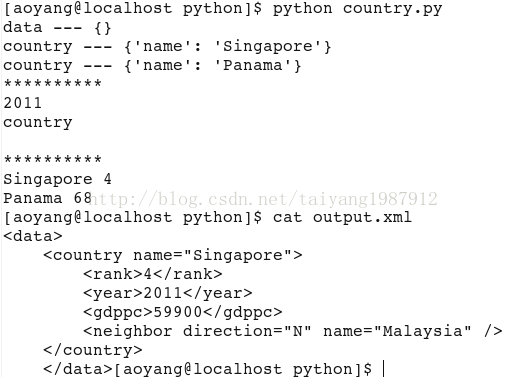
tree = ET.parse("country.xml") #Open the xml document
#root = ET.fromstring(country_string) #pass xml from string
root = tree.getroot() #Get the root node
except Exception, e:
print "Error:cannot parse file:country.xml."
sys.exit(1)
print root.tag, "---", root.attrib
for child in root:
print child.tag, "---", child.attrib
print "*"*10
print root[0][1].text #Access by subscript
print root[0].tag, root[0].text
print "*"*10
for country in root.findall('country'): #Find all country nodes under the root node
rank = country.find('rank').text #The value of the node rank under the child node
name = country.get('name') #The value of the attribute name under the child node
print name, rank
#Modify the xml file
for country in root.findall('country'):
rank = int(country.find('rank').text)
if rank > 50:
root.remove(country)
tree.write('output.xml')
Reference: https://docs.python.org/2/library/xml.etree.elementtree.html
2. xml.dom.*
The Document Object Model (DOM for short) is a standard programming interface recommended by the W3C organization for dealing with extensible markup languages. When a DOM parser parses an XML document, it reads the entire document at one time, saves all elements in the document in a tree structure in memory, and then you can use different functions provided by DOM to read or modify the document. The content and structure of the xml file can also be written to the modified content. In python, xml.dom.minidom is used to parse xml files. The example is as follows:
View code slices on CODE Derived from my code slices
#!/usr/bin/python
#coding=utf-8
from xml.dom.minidom import parse
import xml.dom.minidom
# Open XML document with minidom parser
DOMTree = xml.dom.minidom.parse("country.xml")
Data = DOMTree.documentElement
if Data.hasAttribute("name"):
print "name element : %s" % Data.getAttribute("name")
# Get all countries in the collection
Countrys = Data.getElementsByTagName("country")
# print the details of each country
for Country in Countrys:
print "*****Country*****"
if Country.hasAttribute("name"):
print "name: %s" % Country.getAttribute("name")
rank = Country.getElementsByTagName('rank')[0]
print "rank: %s" % rank.childNodes[0].data
year = Country.getElementsByTagName('year')[0]
print "year: %s" % year.childNodes[0].data
gdppc = Country.getElementsByTagName('gdppc')[0]
print "gdppc: %s" % gdppc.childNodes[0].data
for neighbor in Country.getElementsByTagName("neighbor"):
print neighbor.tagName, ":", neighbor.getAttribute("name"), neighbor.getAttribute("direction")

Reference: https://docs.python.org/2/library/xml.dom.html
3, xml.sax. *
SAX is an event-driven API. Parsing XML using SAX involves two parts: a parser and an event handler. The parser is responsible for reading the XML document and sending events to the event handler, such as element start and element end events; and the event handler is responsible for responding to the events and processing the transmitted XML data. To use the sax method to process xml in python, first introduce the parse function in xml.sax, and the ContentHandler in xml.sax.handler. It is often used in the following situations: 1. To process large files; 2. To only need part of the file, or to get specific information from the file; 3. When you want to build your own object model.
ContentHandler class method introduction
(1) characters(content) method
call timing:
starting from the line, before encountering the label, there are characters, and the value of content is these strings.
From one tag, until the next tag is encountered, there are characters, and the value of content is these strings.
From a tag, until the line terminator is encountered, there are characters, and the value of content is these strings.
Tags can be start tags or end tags.
(2) The startDocument() method
is called when the document is started.
(3) The endDocument() method
is called when the parser reaches the end of the document.
(4) The startElement(name, attrs) method
is called when the XML start tag is encountered, name is the name of the tag, and attrs is the attribute value dictionary of the tag.
(5) The endElement(name) method
is called when the XML end tag is encountered.
View Code Slice Derives to My Code Slice on CODE
#coding=utf-8
#!/usr/bin/python
import xml.sax
class CountryHandler(xml.sax.ContentHandler):
def __init__(self):
self.CurrentData = ""
self.rank = ""
self.year = ""
self.gdppc = ""
self.neighborname = ""
self.neighbordirection = ""
# Element start event handler
def startElement(self, tag, attributes):
self.CurrentData = tag
if tag == "country":
print "*****Country*****"
name = attributes["name"]
print "name:", name
elif tag == "neighbor":
name = attributes["name"]
direction = attributes["direction"]
print name, "->", direction
# Element end event handler
def endElement(self, tag):
if self.CurrentData == "rank":
print "rank:", self.rank
elif self.CurrentData == "year":
print "year:", self.year
elif self.CurrentData == "gdppc":
print "gdppc:", self.gdppc
self.CurrentData = ""
# Content event handler
def characters(self, content):
if self.CurrentData == "rank":
self.rank = content
elif self.CurrentData == "year":
self.year = content
elif self.CurrentData == "gdppc":
self.gdppc = content
if __name__ == "__main__":
# Create an XMLReader
parser = xml.sax.make_parser()
# turn off namepsaces
parser.setFeature(xml.sax.handler.feature_namespaces, 0)
# Override ContextHandler
Handler = CountryHandler()
parser.setContentHandler(Handler)
parser.parse("country.xml")

4, libxml2 and lxml parsing xml
libxml2 is an xml parser developed in C language. It is a free and open source software based on the MIT License. Many programming languages have implementations based on it. The libxml2 module in python is a little short: the xpathEval() interface does not support similar The usage of the template does not affect the usage. Because libxml2 is developed in C language, it is inevitable to be a little uncomfortable in the way of using the API interface.
View Code Slice Derives to My Code Slice on CODE
#!/usr/bin/python
#coding=utf-8
import libxml2
doc = libxml2.parseFile("country.xml")
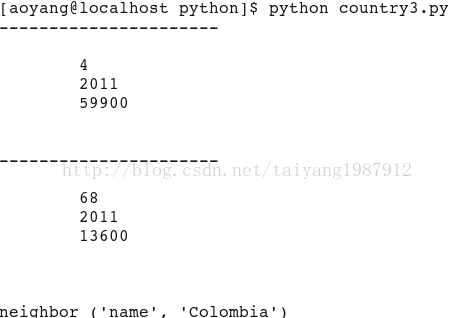
for book in doc.xpathEval('//country'):
if book.content != "":
print "----------------------"
print book.content
for node in doc.xpathEval("//country/neighbor[@name = 'Colombia']"):
print node.name, (node.properties.name, node.properties.content)
doc.freeDoc()
lxml is developed in python language based on libxml2. It is more suitable for python developers than lxml in terms of use, and the xpath() interface supports the usage of similar templates.
View Code Slice Derives to My Code Slice on CODE

3. Summary
(1) The class libraries or modules available for XML parsing in Python include xml, libxml2, lxml, xpath, etc. For in-depth understanding, you need to refer to the corresponding documents.
(2) Each analysis method has its own advantages and disadvantages, and the performance of all aspects can be considered before choosing.
(3) If there are any deficiencies, please leave a message, thank you in advance!