Click the card below to follow the " CVer " public account
AI/CV heavy dry goods, delivered as soon as possible
01
research problem
With the continuous development of the computer vision field, the basic vision task research is inspired by the Transformer-based model of natural language processing (NLP), the vision task is combined with the Transformer network model structure, and the self-attention mechanism is introduced. and other structures to explore and optimize the application of Transformer network in vision tasks, and obtain more competitive advantages in multiple vision tasks such as target detection, segmentation and tracking. At the same time, in the research of basic vision tasks, the introduction of interpretability analysis can form a deeper understanding of existing models from multiple perspectives, which can prompt researchers to further explore the effective modeling process.
However, the existing related work on Vision Transformer still has three problems:
Models lack interpretability. Existing methods (eg, ViT) are inspired by work in the field of natural language processing and only focus on how to combine vision tasks with Transformer networks, but ignore the interpretability issues in model computation.
Interactions between redundant Patches . The self-attention mechanism builds the attention relationship through the long-range relationship between patch-wise, forming redundant computational cost.
Heuristic manual preset Patch interaction area . Current related work uses the heuristic setting of prior information to limit the patch interaction range (Window-based, Range-based and Region-based). The patch-wise interaction in visual tasks should be related to image semantics, but the semantic information contained in the patch is not considered in the patch interaction; at the same time, the existing technology lacks the consideration of the adaptive region design problem, and mostly uses empirical parameters as the window Restrictions.
In response to the above three problems, this recent source arxiv article proposes Visualizing and Understanding Patch Interactions in Vision Transformer for the ViT model.

Paper: https://arxiv.org/abs/2203.05922
02
method
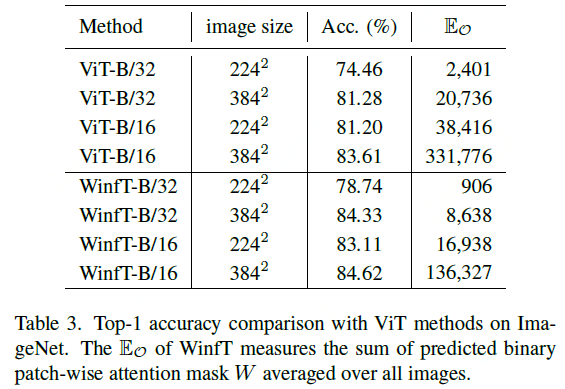
For the ViT model, the author first quantifies the interaction between patches by visual observation and numerical analysis of patch-wise attention. Then, the interactive quantification between patches is used to convert the patch interactive relationship, including centain connections and indiscriminative connections. At the same time, the responsive field of the current patch is calculated based on the interaction between patches. Finally, use the responsive field of the current patch as the patch interactive area (Window). In addition, a Window-free Transformer (WinfT) model is designed through the analysis of the obtained Window area as a supervision signal, and the validity of the conclusions of visual analysis and understanding is further verified through experiments (Table.3). Based on the experimental verification results of WinfT, it is interesting to find that when the patch size is 16X16 and 32X32, the results of the adaptive window region-limited patch interaction classification task are almost the same (84.33% vs 84.62%). The results of visual analysis and experimental verification are instructive for future Transformer-based model design.
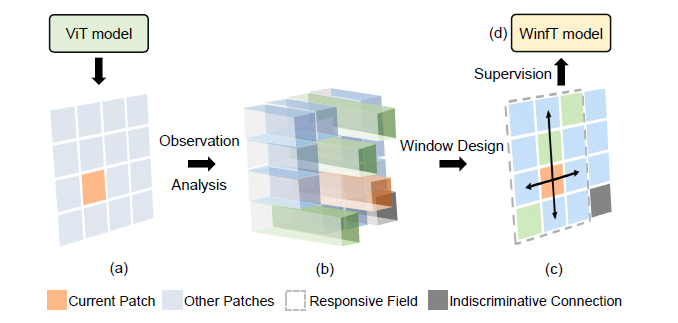
Method flow diagram
Differences in Patch Interactions?
The author randomly selects different patch combinations (inner-object and outer-object) to quantify the interaction between different patches. Experiments show that patches with different semantic information have great differences in the interaction process.
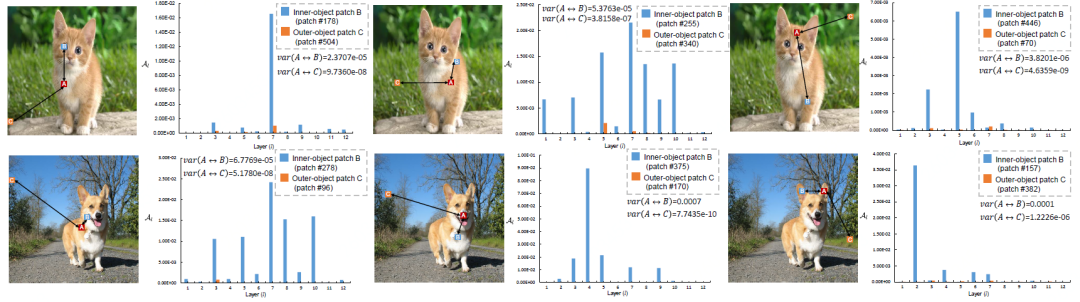
Quantitative analysis of inner-object patch and outer-object patch.
Through such a difference phenomenon, the author further characterizes the relationship of patch interaction from the perspective of uncertainty analysis:
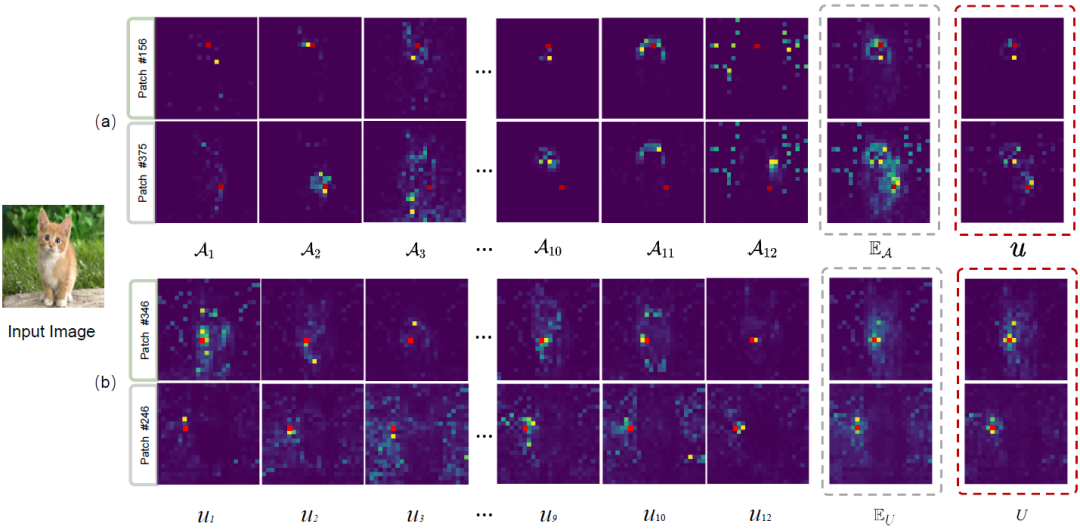
What can quantifying patch interactions do?
1) Adaptive attention window design
The author first quantifies the uncertainty relationship of patch interaction, and selects the interaction relationship by threshold as the patch connection with strong reliability. Then, using the filtered interaction connection relationship, the extreme values in the four directions between the current patch and the patch with stronger interaction reliability are calculated, and finally converted into the interaction window area of the current patch.
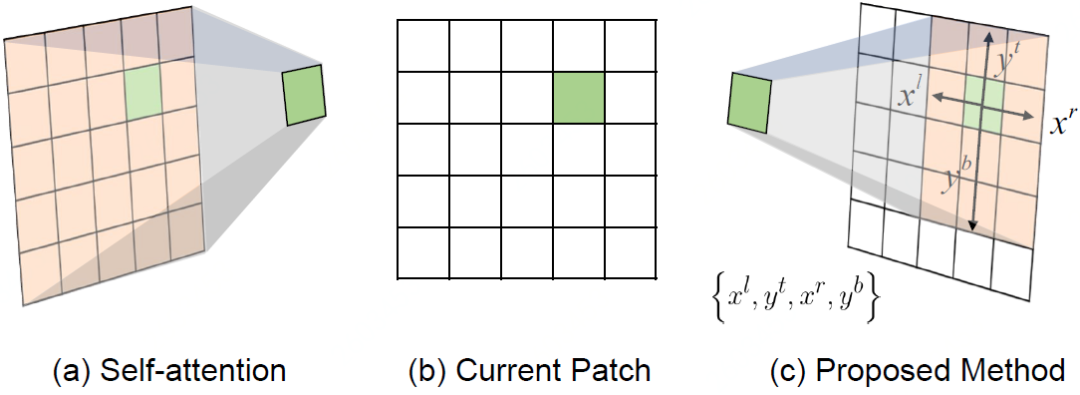
Adaptive Window Design
2) Indiscriminative patch
In designing the adaptive window, the author found that there are some patches that interact with almost all the patches. After numerical analysis, it is found that most of such patches exist in the background. In addition, the corresponding experimental verification is provided to remove the connection between the Indiscriminative patches, which can further improve the performance in the classification task.
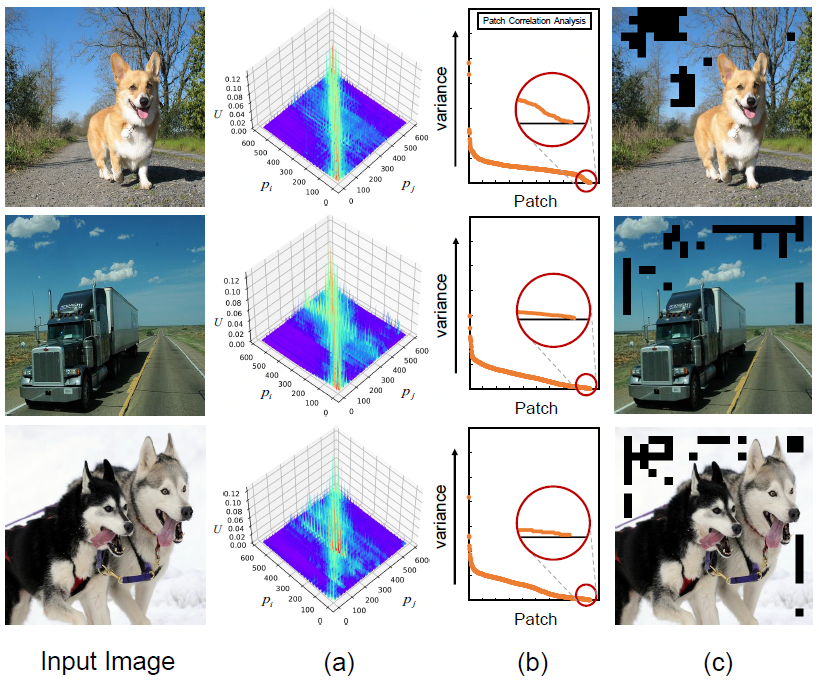
Analyze Indiscriminative patches
The authors also provide different thresholds to visualize the Indiscriminative patch:

Different thresholds to remove the number of Indiscriminative patches
3) Responsive field analysis
The effectiveness of the adaptive window design is proved through the first two parts. The author analyzes the interaction trend of the responsive field formed by the interactive window and the size of the interactive window by combining optical flow and window interaction trends.
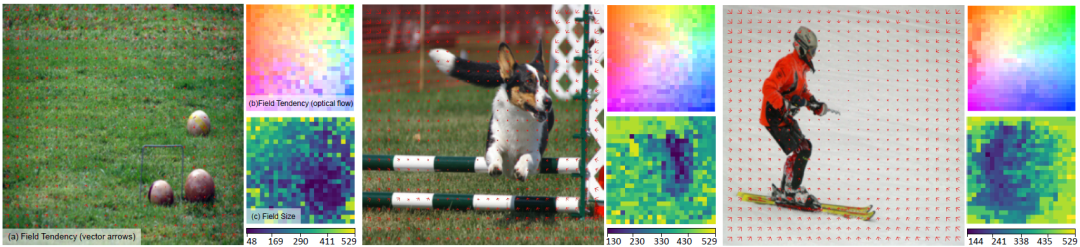
Responsive field analysis例子
The calculation process of trend analysis is as follows:
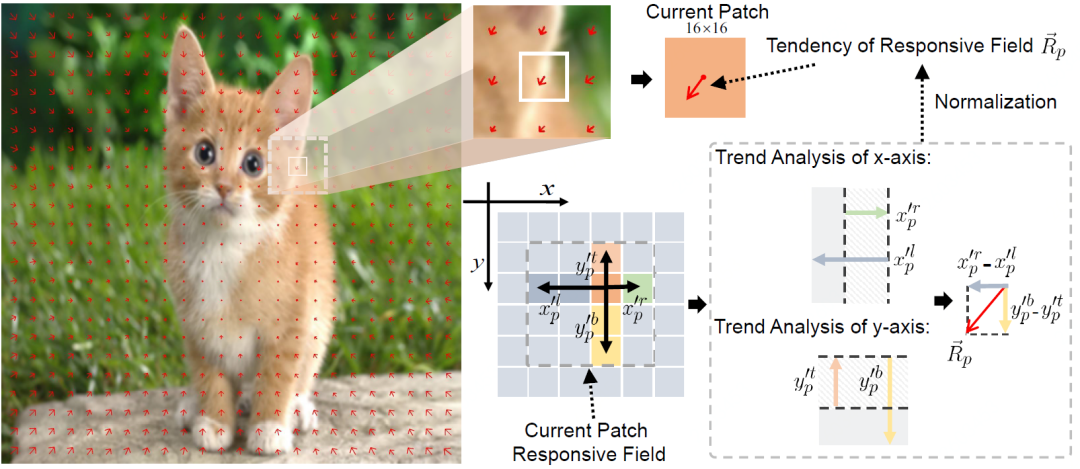
Schematic diagram of analyzing the tendency of the Responsive field
Window-free Transformer (WinfT)
Patch-based interaction analysis provides a new complementary perspective for understanding the Vision Transformer model. Based on visual observation and analysis, the author proposes a Window-free Transformer structure. By introducing a patch-wise responsive field as an interactive window during training to guide the supervised model training, it is significantly improved compared to ViT.

Schematic diagram of WIndow-free Multihead Attention
The WinfT experiment verifies the effectiveness of its method in the ImageNet classification task and the Fine-grained task (CUB), and the experimental results further prove that the visual analysis and the analytical understanding of the ViT model are effective.
ICCV和CVPR 2021论文和代码下载
后台回复:CVPR2021,即可下载CVPR 2021论文和代码开源的论文合集
后台回复:ICCV2021,即可下载ICCV 2021论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的3篇Transformer综述PDF
CVer-Transformer交流群成立
扫码添加CVer助手,可申请加入CVer-Transformer 微信交流群,方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲长按加小助手微信,进交流群
CVer学术交流群(知识星球)来了!想要了解最新最快最好的CV/DL/ML论文速递、优质开源项目、学习教程和实战训练等资料,欢迎扫描下方二维码,加入CVer学术交流群,已汇集数千人!
▲扫码进群
▲点击上方卡片,关注CVer公众号
整理不易,请点赞和在看