创建GraphSage模型:
input_size=1433
out_size=128
num_layers=2
agg_func='MEAN'
raw_features:原始特征,维度2708 * 1433
adj_lists:所有边的连接,格式是:562: {60, 252, 370, 440, 671, 1117, 1183, 1401, 1889, 2014, 2018},
sage_layer1:SageLayer
sage_layer2:SageLayer(layer_size=128,out_size=128)
第一层sage_layer1:
input_size=1433
out_size=128
weight:权重参数,并初始化,维度128 * (1433*2)=128 * 2866
第二层sage_layer2:
input_size=128
out_size=128
weight:权重参数,并初始化,维度128 * (128*2)=128 * 256
创建Classification模型:
self.layer=全连接层
weight:权重参数,并初始化,维度128 * 7
进入GraphSage中的前向传播forward:
第一批20个节点数据
nodes_batch={1, 16, 131, 245, 439, 501, 527, 658, 699, 716, 944, 963, 1003, 1081, 1439, 1582, 1660, 1681, 2007, 2577}
得到nodes_batch_layers,内容如下:
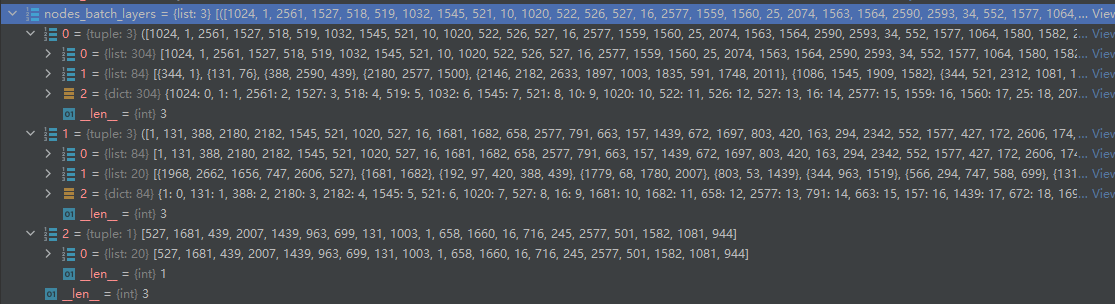
# [1, 16, 131, 245, 439, 501, 527, 658, 699, 716, 944, 963, 1003, 1081, 1439, 1582, 1660, 1681, 2007, 2577}]
nodes_batch_layers[2][0]:原始batch的20个数据节点list
# [1, 131, 388, 2180, 2182, 1545, 521, 1020, 527, 16, 1681, 1682, 658, 2577, 791, 663, 157, 1439, 672, 1697, 803, 420, 163, 294, 2342, 552, 1577, 427, 172, 2606, 174, 1968, 1582, 944, 2483, 53, 566, 439, 952, 1081, 1082, 699, 1083, 1469, 1086, 2367, 192, 1337, 1335, 963, 68, 588, 76, 716, 2508, 466, 1364, 2007, 344, 97, 2146, 611, 1636, 2017, 2662, 1897, 747, 1003, 1004, 2028, 1519, 496, 632, 1259, 1779, 1780, 245, 501, 503, 1656, 1908, 2677, 1909, 1660]
nodes_batch_layers[1][0]:与20个节点相连的84个邻居节点list,包含上一层原始的20个节点
# [{527, 747, 1656, 1968, 2606, 2662},
# {1681, 1682},
# {97, 192, 388, 420, 439},
# {68, 1779, 1780, 2007},
# {53, 803, 1439},
# {344, 963, 1519},
# {294, 566, 588, 699, 747},
# {76, 131},
# {672, 791, 1003, 1004, 1364, 1469, 1897, 2028, 2146, 2182, 2483},
# {1, 344},
# {163, 427, 658, 1577},
# {952, 1083, 1660},
# {16, 466, 552, 566, 1697},
# {157, 611, 716},
# {172, 245, 1636},
# {1020, 2180, 2342, 2367, 2508, 2577},
# {174, 496, 501, 503, 663},
# {632, 1086, 1545, 1582, 1908, 1909, 2017, 2677},
# {521, 1081, 1082, 1259},
# {944, 1335, 1337}]
nodes_batch_layers[1][1]:与20个节点相连邻居节点
{1: 0,
# 131: 1,
# 388: 2,
# 2180: 3,
# 2182: 4,
# 1545: 5,
# 521: 6,
# 1020: 7,
# 527: 8,
# 16: 9,
# 1681: 10,
# 1682: 11,
# 658: 12,
# 2577: 13,
# 791: 14,
# 663: 15,
# 157: 16,
# 1439: 17,
# 672: 18,
# 1697: 19,
# 803: 20,
# 420: 21,
# 163: 22,
# 294: 23,
# 2342: 24,
# 552: 25,
# 1577: 26,
# 427: 27,
# 172: 28,
# 2606: 29,
# 174: 30,
# 1968: 31,
# 1582: 32,
# 944: 33,
# 2483: 34,
# 53: 35,
# 566: 36,
# 439: 37,
# 952: 38,
# 1081: 39,
# 1082: 40,
# 699: 41,
# 1083: 42,
# 1469: 43,
# 1086: 44,
# 2367: 45,
# 192: 46,
# 1337: 47,
# 1335: 48,
# 963: 49,
# 68: 50,
# 588: 51,
# 76: 52,
# 716: 53,
# 2508: 54,
# 466: 55,
# 1364: 56,
# 2007: 57,
# 344: 58,
# 97: 59,
# 2146: 60,
# 611: 61,
# 1636: 62,
# 2017: 63,
# 2662: 64,
# 1897: 65,
# 747: 66,
# 1003: 67,
# 1004: 68,
# 2028: 69,
# 1519: 70,
# 496: 71,
# 632: 72,
# 1259: 73,
# 1779: 74,
# 1780: 75,
# 245: 76,
# 501: 77,
# 503: 78,
# 1656: 79,
# 1908: 80,
# 2677: 81,
# 1909: 82,
# 1660: 83}
nodes_batch_layers[1][2]:84个节点进行dict编号
nodes_batch_layers[0][0]:与84个节点相连的304个邻居节点list,包含84个自身节点
nodes_batch_layers[0][1]:84个节点的邻居节点list
nodes_batch_layers[0][2]:304个节点的dict自编编号
接下来进行aggregation操作:
index=1
nb = 自己和邻居节点list 共84个
pre_neighs = 这层节点的上层邻居的所有信息,包括:聚合自己和邻居节点,点的dict,涉及到的所有节点
aggregation:
参数:nodes,当前节点list 84个
参数:pre_hidden_embs,数据特征,维度:2708 * 1433
参数:pre_neighs,上层邻居的所有信息
embed_matrix:当前304个节点的特征,304*1433
mask:构建 84*304 的邻接矩阵,并且进行归一化mask=mask/mask.sum(dim=1),
aggregate_feats:聚合邻居特征,mask * embed_matrix ,生成维度84*1433
总结:当前节点84个,聚合了周围304个邻居节点的特征,对特征进行归一化,生成特征维度84*1433
sageLayer:
参数:self_feats=原始特征 维度84*1433
参数:aggregate_feats=聚合了304个邻居的特征 维度84*1433
combined:将这两个特征进行拼接,生成维度84*2866
F.relu(combined * W),进行激活函数生成维度84*128的特征
返回特征 84*128
index=2
nb=最初的20个节点
pre_neighs=这层节点的上层邻居的所有信息,包括:聚合自己和邻居节点,点的dict,涉及到的所有节点
aggregation:
参数:nodes,当前节点list 20个
参数:pre_hidden_embs,数据特征,维度:84*128
参数:pre_neighs,上层邻居的所有信息
embed_matrix:=pre_hidden_embs 利用上一层的节点特征,即84个节点的特征,84*128
mask:构建 20*84 的邻接矩阵,并且进行归一化mask=mask/mask.sum(dim=1),
aggregate_feats:聚合邻居特征,mask * embed_matrix ,生成维度20*128
总结:当前节点20个,聚合了周围84个邻居节点的特征,(这84个邻居节点特征是上一层计算得到的,因此维度是84*128,而不是84*1433),对特征进行归一化,最终生成特征维度20*128
sageLayer:
参数:self_feats=原始特征 维度20*128
参数:aggregate_feats=聚合了20个邻居的特征 维度20*128
combined:将这两个特征进行拼接,生成维度20*256
F.relu(combined * W),进行激活函数生成维度20*128的特征
最终这20个节点返回特征 20*128
接下来就要通过Classification模型进行计算,得到维度20 * 7
logists=
tensor([[-1.9839, -1.9866, -2.0804, -1.9014, -1.8841, -1.7800, -2.0367],
[-1.9142, -1.9110, -2.0967, -1.8599, -2.0505, -1.8341, -1.9832],
[-1.9683, -1.9229, -1.9720, -1.9572, -1.9711, -1.8678, -1.9667],
[-1.9209, -2.0136, -2.0654, -1.8666, -1.9862, -1.8006, -1.9937],
[-2.0788, -2.0250, -1.9542, -1.8534, -1.8923, -1.8745, -1.9634],
[-2.0361, -1.8748, -2.0676, -1.8287, -1.9016, -1.8289, -2.1284],
[-2.0782, -1.8997, -1.9607, -1.9720, -1.9491, -1.9568, -1.8227],
[-2.0626, -1.8991, -2.0198, -1.8183, -1.9802, -1.8021, -2.0779],
[-1.9372, -1.8791, -1.9737, -1.9121, -1.9777, -1.8976, -2.0547],
[-2.0668, -1.9538, -1.9821, -1.8051, -2.0310, -1.8033, -2.0139],
[-2.0350, -1.9644, -1.9913, -1.8626, -1.9652, -1.8815, -1.9324],
[-2.0077, -1.8961, -2.0062, -2.0043, -1.8142, -1.8510, -2.0695],
[-1.9880, -1.9198, -1.9179, -1.8831, -1.9339, -2.0266, -1.9590],
[-2.0564, -1.9405, -1.9988, -1.8407, -1.8986, -1.9623, -1.9384],
[-2.0603, -1.9230, -1.9647, -1.8786, -1.9230, -1.9342, -1.9470],
[-2.0483, -1.9780, -2.0290, -1.9329, -1.8557, -1.8542, -1.9407],
[-1.9123, -1.9745, -1.9420, -1.9195, -1.9199, -1.9526, -2.0038],
[-2.0144, -1.9391, -1.9132, -1.8205, -1.9620, -1.9279, -2.0622],
[-2.1094, -1.7795, -2.0029, -1.8137, -2.0519, -1.8241, -2.1027],
[-2.0052, -1.9684, -2.0337, -1.8064, -1.9325, -1.8070, -2.1065]],
loss_sup = -torch.sum(logists[range(logists.size(0)), labels_batch], 0) 根据label获取对应的loss值求和
= tensor([-1.9839, -1.8599, -1.9683, -2.0654, -1.8745, -1.8748, -1.9607, -1.8183,
-1.9777, -1.9538, -1.8815, -2.0043, -1.9179, -2.0564, -1.9470, -1.9329,
-1.9123, -1.8205, -1.7795, -1.8064], grad_fn=<IndexBackward>)
loss_sup /= len(nodes_batch)
=1.9198
这样第一批数据的20个节点就计算完成了:
array([ 527, 1681, 439, 2007, 1439, 963, 699, 131, 1003, 1, 658,
1660, 16, 716, 245, 2577, 501, 1582, 1081, 944])
Step [1/68], Loss: 1.9198, Dealed Nodes [20/1355]