An artifact that increases the crawling rate by 10 times
1 Introduction
Xiao Diaosi : Is there any way to increase the crawling rate?
Xiaoyu : Well, there are many ways to improve it, such as multi-threading and decorators.
Xiao Diaosi : Well, is there any other method?
Xiaoyu : Uh, let me think about it,

Xiaoyu : Hey~ I thought of
Xiao Diaosi : What is that?
Small fish : requests_cache

At this time, Xiao Diaosi's expression
2、requests_cache
2.1 Introduction
requests_cache is an extension package of the requests library. Using it, we can easily cache requests and get the corresponding crawling results directly.
2.2 Installation
Old rules, pip install:
pip install requests-cache
Other ways to install:
" Python3, choose Python to automatically install third-party libraries, and say goodbye to pip! ! "
" Python3: I only use one line of code to import all Python libraries! ! 》
After installation, let's take a look at its usage.
2.3 Code Examples
2.3.1 CachedSession method
1. The default request of requests
In order to reflect its speed, we first write a default request
Code display
# -*- coding:utf-8 -*-
# @Time : 2022-03-18
# @Author : carl_DJ
'''
requests 方法请求
'''
import requests
import time
#开始时间
start = time.time()
#session
session = requests.session()
#循环爬取,10次
for i in range(10):
session.get('http://httpbin.org/delay/2')
print(f'Finish{i + 1} requests')
end = time.time()
print('Cost time', end - start)
operation result
Finish2 requests
Finish3 requests
Finish4 requests
Finish5 requests
Finish6 requests
Finish7 requests
Finish8 requests
Finish9 requests
Finish10 requests
Cost time 24.35784935951233
Process finished with exit code 0
We can see that it took 24+ seconds
So, let's use the CachedSession method to see if we can speed
up 2. CachedSession method
Code display
# -*- coding:utf-8 -*-
# @Time : 2022-03-18
# @Author : carl_DJ
import requests_cache
import time
start = time.time()
#CachedSession方法,在本地生成 demo_cache.sqlite
session = requests_cache.CachedSession('demo_cache')
for i in range(10):
session.get('http://httpbin.org/delay/2')
print(f'Finish{i + 1} requests')
end = time.time()
print('Cost time', end -start)
operation result
Finish1 requests
Finish2 requests
Finish3 requests
Finish4 requests
Finish5 requests
Finish6 requests
Finish7 requests
Finish8 requests
Finish9 requests
Finish10 requests
Cost time 8.624990701675415
Process finished with exit code 0
Generate the content of the demo_cache.sqlite database

file locally, we
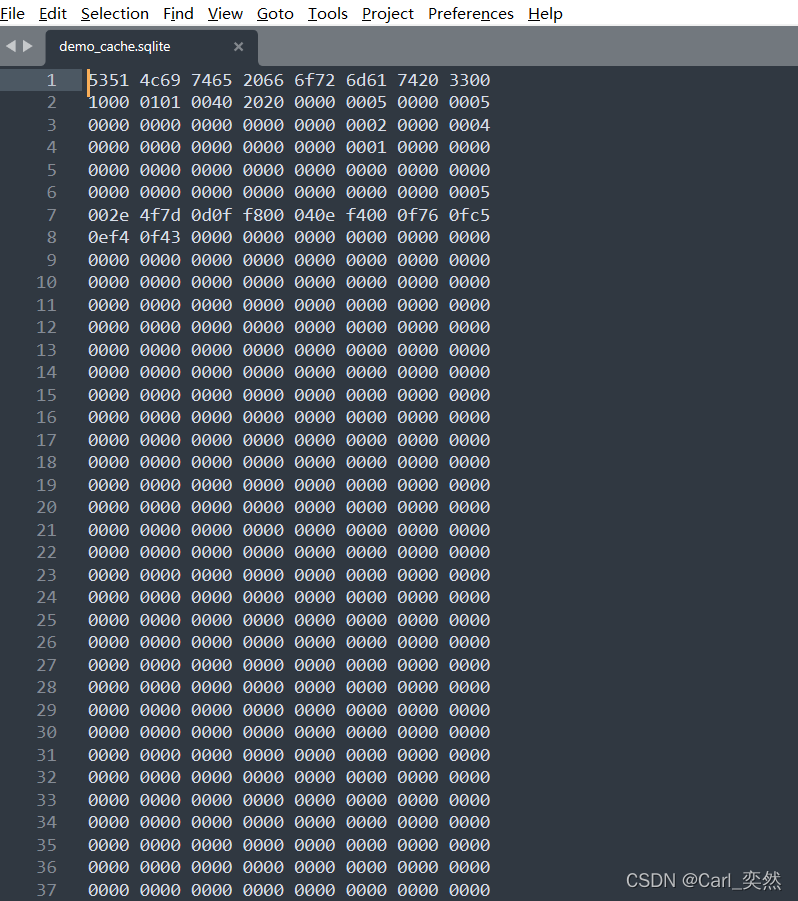
can see that the key in this key-value record is a hash value, the value is a Blob object, and the content is the result of the Response.
As you can guess, a corresponding key will be generated for each request, and then requests-cache will store the corresponding result in the SQLite database. Subsequent requests have the same URL as the first request. After some calculation of their keys It's all the same, so subsequent 2-10 requests are returned immediately.
Yes, using this mechanism, we can skip a lot of repeated requests, which greatly saves crawling time.
2.3.2 install_cache method
1. Patch writing
Of course, we have another method. Without modifying the original code request method, we
add a method to improve the crawling rate.
Code display
# -*- coding:utf-8 -*-
# @Time : 2022-03-18
# @Author : carl_DJ
import requests
import requests_cache
import time
#调用requests_cache.install_cache方法
requests_cache.install_cache('demo_path_cache')
start = time.time()
session = requests.session()
for i in range(10):
session.get('http://httpbin.org/delay/2')
print(f'Finish{i + 1} requests')
end = time.time()
print('Cost time', end -start)
operation result
Finish1 requests
Finish2 requests
Finish3 requests
Finish4 requests
Finish5 requests
Finish6 requests
Finish7 requests
Finish8 requests
Finish9 requests
Finish10 requests
Cost time 7.516860723495483
Process finished with exit code 0
makefile

2. Modify the configuration
In the first two demos, requests-cache uses SQLite as the cache object by default,
and this time, we use filesystem as the cache object
Code display
# -*- coding:utf-8 -*-
# @Time : 2022-03-18
# @Author : carl_DJ
import requests
import requests_cache
import time
#使用filesystem作为缓存对象
requests_cache.install_cache('demo_file_cache', backend='filesystem')
start = time.time()
session = requests.session()
for i in range(10):
session.get('http://httpbin.org/delay/2')
print(f'Finish{i + 1} requests')
end = time.time()
print('Cost time', end -start)
Running results

Other backends are:
['dynamodb', 'filesystem', 'gridfs', 'memory', 'mongodb', 'redis', 'sqlite']
Let's take a look at the specific differences
| Backend | Class | Alias | Dependencies |
|---|---|---|---|
| SQLite | SQLiteCache | sqlite | |
| Say it again | RedisCache | say again | redis-py |
| MongoDB | MongoCache | mongodb | pymongo |
| GridFS | GridFSCache | gridfs | pymongo |
| DynamoDB | DynamoDbCache | dynamodb | boto3 |
| Filesystem | FileCache | filesystem | |
| Memory | BaseCache | memory |
If using redis
backend = requests_cache.RedisCache(host='localhost', port=6379)
requests_cache.install_cache('demo_redis_cache', backend=backend)
3. Cache only one request
# -*- coding:utf-8 -*-
# @Time : 2022-03-18
# @Author : carl_DJ
import time
import requests
import requests_cache
#allowable_methods 方式,只对post请求进行缓存
requests_cache.install_cache('demo_post_cache', allowable_methods=['POST'])
start = time.time()
session = requests.Session()
for i in range(10):
session.get('http://httpbin.org/delay/2')
print(f'Finished {i + 1} requests')
end = time.time()
print('Cost time for get', end - start)
start = time.time()
for i in range(10):
session.post('http://httpbin.org/delay/2')
print(f'Finished {i + 1} requests')
end = time.time()
print('Cost time for post', end - start)
operation result
Finished 1 requests
Finished 2 requests
Finished 3 requests
Finished 4 requests
Finished 5 requests
Finished 6 requests
Finished 7 requests
Finished 8 requests
Finished 9 requests
Finished 10 requests
Cost time for get 29.42441463470459
Finished 1 requests
Finished 2 requests
Finished 3 requests
Finished 4 requests
Finished 5 requests
Finished 6 requests
Finished 7 requests
Finished 8 requests
Finished 9 requests
Finished 10 requests
Cost time for post 2.611323595046997
Process finished with exit code 0
At this time, I saw that the GET request took more than 24 seconds to end because there was no cache, and the POST ended in more than 2 seconds because of the use of the cache.
2.3.3 Cache Headers method
In addition to our custom cache, requests-cache also supports parsing HTTP Request / Response Headers and caching based on the content of the Headers.
Code display
# -*- coding:utf-8 -*-
# @Time : 2022-03-18
# @Author : carl_DJ
import time
import requests
import requests_cache
requests_cache.install_cache('demo_headers_cache')
start = time.time()
session = requests.Session()
for i in range(10):
#Request Headers 里面加上了 Cache-Control 为 no-store
session.get('http://httpbin.org',
headers={
'Cache-Control': 'no-store'
})
print(f'Finished {i + 1} requests')
end = time.time()
print('Cost time for get', end - start)
start = time.time()
Add Cache-Control to no-store in Request Headers, even if we declare cache, it will not take effect.
3. Summary
Seeing this, today's sharing is almost here.
In practical applications, requests_cache is indeed a good method if crawling in a loop,
which saves time and improves efficiency.
The key is to use the saved time to take a bath.