One shot learning is a classification task that uses one or several samples to classify many samples in the future.
This is a common task in the field of face recognition, such as face recognition and face authentication. In these tasks, people must be given different facial expressions, lighting conditions, jewelry and hairstyles in one or several sample photos. The face is classified correctly.
Modern face recognition systems solve the problem of single-sample learning through face recognition by learning a rich low-dimensional feature representation method (called face embedding). This low-dimensional feature representation can easily calculate faces and compare them in verification and recognition tasks.
Historically, embedding has solved the single-shot learning problem through the use of a Siamese network. By training the twin network with the Comparative Loss function, better performance was obtained, which later led Google to use the Triplet Loss function in the FaceNet system. This function achieved the benchmark face recognition task The most advanced result at the time.
In this article, I will explain the challenges of single-sample learning in face recognition, and how to use contrast loss and triple loss functions to learn high-quality face embeddings.
After reading this article, you will learn:
Single-sample learning is a classification task that makes many predictions for a given one (or several) samples of each class, and face recognition is an example of single-sample learning.
Siamese network is a method to solve single-sample learning by comparing the learning feature vectors of known samples and candidate samples.
The contrast loss function and the subsequent triple loss function can be used to learn high-quality face embedding vectors, which provides a basis for modern face recognition systems.
Closer to home.
Overview
This article will be divided into four parts:
Single sample learning and face recognition
Siamese network for one-shot learning
Contrast loss for dimensionality reduction
Triple loss for learning face embedding
Single sample learning and face recognition
Generally, classification involves fitting a model given multiple samples of each class, and then using the fitted model to make predictions for many samples of each class.
For example, we may have performed thousands of measurements on plants of three different species. The model can be applied to these samples, summarizing the commonalities between the measurement results of a given species, and comparing the differences between the measurement results of different species.
单样本学习是一种分类任务,其中每个类都有一个样本(或极少数样本),用于准备模型训练,然后模型反过来又必须对未来的许多未知样本进行预测。
在单样本学习的情况下,向算法提供了一个对象类的单一样本。
——《Knowledge transfer in learning to recognize visual ibjects classes》,2006 年
对人类来说,这是一个相对容易的问题。例如,一个人可能有一次见过一辆法拉利跑车,那么在未来,他能够在新的情况下,比如在路上,在电影里,在图书中以及在不同的光照和颜色的情况下,能够认出法拉利跑车。
人类在几乎没有监督的情况下学习新概念,例如,一个小孩可以从书中的一张图片概括出“长颈鹿”的概念,但我们目前最好的深度学习系统就需要成百上千的样本才能学会。
《Matching Network for One Shot Learning》,2017 年
单样本学习与零样本学习相关,但又有所不同。
这应该区别于零样本学习,在零样本学习中,模型并不能查看目标类的任何样本。
《Siamese Neural Networks for One-shot Image Recognition》,2015 年
人脸识别任务提供了单样本学习的样本。
具体来说,在人脸识别的情况下,模型或系统可能只有一个或几个给定人脸的样本,并且必须从新照片中正确识别出该人,包括在表情、发型、光照和首饰等都有所变化的情况下。
在人脸认证的情况下,模型或系统可能只有一个人脸的样本记录,并且必须正确地验证该人的新照片,也许每天都要这样。
因此,人脸识别是单样本学习的常见例子之一。
用于单样本学习的孪生网络
目前已推广用于单样本学习的网络是孪生网络。
孪生网络是由两个并行神经网络构成的架构,每个神经网络采用不同的输入,其输出被组合起来以提供一些预测。
这是专为验证任务而设计的网络,最早由 Jane Bromley 等人在 2005 年题为《使用孪生时延神经网络进行签名认证》(《Signature Verification using a Siamese Time Delay Neural Network》)的论文中首次提出用于签名认证。
该算法基于一种新的人工神经网络,称为”孪生“神经网络。这个网络由在其输出端连接的两个相同的子网络组成。
——《Signature Verification using a “Siamese” Time Delay Neural Network》,2005 年
使用两个相同的网络,一个采取此人的已知签名,另一个获取候选签名。将两个网络的输出组合起来进行评分,以辨明候选签名是真实签名还是伪造签名。
验证包括将提取的特征向量与用于签名者存储的特征向量进行比较。接受比所选阈值更接近该存储表示的签名,所有其他签名将被视为伪造而拒绝。
——《Signature Verification using a “Siamese” Time Delay Neural Network》,2005 年
用于签名认证的孪生网络示例。摘自:《Signature Verification using a “Siamese” Time Delay Neural Network》
孪生网络是最近才开始被使用的,在 Gregory Koch 等人 2015 年发表的题为《用于一次性图像识别的孪生神经网络》(《Siamese Neural Networks for One-Shot Image Recognition》)中,将深度卷积网络用于并行图像输入。
首先训练深度 CNN 来区分每个类的样本。其思想是让模型学习能够有效地从输入图像中提取抽象特征的特征向量。
用于训练孪生网络的图像验证示例。摘自:《Siamese Neural Networks for One-Shot Image Recognition》
然后,这些模型重新用于验证,以预测新样本是否与每个类的模板相匹配。
具体来说,每个网络产生输入图像的特征向量,然后使用 L1 距离和 sigmoid 激活进行比较。将该模型应用于计算机视觉中使用的手写字符数据集的基准测试。
孪生网络的意义在于,它通过学习特征表示(特征向量)来解决单样本学习的方法,然后将特征表示进行比较以用于验证任务。
Yaniv Taigman 等人在 2014 年发表的论文《DeepFace:弥合人脸认证与人类水平的差距》(《DeepFace: Closing the Gap to Human-Level Performance in Face Verification》)中,描述了使用孪生网络开发的人脸识别系统的一个例子。
他们的方法包括,首先训练模型进行人脸识别,然后移除模型的分类器层,将激活作为特征向量,然后计算并比较两种不同的人脸进行人脸认证。
我们还测试了一种端到端的度量学习方法,称为孪生网络:一旦学习完毕,人脸识别网络(没有顶层)将被复制两次(每个输入图像一次),这些特征将被用于直接预测两个输入图像是否属于同一个人。
——《DeepFace: Closing the Gap to Human-Level Performance in Face Verification》,2014 年
用于降维的对比损失
学习像图像这样的复杂输入的向量表示就是降维的一个例子。
降维目的是将高维数据转换为低维表示,以便将类似的输入对象映射到流形上的临近点。
——《Dimensionality Reduction by Learning an Invariant Mapping》,2006 年
有效降维的目标是学习一种新的低维表示,它保留了输入的结构,使得输出向量之间的距离能够有意义地捕捉到输入中的差异。然而,向量必须捕获到输入中的不变特征。
问题是在给定输入空间中的样本之间的邻域关系的情况下,找到一个将高维输入模式映射到低维输出的函数。
——《Dimensionality Reduction by Learning an Invariant Mapping》,2006 年
降维是孪生网络用于解决单样本学习的方法。
Raia Hadsell 等人在 2006 年发表的一篇题为《学习不变映射的降维》(《Dimensionality Reduction by Learning an Invariant Mapping》)论文中,探讨了利用具有图像数据的卷积神经网络进行孪生网络降维,并提出了通过对比损失对模型进行训练的方法。
与在训练数据集中的所有输入样本中评估模型性能的其他损失函数不同,对比损失是在成对的输入之间计算的,例如提供给孪生网络的两个输入之间。
成对的样本被提供给网络,损失函数根据样本的类别是相同的还是不同对模型进行不同的惩罚。具体来说,如果类是相同的,损失函数就鼓励模型输出更为相似的特征向量,而如果类不同的话,那么损失函数就会鼓励模型输出不太相似的特征向量。
对比损失需要人脸图像对,然后将成对的正类拉到一起,并抛弃成对的负类。…… 然而,对比损失的主要问题是裕度参数(margin parameters)往往难以选择。
——《Deep Face Recognition: A Survey》,2018 年
损失函数要求选择一个裕度(margin),用于确定来自不同对的样本进行惩罚的极限。选择这个裕度需仔细考虑,这是使用损失函数的一个缺点。
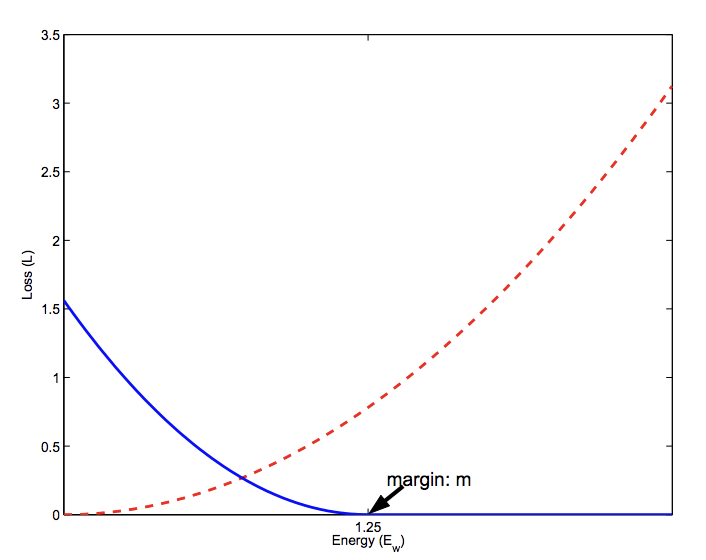
相似(红线)和不同(蓝线)对的对比损失计算图。摘自《Dimensionality reduction by learning an invariant mapping》。
对比损失可用来训练人脸识别系统,特别是用于人脸认证的任务。此外,通过在计算损失和更新模型之前顺序提供成对的样本并保存预测的特征向量,可以在不需要孪生网络架构中使用的并行模型的情况下实现这一点。
例如,DeepID2 和后续系统(DeepID2+、DeepID3),它们使用深度卷积神经网络,但并不是孪生网络架构,并在基准人脸识别数据集上实现了最先进的结果。
验证信号可直接对 DeepID2 进行正规化,从而有效减少人内变化(intra-personal variations)。常用的约束包括 L1/L2 范数和余弦相似度。我们采用以下基于 L2 范数的损失函数,它最初是由 Hadsell 等人提出的,用于降维。
——《Deep Learning Face Representation by Joint Identification-Verification》,2014 年
用于学习人脸嵌入的三重损失
对比损失的概念可以进一步扩展,从两个样本扩展到三个样本,称为三重损失。
Google 的 Florian Schroff 等人在 2015 年发表的论文《FaceNet:人脸识别和聚类的统一嵌入》(《FaceNet: A Unified Embedding for Face Recognition and Clustering》)中介绍了三重损失。
三重损失不是基于两个样本来计算损失,而是包含一个锚示例(anchor example)和一个正类或匹配的样本(相同类)和一个负类或不匹配的样本(不同类)。
损失函数对模型进行惩罚,减小匹配样本之间的距离,增加了非匹配样本之间的距离。
它需要人脸的三元组,然后它将锚和相同身份的正类样本之间的距离进行最小化,并将锚与不同身份的负类样本之间的距离进行最大化。
——《Deep Face Recognition: A Survey》,2018 年
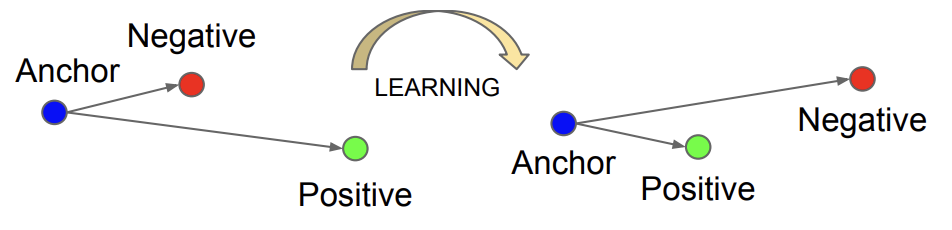
结果就是一个特征向量,被称为“人脸嵌入”,它具有一个有意义的欧几里得关系,使得相似的人脸产生的嵌入距离很小(例如,可以进行聚类),并且同一个人脸的不同样本产生非常小的嵌入,允许对其他身份进行验证和区分。
这种方法被用做 FaceNet 系统的基础,该系统在基准人脸识别数据集上获得了当时最先进的结果。