Foreword: HDFS is a distributed storage framework, which can provide a large amount of support for big data computing frameworks (MR and spark) in the memory access of big data, but if you want to quickly and conveniently handle small items in a big data For access, it becomes not easy to implement on hdfs, so Apache HBase is a technical framework specifically for this problem.
One: About
Hbase 1. Introduction to Hbase:
HBase is an open source, distributed, multi-version, column-oriented non-relational database built on BigTable . It is designed to provide high reliability, high performance, column storage, scalable, multi-version NoSQL distributed data storage system, to achieve real-time, random read and write access to large data.
2. HBase features
1). The large amount of data in the table, linear and modular scalability, so that a table can reach billions of rows and millions of columns.
2). Hbase integrates with HDFS, Hbase supports HDFS as its distributed file system, Hbase integrates with MR, and Hbase supports MR for reading and large-scale parallel processing. 3). Automatic table segmentation: Hbase is distributed and stored in the server cluster with Region as the unit. When the table data increases to the size of the Region, the Region will be automatically split into two regions through the middle key and automatically allocated to the cluster.
4). Column-oriented storage: cut files by column, column (family) independent retrieval, data in Hbase are all strings, no type, data in each unit can have multiple versions, by default the version number is automatic Assignment is the timestamp when the cell is inserted .
Two: Hbase data model
In Hbase, data is stored in a table with rows and columns. This seems to be similar to a relational database (RDBMS), but it is not the case. Relational databases use rows and columns to uniquely determine the value to be searched, while in Hbase, a unique value is determined by row key, column (column: column modifier) and timestamp. Therefore, the mapping relationship of the values in the table of the relational database is two-dimensional, and the mapping relationship in the Hbase table is multi-dimensional. Let's talk about the logical structure and physical storage structure in Hbase respectively.
1. Logical structure
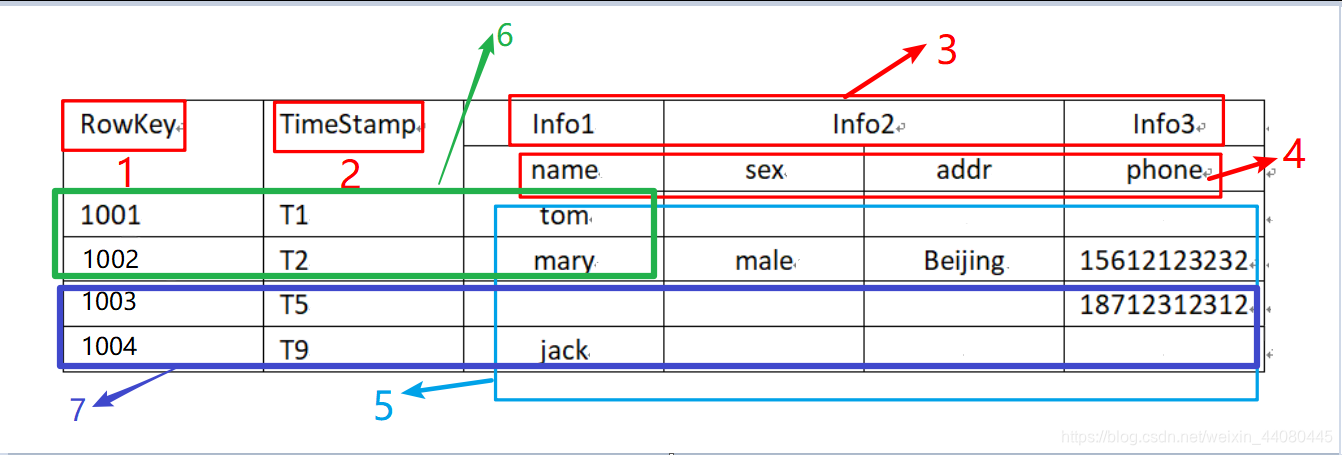
Let's talk about the various parts of the table:
(1). RowKey:
Like nosql databases, row key is the primary key used to retrieve records, and the rowkey of each data must be unique and not repeated. Access the rows in the Hbase table. The Hbase table is sorted by key, and all tables must have RowKey.
(2).Time Stamp:
Used to identify different versions of the data. When each piece of data is written, if a timestamp is not specified, the system will automatically add this field to it, and its value is the time when it was written to HBase.
(3). Column Family:
Each column in HBase is defined by Column Family and Column Qualifier, such as info1: name, info2: age. When building a table, you only need to specify the column family, and the column modifiers do not need to be defined in advance.
(4). Column qualifier:
There is a column qualifier under each column family, and the column qualifier can be dynamically added and deleted.
(5). Value (also called cell):
the smallest cell uniquely determined by {rowkey, column Family: column Qualifier, time Stamp}. For example, Tom is determined by the union of {1001, T1, Info1, name}.
(6).store:
Each region consists of one or more stores, at least one store, hbase will put the data accessed together in one store, that is, create a store for each ColumnFamily (that is, there are several ColumnFamily, There are also a few stores).
(7).Region:
similar to the table concept of relational database. The difference is that HBase only needs to declare the column family when defining the table, and there is no need to declare specific columns. This means that when writing data to HBase, fields can be specified dynamically and on demand. Therefore, compared with relational databases, HBase can easily cope with field changes.
2. Physical storage structure
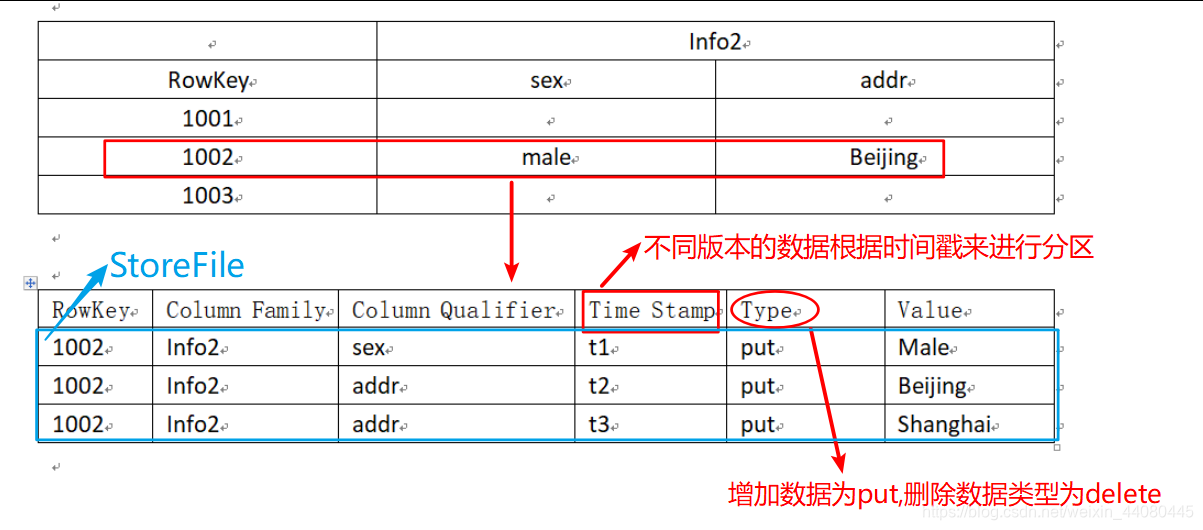
Three: Hbase architecture principle
The server architecture of HBase follows a simple master-slave server architecture, which consists of HRegion Server group and HBase Master server . Among them, the HBase Master server is equivalent to the administrator of the cluster, responsible for managing all HRegion Servers, and the HRegion Server is equivalent to many employees of the administrator. All servers in HBase use ZooKeeper to coordinate and handle errors that may be encountered during the operation of the HBase server. HMaster itself does not store any data in HBase. Logical tables in HBase may be divided into multiple HRegions.
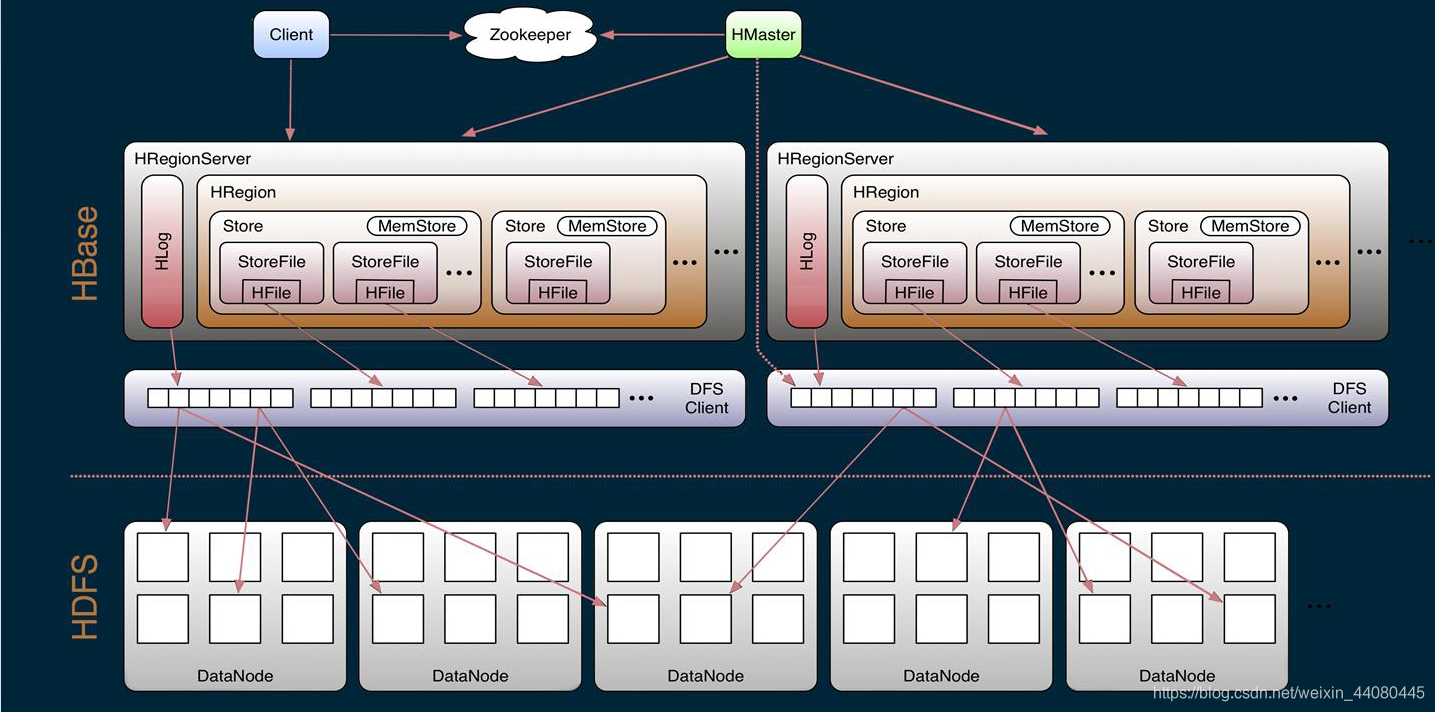
1.Client:
HBase Client uses HBase's RPC mechanism (communication mechanism) to communicate with HMaster and HRegion Server. For DDL operations, Client and HMaster perform RPC; for DML operations, Client and HRegion Server perform RPC . HBase Client finds the Region Server that is being served through the meta table. After finding the required Region, the Client contacts the Region Server serving the Region instead of the Master, and sends a read or write request. This information is cached on the Client side, so that subsequent requests can be used directly without going through the search process. If the Region is reassigned by the main load balancer or the Region Server has died, the client will re-query the directory table to determine the new location of the user's Region.
2. Zookeeper:
1). Ensure that there is only one active master in the cluster at any time, because multiple Masters will be started to ensure safety. In this way, the master solves the problem of single point of failure due to the existence of zookeeper.
2). Each Region Server registers its own temporary node on ZK, so ZK stores the addressing entries of all Regions. Know which machine the Region is on.
3). Monitor the status of the Region Server in real time, and report the online and offline information of the Region Server to HMaster. , And report the online and offline information of the Region Server to HMaster. (Because at intervals, RegionServer and Master will send heartbeat information to zookeeper). The reason why Region Server does not send information directly to Master is to reduce the pressure of Master. Because there is only one active Master, all RegionServers report information and pressure to him at the same time. Too big. And if there are 100 RegionServers, Region Servers can report information to a zookeeper for every 10, to achieve load balancing of zookeeper
4). The metadata (Schema) of storing Hbase includes, knowing which tables are in the entire Hbase cluster, each What column families does the Table have?
3. Hmaster:
1). Assign HRegion to HRegion Server and monitor the status of each HRegion Server.
2). Responsible for load balancing
of HRegionServer. 3). Find invalid HRegionServer and redistribute it
4.
Region Server: The Region Server is the manager of the Region. It stores a large number of Regions. Its implementation class is HRegionServer. Its main functions are as follows: For data operations (mainly DML): get, put, delete; for Region Operation: splitRegion, compactRegion (split and merge the table).
5.Region:
For users, each table is a collection of a bunch of data, distinguished by the primary key RowKey, and RowKey is sorted in dictionary order within the system. When the size of the table in HBase exceeds the set value, HBase will use the RowKey key in the middle to split the table horizontally into two Regions. For this part, see the above content (2: The seventh part of the logical structure of the Hbase data model)
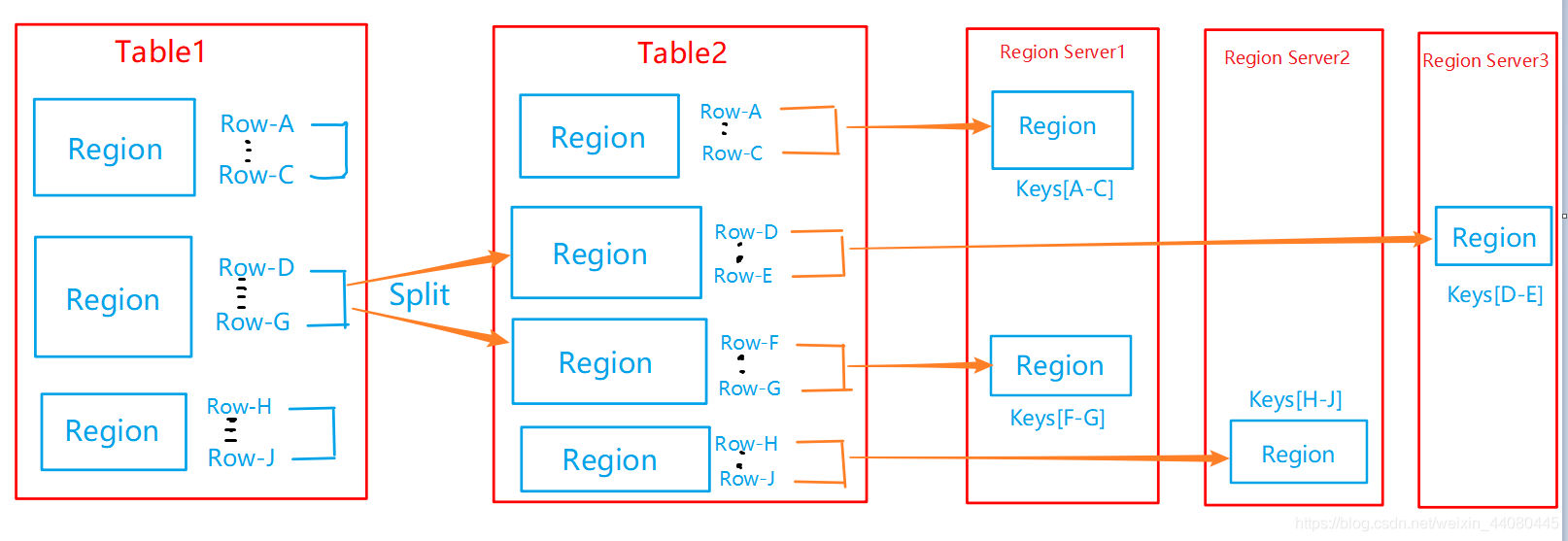
***Region拆分过程***
Physically speaking, the table created in HBase is originally a Region. As the number of table records increases, the resources occupied by the table content increase. When the specified reading value is increased, a table is split into two pieces, each of which is An HRegion. By analogy, as the number of table records increases and becomes larger, it will gradually split into several HRegions. When Tablel shown in Figure 8-8 is 3 Regions, as the value of RowKeyD~G increases, when the value of the Region reaches the national value, the region will be split by pressing the middle key to generate two new Regions , RowKey range is Row-D~E, Row-F~G respectively. Each HRegion will store a certain piece of continuous data in a table. From the start primary key to the end primary key, a complete table is stored on multiple HRegions, that is, each Region is represented by [startkey, endkey]. Different Regions will be assigned by the Master to the corresponding Region Server for management . It can be said that Region is the smallest unit of distributed storage.
The hierarchy of Regions is as follows.
Table (Hbase table)
|----Region (Multiple Regions form Table)
|--------Store (a Colomn Family stored in a Region in the Table)
|------ -----MemStore (each store in each Region has one MemStore)
|-----------StoreFile (each store in each Region has multiple StoreFiles)
|---- ---------------Block (There are multiple Blocks in each StoreFile)
6. HLog:
WAL (Write-Ahead-Log) pre-write log is a kind of log used by Hbase RegionServer to record operation content during the process of processing data insertion and deletion. Each time a record such as Put, Delete, etc., the data is first written to the HLog file corresponding to the RegionServer. When the client submits data to the RegionServer, it will write the WAL log first. Only when the WAL log is successfully written, The client will be told that the data submission is successful. If writing the WAL fails, the client will be notified that the submission failed. In other words, this is actually a process of data landing. The function of hLog is that when a Region Server is shut down, it can take out the log recorded by itself for data recovery.
7. HStore:
HStore is the core of HBase storage and consists of two parts, one is MemStore and the other is StoreFile. MemStore is Sorted Memory Buffer. The data written by the user will first be put into the MemStore. When the MemStore is full, it will be flushed into a StoreFile (the underlying implementation is HFile). When the number of StoreFile files grows to a certain national value, the Compact merge operation will be triggered. Combine multiple StoreFiles into one StoreFile. During the merging process, version merging and data deletion will be carried out. When StoreFile Compact, a larger and larger StoreFile will be gradually formed. When the size of a single StoreFile exceeds a certain national value, the Split operation will be triggered and the current Region will be split into two at the same time. Region (see the region split process in the above figure for this process), the parent region will go offline, and the two newly split child regions will be allocated to the corresponding HRegion Server by HMaster, so that the pressure of the original one region can be divided to two Region.
Four: Hbase installation and deployment:
https://blog.csdn.net/weixin_44080445/article/details/107436127