IDEA开发SparkSQL
上一篇博客SparkSQL核心编程所有举的例子都是在虚拟机的命令行实现的,但是实际开发中,都是使用 IDEA 进行开发的,所以下面介绍下SparkSQL在IDEA中的使用。
准备工作
添加所需要的依赖(包括spark-core依赖,spark-sql依赖,mysql-connector-java依赖)
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>3.0.0</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.49</version>
</dependency>
SparkSQL核心编程在IDEA中实现
SparkSQL核心编程的介绍参照上一篇博客上一篇博客
代码实现
package com.atguigu.bigdata.spark.sql
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{
DataFrame, Dataset, Row, SparkSession}
object Spark01_SparkSQL_Basic {
def main(args: Array[String]): Unit = {
//TODO 创建SparkSQL的运行环境
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkSQL")
val spark = SparkSession.builder().config(sparkConf).getOrCreate()
//TODO 执行逻辑操作
//RDD
//DataFrame
// val df: DataFrame = spark.read.json("datas/user.json")
//df.show()
//DataFrame => SQL
// df.createOrReplaceTempView("user")
// spark.sql("select * from user").show()
// spark.sql("select age,username from user").show()
// spark.sql("select avg(age) from user").show()
//DataFrame => DSL
//在使用DataFrame时,如果涉及到转换操作,需要引入转换规则
// import spark.implicits._
// df.select("age","username").show()
// df.select($"age" + 1).show()
// df.select('age + 1).show()
//DataSet
//DataFrame其实是特定泛型的DataSet
// import spark.implicits._
// val seq = Seq(1,2,3,4)
// val ds: Dataset[Int] = seq.toDS()
// ds.show()
//RDD<=> DataFrame
import spark.implicits._
val rdd = spark.sparkContext.makeRDD(List((1,"zhangsan",20),(2,"lisi",30)))
val df: DataFrame = rdd.toDF("id", "name", "age")
val rowRDD: RDD[Row] = df.rdd
//DataFrame<=>DataSet
val ds: Dataset[User] = df.as[User]
val df1: DataFrame = ds.toDF()
//DataSet<=>RDD
val ds1 = rdd.map {
case (id,name,age) => {
User(id,name,age)
}
}.toDS()
val userRDD: RDD[User] = ds1.rdd
//TODO 关闭环境
spark.close()
}
case class User(id: Int, name: String, age: Int)
}
用户自定义函数
SparkSQL自带的函数并不能完全满足实际开发中的需求,为了解决这样一个问题,在SparkSQL中用户可以通过 spark.udf 功能添加自定义函数,实现自定义功能。
1. UDF
UDF是sparkSQL中用户自定义函数,用法和sparkSQL中的内置函数类似;是saprkSQL中内置函数无法满足要求,用户根据业务需求自定义的函数。
使用UDF自定义函数案例
package com.atguigu.bigdata.spark.sql
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
object Spark02_SparkSQL_UDF {
def main(args: Array[String]): Unit = {
//TODO 创建SparkSQL的运行环境
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkSQL")
val spark = SparkSession.builder().config(sparkConf).getOrCreate()
//TODO 执行逻辑操作
val df = spark.read.json("datas/user.json")
df.createOrReplaceTempView("user")
//自定义函数(但是createOrReplaceGlobalTempView不行)
spark.udf.register("prefixName", (name: String) => {
"Name: " + name
})
spark.sql("select age, prefixName(username) from user").show
//TODO 关闭环境
spark.close()
}
}
2. UDAF
强类型的 Dataset 和弱类型的 DataFrame 都提供了相关的聚合函数, 如 count(),countDistinct(),avg(),max(),min()。除此之外,用户可以设定自己的自定义聚合函数。通过继承 UserDefinedAggregateFunction 来实现用户自定义弱类型聚合函数。从 Spark3.0 版本后,UserDefinedAggregateFunction 已经不推荐使用了。可以统一采用强类型聚合函数Aggregator 。
使用UDAF自定义聚合函数类案例
package com.atguigu.bigdata.spark.sql
import org.apache.spark.SparkConf
import org.apache.spark.sql.expressions.{
MutableAggregationBuffer, UserDefinedAggregateFunction}
import org.apache.spark.sql.types.{
DataType, LongType, StructField, StructType}
import org.apache.spark.sql.{
Row, SparkSession}
object Spark03_SparkSQL_UDAF {
def main(args: Array[String]): Unit = {
//TODO 创建SparkSQL的运行环境
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkSQL")
val spark = SparkSession.builder().config(sparkConf).getOrCreate()
//TODO 执行逻辑操作
val df = spark.read.json("datas/user.json")
df.createOrReplaceTempView("user")
//自定义函数(但是createOrReplaceGlobalTempView不行)
spark.udf.register("ageAvg", new MyAvgUDAF)
spark.sql("select ageAvg(age) from user").show
//TODO 关闭环境
spark.close()
}
/*
自定义聚合函数类:计算年龄的平均值
1.继承UserDefinedAggregateFunction
2.重写方法
*/
class MyAvgUDAF extends UserDefinedAggregateFunction {
//输入数据的结构
override def inputSchema: StructType = {
StructType(
Array(
StructField("age",LongType)
)
)
}
//缓冲区数据的结构
override def bufferSchema: StructType = {
StructType(
Array(
StructField("total",LongType),
StructField("count",LongType)
)
)
}
//函数计算结果的类型
override def dataType: DataType = LongType
//函数的稳定性
override def deterministic: Boolean = true
//缓冲区初始化
override def initialize(buffer: MutableAggregationBuffer): Unit = {
// buffer(0) = 0L
// buffer(1) = 0L
buffer.update(0,0L)
buffer.update(1,0L)
}
//根据输入的值来更新缓冲区数据
override def update(buffer: MutableAggregationBuffer, input: Row): Unit = {
buffer.update(0,buffer.getLong(0) + input.getLong(0))
buffer.update(1,buffer.getLong(1) + 1)
}
//缓冲区数据合并
override def merge(buffer1: MutableAggregationBuffer, buffer2: Row): Unit = {
buffer1.update(0, buffer1.getLong(0) + buffer2.getLong(0))
buffer1.update(1, buffer1.getLong(1) + buffer2.getLong(1))
}
//计算平均值
override def evaluate(buffer: Row): Any = {
buffer.getLong(0) / buffer.getLong(1)
}
}
}
数据的加载和保存
通用的加载和保存方式
SparkSQL 提供了通用的保存数据和数据加载的方式。这里的通用指的是使用相同的API,根据不同的参数读取和保存不同格式的数据,SparkSQL 默认读取和保存的文件格式为 parquet。
(1)加载数据
spark.read.load 是加载数据的通用方法

如果读取不同格式的数据,可以对不同的数据格式进行设定
scala> spark.read.format("…")[.option("…")].load("…")
- format("…"):指定加载的数据类型,包括"csv"、“jdbc”、“json”、“orc”、“parquet"和"textFile”。
- load("…"):在"csv"、“jdbc”、“json”、“orc”、"parquet"和"textFile"格式下需要传入加载数据的路径。
- option("…"):在"jdbc"格式下需要传入 JDBC 相应参数,url、user、password 和 dbtable 我们前面都是使用 read API 先把文件加载到 DataFrame 然后再查询,其实,我们也可以直接在文件上进行查询:
文件格式.` 文件路径 `
(2)保存数据
df.write.save 是保存数据的通用方法

如果保存不同格式的数据,可以对不同的数据格式进行设定
scala>df.write.format("…")[.option("…")].save("…")
- format("…"):指定保存的数据类型,包括"csv"、“jdbc”、“json”、“orc”、"parquet"和
“textFile”。 - save ("…"):在"csv"、“orc”、"parquet"和"textFile"格式下需要传入保存数据的路径。
- option("…"):在"jdbc"格式下需要传入 JDBC 相应参数,url、user、password 和 dbtable 保存操作可以使用 SaveMode, 用来指明如何处理数据,使用 mode()方法来设置。
注: 这些 SaveMode 都是没有加锁的, 也不是原子操作。
SaveMode 是一个枚举类,其中的常量包括:
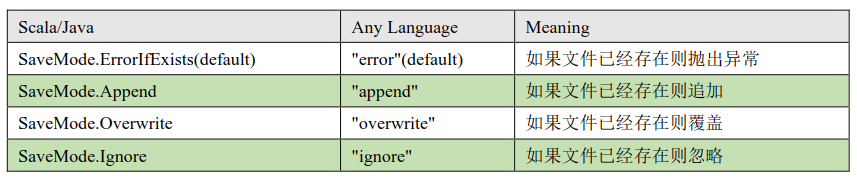
注:以下三种使用较少
Parquet
Spark SQL 的默认数据源为 Parquet 格式。Parquet 是一种能够有效存储嵌套数据的列式存储格式。
数据源为 Parquet 文件时,Spark SQL 可以方便的执行所有的操作,不需要使用 format。修改配置项 spark.sql.sources.default,可修改默认数据源格式。
(1)加载数据
scala> val df = spark.read.load("examples/src/main/resources/users.parquet")
scala> df.show
(2)保存数据
scala> var df = spark.read.json("/opt/module/data/input/people.json")
//保存为 parquet 格式
scala> df.write.mode("append").save("/opt/module/data/output")
JSON
Spark SQL 能够自动推测 JSON 数据集的结构,并将它加载为一个 Dataset[Row]. 可以通过 SparkSession.read.json()去加载 JSON 文件。
注意:Spark 读取的 JSON 文件不是传统的 JSON 文件,每一行都应该是一个 JSON 串。格式如下:
{
"name":"Michael"}
{
"name":"Andy", "age":30}
[{
"name":"Justin", "age":19},{
"name":"Justin", "age":19}]
(1)导入隐式转换
import spark.implicits._
(2)加载 JSON 文件
val path = "/opt/module/spark-local/people.json"
val peopleDF = spark.read.json(path)
(3)创建临时表
peopleDF.createOrReplaceTempView("people")
(4)数据查询
val teenagerNamesDF = spark.sql("SELECT name FROM people WHERE age BETWEEN 13
AND 19")
teenagerNamesDF.show()
+------+
| name|
+------+
|Justin|
+------+
CSV
Spark SQL 可以配置 CSV 文件的列表信息,读取 CSV 文件,CSV 文件的第一行设置为数据列
spark.read.format("csv").option("sep", ";").option("inferSchema",
"true").option("header", "true").load("data/user.csv")
MySQL
Spark SQL 可以通过 JDBC 从关系型数据库中读取数据的方式创建 DataFrame,通过对DataFrame 一系列的计算后,还可以将数据再写回关系型数据库中。如果使用 spark-shell 操作,可在启动 shell 时指定相关的数据库驱动路径或者将相关的数据库驱动放到 spark 的类路径下。
bin/spark-shell
--jars mysql-connector-java-5.1.27-bin.jar
下面演示下在IDEA中通过JDBC对Mysql进行操作
(1)导入相关依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>3.0.0</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.49</version>
</dependency>
(2)案例实操
df.write.mode("append").json("/opt/module/spark-lcoal/data/output")
package com.atguigu.bigdata.spark.sql
import org.apache.spark.SparkConf
import org.apache.spark.sql._
object Spark04_SparkSQL_JDBC {
def main(args: Array[String]): Unit = {
//TODO 创建SparkSQL的运行环境
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkSQL")
val spark = SparkSession.builder().config(sparkConf).getOrCreate()
//TODO 执行逻辑操作
//读取MySql数据
val df = spark.read
.format("jdbc")
.option("url", "jdbc:mysql://192.168.121.102:3306/spark-sql")
.option("driver", "com.mysql.jdbc.Driver")
.option("user", "root")
.option("password", "xxxxx")
.option("dbtable", "user")
.load()
df.show
//保存数据
// df.write
// .format("jdbc")
// .option("url", "jdbc:mysql://192.168.121.102:3306/spark-sql")
// .option("driver", "com.mysql.jdbc.Driver")
// .option("user", "root")
// .option("password", "xxxxx")
// .option("dbtable", "user1")
// .mode(SaveMode.Append)
// .save()
//TODO 关闭环境
spark.close()
}
}