Introduction to the seven Join types supported in Apache Spark
Past memory big data Past memory big data
In data analysis, it is a very common scenario to perform a Join operation on two data sets. In this article, I introduced the five Join strategies supported by Spark. In this article, I will introduce you to the Join Type supported in Apache Spark.
In the current version of Apache Spark 3.0, the following seven join types are supported:
•INNER JOIN
•CROSS JOIN
•LEFT OUTER JOIN
•RIGHT OUTER JOIN
•FULL OUTER JOIN
•LEFT SEMI JOIN
•LEFT ANTI JOIN
In terms of implementation, the implementation classes corresponding to these seven kinds of Join are as follows:
object JoinType {
def apply(typ: String): JoinType = typ.toLowerCase(Locale.ROOT).replace("_", "") match {
case "inner" => Inner
case "outer" | "full" | "fullouter" => FullOuter
case "leftouter" | "left" => LeftOuter
case "rightouter" | "right" => RightOuter
case "leftsemi" | "semi" => LeftSemi
case "leftanti" | "anti" => LeftAnti
case "cross" => Cross
case _ =>
val supported = Seq(
"inner",
"outer", "full", "fullouter", "full_outer",
"leftouter", "left", "left_outer",
"rightouter", "right", "right_outer",
"leftsemi", "left_semi", "semi",
"leftanti", "left_anti", "anti",
"cross")
throw new IllegalArgumentException(s"Unsupported join type '$typ'. " +
"Supported join types include: " + supported.mkString("'", "', '", "'") + ".")
}
}Today, I do not intend to introduce the implementation of these seven types of Join from the underlying code, but from the perspective of a data analyst to introduce the meaning and use of these types of Join. Before introducing the following, suppose we have two tables related to customer and order, as follows:
scala> val order = spark.sparkContext.parallelize(Seq(
| (1, 101,2500), (2,102,1110), (3,103,500), (4 ,102,400)
| )).toDF("paymentId", "customerId","amount")
order: org.apache.spark.sql.DataFrame = [paymentId: int, customerId: int ... 1 more field]
scala> order.show
+---------+----------+------+
|paymentId|customerId|amount|
+---------+----------+------+
| 1| 101| 2500|
| 2| 102| 1110|
| 3| 103| 500|
| 4| 102| 400|
+---------+----------+------+
scala> val customer = spark.sparkContext.parallelize(Seq(
| (101,"iteblog") ,(102,"iteblog_hadoop") ,(103,"iteblog001"), (104,"iteblog002"), (105,"iteblog003"), (106,"iteblog004")
| )).toDF("customerId", "name")
customer: org.apache.spark.sql.DataFrame = [customerId: int, name: string]
scala> customer.show
+----------+--------------+
|customerId| name|
+----------+--------------+
| 101| iteblog|
| 102|iteblog_hadoop|
| 103| iteblog001|
| 104| iteblog002|
| 105| iteblog003|
| 106| iteblog004|
+----------+--------------+
准备好数据之后,现在我们来一一介绍这些 Join 类型。INNER JOIN
In Spark, if no Join type is specified, the default is INNER JOIN. INNER JOIN will only return data that meets the join condition. This should be used more often, as follows:
scala> val df = customer.join(order,"customerId")
df: org.apache.spark.sql.DataFrame = [customerId: int, name: string ... 2 more fields]
scala> df.show
+----------+--------------+---------+------+
|customerId| name|paymentId|amount|
+----------+--------------+---------+------+
| 101| iteblog| 1| 2500|
| 103| iteblog001| 3| 500|
| 102|iteblog_hadoop| 2| 1110|
| 102|iteblog_hadoop| 4| 400|
+----------+--------------+---------+------+As can be seen from the above, when we do not specify any Join type, the default is INNER JOIN; in the generated result, Spark automatically deletes the customerId that exists in both tables for us. If represented by a graph, INNER JOIN can be represented as follows:
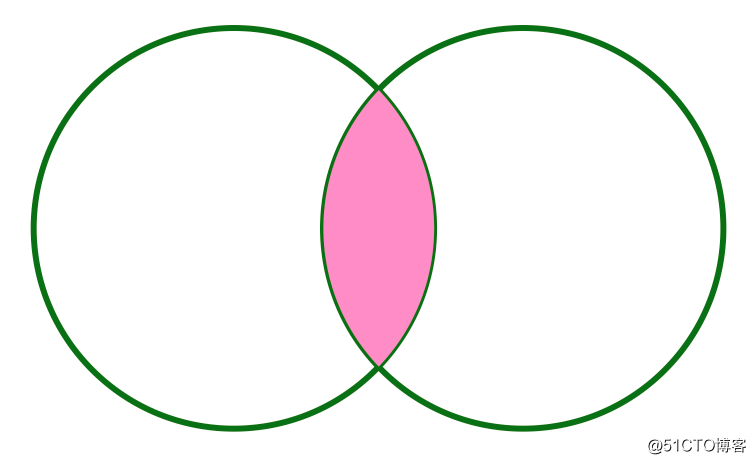
The pink part of the picture above is the result of INNER JOIN.
CROSS JOIN
This type of Join is also called Cartesian Product (Cartesian Product). Each row of data in the left table of Join will be joined with each row of data in the right table. The resulting number of rows is m*n, so in a production environment Try not to use this kind of Join. The following is an example of the use of CROSS JOIN:
scala> val df = customer.crossJoin(order)
df: org.apache.spark.sql.DataFrame = [customerId: int, name: string ... 3 more fields]
scala> df.show
+----------+--------------+---------+----------+------+
|customerId| name|paymentId|customerId|amount|
+----------+--------------+---------+----------+------+
| 101| iteblog| 1| 101| 2500|
| 101| iteblog| 2| 102| 1110|
| 101| iteblog| 3| 103| 500|
| 101| iteblog| 4| 102| 400|
| 102|iteblog_hadoop| 1| 101| 2500|
| 102|iteblog_hadoop| 2| 102| 1110|
| 102|iteblog_hadoop| 3| 103| 500|
| 102|iteblog_hadoop| 4| 102| 400|
| 103| iteblog001| 1| 101| 2500|
| 103| iteblog001| 2| 102| 1110|
| 103| iteblog001| 3| 103| 500|
| 103| iteblog001| 4| 102| 400|
| 104| iteblog002| 1| 101| 2500|
| 104| iteblog002| 2| 102| 1110|
| 104| iteblog002| 3| 103| 500|
| 104| iteblog002| 4| 102| 400|
| 105| iteblog003| 1| 101| 2500|
| 105| iteblog003| 2| 102| 1110|
| 105| iteblog003| 3| 103| 500|
| 105| iteblog003| 4| 102| 400|
+----------+--------------+---------+----------+------+
only showing top 20 rowsLEFT OUTER JOIN
LEFT OUTER JOIN is equivalent to LEFT JOIN. I believe everyone knows the result returned by this Join, so I won’t introduce it. The following three wordings are equivalent:
val leftJoinDf = customer.join(order,Seq("customerId"), "left_outer")
val leftJoinDf = customer.join(order,Seq("customerId"), "leftouter")
val leftJoinDf = customer.join(order,Seq("customerId"), "left")
scala> leftJoinDf.show
+----------+--------------+---------+------+
|customerId| name|paymentId|amount|
+----------+--------------+---------+------+
| 101| iteblog| 1| 2500|
| 103| iteblog001| 3| 500|
| 102|iteblog_hadoop| 2| 1110|
| 102|iteblog_hadoop| 4| 400|
| 105| iteblog003| null| null|
| 106| iteblog004| null| null|
| 104| iteblog002| null| null|
+----------+--------------+---------+------+If it is represented by a figure, the LEFT OUTER JOIN can be as follows: It can be seen that the data of the left table participating in the Join will be displayed, and the right table will only be displayed if it is related.
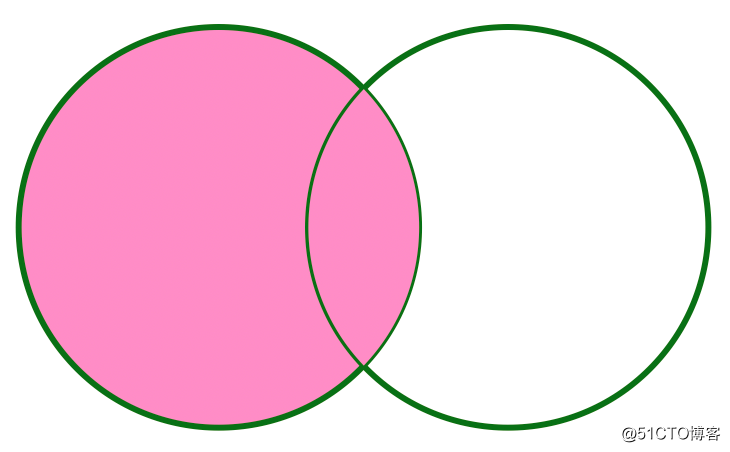
RIGHT OUTER JOIN
Similar to LEFT OUTER JOIN, RIGHT OUTER JOIN is equivalent to RIGHT JOIN, and the following three ways of writing are also equivalent:
val rightJoinDf = order.join(customer,Seq("customerId"), "right")
val rightJoinDf = order.join(customer,Seq("customerId"), "right_outer")
val rightJoinDf = order.join(customer,Seq("customerId"), "rightouter")
scala> rightJoinDf.show
+----------+---------+------+--------------+
|customerId|paymentId|amount| name|
+----------+---------+------+--------------+
| 101| 1| 2500| iteblog|
| 103| 3| 500| iteblog001|
| 102| 2| 1110|iteblog_hadoop|
| 102| 4| 400|iteblog_hadoop|
| 105| null| null| iteblog003|
| 106| null| null| iteblog004|
| 104| null| null| iteblog002|
+----------+---------+------+--------------+If it is represented by a figure, the RIGHT OUTER JOIN can be as follows: It can be seen that the data of the right table participating in the Join will be displayed, and the left table will only be displayed if it is related.
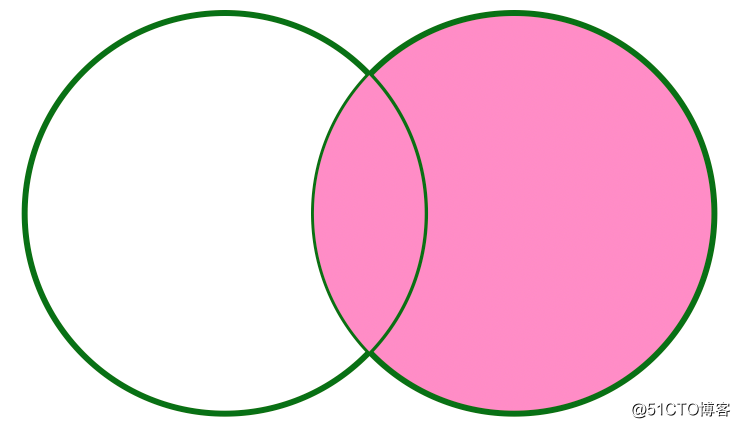
FULL OUTER JOIN
Everyone should be familiar with the meaning of FULL OUTER JOIN, so I won't introduce its meaning. FULL OUTER JOIN has the following four ways of writing:
val fullJoinDf = order.join(customer,Seq("customerId"), "outer")
val fullJoinDf = order.join(customer,Seq("customerId"), "full")
val fullJoinDf = order.join(customer,Seq("customerId"), "full_outer")
val fullJoinDf = order.join(customer,Seq("customerId"), "fullouter")
scala> fullJoinDf.show
+----------+---------+------+--------------+
|customerId|paymentId|amount| name|
+----------+---------+------+--------------+
| 101| 1| 2500| iteblog|
| 103| 3| 500| iteblog001|
| 102| 2| 1110|iteblog_hadoop|
| 102| 4| 400|iteblog_hadoop|
| 105| null| null| iteblog003|
| 106| null| null| iteblog004|
| 104| null| null| iteblog002|
+----------+---------+------+--------------+FULL OUTER JOIN can be represented by the following figure:
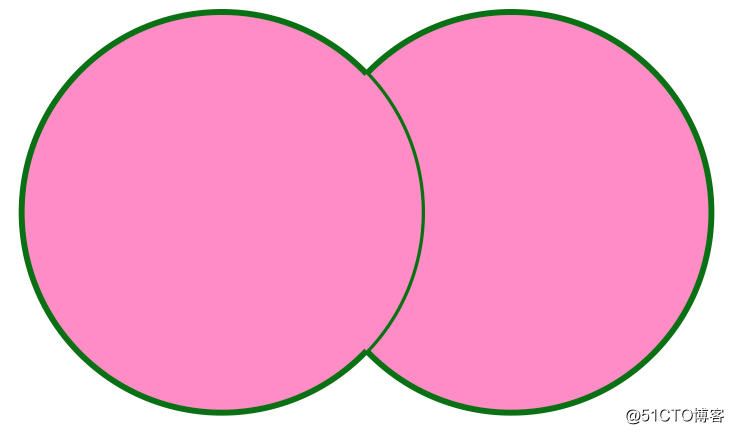
LEFT SEMI JOIN
There are relatively few people who should know LEFT SEMI JOIN. LEFT SEMI JOIN will only return the data that matches the right table, and LEFT SEMI JOIN will only return the data of the left table, the data of the right table will not be displayed, the following three The writing methods are all equivalent:
val leftSemiJoinDf = order.join(customer,Seq("customerId"), "leftsemi")
val leftSemiJoinDf = order.join(customer,Seq("customerId"), "left_semi")
val leftSemiJoinDf = order.join(customer,Seq("customerId"), "semi")
scala> leftSemiJoinDf.show
+----------+---------+------+
|customerId|paymentId|amount|
+----------+---------+------+
| 101| 1| 2500|
| 103| 3| 500|
| 102| 2| 1110|
| 102| 4| 400|
+----------+---------+------+As can be seen from the above results, LEFT SEMI JOIN can actually be rewritten with IN/EXISTS:
scala> order.registerTempTable("order")
warning: there was one deprecation warning (since 2.0.0); for details, enable `:setting -deprecation' or `:replay -deprecation'
scala> customer.registerTempTable("customer")
warning: there was one deprecation warning (since 2.0.0); for details, enable `:setting -deprecation' or `:replay -deprecation'
scala> val r = spark.sql("select * from order where customerId in (select customerId from customer)")
r: org.apache.spark.sql.DataFrame = [paymentId: int, customerId: int ... 1 more field]
scala> r.show
+---------+----------+------+
|paymentId|customerId|amount|
+---------+----------+------+
| 1| 101| 2500|
| 3| 103| 500|
| 2| 102| 1110|
| 4| 102| 400|
+---------+----------+------+LEFT SEMI JOIN can be represented by the following figure:
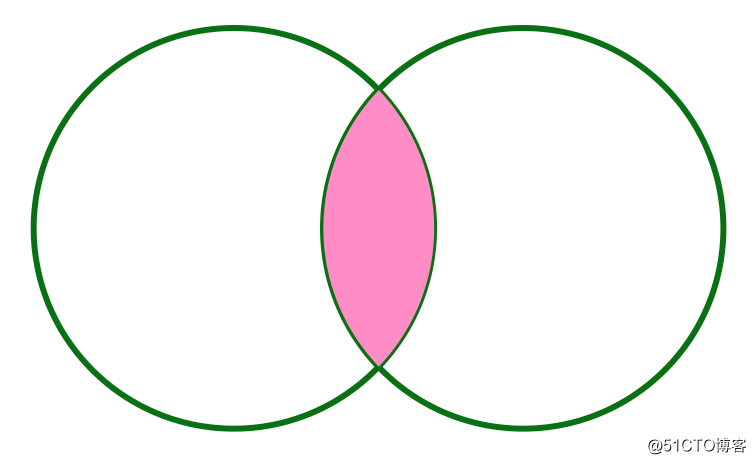
LEFT ANTI JOIN
Contrary to LEFT SEMI JOIN, LEFT ANTI JOIN will only return data from the left table that does not match the right table. And the following three ways of writing are also equivalent:
val leftAntiJoinDf = customer.join(order,Seq("customerId"), "leftanti")
val leftAntiJoinDf = customer.join(order,Seq("customerId"), "left_anti")
val leftAntiJoinDf = customer.join(order,Seq("customerId"), "anti")
scala> leftAntiJoinDf.show
+----------+----------+
|customerId| name|
+----------+----------+
| 105|iteblog003|
| 106|iteblog004|
| 104|iteblog002|
+----------+----------+In the same way, LEFT ANTI JOIN can also be rewritten with NOT IN:
scala> val r = spark.sql("select * from customer where customerId not in (select customerId from order)")
r: org.apache.spark.sql.DataFrame = [customerId: int, name: string]
scala> r.show
+----------+----------+
|customerId| name|
+----------+----------+
| 104|iteblog002|
| 105|iteblog003|
| 106|iteblog004|
+----------+----------+LEFT SEMI ANTI can be represented by the following figure:
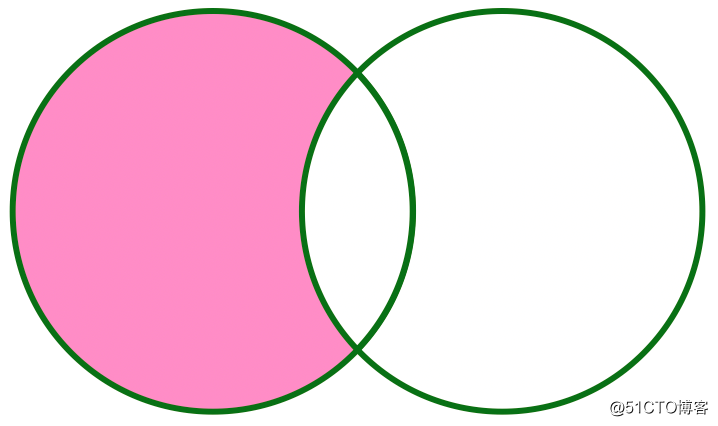
Well, the seven Join types of Spark have been briefly introduced. You can choose different Join types according to different types of business scenarios. That's all for sharing today, thank you for your attention and support.