人工智能相关概念
【小宅按】作为一个大数据从业人员,相信大家整天都在被AI、机器学习、深度学习等一些概念轰炸。有时候甚至有点诚惶诚恐,一方面作为一个“业内人士”而自豪,另一方面觉得新概念一个接一个,自己不甚了解,有点恐惧。我一直相信一句台词——“喝了敌人的血,下次见面就不会再怕了”。学习知识亦然,很多时候,你觉得很高深,实际上是缺乏清晰的概念。当你真的把这些概念理清楚后,往往会恍然大悟,万变不离其宗,原来不过如此。
人工智能是一个很老的概念,机器学习是人工智能的一个子集,深度学习又是机器学习的一个子集。机器学习与深度学习都是需要大量数据来“喂”的,是大数据技术上的一个应用,同时深度学习还需要更高的运算能力支撑,如GPU。以一张图来结尾。
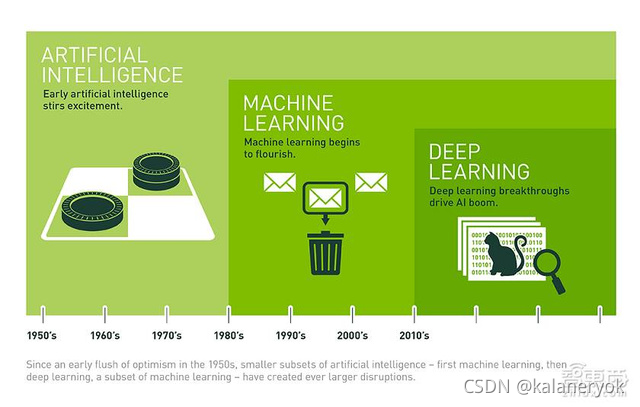
人工智能(Artificial Intelligence)
人工智能是研究、开发用于模拟、延伸和扩展人的智能的理论、方法、技术及应用系统的一门技术科学。我们来分解一下这个概念。“人工智能”是“一门技术科学”,它研究与开发的对象是“理论、技术及应用系统”,研究的目的是为了“模拟、延伸和扩展人的智能”。既然如此,那么买菜用的“计算器”算是人工智能吗?严格地说是算的,因为它至少做了“模拟”人在计算方面的智能,并扩展了这个能力(比人算得更快)。我们每天编码驱动计算机去帮我们干活,这个算是人工智能吗?也算的。所以,首先不用妄自菲薄,其实大家早已是“人工智能”的从业者了。我们现在看到的貌似很高端的技术,如图像识别、NLP,其实依然没有脱离这个范围,说白了,就是“模拟人在看图方面的智能”和“模拟人在听话方面的智能”,本质上和“模拟人在计算方面的智能”没啥两样,虽然难度有高低,但目的是一样的——模拟、延伸和扩展人的智能。另外,人工智能也不是啥新概念,事实上这是50年代提出的东西了(比你们老多了),现在这么火热,顶多只能算是“诈尸”,谈不上“新生”。
随着人对计算机科学的期望越来越高,要求它解决的问题越来越复杂,摧枯拉朽地打个小怪已经远远不能满足人们的诉求了。1+1好算,1+2也不难,这些已经能解决的问题暂且按下不表。要解决的问题域越来越复杂,即使是同一个问题,其面对的场景也越来越多。咱总不能每新出来一种场景,就让码农去查找switch,然后在default前去再加一个case吧;世间的场景千千万,那得多少个case啊,杀个码农祭天也保不齐会出问题啊。那怎么办呢?于是有人提出了一个新的思路——能否不为难码农,让机器自己去学习呢(提出这个概念的人一定做过码农)?
机器学习
所以,机器学习的定义就出来了。机器学习就是用算法解析数据,不断学习,对世界中发生的事做出判断和预测的一项技术。研究人员不会亲手编写软件、确定特殊指令集、然后让程序完成特殊任务;相反,研究人员会用大量数据和算法“训练”机器,让机器学会如何执行任务。这里有三个重要的信息:1、“机器学习”是“模拟、延伸和扩展人的智能”的一条路径,所以是人工智能的一个子集;2、“机器学习”是要基于大量数据的,也就是说它的“智能”是用大量数据喂出来的,如果缺少海量数据,它也就啥也不是了;3、正是因为要处理海量数据,所以大数据技术尤为重要;“机器学习”只是大数据技术上的一个应用。常用的10大机器学习算法有:决策树、随机森林、逻辑回归、SVM、朴素贝叶斯、K最近邻算法、K均值算法、Adaboost算法、神经网络、马尔科夫。Apache有个开源项叫mahout,提供了这些经典算法的实现;但是后来spark出来了,由于在内存迭代计算方面的优势,一下子抢过了这个风头,目前spark自带的MLlib被使用得更为广泛。虽然mahout也在向spark转,但是在技术的世界里就是这样的,只有新人笑,哪闻旧人哭。
深度学习
相较而言,深度学习是一个比较新的概念,算是00后吧,严格地说是2006年提出来的。是用于建立、模拟人脑进行分析学习的神经网络,并模仿人脑的机制来解释数据的一种机器学习技术。它的基本特点,是试图模仿大脑的神经元之间传递,处理信息的模式。最显著的应用是计算机视觉和自然语言处理(NLP)领域。显然,“深度学习”是与机器学习中的“神经网络”是强相关,“神经网络”也是其主要的算法和手段;或者我们可以将“深度学习”称之为“改良版的神经网络”算法。深度学习又分为卷积神经网络(Convolutional neural networks,简称CNN)和深度置信网(Deep Belief Nets,简称DBN)。其主要的思想就是模拟人的神经元,每个神经元接受到信息,处理完后传递给与之相邻的所有神经元即可。所以看起来的处理方式有点像下图(想深入了解的同学可以自行google)。
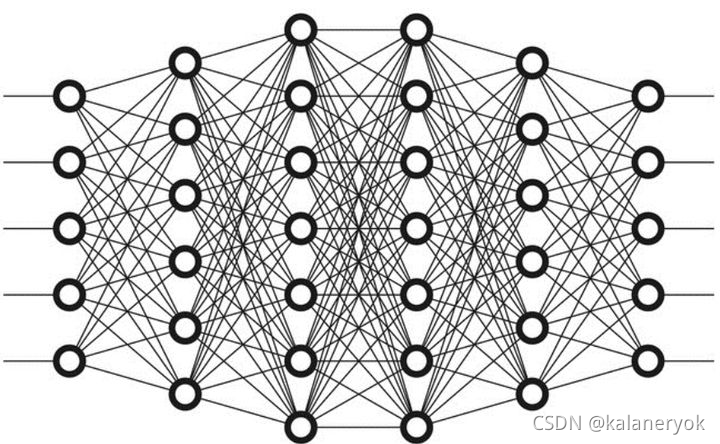
神经网络的计算量非常大,事实上在很长时间里由于基础设施技术的限制进展并不大。而GPU的出现让人看到了曙光,也造就了深度学习的蓬勃发展,“深度学习”才一下子火热起来。击败李世石的Alpha go即是深度学习的一个很好的示例。Google的TensorFlow是开源深度学习系统一个比较好的实现,支持CNN、RNN和LSTM算法,是目前在图像识别、自然语言处理方面最流行的深度神经网络模型。事实上,提出“深度学习”概念的Hinton教授加入了google,而Alpha go也是google家的。在一个新兴的行业,领军人才是多么的重要啊!
详细历史举例
从衰败到繁荣1956年,在达特茅斯会议(Dartmouth Conferences)上,计算机科学家首次提出了“AI”术语,AI由此诞生,在随后的日子里,AI成为实验室的“幻想对象”。几十年过去了,人们对AI的看法不断改变,有时会认为AI是预兆,是未来人类文明的关键,有时认为它只是技术垃圾,只是一个轻率的概念,野心过大,注定要失败。坦白来讲,直到2012年AI仍然同时具有这两种特点。在过去几年里,AI大爆发,2015年至今更是发展迅猛。之所以飞速发展主要归功于GPU的广泛普及,它让并行处理更快、更便宜、更强大。还有一个原因就是实际存储容量无限拓展,数据大规模生成,比如图片、文本、交易、地图数据信息。· · ·AI:让机器展现出人类智力回到1956年夏天,在当时的会议上,AI先驱的梦想是建造一台复杂的机器(让当时刚出现的计算机驱动),然后让机器呈现出人类智力的特征。这一概念就是我们所说的“强人工智能(General AI)”,也就是打造一台超棒的机器,让它拥有人类的所有感知,甚至还可以超越人类感知,它可以像人一样思考。在电影中我们经常会看到这种机器,比如 C-3PO、终结者。还有一个概念是“弱人工智能(Narrow AI)”。简单来讲,“弱人工智能”可以像人类一样完成某些具体任务,有可能比人类做得更好,例如,Pinterest服务用AI给图片分类,Facebook用AI识别脸部,这就是“弱人工智能”。上述例子是“弱人工智能”实际使用的案例,这些应用已经体现了一些人类智力的特点。怎样实现的?这些智力来自何处?带着问题我们深入理解,就来到下一个圆圈,它就是机器学习。· · ·机器学习:抵达AI目标的一条路径大体来讲,机器学习就是用算法真正解析数据,不断学习,然后对世界中发生的事做出判断和预测。此时,研究人员不会亲手编写软件、确定特殊指令集、然后让程序完成特殊任务,相反,研究人员会用大量数据和算法“训练”机器,让机器学会如何执行任务。
机器学习这个概念是早期的AI研究者提出的,在过去几年里,机器学习出现了许多算法方法,包括决策树学习、归纳逻辑程序设计、聚类分析(Clustering)、强化学习、贝叶斯网络等。正如大家所知的,没有人真正达到“强人工智能”的终极目标,采用早期机器学习方法,我们连“弱人工智能”的目标也远没有达到。在过去许多年里,机器学习的最佳应用案例是“计算机视觉”,要实现计算机视觉,研究人员仍然需要手动编写大量代码才能完成任务。研究人员手动编写分级器,比如边缘检测滤波器,只有这样程序才能确定对象从哪里开始,到哪里结束;形状侦测可以确定对象是否有8条边;分类器可以识别字符“S-T-O-P”。通过手动编写的分组器,研究人员可以开发出算法识别有意义的形象,然后学会下判断,确定它不是一个停止标志。这种办法可以用,但并不是很好。如果是在雾天,当标志的能见度比较低,或者一棵树挡住了标志的一部分,它的识别能力就会下降。直到不久之前,计算机视觉和图像侦测技术还与人类的能力相去甚远,因为它太容易出错了。· · ·深度学习:实现机器学习的技术“人工神经网络(Artificial Neural Networks)”是另一种算法方法,它也是早期机器学习专家提出的,存在已经几十年了。神经网络(Neural Networks)的构想源自于我们对人类大脑的理解——神经元的彼此联系。二者也有不同之处,人类大脑的神经元按特定的物理距离连接的,人工神经网络有独立的层、连接,还有数据传播方向。例如,你可能会抽取一张图片,将它剪成许多块,然后植入到神经网络的第一层。第一层独立神经元会将数据传输到第二层,第二层神经元也有自己的使命,一直持续下去,直到最后一层,并生成最终结果。每一个神经元会对输入的信息进行权衡,确定权重,搞清它与所执行任务的关系,比如有多正确或者多么不正确。最终的结果由所有权重来决定。以停止标志为例,我们会将停止标志图片切割,让神经元检测,比如它的八角形形状、红色、与众不同的字符、交通标志尺寸、手势等。神经网络的任务就是给出结论:它到底是不是停止标志。神经网络会给出一个“概率向量”,它依赖于有根据的推测和权重。在该案例中,系统有86%的信心确定图片是停止标志,7%的信心确定它是限速标志,有5%的信心确定它是一支风筝卡在树上,等等。然后网络架构会告诉神经网络它的判断是否正确。即使只是这么简单的一件事也是很超前的,不久前,AI研究社区还在回避神经网络。在AI发展初期就已经存在神经网络,但是它并没有形成多少“智力”。问题在于即使只是基本的神经网络,它对计算量的要求也很高,因此无法成为一种实际的方法。尽管如此,还是有少数研究团队勇往直前,比如多伦多大学Geoffrey Hinton所领导的团队,他们将算法平行放进超级电脑,验证自己的概念,直到GPU开始广泛采用我们才真正看到希望。回到识别停止标志的例子,如果我们对网络进行训练,用大量的错误答案训练网络,调整网络,结果就会更好。研究人员需要做的就是训练,他们要收集几万张、甚至几百万张图片,直到人工神经元输入的权重高度精准,让每一次判断都正确为止——不管是有雾还是没雾,是阳光明媚还是下雨都不受影响。这时神经网络就可以自己“教”自己,搞清停止标志的到底是怎样的;它还可以识别Facebook的人脸图像,可以识别猫——吴恩达(Andrew Ng)2012年在谷歌做的事情就是让神经网络识别猫。吴恩达的突破之处在于:让神经网络变得无比巨大,不断增加层数和神经元数量,让系统运行大量数据,训练它。吴恩达的项目从1000万段YouTube视频调用图片,他真正让深度学习有了“深度”。到了今天,在某些场景中,经过深度学习技术训练的机器在识别图像时比人类更好,比如识别猫、识别血液中的癌细胞特征、识别MRI扫描图片中的肿瘤。谷歌AlphaGo学习围棋,它自己与自己不断下围棋并从中学习。
·有了深度学习AI的未来一片光明有了深度学习,机器学习才有了许多实际的应用,它还拓展了AI的整体范围。 深度学习将任务分拆,使得各种类型的机器辅助变成可能。无人驾驶汽车、更好的预防性治疗、更好的电影推荐要么已经出现,要么即使出现。AI既是现在,也是未来。有了深度学习的帮助,也许到了某一天AI会达到科幻小说描述的水平,这正是我们期待已久的。你会有自己的C-3PO,有自己的终结者。