Click on "Uncle Wheat" above and select "Top/Star Public Account"
Welfare dry goods, delivered as soon as possible
Hello everyone, my name is Wheat, and today I recommend a method of communication protocol analysis.
A while ago, when a friend used a microcontroller to communicate with a peripheral, the peripheral returned a bunch of data in the following format:
AA AA 04 80 02 00 02 7B AA AA 04 80 02 00 08 75 AA AA 04 80 02 00 9B E2 AA AA 04 80 02 00 F6 87 AA AA 04 80 02 00 EC 91
Among them, AA AA 04 80 02 is the data check header, and the last three digits are valid data. Ask me how to get valid data from the data continuously returned by the peripheral.
The easiest thing to think of for this kind of problem is to use a flag bit to mark the digit of a frame of data that is currently being parsed, and then determine whether the currently received data is consistent with the check data, and if it is consistent, add one to the flag bit, Otherwise, the flag position 0 will be re-judged. The code for parsing the data using this method is as follows:
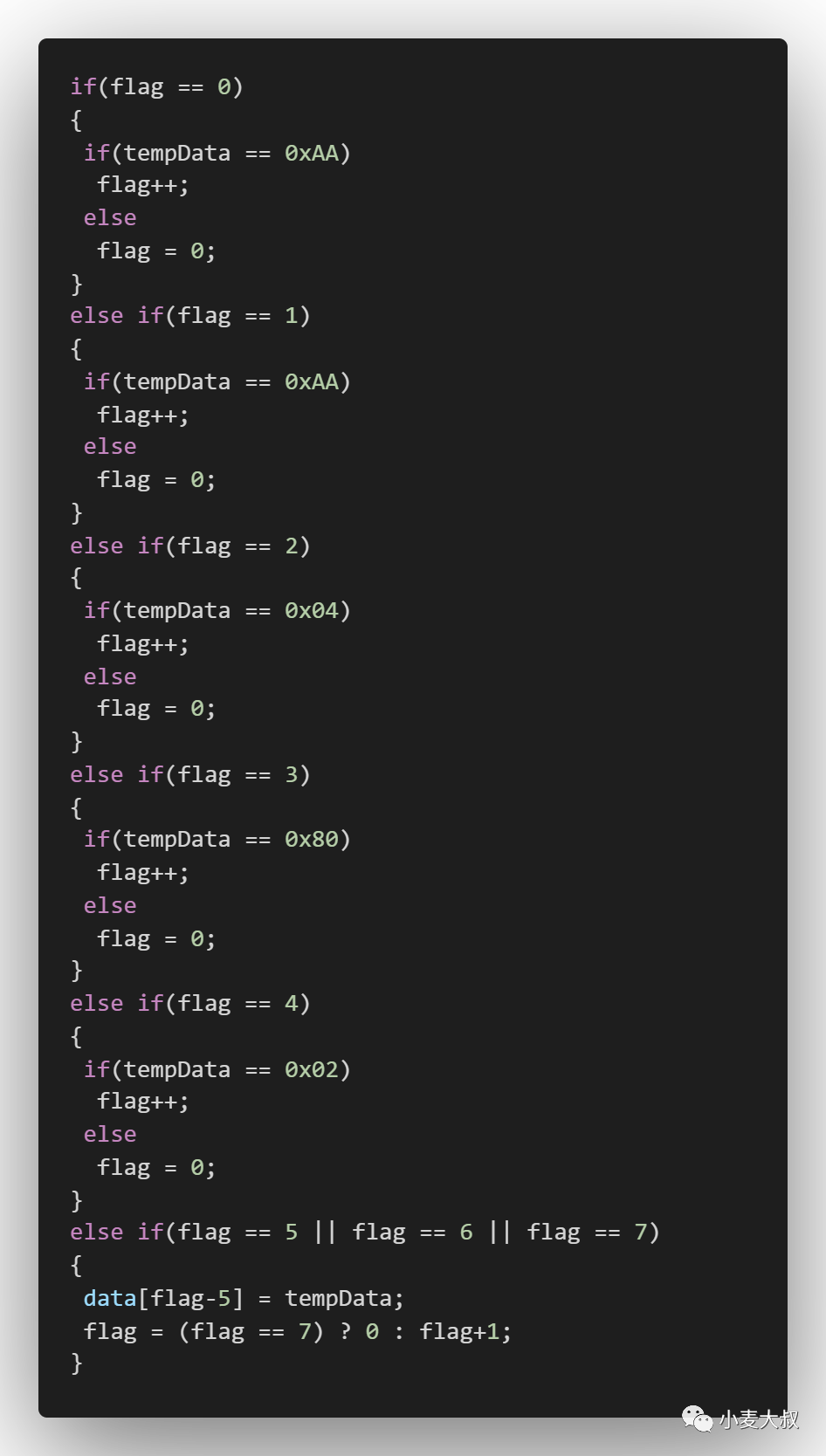
Using the above method is the easiest and easiest method to think of. Baidu basically uses a similar method for data analysis, but using this method has the following disadvantages:
1. Extensive use of judgment can easily lead to logical confusion.
2. The code repetition rate is high and the degree of abstraction is low. From the above code, you can see that a lot of codes are only different in the judged data, and the other codes are completely the same.
3. Poor code reusability. The written code cannot be used on other similar peripherals. If there are multiple peripherals, multiple copies of similar code need to be written.
4. Low scalability. If the peripheral still has a data check tail that needs to be checked or the data check header is changed, multiple judgments need to be written again to be used for checking again, which cannot be extended on the original code.
5. Misjudgment is prone to occur.
In this regard, a new solution is proposed here, which can be used for all similar data analysis. The principle is as follows:
A fixed-capacity queue is used to buffer the received data. The queue capacity is equal to the size of one frame of data. Each time a data comes, the data is added to the queue. When a frame of data is completely received, all the data in the queue is at this time. That is, a complete frame of data, so it is only necessary to determine whether the queue is the data check header and whether the queue tail is the data check tail to know whether a complete frame of data has been received, and then the data is removed from the queue. Just take it out. The schematic diagram is as follows:
Each time a piece of data comes, add it to the queue:
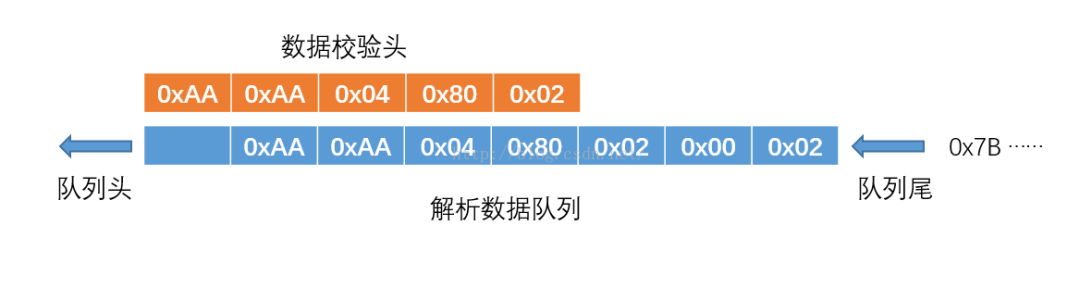
When a complete frame of data is received, the queue header and the data check header coincide:

At this point, only valid data needs to be taken out of the queue.
If there is a data tail check, just add a check tail, as shown in the following figure:

OK, analysis is over, let's start coding.
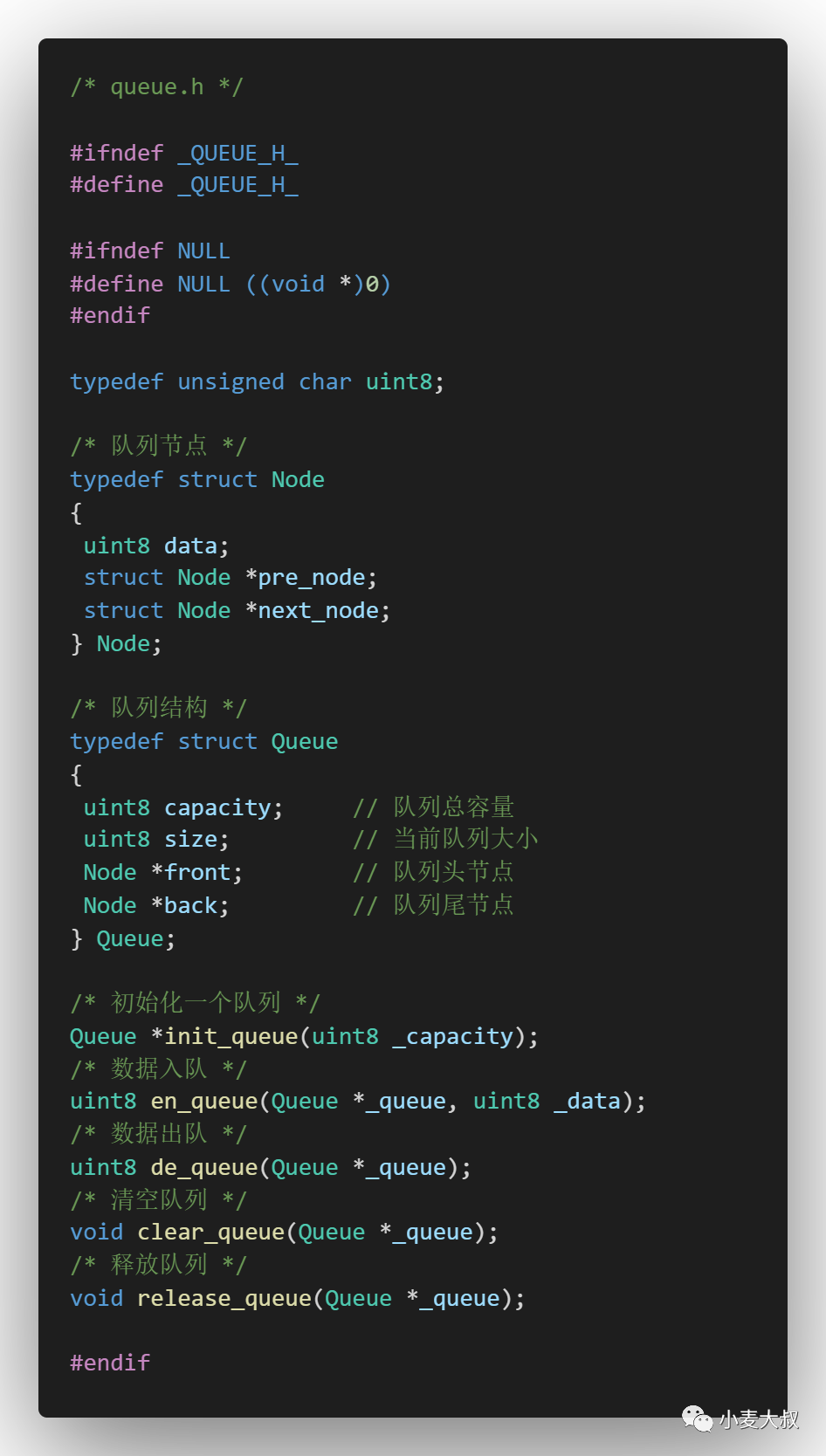
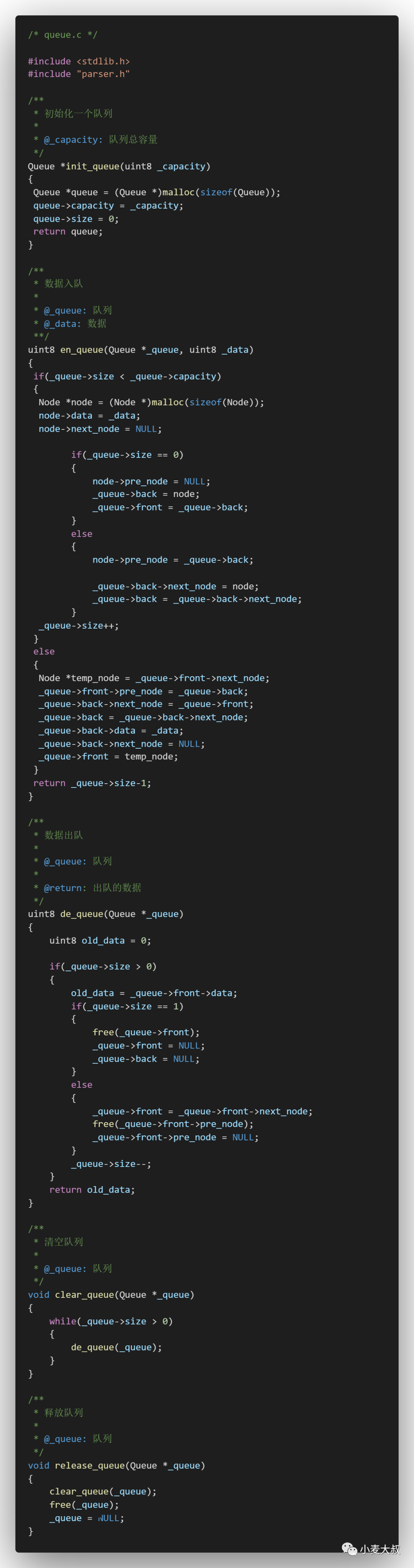
First of all, a queue is needed. In order to ensure universality, the bottom layer of the queue uses an implementation similar to a doubly linked list (of course, it can also be implemented using an array). The structures that need to be encapsulated include queue capacity, queue size, queue head node and queue tail node, which need to be implemented. The operations include queue initialization, data entry, data dequeue, clearing the queue and releasing the queue. The specific codes are as follows:
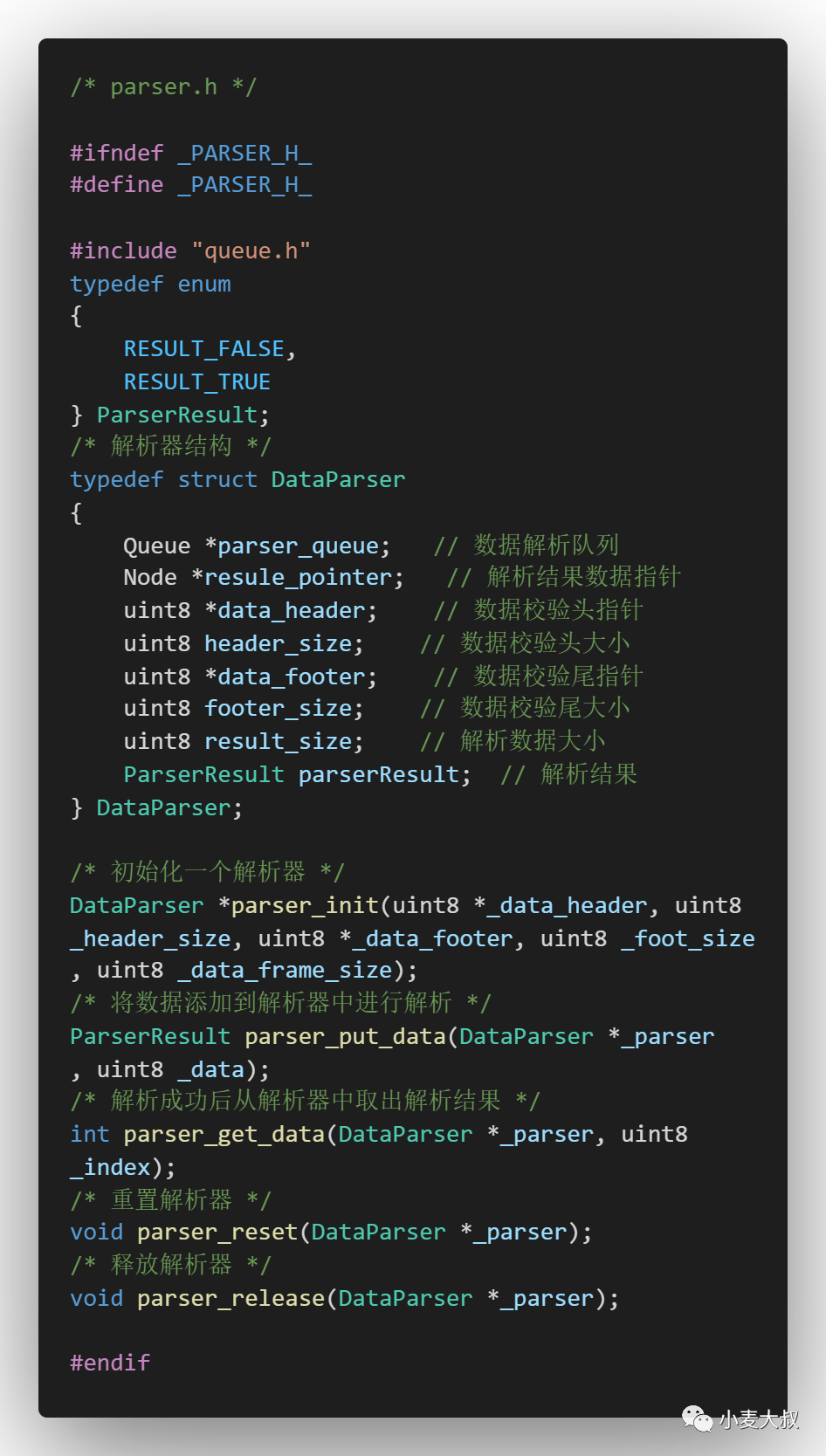
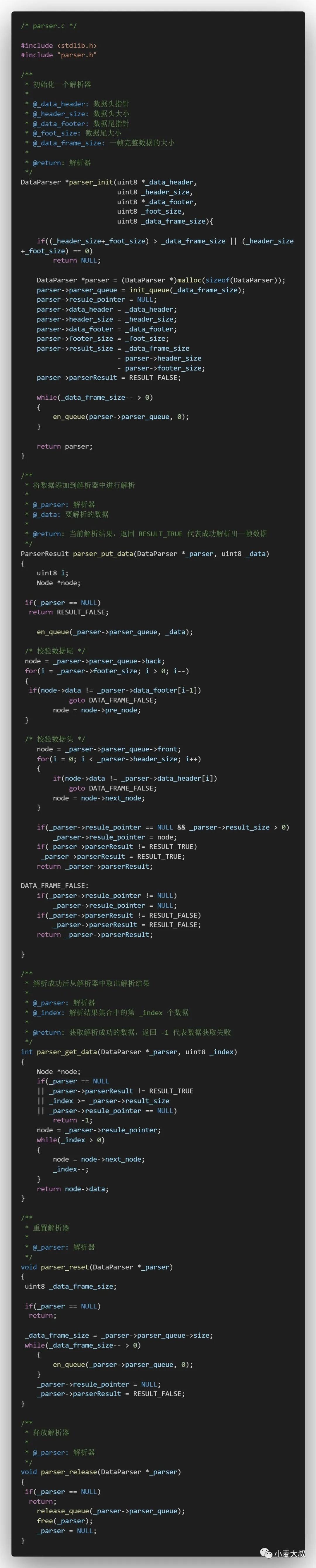
The second is the parser. The structures that need to be encapsulated include the parsing data queue, the data verification header, the data verification tail, the parsing result, and a pointer to the parsing result. The operations that need to be implemented include parser initialization, adding data parsing, obtaining parsing results, Reset the parser and release the parser, the specific code is as follows:
Next, write the test code to test it:

The test results are as follows:
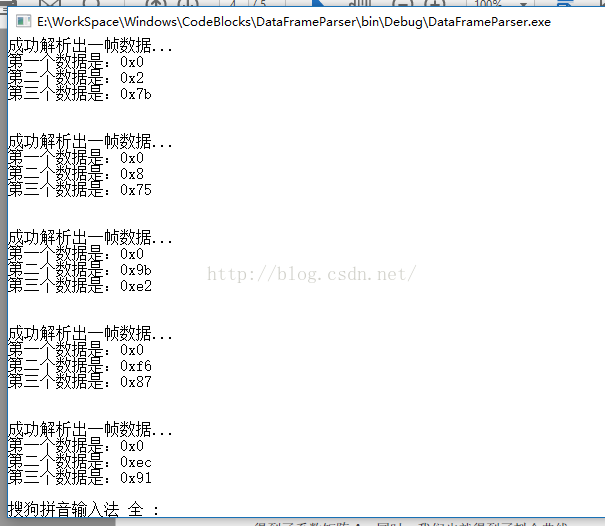
As can be seen from the above, the results of the analysis are consistent with the target.
github address:
https://github.com/528787067/DataFrameParser
Original address: https://blog.csdn.net/XR528787067/article/details/52822377
Transferred from the public number: embedded hodgepodge
Copyright statement: This article comes from the Internet, and the copyright belongs to the original author. Copyright issues, please contact to delete.
—— The End ——
Recommended in the past
The most suitable communication protocol for single-chip microcomputer, how to design?
46 million units sold! The Road to Raspberry Pi
Good tool, don't hide it! Introduce a tool to improve efficiency
This c language skill refreshed my understanding of structures!
You can never imagine that C language can play like this!
Good project, don't keep it private! Open source wheels for microcontroller development
Everything you ordered looks good , I take it seriously as I like it