Overview
Our database generally executes multiple transactions concurrently, and multiple transactions may concurrently add, delete, modify, and query the same batch of data, which may lead to what we call dirty writes, dirty reads, non-repeatable reads, and phantom reads. question. The essence of these problems is the multi-transaction concurrency problem of the database. In order to solve the multi-transaction concurrency problem, the database is designed 事务隔离机制、锁机制、MVCC多版本并发控制隔离机制with a set of mechanisms 解决多事务并发问题.
Transactions and their ACID properties
A transaction is a logical processing unit composed of a set of SQL statements. A transaction has the following four attributes, which are usually referred to as the ACID attribute of the transaction.
- Atomicity: A transaction is an atomic unit of operation in which all or none of the changes to data are performed.
- Consistent: Data must remain in a consistent state at both the start and completion of a transaction. This means that all relevant data rules must be applied to the modification of the transaction to maintain the integrity of the data.
- Isolation: The database system provides a certain isolation mechanism to ensure that transactions are executed in an independent environment that is not affected by external concurrent operations. This means that the intermediate state in the transaction process is invisible to the outside world, and vice versa.
- Durable: After the transaction is completed, its modifications to the data are permanent and can be maintained even in the event of a system failure.
Problems with concurrent transaction processing
Lost Update or Dirty Write
The lost update problem occurs when two or more transactions select the same row and then update that row based on the originally selected value, since each transaction is unaware of the existence of the other transaction – the last update overwrites the value created by the other transaction made updates .
Dirty Reads
A transaction is modifying a record. Before the transaction is completed and committed, the data of this record is in an inconsistent state; at this time, another transaction also reads the same record. If it is not controlled, the second Transactions that read this "dirty" data and do further processing based on it create uncommitted data dependencies. This phenomenon is vividly called " 脏读".
In one sentence:Transaction A reads data that transaction B has modified but not yet committed, and also do operations on this data basis. At this point, if transaction B rolls back, the data read by A is invalid and does not meet the consistency requirements.
Non-Repeatable Reads
At a certain time after a transaction reads some data, it reads the previously read data again, but finds that the data it has read has changed, or some records have been deleted! This phenomenon is called " 不可重复读".
In one sentence:The same query statement inside transaction A reads inconsistent results at different times, which does not conform to isolation。
Phantom Reads
A transaction re-reads previously retrieved data according to the same query conditions, but finds that other transactions have inserted new data that satisfies its query conditions. This phenomenon is called " 幻读".
Transaction isolation level
"Dirty reads", "non-repeatable reads", and "phantom reads" are all actually 数据库读一致性问题resolved by the database providing a certain transaction isolation mechanism.
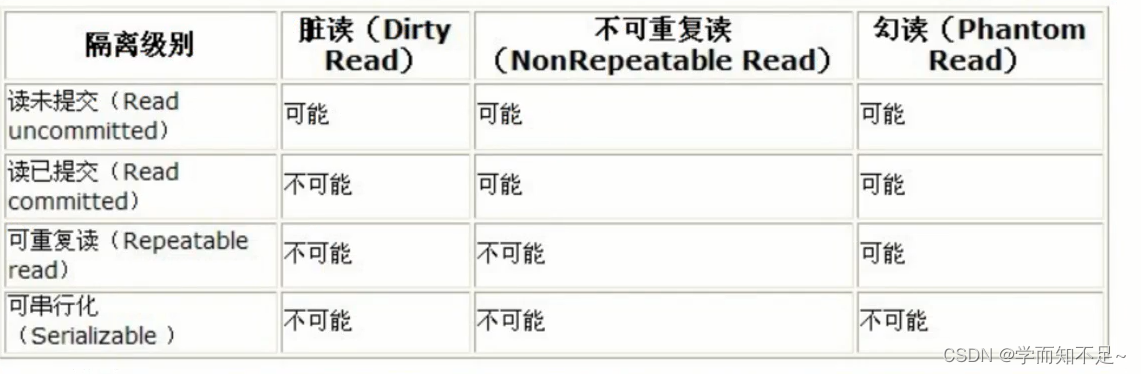
The stricter the transaction isolation of the database, the smaller the concurrent side effects, but the greater the cost, because transaction isolation is essentially to make the transaction "serialize" to a certain extent, which is obviously contradictory to "concurrency".
At the same time, different applications have different requirements for read consistency and transaction isolation. For example, many applications are not sensitive to "non-repeatable read" and "phantom read", and may be more concerned about the ability to concurrently access data.
-- 看当前数据库的事务隔离级别
show variables like 'tx_isolation'; -- mysql8.0之前的写法
show variables like 'transaction_isolation'; -- mysql8.0的写法
-- 设置事务隔离级别
set tx_isolation='REPEATABLE-READ';-- mysql8.0之前的写法
set transaction_isolation='REPEATABLE-READ';-- mysql8.0的写法
The default transaction isolation level of Mysql is repeatable read. When developing programs with Spring, if the isolation level is not set, the isolation level set by Mysql is used by default. If Spring is set, the isolation level that has been set is used.
lock mechanism
A lock is a mechanism by which a computer coordinates concurrent access to a resource by multiple processes or threads.
In the database, in addition to the contention of traditional computing resources (such as CPU, RAM, I/O, etc.), data is also a resource that needs to be shared by users.
How to ensure the consistency and validity of concurrent data access is a problem that all databases must solve, and lock conflict is also an important factor affecting the performance of concurrent database access.
lock classification
-
FromperformanceThe above is divided into:
乐观锁(implemented by version comparison) and悲观锁 -
FromTypes of operations on the databaseDivided into:
读锁and写锁(both are pessimistic locks)
读锁(共享锁,S锁(Shared)): for the same data, multiple read operations can be performed simultaneously without affecting each other
写锁(排它锁,X锁(eXclusive)): before the current write operation is completed, it will block other write locks and read locks and
read locks will block Writes, but does not block reads. The write lock blocks both reading and writing -
From the granularity of data operations, it is divided into: table locks and row locks
table lock
Each operation locks the entire table. Low overhead and fast locking; no deadlock; large locking granularity, the highest probability of lock conflict, and the lowest concurrency; generally used in the scenario of whole table data migration.
Basic operation
#建表SQL(MyISAM存储引擎)
CREATE TABLE `mylock` (
`id` INT (11) NOT NULL AUTO_INCREMENT,
`NAME` VARCHAR (20) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE = MyISAM DEFAULT CHARSET = utf8;
#插入数据
INSERT INTO `mylock` (`id`, `NAME`) VALUES ('1', 'a');
INSERT INTO `mylock` (`id`, `NAME`) VALUES ('2', 'b');
INSERT INTO `mylock` (`id`, `NAME`) VALUES ('3', 'c');
INSERT INTO `mylock` (`id`, `NAME`) VALUES ('4', 'd');
-- 手动增加表锁:
lock table 表名称 read(write), 表名称2 read(write);
-- 查看表上加过的锁:
show open tables;
-- 删除表锁:
unlock tables;
row lock
Each operation locks a row of data. High overhead and slow locking; deadlocks will occur; the locking granularity is the smallest, the probability of lock conflicts is the lowest, and the concurrency is the highest.
InnoDBMYISAMThere are two biggest differences with :
- Support transactions (TRANSACTION)
- Support row level lock
row lock demo
One session opens transaction updates without committing, another session will block updating the same record, and updating different records will not block
Summarize
Before executing the query statement SELECT, MyISAM will automatically add read locks to all the tables involved, and will automatically add write locks to the involved tables when executing update, insert, and delete operations.
When InnoDB executes the SELECT query statement, it will not lock because of the mvcc mechanism, but the update, insert, and delete operations will add row locks
In short, it is 读锁会阻塞写,但是不会阻塞读。而写机制会把读和写都阻塞.
Row lock and isolation level case analysis
CREATE TABLE `account` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(255) DEFAULT NULL,
`balance` int(11) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
INSERT INTO `account` (`name`, `balance`) VALUES ('lilei', '450');
INSERT INTO `account` (`name`, `balance`) VALUES ('hanmei','16000');
INSERT INTO `account` (`name`, `balance`) VALUES ('lucy', '2400');
read uncommitted
1. Open a client A and set the current transaction isolation level to read uncommitted (read uncommitted)
set tx_isolation='read-uncommitted';
set transaction_isolation = 'read-uncommitted'; -- mysql8.0
Query the initial value of the table account:
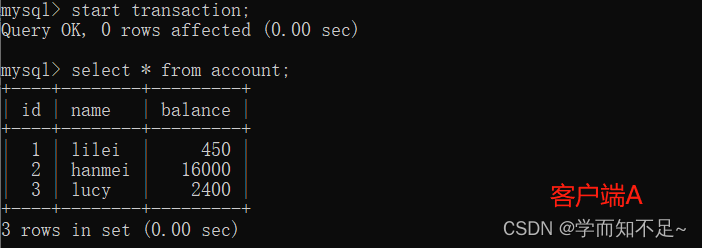
2. Before the transaction of client A is committed, open another client B and update the table account
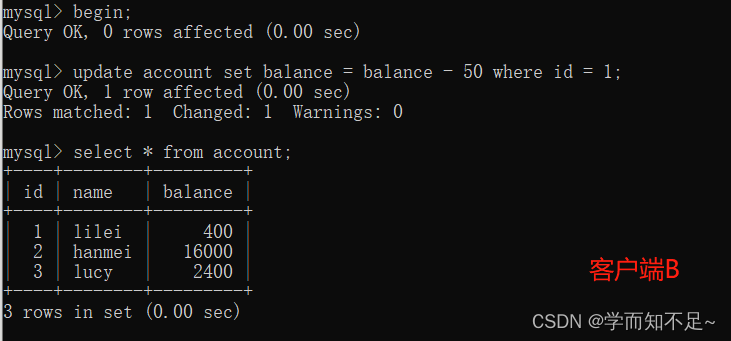
3. At this time, although the transaction of client B has not been committed, client A can query To the data that has been updated by B
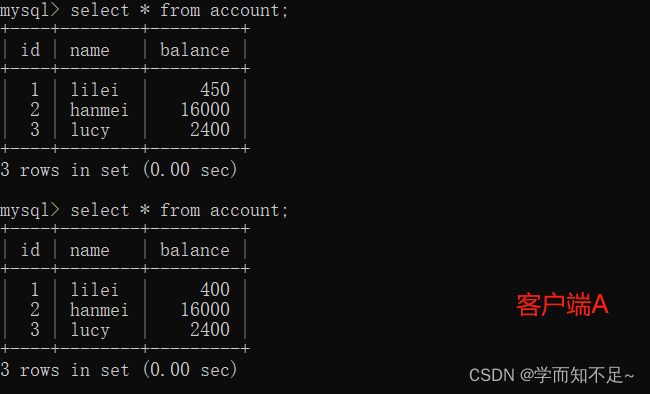
4. Once the transaction of client B is rolled back for some reason, all operations will be undone, and the data queried by client A is actually dirty data
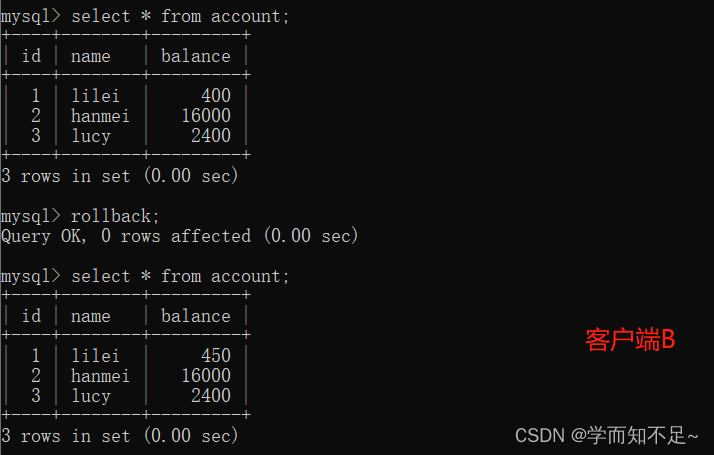
5. Execute the update statement on client A update account set balance = balance - 50 where id = 1;
lilei's balance did not become 350, but 400. Isn't it strange that the data is inconsistent ?如果你这样想就太天真了,在应用程序中,我们会用400-50 = 350,并不知道其他会话回滚了,要想解决这个问题可以采用读已提交的隔离机制
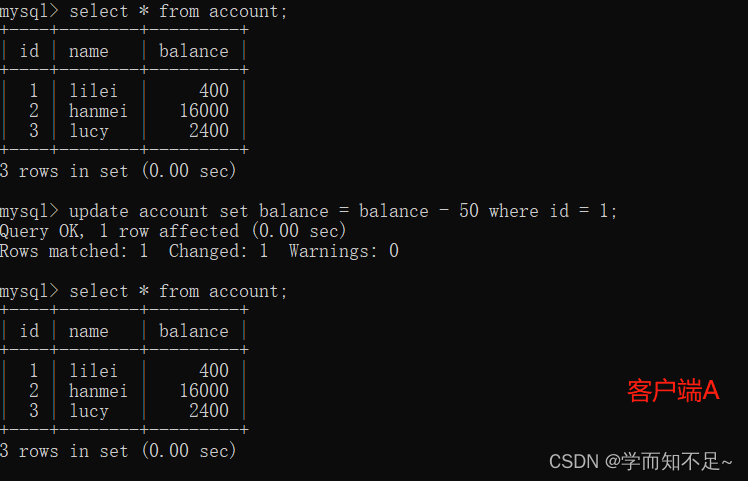
read committed
1. Open a client A, set the current transaction isolation level to read committed (uncommitted read), and query all records in the table account
set transaction_isolation = 'read-committed'; -- mysql8.0

2. Before the transaction of client A is committed, open another client B and update the table account
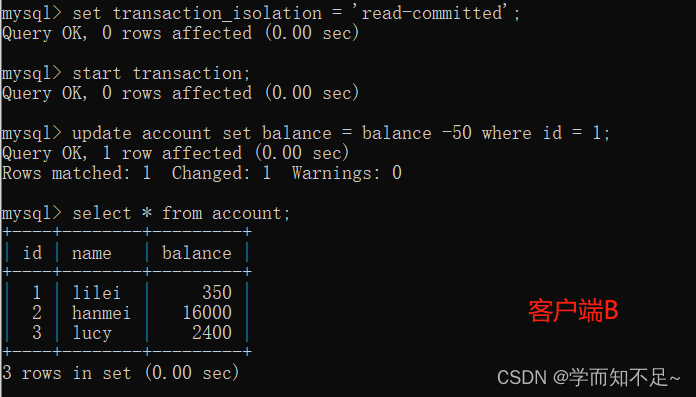
3. At this time, the transaction of client B has not been committed, and client A cannot query the data that has been updated by B. 解决了脏读问题
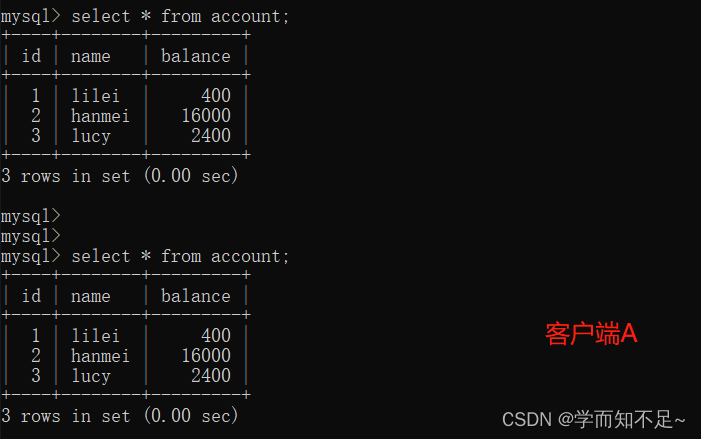
4. The client The transaction of terminal B is submitted
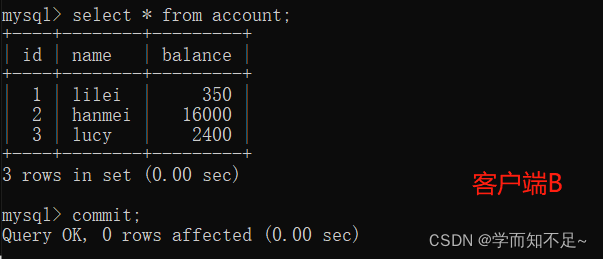
5. Client A executes the same query as the previous step, and the result is inconsistent with the previous step, that is, a non-repeatable read problem occurs
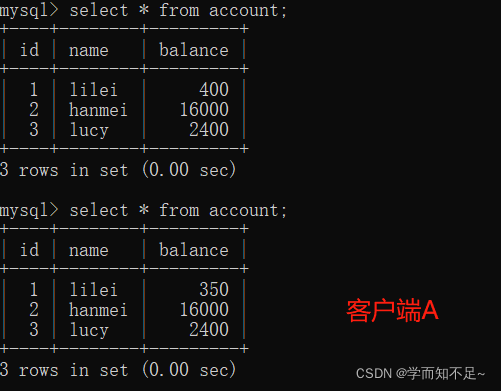
repeatable read
1. Open a client A, set the current transaction mode to repeatable read, and query all records in the table account
set transaction_isolation = 'repeatable-read';
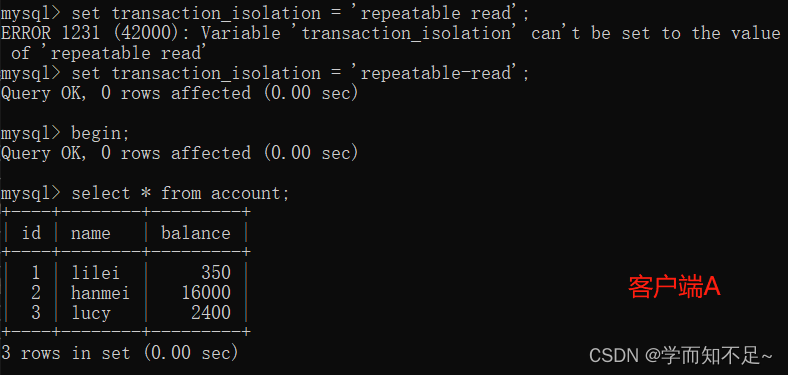
2. Before the transaction of client A is committed, open another client B, update the table account and submit it
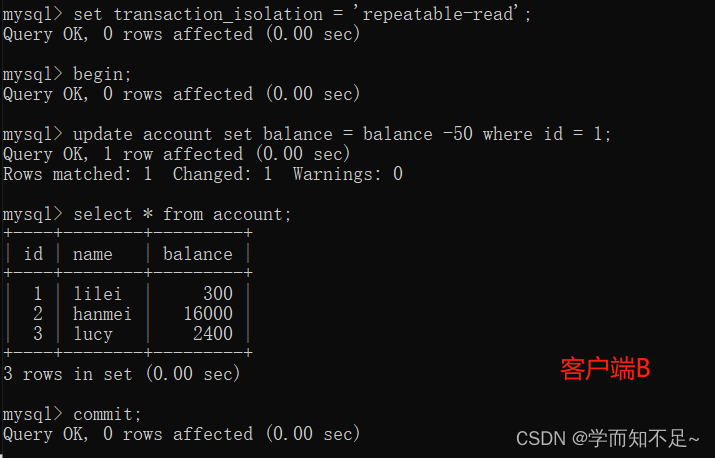
3. Query all records in the table account on client A, the query result is consistent with step 1. There is no non-repeatable read Question
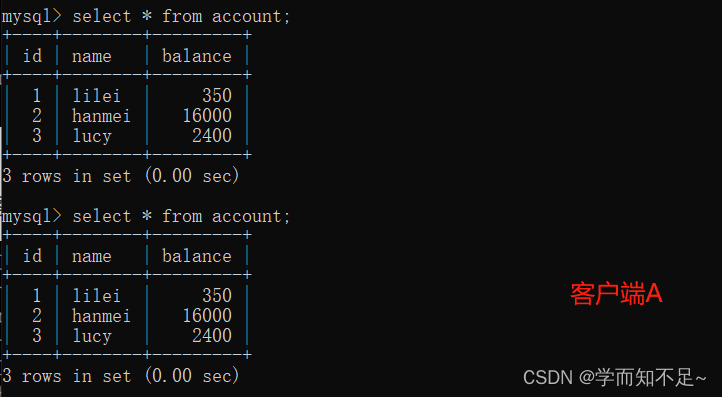
4. On client A, execute update account set balance = balance - 50 where id = 1;
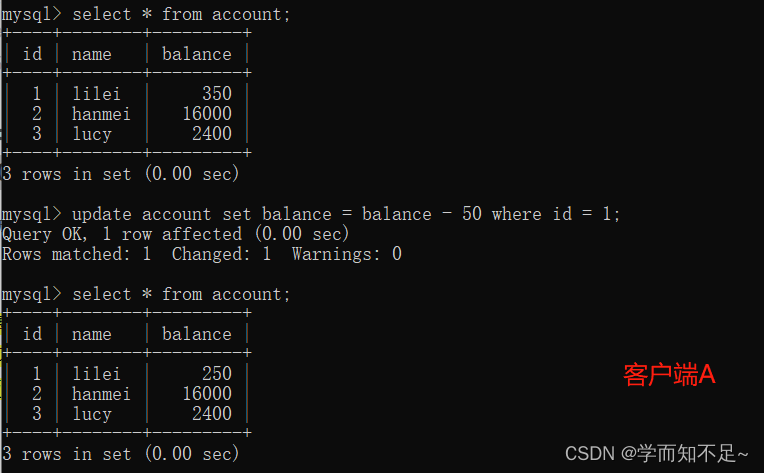
balance does not become 350-50 = 300, the balance value of lilei is calculated using 300 in step 2, so It is 250, and the consistency of the data is not destroyed.
The MVCC (multi-version concurrency control) mechanism is used under the repeatable read isolation level. The select operation will not update the version number, but is a snapshot read (historical version); insert, update, and delete will update the version number, which is the current read (current version). )
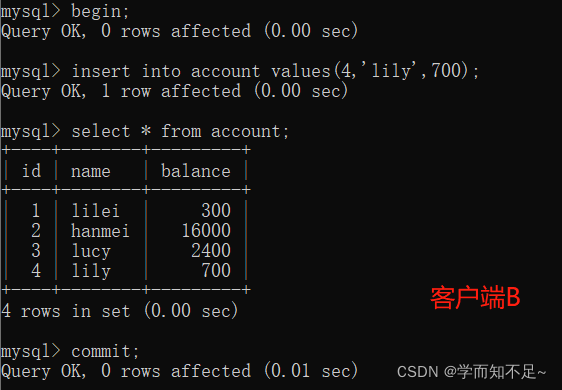
5. Re-open client B, insert a new piece of data and submit it
. 6. Query all records in the account table on client A, and no new data is found, so no phantom reading occurs
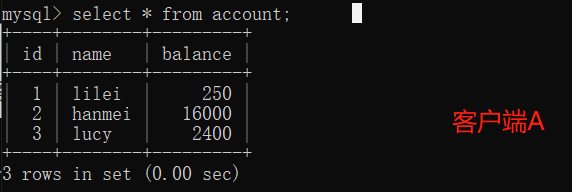
. 7. Verify phantom reading
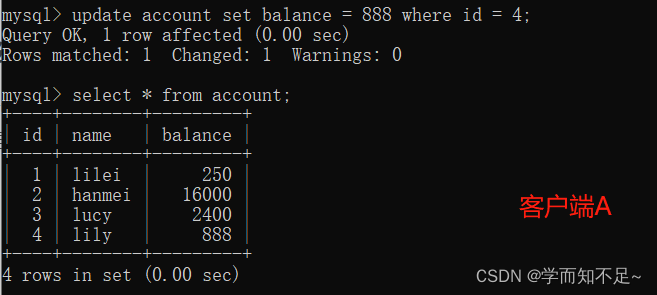
and execute update account on client A. set balance = 888 where id = 4;
can be updated successfully, and the new data of client B can be found by querying again
serialize
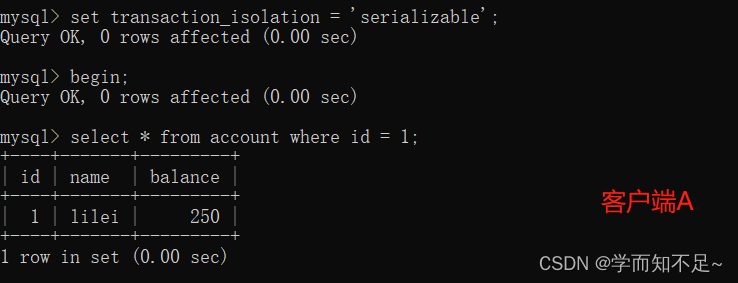
1. Open a client A, set the current transaction mode to serializable, and query the initial value of the table account
set transaction_isolation = 'serializable';
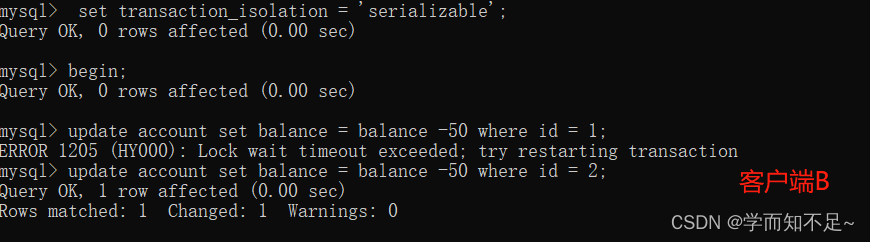
2. Open a client B and set the current transaction mode to serializable. Updating the same record with id 1 will be blocked and waiting, and updating the record with id 2 can be successful, indicating that InnoDB queries in serial mode will also be blocked. Plus row lock
If client A executes a range query, then all rows in the range include the gap interval range where each row of records is located (even if the row data has not been inserted, it will be locked, which is the gap lock) . is locked .
At this time, if client B inserts data in this range, it will be blocked, so phantom reading is avoided.
这种隔离级别并发度极低,开发中很少会用到
Gap Lock
A gap lock locks the gap between two values. The default level of Mysql is repeatable-read. Is there a way to solve the phantom read problem? Gap locks can solve phantom reads in some cases.
Adjust the isolation level to the default isolation level of mysql, and the account has the following data:

then the gap has ids (3,10), (10,20), (20, positive infinity) These three intervals
are executed under client A update account set name = 'zhuge' where id > 8 and id < 18;
then other clients cannot insert or modify any data in all the row records included in this range and the gap between row records , that is, the id is in (3 ,20] interval cannot modify the data, note that the last 20 is also included
间隙锁是在可重复读隔离级别下才会生效.
Next-key Locks
Next-key Locks are a combination of row locks and gap locks. The whole interval of (3,20] in the above example can be called a key lock
Indexless row locks are upgraded to table locks
The lock is mainly added to the index. If the non-index field is updated, the row lock may become a table lock.
- Client A executes: update account set balance = 800 where name = 'lilei';
- Client B will block any row of the table.
InnoDB row locks are locks for indexes, not locks for records. And the index cannot be invalidated, otherwise it will be upgraded from row lock to table lock.
in conclusion
Because the InnoDB storage engine implements row-level locking, although the performance consumption of the locking mechanism may be higher than that of table-level locking, it is far superior to MyISAM's table-level locking in terms of overall concurrent processing capability. .
When the system concurrency is high, the overall performance of InnoDB will have obvious advantages compared with MyISAM.
However, InnoDB's row-level locking also has its fragile side. When we use it improperly, the overall performance of InnoDB may not be higher than that of MyISAM, but may even be worse.
row lock analysis
Analyze row lock contention on your system by examining the InnoDB_row_lock status variable
show status like 'innodb_row_lock%';
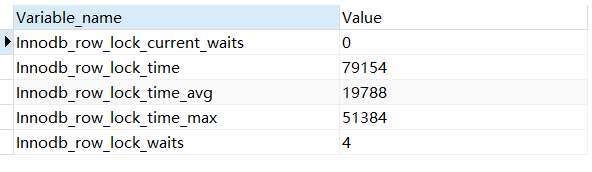
The description of each state quantity is as follows:
Innodb_row_lock_current_waits: The number of currently waiting locks
Innodb_row_lock_time: The total length of time from the system startup to the moment when the lock is locked
Innodb_row_lock_time_avg: The average time spent on each waiting
Innodb_row_lock_time_max: The longest waiting time from the system startup to the present
Innodb_row_lock_waits: System startup Total wait times since then
For these five state variables, the more important ones are:
Innodb_row_lock_time_avg(average waiting time)
Innodb_row_lock_waits(total wait times)
Innodb_row_lock_time(Total waiting time)
Especially when the number of waiting times is high, and each waiting time is not small, we need to analyze why there are so many waiting in the system, and then start to formulate an optimization plan based on the analysis results.
View INFORMATION_SCHEMA system library lock related data sheet
--查看事务
select * from INFORMATION_SCHEMA.INNODB_TRX;
-- innodb_locks表在8.0.13版本中由performance_schema.data_locks表所代替
--查看锁
select * from INFORMATION_SCHEMA.INNODB_LOCKS;
--查看锁等待
--innodb_lock_waits表则由performance_schema.data_lock_waits表代替。
select * from INFORMATION_SCHEMA.INNODB_LOCK_WAITS;
--释放锁trx_mysql_thread_id可以从INNODB_TRX表里查看到
kill trx_mysql_thread_id;
--查看锁等待详细信息 mysql8.0去掉\G
show engine innodb status\G;
deadlock
Client A executes: select * from account where id=1 for update;
client B executes: select * from account where id=2 for update;
client A executes: select * from account where id=2 for update;
client B executes: select * from account where id=1 for update;
View recent deadlock log information: show engine innodb status; in most cases mysql can automatically detect deadlock and roll back the transaction that caused the deadlock, but in some cases mysql cannot automatically detect deadlock
Lock Optimization Recommendations
- As far as possible, all data retrieval is done through the index to avoid the escalation of non-index row locks to table locks
- Reasonably design indexes to minimize the scope of locks
- Minimize the range of retrieval conditions as much as possible to avoid gap locks
- Try to control the size of the transaction, reduce the amount of locking resources and the length of time, and try to execute the SQL involving transaction locking at the end of the transaction.
- Low-level transaction isolation as possible