In-depth understanding of Delta Lake's DML implementation principles (Update, Delete, Merge)
Past memory big data
Delta Lake supports DML commands, including DELETE, UPDATE, and MERGE, which simplify business scenarios such as CDC, auditing, governance, and GDPR/CCPA workflow. In this article, we will demonstrate how to use these DML commands, and will introduce the implementation of these commands, and also introduce some performance tuning techniques for the corresponding commands.
Delta Lake: basic principles
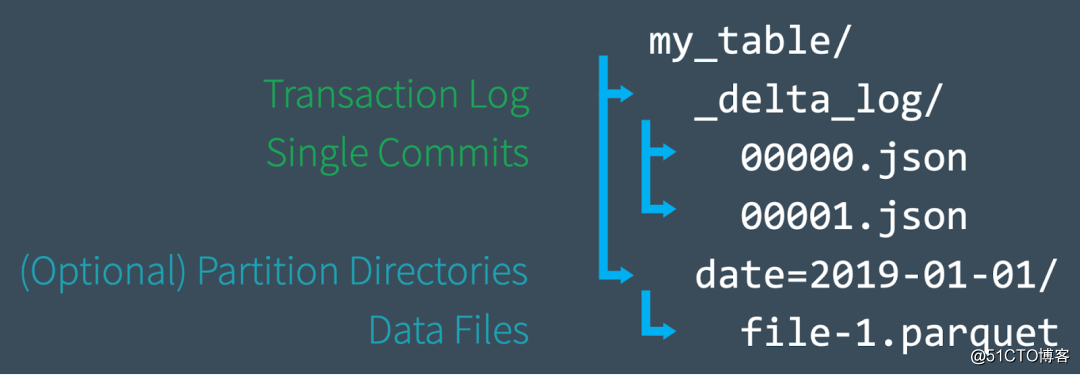
If you are just learning Delta Lake, then you can read this chapter to quickly understand the basic principles of Delta Lake. This section mainly introduces the construction of the Delta Lake table at the file level.
When creating a new table, Delta saves the data in a series of Parquet files, and creates a _delta_log folder in the root directory of the table, which contains the transaction log of Delta Lake, and the ACID transaction log records each time the corresponding table change. When you modify the table (for example, by adding new data or performing an update, merge, or delete), Delta Lake saves the record of each new transaction as a numbered JSON file in the delta_log folder, from 00...00000. The json name starts, followed by 00...00001.json, 00...00002.json, and so on; for every 10 transactions, Delta will also generate a "checkpoint" Parquet file in the delta_log folder. This file allows us to quickly recreate the state of the table.
Finally, when we query the Delta Lake table, we can first read the transaction log to quickly determine which data files constitute the latest version of the table, without the need to list all the files in the cloud object storage, which greatly improves query performance . When we perform DML operations, Delta Lake will create new files instead of modifying them in the original files, and use the transaction log to record all these operations, such as which files are new. If you want to know more about this, you can refer to the article "In-Depth Understanding of Apache Spark Delta Lake Transaction Logs".
Well, with the previous basic introduction, we can introduce how to use Delta Lake's DML command and the working principle behind it. The following example uses SQL to operate. This requires us to use Delta Lake 0.7.0 and Apache Spark 3.0. For details, see "Enable Spark SQL DDL and DML in Delta Lake".
UPDATE use and internal principles
You can use the UPDATE operation to selectively update any row that matches a filter condition (also known as a predicate). The following code demonstrates how to use each type of predicate as part of an UPDATE statement. Note that Delta Lake's update can be used in Python, Scala and SQL, but for the purpose of this article, we only use SQL to introduce its use here.
-- Update events
UPDATE events SET eventType = 'click' WHERE eventType = 'click'
UPDATE: Under the hoodThe implementation of UPDATE in Delta Lake is divided into two steps:
• First find and select those files that contain data that matches the predicate and need to be updated. In this process, Delta Lake can use data skipping technology to speed up this process. The data skipping technology seems to be only available in the commerce department of the number of bricks, and the open source version seems to have not been seen.
• Read each matching file into memory, update the relevant line, and write the result to a new data file.
The whole process is as follows:
Once Delta Lake successfully executes the UPDATE, it will add a commit to the transaction log, indicating that the new data file will be used from now on to replace the old data file. However, the old data file is not deleted. Instead, it is just marked as tombstoned-meaning that this file only belongs to the old version of the table data file and not the current version of the data file. Delta Lake can use it to provide data version control and time travel.
UPDATE + Delta Lake time travel = Easy debugging
Keeping old data files is very useful for debugging, because you can use Delta Lake time travel at any time to go back to history and query the previous version of the table. If one day we accidentally update the table by mistake and want to find out what happened, we can easily compare the two versions of the table.
SELECT * FROM events VERSION AS OF 12UPDATE: Performance tuning
The main way to improve the performance of Delta Lake's UPDATE command is to add more predicates to narrow the search space. The more specific the search, the fewer files Delta Lake needs to scan and/or modify.
Databricks' commercial version of Delta Lake has some enterprise enhancements, such as improved data skipping, the use of bloom filters and Z-Order Optimize. Z-Order Optimize reorganizes the layout of each data file to make similar The column values are strategically close to each other for maximum efficiency.
DELETE use and internal principles
We can use the DELETE command and selectively delete any row based on the predicate (filter condition).
DELETE FROM events WHERE date < '2017-01-01'If you want to recover an accidental delete operation, you can use time travel to roll back the table to its original state, as shown in the following Python code snippet.
# Read correct version of table into memory
dt = spark.read.format("delta") \
.option("versionAsOf", 4) \
.load("/tmp/loans_delta")
# Overwrite current table with DataFrame in memory
dt.write.format("delta") \
.mode("overwrite") \
.save(deltaPath)
DELETE: Under the hood
DELETE works the same as UPDATE. Delta Lake scans the data twice: the first scan is to identify any data files that contain rows that match the predicate conditions. The second scan reads the matching data file into the memory. At this time, Delta Lake deletes the relevant rows, and then writes the undeleted data to a new file on the disk.
After Delta Lake successfully completes the delete operation, the old data files will not be deleted-they still remain on the disk, but these files are recorded as tombstoned in the Delta Lake transaction log (no longer part of the active table). Remember, those old files will not be deleted immediately, because we may need to use the time travel feature to jump to an earlier version of the data. If you want to delete files that exceed a certain period of time, you can use the VACUUM command.
DELETE + VACUUM: clean up old files
Run the VACUUM command to permanently delete all data files that meet the following conditions:
• is no longer part of the active table, and
• exceeds the retention threshold (the default is seven days).
Delta Lake does not automatically delete old files-we have to run the VACUUM command ourselves, as shown below. If we wish to specify a retention period that is different from the default value, then we can provide it as a parameter.
from delta.tables import *
# vacuum files not required by versions older than the default
# retention period, which is 168 hours (7 days) by default
dt.vacuum()
deltaTable.vacuum(48) # vacuum files older than 48 hoursNote : If the retention time specified when running the VACUUM command is 0 hours, all unused files in the latest version of the table will be deleted. Please make sure that there is no write operation to the corresponding table when running this command, otherwise data loss may occur.
DELETE: Performance tuning
is the same as the UPDATE command. The main way to improve the performance of Delta Lake DELETE operations is to add more predicates to narrow the search space. Databricks' commercial version of Delta Lake has some enterprise enhancements, such as improved data skipping, the use of bloom filters, and Z-Order Optimize.
MERGE use and internal principles
The MERGE command of Delta Lake allows us to realize the semantics of upserts, which is actually a mixture of UPDATE and INSERT. In order to understand the meaning of upserts, suppose we have a table (target table) and a source table, which contains new records and updates to existing records. Upsert works like this:
• When a record in the source table matches an existing record in the target table, Delta Lake will update the record.
• When there is no match, Delta Lake will insert a new record.
MERGE INTO events
USING updates
ON events.eventId = updates.eventId
WHEN MATCHED THEN UPDATE
SET events.data = updates.data
WHEN NOT MATCHED THEN
INSERT (date, eventId, data) VALUES (date, eventId, data) Delta Lake's MERGE command greatly simplifies the workflow.
MERGE: Under the hood
Delta Lake implements MERGE through the following two steps:
• Perform an inner join between the target table and the source table to select all matching files.
• Perform outer join between the selected file in the target table and the source table, and write out the updated/deleted/inserted data.
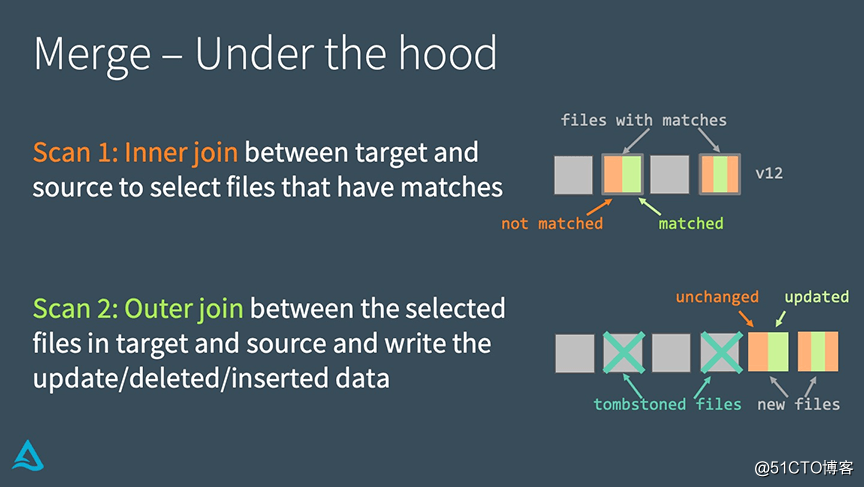
The main difference between the implementation of MERGE and UPDATE or DELETE is that it uses join. This fact allows us to use some unique strategies when seeking to improve performance.
MERGE: performance tuning
In order to improve the execution performance of MERGE, we need to understand which of the above two joins affects the execution of the program.
If inner join is the bottleneck of MERGE execution (for example, it takes too long to find the files that need to be rewritten in Delta Lake), then we can use the following strategies to solve it:
•Add more filter conditions to reduce the search space;
•Adjust the number of shuffle partitions;
•Adjust the threshold of broadcast join;.
•If there are many small files in the table, we can compress and merge them first; but do not compress them too much Large files, because Delta Lake must copy the entire file to rewrite it.
If outer join is the bottleneck of MERGE execution (for example, it takes too long to rewrite the file), then we can use the following strategies to solve it:
• Adjust the number of shuffle partitions.
• This partition table may generate a lot of small files;
• Turn on automatic repartitioning before writing files to reduce the files generated by Reduce.
• Adjust the broadcast threshold. If we use full outer join, Spark cannot perform broadcast join, but if we use right outer join, Spark can be used; we can adjust the broadcast threshold according to the actual situation;
• cache source table / DataFrame.
• cache source table . Speed up the second scan time, but remember not to cache the target table, because this may cause cache consistency problems.
to sum up
Delta Lake supports DML commands such as UPDATE, DELETE, and MERGE INTO, which greatly simplifies the workflow of many common big data operations. In this article, we demonstrated how to use these commands in Delta Lake, introduced the implementation principles of these DML commands, and provided some performance tuning techniques.