文章目录
前言
本博文专用于软件创新实验室MySQL数据库与简单SQL语句课堂,请上课的同学们先自行安装 MySQL,可参考群里发的视频,也可以参考博文MySQL安装教程,在开发这条路上,数据库将会一直陪伴着我们!
简介
什么是数据库?
数据库是一个以某种有组织的方式存储的数据集合,它是一个按数据结构来存储和管理数据的计算机软件系统。理解数据库的一种最简单的办法是将其想象为一个文件柜,这个文件柜只是一个存储数据的空间,而数据库就是这么一个空间。
数据库管理系统(Database Management System, DBMS)是用于创建、管理、和维护数据库时所使用的软件,用以管理数据库,一定程度上,用户都是在操作 DBMS,所以日常的数据库概念一般就是指 DBMS。
常见的数据库软件 DBMS 有甲骨文的 Oracle DB、微软的 Access、MongoDB等,
什么是MySQL?
MySQL 是一款安全、跨平台、高效的,并与 PHP、Java 等主流编程语言紧密结合的数据库系统。该数据库系统是由瑞典的 MySQL AB 公司开发、发布并支持,由 MySQL 的初始开发人员 David Axmark 和 Michael Monty Widenius 于 1995 年建立的。
MySQL 的象征符号是一只名为 Sakila 的海豚,代表着 MySQL 数据库的速度、能力、精确和优秀本质。

特点
- 功能强大
MySQL 中提供了多种数据库存储引擎,各引擎各有所长,适用于不同的应用场合,用户可以选择最合适的引擎以得到最高性能,可以处理每天访问量超过数亿的高强度的搜索 Web 站点。MySQL5 支持事务、视图、存储过程、触发器等。 - 支持跨平台
MySQL 支持至少 20 种以上的开发平台,包括 Linux、Windows、FreeBSD 、IBMAIX、AIX、FreeBSD 等。这使得在任何平台下编写的程序都可以进行移植,而不需要对程序做任何的修改。 - 运行速度快
高速是 MySQL 的显著特性。在 MySQL 中,使用了极快的 B 树磁盘表(MyISAM)和索引压缩;通过使用优化的单扫描多连接,能够极快地实现连接;SQL 函数使用高度优化的类库实现,运行速度极快。 - 支持面向对象
PHP 支持混合编程方式。编程方式可分为纯粹面向对象、纯粹面向过程、面句对象与面向过程混合 3 种方式。 - 安全性高
灵活和安全的权限与密码系统,允许基本主机的验证。连接到服务器时,所有的密码传输均采用加密形式,从而保证了密码的安全。 - 成本低
MySQL 数据库是一种完全免费的产品,用户可以直接通过网络下载。 - 支持各种开发语言
MySQL 为各种流行的程序设计语言提供支持,为它们提供了很多的 API 函数,包括 PHP、ASP.NET、Java、Eiffel、Python、Ruby、Tcl、C、C++、Perl 语言等。 - 数据库存储容量大
MySQL 数据库的最大有效表尺寸通常是由操作系统对文件大小的限制决定的,而不是由 MySQL 内部限制决定的。InnoDB 存储引擎将 InnoDB 表保存在一个表空间内,该表空间可由数个文件创建,表空间的最大容量为 64TB,可以轻松处理拥有上千万条记录的大型数据库。 - 支持强大的内置函数
PHP 中提供了大量内置函数,几乎涵盖了 Web 应用开发中的所有功能。它内置了数据库连接、文件上传等功能,MySQL 支持大量的扩展库,如 MySQLi 等,可以为快速开发 Web 应用提供便利。
SQL
1.什么是SQL?
Structured Query Language:结构化查询语言
其实就是定义了操作所有关系型数据库的规则。每一种数据库操作的方式存在不一样的地方,称为“方言”。
2.SQL通用语法
1) SQL 语句可以单行或多行书写,以分号结尾。
2) 可使用空格和缩进来增强语句的可读性。
3) MySQL 数据库的 SQL 语句不区分大小写,关键字建议使用大写。
4) 3 种注释
* 单行注释: -- 注释内容 或 # 注释内容(mysql 特有)
* 多行注释: /* 注释 */
3. SQL分类
1) DDL(Data Definition Language)数据定义语言
用来定义数据库对象:数据库,表,列等。关键字:create, drop,alter 等
2) DML(Data Manipulation Language)数据操作语言
用来对数据库中表的数据进行增删改。关键字:insert, delete, update 等
3) DQL(Data Query Language)数据查询语言
用来查询数据库中表的记录(数据)。关键字:select, where 等
4) DCL(Data Control Language)数据控制语言(了解)
用来定义数据库的访问权限和安全级别,及创建用户。关键字:GRANT, REVOKE 等
DDL:操作数据库、表
1. 操作数据库:CRUD
1. C(Create):创建
* 创建数据库:
* create database 数据库名称;
* 创建数据库,判断不存在,再创建:
* create database if not exists 数据库名称;
* 创建数据库,并指定字符集
* create database 数据库名称 character set 字符集名;
* 练习: 创建db4数据库,判断是否存在,并制定字符集为gbk
* create database if not exists db4 character set gbk;
2. R(Retrieve):查询
* 查询所有数据库的名称:
* show databases;
* 查询某个数据库的字符集:查询某个数据库的创建语句
* show create database 数据库名称;
3. U(Update):修改
* 修改数据库的字符集
* alter database 数据库名称 character set 字符集名称;
4. D(Delete):删除
* 删除数据库
* drop database 数据库名称;
* 判断数据库存在,存在再删除
* drop database if exists 数据库名称;
5. 使用数据库
* 查询当前正在使用的数据库名称
* select database();
* 使用数据库
* use 数据库名称;
2. 操作表
1. C(Create):创建
* 语法:
create table 表名(
列名1 数据类型1,
列名2 数据类型2,
....
列名n 数据类型n
);
* 注意:最后一列,不需要加逗号(,)
* 数据库类型:
1) int:整数类型
* age int,
2) double:小数类型
* score double(5,2)
3) date:日期,只包含年月日,yyyy-MM-dd
4) datetime:日期,包含年月日时分秒 yyyy-MM-dd HH:mm:ss
5) timestamp:时间错类型 包含年月日时分秒 yyyy-MM-dd HH:mm:ss
* 如果将来不给这个字段赋值,或赋值为null,则默认使用当前的系统时间,来自动赋值
6) varchar:字符串
* name varchar(20):姓名最大20个字符
* zhangsan 8个字符 张三 2个字符
* 创建表
create table student(
id int,
name varchar(32),
age int ,
score double(4,1),
birthday date,
insert_time timestamp
);
* 复制表:
* create table 表名 like 被复制的表名;
2. R(Retrieve):查询
* 查询某个数据库中所有的表名称
* show tables;
* 查询表结构
* desc 表名;
3. U(Update):修改
1) 修改表名
alter table 表名 rename to 新的表名;
2) 修改表的字符集
alter table 表名 character set 字符集名称;
3) 添加一列
alter table 表名 add 列名 数据类型;
4) 修改列名称 类型
alter table 表名 change 列名 新列别 新数据类型;
alter table 表名 modify 列名 新数据类型;
5) 删除列
alter table 表名 drop 列名;
4. D(Delete):删除
* drop table 表名;
* drop table if exists 表名 ;
- 客户端图形化工具:SQLYog,Navicat
DML:增删改表中数据
1. 添加数据:
* 语法:
* insert into 表名(列名1,列名2,...列名n) values(值1,值2,...值n);
* 注意:
1) 列名和值要一一对应。
2) 如果表名后,不定义列名,则默认给所有列添加值
insert into 表名 values(值1,值2,...值n);
3) 除了数字类型,其他类型需要使用引号(单双都可以)引起来
2. 删除数据:
* 语法:
* delete from 表名 [where 条件]
* 注意:
1) 如果不加条件,则删除表中所有记录。
2) 如果要删除所有记录
(1) delete from 表名; -- 不推荐使用。有多少条记录就会执行多少次删除操作
(2) TRUNCATE TABLE 表名; -- 推荐使用,效率更高 先删除表,然后再创建一张一样的表。
3. 修改数据:
* 语法:
* update 表名 set 列名1 = 值1, 列名2 = 值2,... [where 条件];
* 注意:
* 如果不加任何条件,则会将表中所有记录全部修改。
DQL:查询表中的记录
* select * from 表名;
1. 语法:
select
字段列表
from
表名列表
where
条件列表
group by
分组字段
having
分组之后的条件
order by
排序
limit
分页限定
2. 基础查询
1) 多个字段的查询
select 字段名1,字段名2... from 表名;
* 注意:
* 如果查询所有字段,则可以使用*来替代字段列表。
2) 去除重复:
* distinct
3) 计算列
* 一般可以使用四则运算计算一些列的值。(一般只会进行数值型的计算)
* ifnull(表达式1,表达式2):null参与的运算,计算结果都为null
* 表达式1:哪个字段需要判断是否为null
* 如果该字段为null后的替换值。
4) 起别名:
* as:as也可以省略
3. 条件查询
1. where子句后跟条件
2. 运算符
* > 、< 、<= 、>= 、= 、<>
* BETWEEN...AND
* IN( 集合)
* LIKE:模糊查询
* 占位符:
* _:单个任意字符
* %:多个任意字符
* IS NULL
* and 或 &&
* or 或 ||
* not 或 !
-- 查询年龄大于20岁
SELECT * FROM student WHERE age > 20;
SELECT * FROM student WHERE age >= 20;
-- 查询年龄等于20岁
SELECT * FROM student WHERE age = 20;
-- 查询年龄不等于20岁
SELECT * FROM student WHERE age != 20;
SELECT * FROM student WHERE age <> 20;
-- 查询年龄大于等于20 小于等于30
SELECT * FROM student WHERE age >= 20 && age <=30;
SELECT * FROM student WHERE age >= 20 AND age <=30;
SELECT * FROM student WHERE age BETWEEN 20 AND 30;
-- 查询年龄22岁,18岁,25岁的信息
SELECT * FROM student WHERE age = 22 OR age = 18 OR age = 25
SELECT * FROM student WHERE age IN (22,18,25);
-- 查询英语成绩为null
SELECT * FROM student WHERE english = NULL; -- 不对的。null值不能使用 = (!=) 判断
SELECT * FROM student WHERE english IS NULL;
-- 查询英语成绩不为null
SELECT * FROM student WHERE english IS NOT NULL;
-- 查询姓马的有哪些? like
SELECT * FROM student WHERE NAME LIKE '马%';
-- 查询姓名第二个字是化的人
SELECT * FROM student WHERE NAME LIKE "_化%";
-- 查询姓名是3个字的人
SELECT * FROM student WHERE NAME LIKE '___';
-- 查询姓名中包含德的人
SELECT * FROM student WHERE NAME LIKE '%德%';
后记
本博文借鉴了MySQL 简介和MySQL数据库简介,上述只是简单的对数据库进行介绍以及略微讲解了 SQL 语句,数据库还是很博大精深的,感兴趣的同学可以深入探究一番,比如事务,B+树等,冲冲冲!
拓展
范式
通常我们在创建数据库需要一定的规则去遵守,在 RDBMS 中,这种规则就是范式。而规范化目的就是使结构更合理,消除存储异常,使数据冗余尽量小,便于插入、删除和更新,使得它符合第一范式的规则,然后是第二范式,最后是第三范式。一般来说,数据库只需满足第三范式就行了。这里只介绍三大范式,当然还有 BCNF 等,感兴趣的同学自行了解。
第一范式 1NF
-
每个表具有一个主键,主键可以由一个列或多个列组成,是记录的唯一标识符;
-
数据库表中的任何字段都是单一属性,不可再分。
例题
如下是记录学生家庭信息的数据库表,
| 学号 | 姓名 | 性别 | 家庭地址 |
|---|---|---|---|
| 001 | 小明 | 男 | 浙江省金华市婺城区 |
| 002 | 小红 | 女 | 广东省深圳市南山区 |
| 003 | 小王 | 男 | 江苏省南京市江宁区 |
从图中我们可以发现:学号、姓名、性别都是具有唯一性的,是不可在分割的部分,而家庭住址则是由省、市、区三部分组成,因此可以被细分,如下图所示:
| 学号 | 姓名 | 性别 | 省 | 市 | 区 |
|---|---|---|---|---|---|
| 001 | 小明 | 男 | 浙江省 | 金华市 | 婺城区 |
| 002 | 小红 | 女 | 广东省 | 深圳市 | 南山区 |
| 003 | 小王 | 男 | 江苏省 | 江宁区 | 南京市 |
这样子就是符合第一范式的数据库表了。
第二范式 2NF
-
第二范式是在第一范式的基础上建立起来的,即满足第二范式必须先满足第一范式;
-
要求数据表里的所有数据都要和该数据表的主键有完全依赖关系,即不存在部分函数依赖。
例题1
如下是记录学生课程信息的数据库表,其中有四个字段,分别为学生学号 sno,课程编号 cno,最终成绩 grade,课程学分 credit,
| sno | cno | grade | credit |
|---|---|---|---|
| 001 | 1 | 76 | 3 |
| 002 | 1 | 98 | 3 |
| 003 | 1 | 45 | 3 |
| 004 | 2 | 86 | 4 |
如此以来,学分被大量重复存储,造成数据冗余:
-
如要某课程学分,则要大量重复操作;
-
如要加新课程,由于
sno和cno共同做为主键,则在加入新课程时,必须有人选该课;
总之,这种设计不太好,非关键字属性 credit 仅函数依赖于 cno,也就是credit 部分依赖组合关键字 (sno,cno) 而不是完全依赖!
解决方法:分为两个关系模式,如下图所示,通过 cno 进行关联,
课程信息表
| cno | credit |
|---|---|
| 1 | 3 |
| 2 | 4 |
学生成绩表
| sno | cno | grade |
|---|---|---|
| 001 | 1 | 76 |
| 002 | 1 | 98 |
| 003 | 1 | 45 |
| 001 | 2 | 86 |
例题2
如下是学生信息表,
| 学号 | 姓名 | 性别 | 年龄 | 专业编号 | 课程编号 | 课程名称 | 任课教师 | 上课地点 | 上课时间 |
|---|---|---|---|---|---|---|---|---|---|
| 001 | 小明 | 男 | 19 | 134 | 13401 | 计算机导论 | 张三 | 20幢 | 8:30 |
| 002 | 小红 | 女 | 18 | 069 | 06913 | 拉拉操 | 李四 | 19幢 | 14:00 |
| 003 | 小王 | 男 | 20 | 208 | 20832 | 毛概 | 王五 | 17幢 | 10:45 |
从这个表中可以看出:学号和专业编号是学生信息表的联合主键,而任课教师、上课地点等信息都与主键没有直接关联,违反了第二范式的原则,因此我们要对这个表进行一些改动,使之符合第二范式的要求。
解决方法:根据两个主键的主要信息将该数据库表分割为学生信息表和专业信息表两个表,将上课专业的具体信息再分为课程信息表。学生所在专业作为了一个唯一性的列(一个学校只具有这一个专业),而专业所往下又可划分为不同信息,不同的课程所上课时间、地点、老师又都各不相同。
学生信息表
| 学号 | 姓名 | 性别 | 年龄 |
|---|---|---|---|
| 001 | 小明 | 男 | 19 |
| 002 | 小红 | 女 | 18 |
| 003 | 小王 | 男 | 20 |
专业信息表
| 学号 | 专业编号 | 课程编号 |
|---|---|---|
| 001 | 134 | 13401 |
| 002 | 069 | 06913 |
| 003 | 208 | 20832 |
课程信息表
| 课程编号 | 课程名称 | 任课教师 | 上课地点 | 上课时间 |
|---|---|---|---|---|
| 13401 | 计算机导论 | 张三 | 20幢 | 8:30 |
| 06913 | 拉拉操 | 李四 | 19幢 | 14:00 |
| 20832 | 毛概 | 王五 | 17幢 | 10:45 |
第三范式 3NF
- 符合第二范式;
- 消除了传递依赖关系,任何两个非主键字段之间不存在依赖关系,即关系模式 R(U,F)中的所有非主属性对任何候选关键字都不存在传递依赖。
例题
学生信息表
| 学号 | 姓名 | 性别 | 年龄 | 课程编号 |
|---|---|---|---|---|
| 001 | 小明 | 男 | 19 | 13401 |
| 002 | 小红 | 女 | 18 | 06913 |
| 003 | 小王 | 男 | 20 | 20832 |
课程信息表
| 课程编号 | 课程名称 | 任课教师 | 上课地点 | 上课时间 |
|---|---|---|---|---|
| 13401 | 计算机导论 | 张三 | 20幢 | 8:30 |
| 06913 | 拉拉操 | 李四 | 19幢 | 14:00 |
| 20832 | 毛概 | 王五 | 17幢 | 10:45 |
从这两张表中我们都可以明显的发现:不管哪一字段都与表当前的主键是紧密相连的,都依赖它。比如:一个学生的学号是唯一的,当你从数据库中要查找一个学生所选的课程时,你只需使用 WHERE 子句指定查找学号即可查出,课程信息表也是如此。
所以对于建好一个数据库来说,这三个范式是多么的重要啊。不仅使我们避免了大量的数据冗余,节省了存储空间,而且保持了数据的一致性。要查询不同表中的数据只需进行 SELECT 联合查询即可!
B+树
B+ 树是一种树数据结构,通常用于数据库和操作系统的文件系统中。B+ 树的特点是能够保持数据稳定有序,其插入与修改拥有较稳定的对数时间复杂度。B+ 树元素自底向上插入,这与二叉树恰好相反。
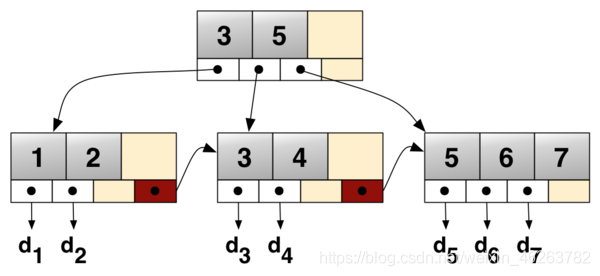
节点结构
在 B+ 树中的节点通常被表示为一组有序的元素和子指针。如果此 B+ 树的阶数是 m,则除了根之外的每个节点都包含最少 [m/2] 个元素最多 m-1 个元素,对于任意的结点有最多 m 个子指针。对于所有内部节点,子指针的数目总是比元素的数目多一个。所有叶子都在相同的高度上,叶结点本身按关键字大小从小到大链接。
插入
- 首先,查找要插入其中的节点的位置。接着把值插入这个节点中。
- 如果没有节点处于违规状态则处理结束。
- 如果某个节点有过多元素,则把它分裂为两个节点,每个都有最小数目的元素。在树上递归向上继续这个处理直到到达根节点,如果根节点被分裂,则创建一个新根节点。为了使它工作,元素的最小和最大数目典型的必须选择为使最小数不小于最大数的一半。
删除
-
首先,查找要删除的值。接着从包含它的节点中删除这个值。
-
如果没有节点处于违规状态则处理结束。
-
如果节点处于违规状态则有两种可能情况:
-
它的兄弟节点,就是同一个父节点的子节点,可以把一个或多个它的子节点转移到当前节点,而把它返回为合法状态。如果是这样,在更改父节点和两个兄弟节点的分离值之后处理结束。
-
它的兄弟节点由于处在低边界上而没有额外的子节点。在这种情况下把两个兄弟节点合并到一个单一的节点中,而且我们递归到父节点上,因为它被删除了一个子节点。持续这个处理直到当前节点是合法状态或者到达根节点,在其上根节点的子节点被合并而且合并后的节点成为新的根节点。
-
例题
给定下图中的B+树,插入如下:20、13、15、10、11、12,每次插入后画一个单独的B+树结构
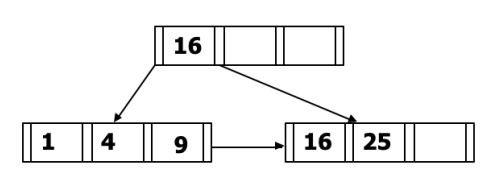
最终答案:
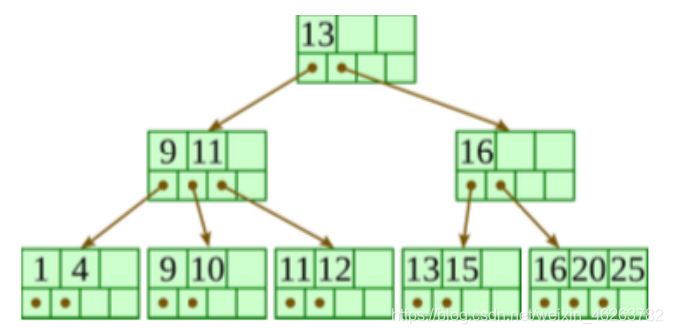
参考答案
- Write SQL DDL corresponding to the schema in Figure 3.17. Make any reasonable assumptions about data types, and be sure to declare primary and foreign keys.

Solution
create table person
(driver_id varchar(50),
name varchar(50),
address varchar(50),
primary key (driver_id));
create table car
(license_plate varchar(50),
model varchar(50),
year integer,
primary key (license_plate));
create table accident
(report_number integer,
year integer,
location varchar(50),
primary key (report_number));
create table owns
(driver_id varchar(50),
license_plate varchar(50),
primary key (driver_id, license_plate),
foreign key (driver_id) references person,
foreign key (license_plate) references car);
create table participated
(report_number integer
license_plate varchar(50),
driver_id varchar(50),
damage_amount integer,
primary key (report_number, license-plate),
foreign key (license_plate) references car,
foreign key (report_number) references accident)),
foreign key (driver_id) references person;
-
Consider the employee database of Figure 3.19, where the primary keys are underlined. Give an expression in SQL for each of the following queries.
a. Find ID and name of each employee who lives in the same city as the location of the company for which the employee works.
b. Find ID and name of each employee who lives in the same city and on the same street as does her or his manager.
c. Find ID and name of each employee who earns more than the average salary of all employees of her or his company.
d. Find the company that has the smallest payroll.

Solution
a. Find ID and name of each employee who lives in the same city as the location of the company for which the employee works.
select e.ID, person_name
from employee as e, works as w, company as с
where e.lD = w.ID
and e.citу = с.city
and w.company_name = c.company_nаmе
b. Find ID and name of each employee who lives in the same city and on the same street as does her or his manager.
select e.ID, e.person_name
from employee as e, employee as m, manages
where e.ID = manages.ID
and m.ID = manages.manager_id
and e.street = m.street
and e.city = m.city
c. Find ID and name of each employee who earns more than the average salary of all employees of her or his company.
select E.ID, person_name
from works as T, employee as E
where E.ID = T.ID
and salary > (select avg (salary)
from works as S
where Т.соmрапу_nаmе = S.сотрапy_nаmе)
The primary key constraint on works ensures that each person works for at most one company.
d. Find the company that has the smallest payroll.
select соmрапу_nаmе
from works
group by company_name
having sum (salary) <= all (select sum (salary)
from works
group by соmрапу_nаmе)
classroom(building, room_number, capacity)
department(dept_name, building, budget)
course(course_id, title, dept_name, credits)
instructor(ID, name, dept_name, salary)
section(course_id, sec_id, semester, year, building, room_number, time_slot_id)
teaches(ID, course_id, sec_id, semester, year)
student(ID, name, dept_name, tot_cred)
takes(ID, course_id, sec_id, semester, year, grade)
advisor(s_ID, i_ID)
time_slot(time_slot_id, day, start_time, end_time)
prereq(course_id, prereq_id)
Considering the database above, use SQL language to write the following queries.
Solution
Q1. Find the department names of all instructors
select distinct dept_name
from instructor;
Q2. Find the names of all instructors in the Computer Science department who have salary greater than $70,000.
select name
from instructor
where dept_name = 'Comp. Sci.' and salary > 70000;
Q3. Find the names of all instructors, along with their department names and department building name.
select name, instructor.dept_name, building
from instructor, department
where instructor.dept_name = department.dept_name;
Q4. Find the names of all instructors whose salary is greater than at least one instructor in the Biological department.
select distinct T.name
from instructor as T, instructor as S
where T.salary > S.salary and S.dept_name = 'Biology';
Q5. Find the names of all departments whose building name includes the substring ‘Watson’.”
select dept_name
from department
where building like '%Watson%';
Q6. Using union property, find the set of all courses taught either in Fall 2009 or in Spring 2010, or both.
(select course_id
from section
where semester = 'Fall' and year= 2009)
union
(select course_id
from section
where semester = 'Spring' and year= 2010);
Q7. Find all instructors who appear in the instructor relation with null values for salary.
select name
from instructor
where salary is null;
4.范式
①

②

③

- B+树
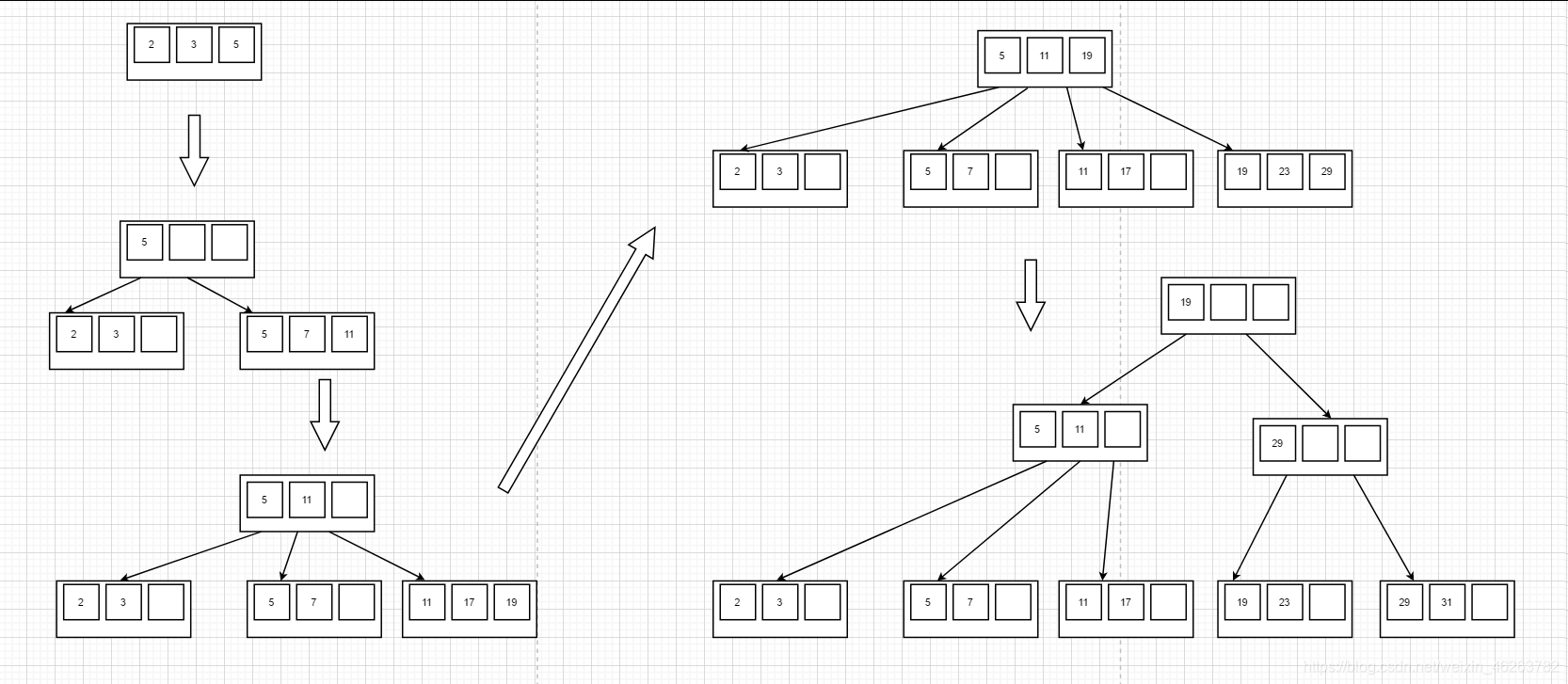
(此图选自张灵珊同学的作业)