网页主页:https://minitorch.github.io/index.html
github项目地址:https://github.com/minitorch
是2020年cornell大学的一门课程,
这是一个大学课程的课后作业项目,一共就:
- Setup(安装环境)
- ML Primer ( 机器学习基础知识复习)
- Fundamentals
- Autodiff
- Tensors
- Efficiency
- Networks
其中,除了第二部分之外,其他部分在github上都有Public template,每次进行对应module的任务时,都需要先git clone对应的module模块,完成相应的任务
2. 任务要求
- 要求从这个repo中进行clone,https://github.com/shaiic
- 作业提交:https://github.com/shaiic/mini-ai-lab
- 任务提交说明:https://wiki.shaiic.com/pages/viewpage.action?pageId=27688971
1. Setup(环境安装)
网页说明:https://minitorch.github.io/install.html
github项目地址:https://github.com/minitorch/Module-0
个人安装记录:
要求是python3.7以上的版本,本机有conda环境,所以直接用conda创建一个新环境好了
# 创建一个名叫 minitorch的新环境
conda create -n minitorch python=3.7
# 切换到刚刚新创建的这个环境里去
conda activate minitorch
# 安装额外需要的一个包
conda install llvmlite
然后根据官网的提示,需要把对应的Module 0的github项目,是一个public template,可以直接use this template,借用这个项目的模板去生成自己的内容。
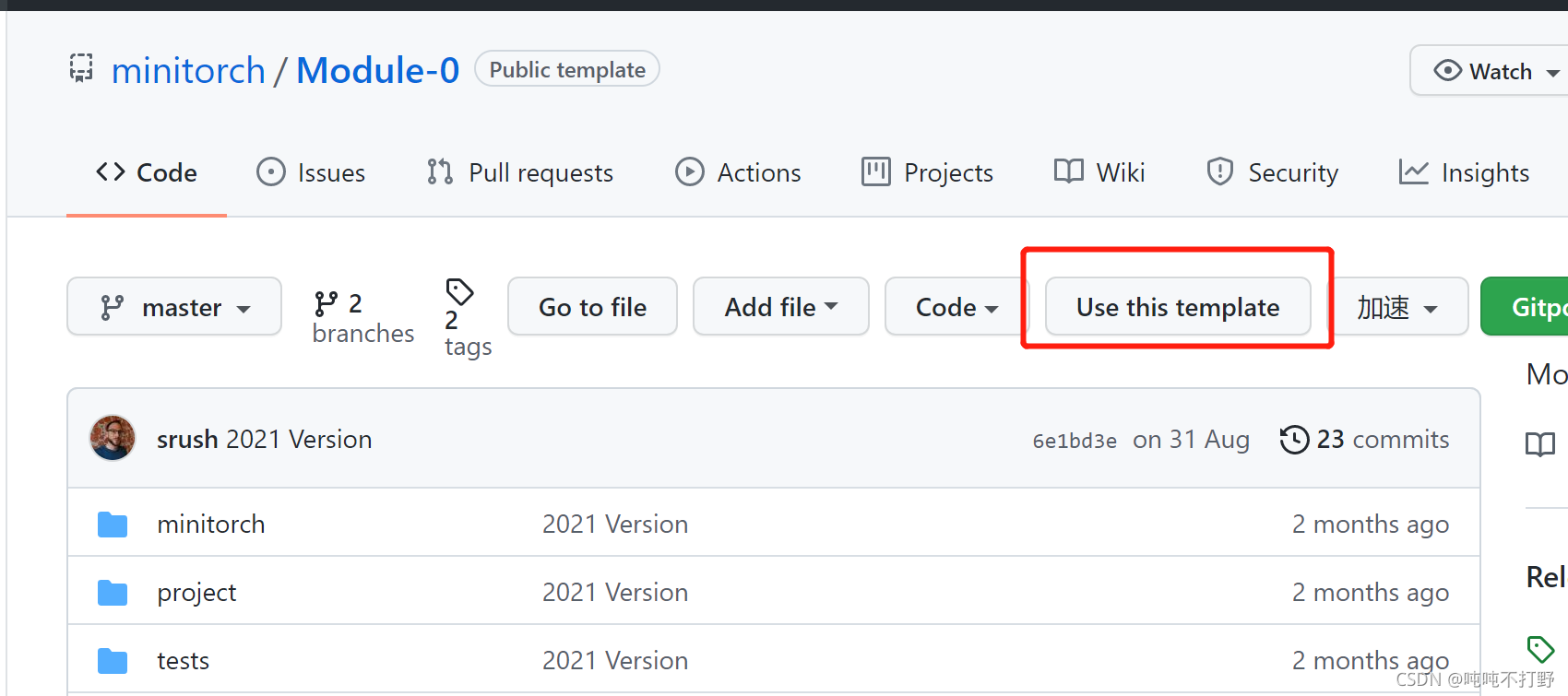
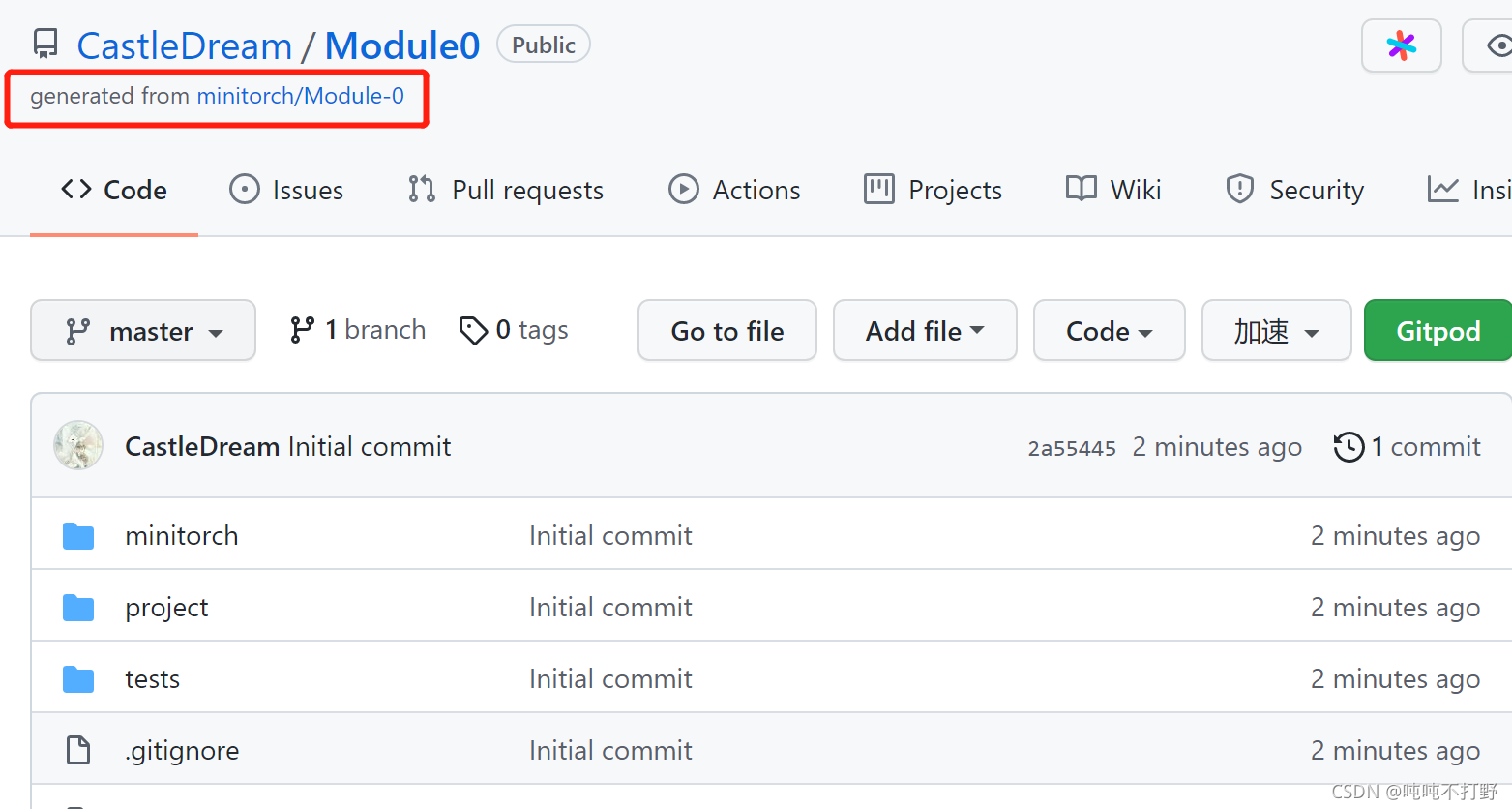
然后自己找个目录,新建一个minitorch,以后这个项目都丢到这里,进入这个文件夹,然后打开git的bash,把自己账号下生成的这个module0项目git clone一下就好了,例如,我使用的就是:
git clone https://github.com/CastleDream/Module0.git
# 然后安装requirement的东西
# 记得切换conda环境,还有github这个项目的文件夹
python -m pip install -r requirements.txt
python -m pip install -r requirements.extra.txt
python -m pip install -Ue .

这里需要注意,这个minitorch包是基于github的这个repo的,所以如果删除了这个repo,这个包就找不到了,不要乱删。
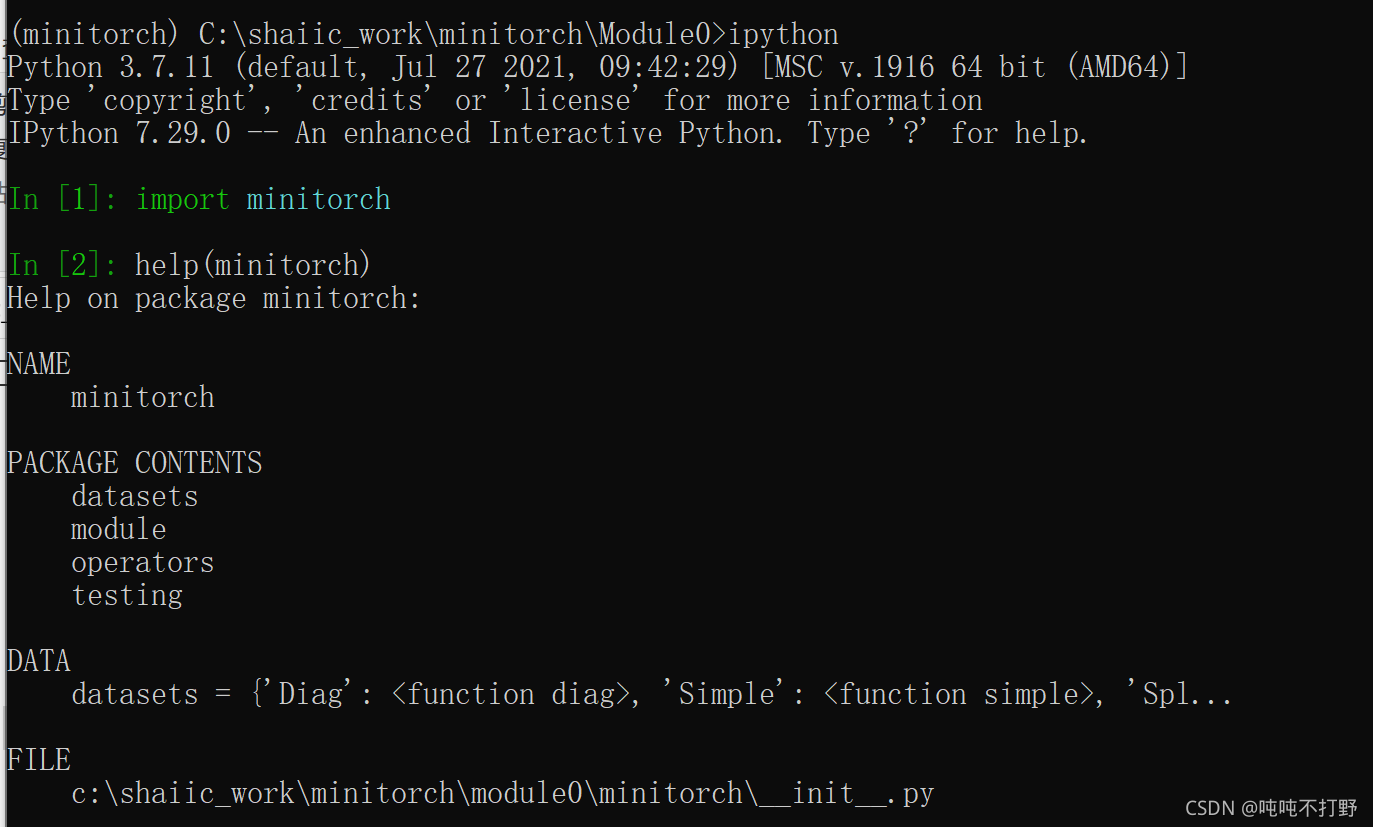
为了验证是否安装正确,可以在python环境下,运行import minitorch
2. ML Primer(机器学习基础)
这部分引导是对机器学习非常基础的一个介绍,但是对于后续的任务以及最后的测验非常必要。机器学习有着非常丰富的模型、目标以及学习设置,是一个快速发展的领域。有很多非常棒的关于机器学习细节的书籍,这里我推荐:Pattern Recognition and Machine Learning。
本次的介绍不在于详细讲述机器学习。我们的目标是用一类模型解释一个数据集的最小细节。特别的,是介绍一个有监督神经网络用于二分类。本节的目标是学习一个基本的神经网络是如何进行简单的分类的。
2.1 数据集
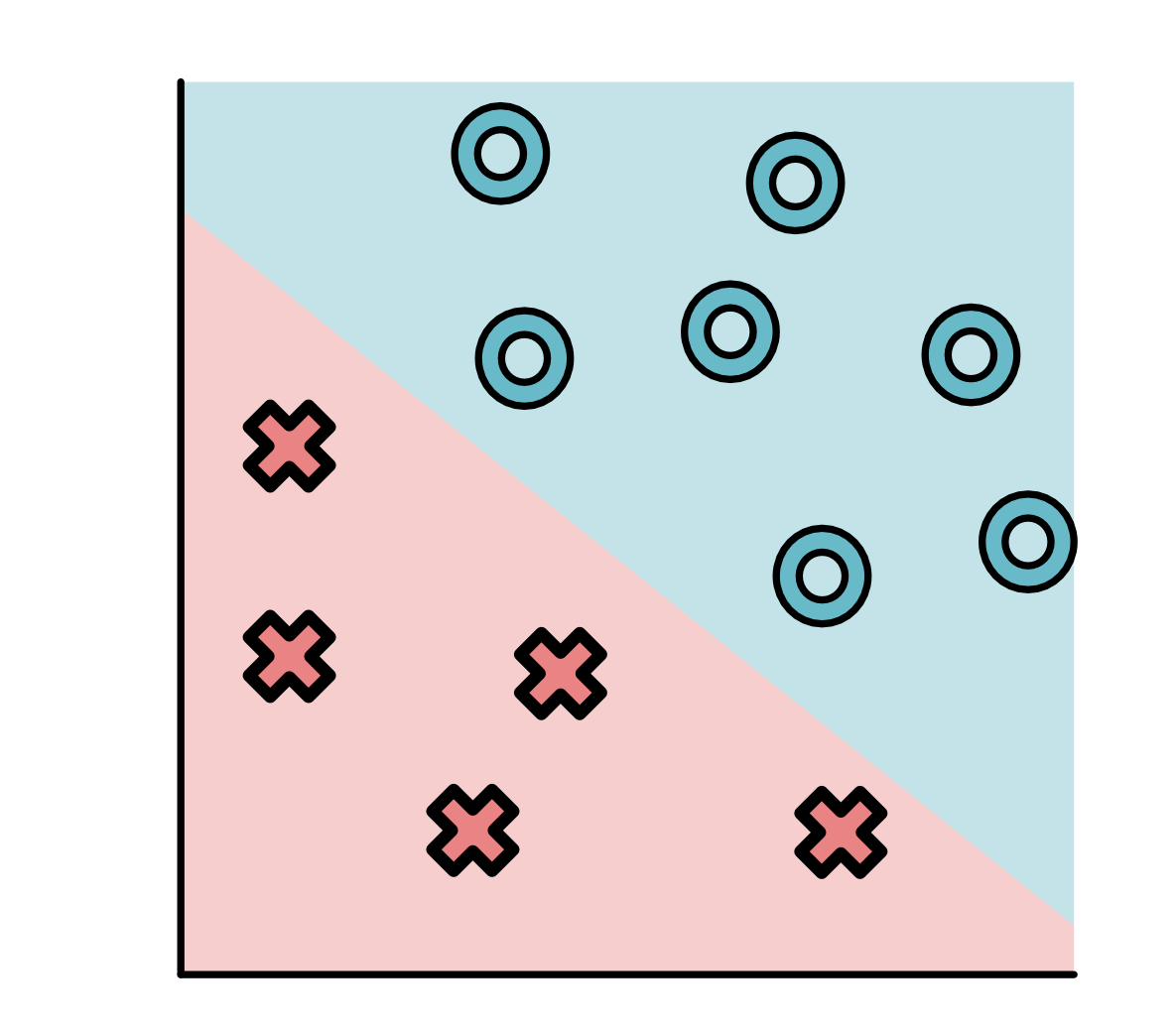
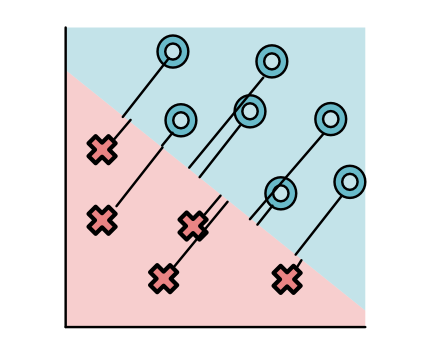
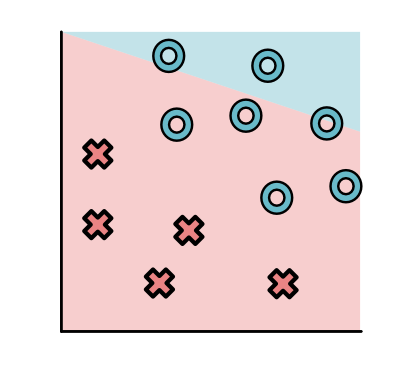
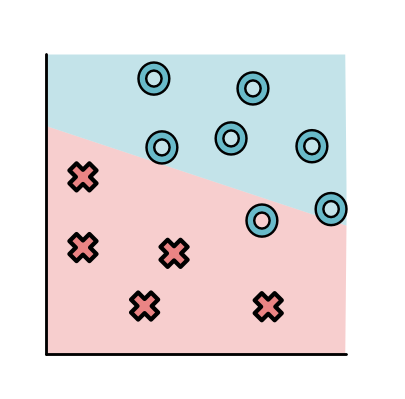
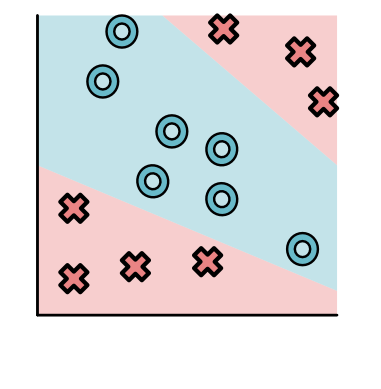
监督学习问题都有一个有标记的训练数据集。假定给出一个标注点的集合。每个点都有两个坐标值: x 1 x_1 x1和 x 2 x_2 x2表示,同时有一个标签 y y y,要么是 O O O,要么是 X X X。比如:
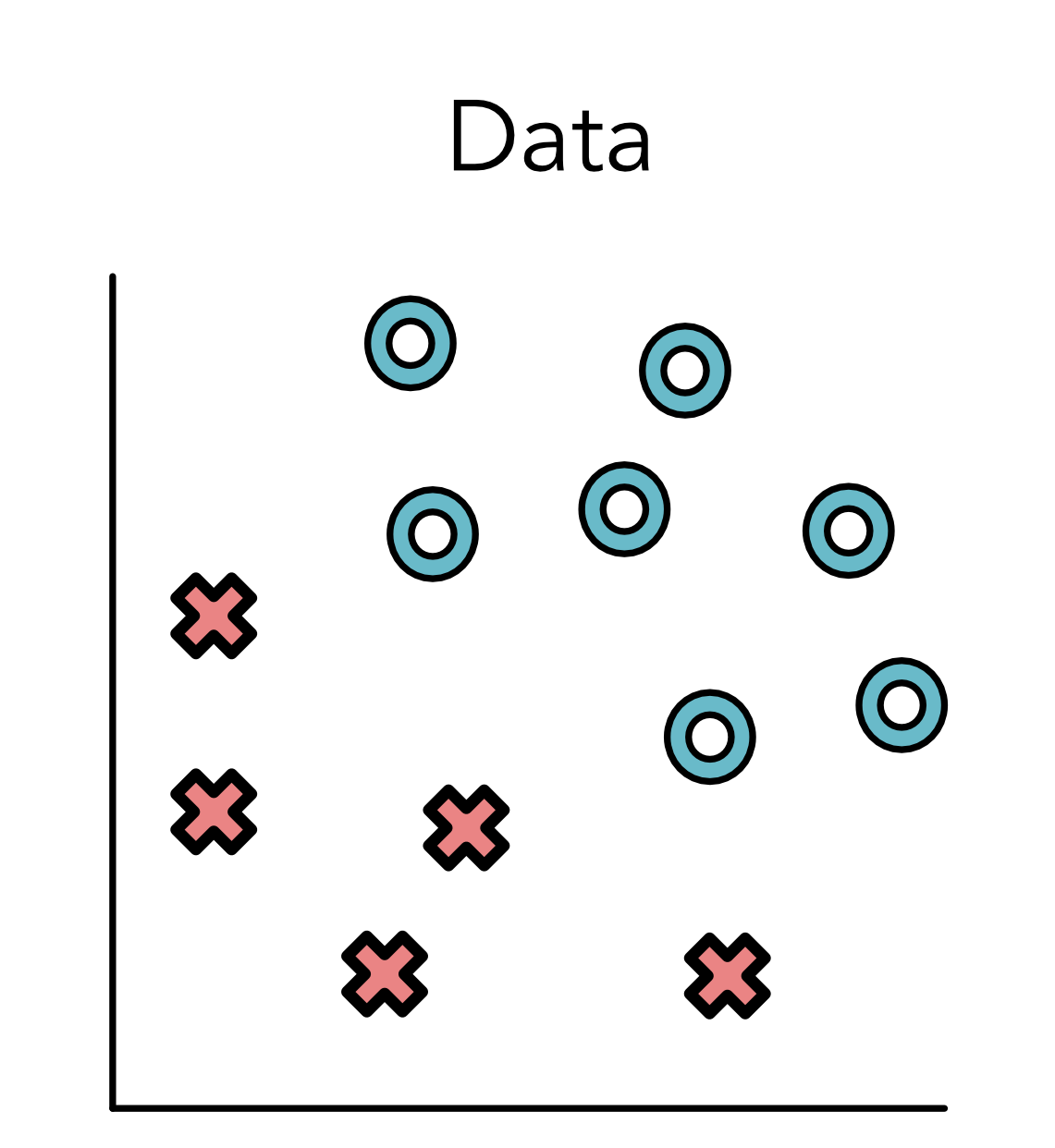
上图中,所有标签为O的点都分布在右上方,标签为X的点都分布在左下方。不是所有的数据集都这么简单,例如下面这个图就看起来稍微复杂了一些。
在之后的课程中,可能与遇到更多不同形式的数据集,比如:手写数字数据集,如下

单独看其中的8或者2:


2.2 模型
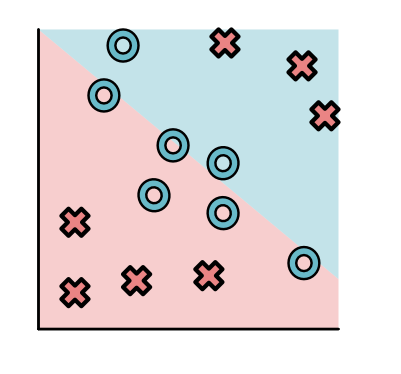
除了数据集,机器学习系统需要明确拟合数据所使用的模型。一个模型就是给数据点分配标签的函数。在2D平面中,我们可以使用决策边界来可视化一个模型。比如,考虑以下(模型A)
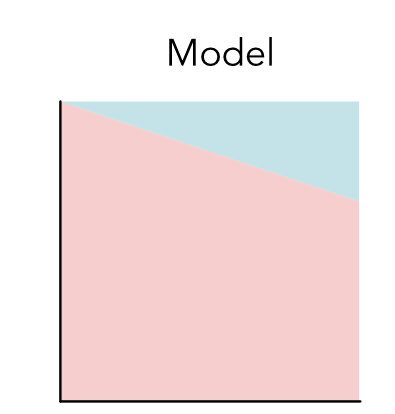
对于大多数数据点来说,模型都将其归为X这个类,只有右上角一小部分归为O这个类。
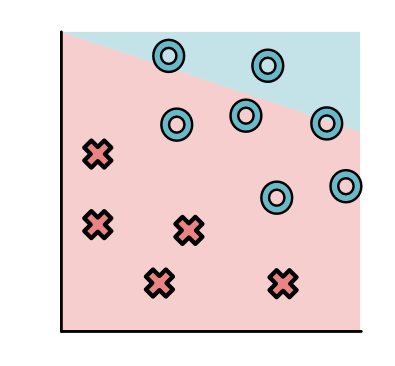
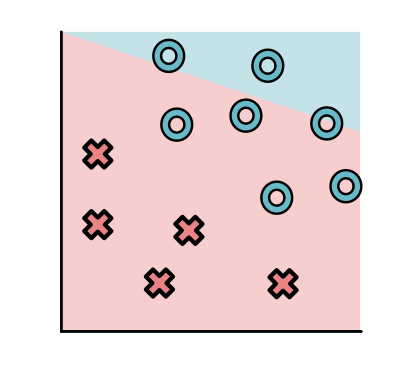
可以把刚刚描述的简单数据集放到这个模型图上面,这样可以大致看到模型对数据的拟合情况。
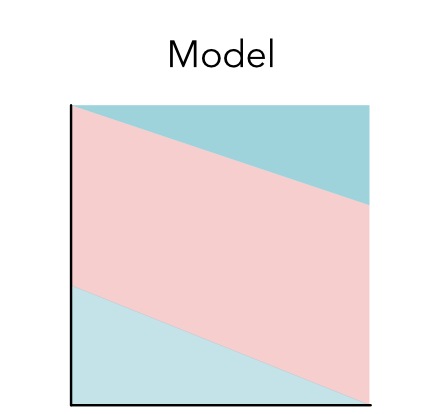
模型也可以有不同的形式,例如下面是另一个模型的可视化,接下来更多的讨论这个,下面这个模型会把数据点分成三部分(模型B)
模型也会有奇怪的形状,甚至是不连续的区域。比如下面的蓝色或者红色的分割区域(模型C)
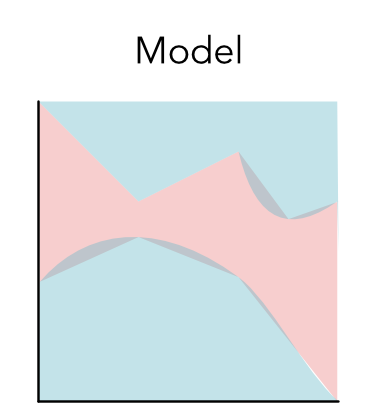
一类模型通常具有类似的形状,对于编程人员来说,我们可能不知道数据的形状,所以我们需要先尝试一些模型。机器学习就是从这些模型中找出最好模型的过程。
第一类需要考虑的模型就是线性模型,线性模型仅仅就是将数据空间使用一条直线进行分割。比如,模型A是一个线性模型,但是直觉上更好的模型应该是这样:
注意模型B其实也是用的是直线进行分割,但其不是一个线性模型,它使用了多条线来分割数据空间,可以看一些模型的例子,下面是一些随机生成的数据。(图都是使用plotly生成的,所以具有一定的交互功能。是使用分段函数绘制的图像,所以要拟合以下数据,模型最好也是分段函数)
2.3 参数
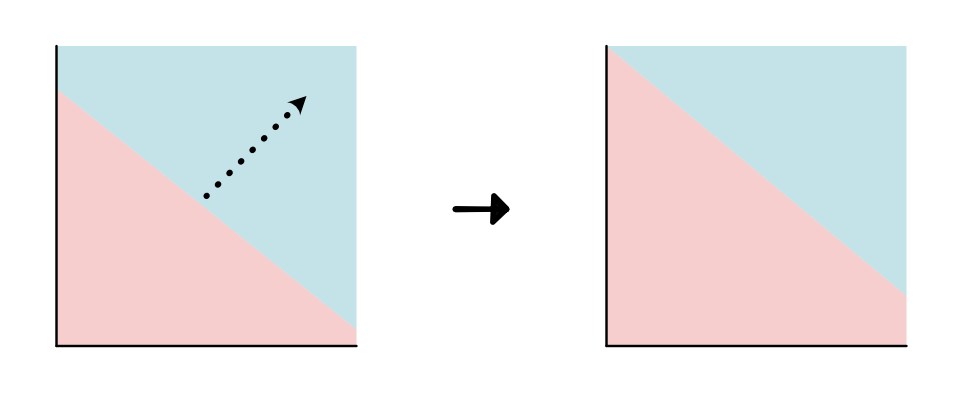
一旦决定了要使用哪一类模型,就需要去学习模型参数。例如,对于线性模型来说,就需要不断移动分割直线(即改变直线的截距和斜率),使得模型可以最好拟合数据。如下图
a. 旋转直线(修改斜率 slope)
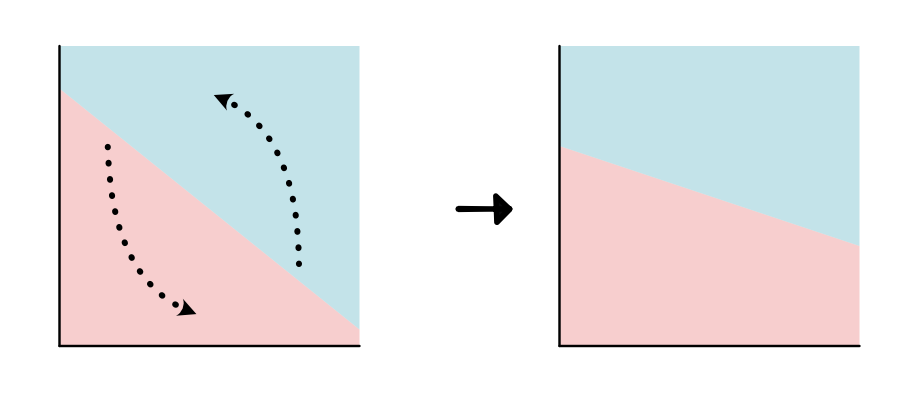
b. 改变截距(intercept)
参数(Parameters)是可以完全定义一个模型功能的数值集合。参数对于指导模型如何计算,以及对于给定的数据点如何分类/决策是至关重要的。
对于上面用于二分类的线性模型,其模型可以表示为:
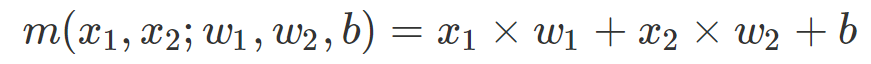
其中 w 1 , w 2 , b w_1,w_2,b w1,w2,b就是参数, x 1 , x 2 x_1,x_2 x1,x2就是输入的数据点,模型预测数据点属于X依据是, m m m是否大于1,如果小于1,则就属于O类。
2.4 损失函数
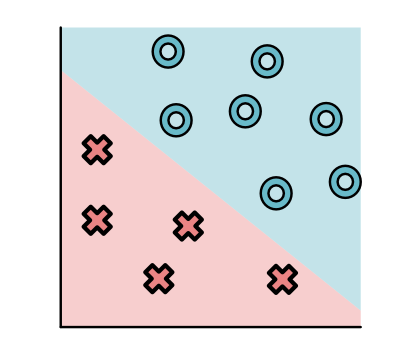
当我们观察数据的时候,可以很清晰的看到有些模型非常好,没有分类误差,如下:
但是另一些就不太好,会有很多误差
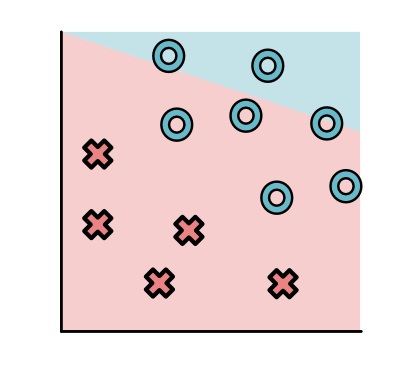
为了找到一个好的模型,首先我们需要定义什么是好。我们会通过一个叫损失函数(loss function)的东西去衡量目前做的有多差。一个好的模型的损失函数会尽可能的小。
我们的损失函数基于当前这个例子和当前的决策边界。可以认为损失函数中的距离就是每个点到上面函数 m ( ) m() m()的几何距离。
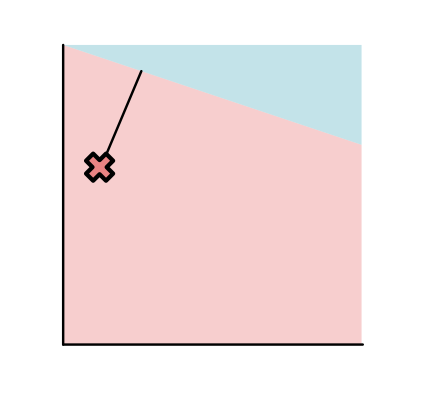
简单起见,看不同模型下一个数据点的情况。
这个点可能被分类正确了,但是距离分割边界非常远(点A,还不错)
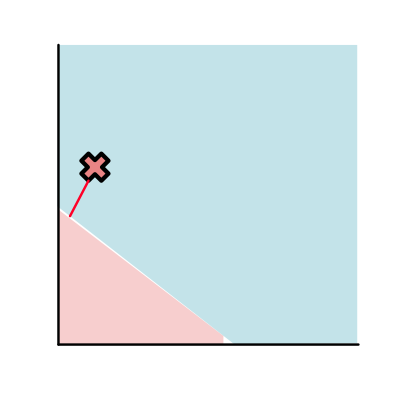
还有就是分类正确,但是距离分割线很近(点B,不太好,有分错的可能,太靠近分割线了)

或者直接就分类错误了(点C,非常糟)
损失取决于实例中使用的损失函数,最常使用的损失函数(后面的重点目标)就是sigmoid函数。对于非常小的负值,值会接近于0;对于非常大的正值,会接近于1。其他靠近原点的部分,近似是一个平滑的S曲线。
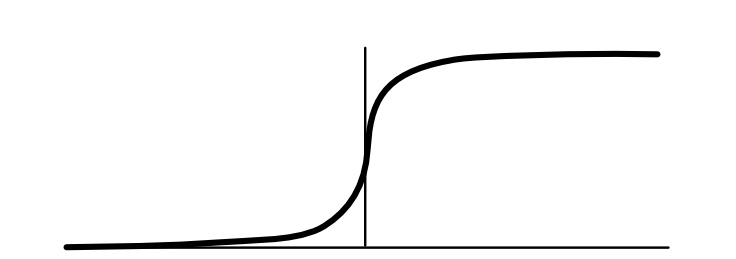
如下所示,三个标记为X的点落在sigmoid曲线的如下位置,对于点A来说,几乎为0;对于点B来说,中间值,对于点C来说,几乎为1。
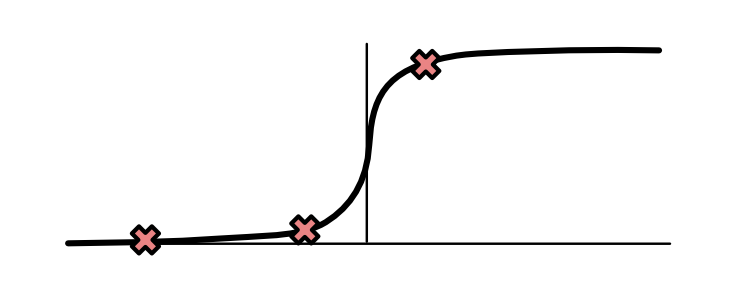
一个模型的整体的损失就是单个点的损失的和。所以不难得出结论,好的模型比糟糕的模型会产生更小的loss
2.5 拟合参数
模型类告诉我们,我们可以考虑哪些模型,参数用来告诉我们如何去明确一个给定的模型,损失函数告诉我们当前的模型好不好。所以我们需要一种方法可以找到指定损失函数下的好的模型,这步称为参数拟合。
不幸的是,参数拟合通常比较困难。即便对于最简单的ML模型,这都是一项具有挑战性同时对计算性能要求很高的任务。在我们的示例问题中,我们只有三个参数,但是现在很多大型模型可能会有几百万的参数需要去拟合。
这时候就需要类似MiniTorch这样的库。这些库的目标就是以精确的编码,建立一个用于监督学习的框架,以一种自动且高效的方式去拟合参数。
这些库都重点关注一种参数拟合的方式:梯度下降。直觉上来说,梯度下降以如下方式工作:
- 使用初始化后的参数计算数据的损失函数 L L L
- 观察每个参数的改变对损失的影响
- 朝着减小损失的方向去小步更新参数
回到刚刚不正确的模型,
正如我们所看到的,上面的模型有很高的损失,我们需要考虑更新参数来找到一个更好的模型。比如,更新截距
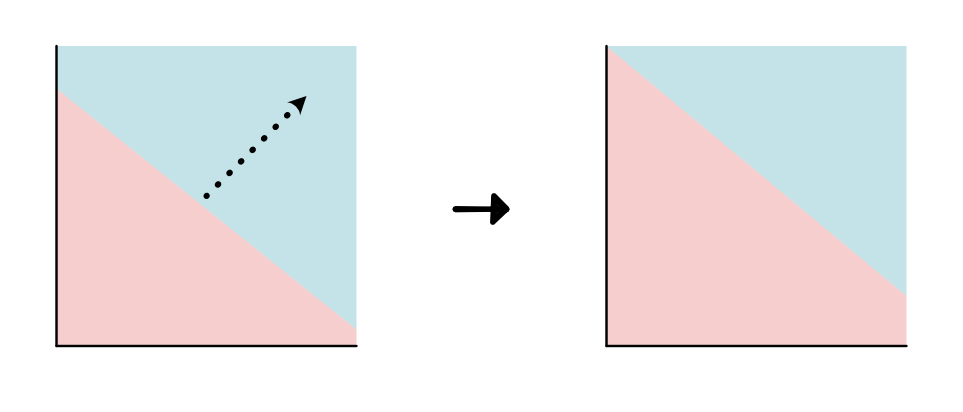
我们可以考虑改变参数时,损失是如何改变的。看起来,如果稍微减小一下截距,损失似乎是下降的。
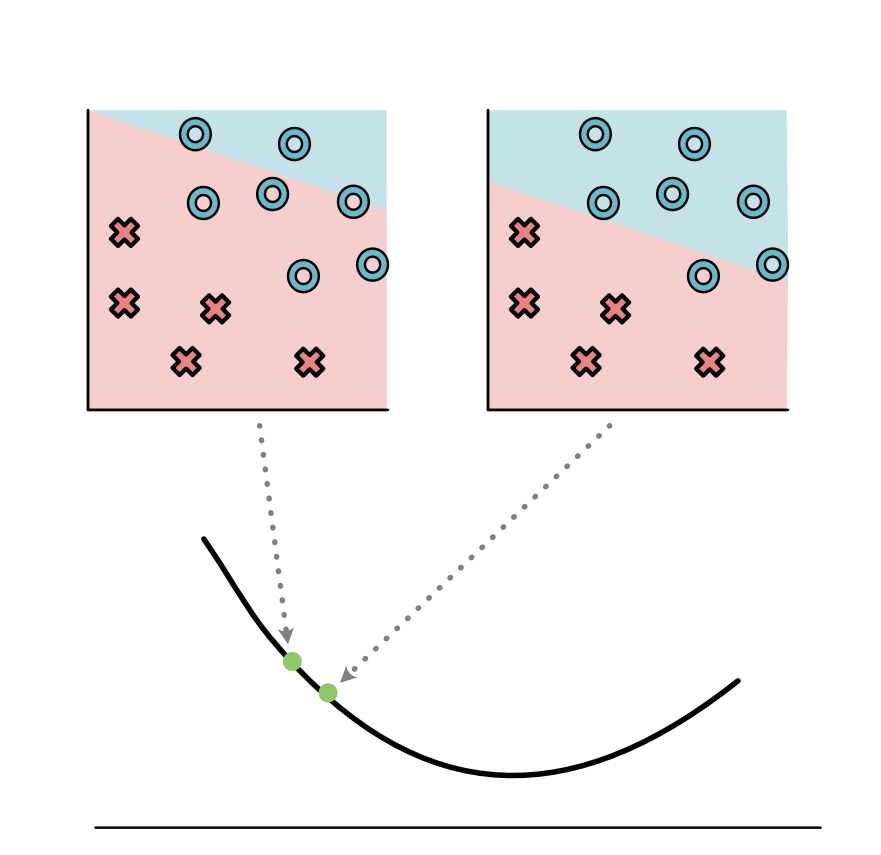
也就是说这样做,会得到一个更好的模型
可以对模型中其他参数重复截距的这一过程。
但是我们是如何知道改变截距损失函数是如何改变的呢?对于小的问题,可以移动一点看看图。但是对于具有百万参数的机器学习模型来说,就非常耗时。
一个更好的方式是利用微积分,对损失函数求导。一旦可以通过自动微分获取其导数,就知道该如何更新参数来适应损失函数。更好的是,我们可以高效的计算出所有参数的导数(也就是机器学习中常说的梯度),来知道这些参数该向哪里移动。
Minitorch中的前4个module展示了如何去高效实施自动求微分,更新导数的过程。
2.6 神经网络
迄今为止,我们知道线性模型这一类模型可以很好的拟合简单的数据,但是如果当数据有多种分割块,即不是线性可分的数据,则线性模型就无能为力了。
对于这类型数据,一种可选的模型类就是神经网络。神经网路可以用于指定更广泛的分类器。
直觉上来说,神经网络可以通过两阶段或者更多的阶段去进行分类。每个阶段使用一个线性模型将数据重塑为新的点,最后一个阶段则是对这些转换过的数据进行线性分类。
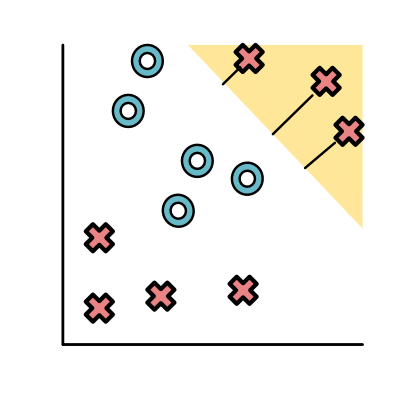
看一下数据集:
一个神经网络可能会先产生一个分类器(黄色),将上面所有红色的点分开
然后再生成另一个分类器(绿色)把所有下面的红色点分出来
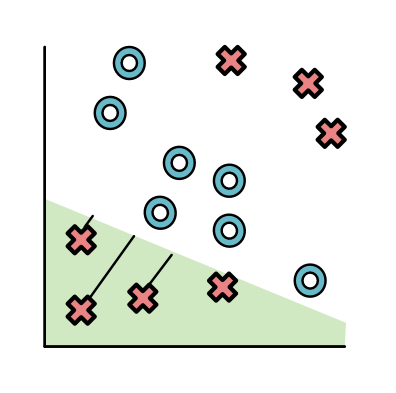
神经网络允许根据分类器的距离去转换这些点(非常类似于上面的损失函数)。可以使用任何函数去进行这种变换。理想情况下,这个函数会使得黄色和绿色的值变大,另一些点变小。ReLU函数就可以实现这个功能(ReLU表示Rectified Linear Unit,线性修正单元,一种非常复杂的表达“删除低于0的值”的方式)。
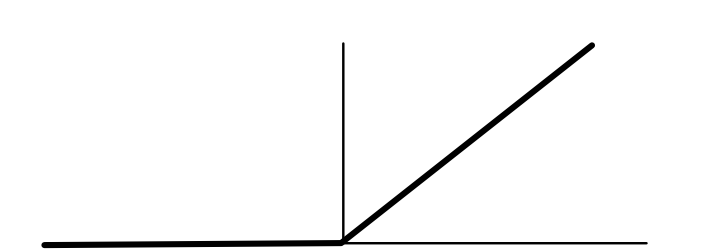
对于黄色的分类器,ReLU会产生以下的值:
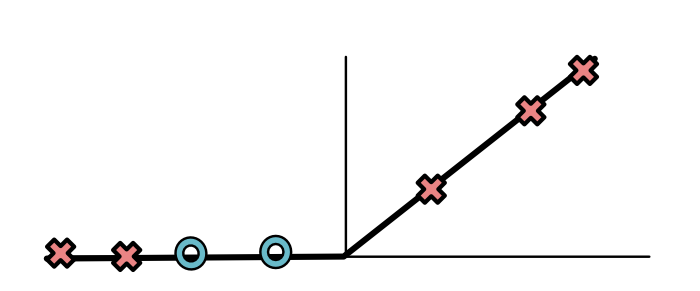
对于位于上方的X,是正值;对于下面的O和X,是0值。对于绿色分类器也有类似的现象。
最后黄色和绿色变成了新的 x 1 , x 2 x_1,x_2 x1,x2,那么这时候O就很容易分类了
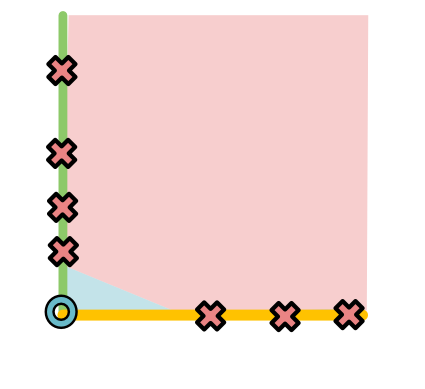
返回看初始的模型,这个过程就像生成了两条分割数据的线
数学上来说,我们把转换后的数据作为 h 1 , h 2 h_1,h_2 h1,h2,这些是通过对原始数据应用不同参数的分类器得到的。最终预测是对 h 1 , h 2 h_1,h_2 h1,h2应用分类器:
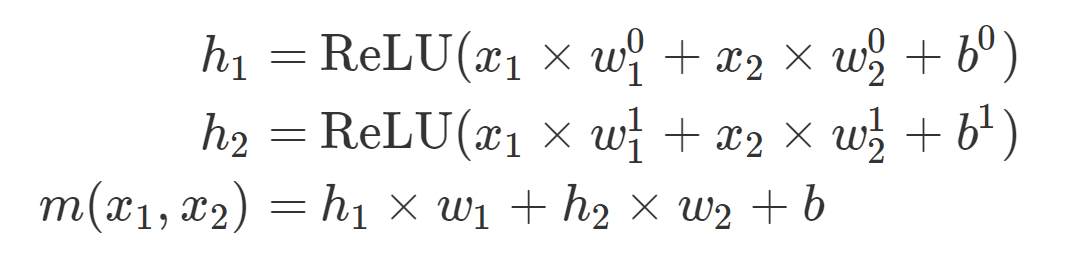
其中w1,w2,w01,w02,w11,w12,b,b0,b1都是参数。
如果我们需要获得表达能力更强更灵活的模型,代价则是需要将更多的参数通过数据进行拟合。
神经网络是前几个模型中的一个重点,看起来很简单,但是高效的拟合它需要构建完善的系统结构。一旦构建好了基础的系统结构,就可以很简单的支持现在的神经网络模型了。