HBase Spark analysis engine is an analysis engine provided by the HBase version of cloud database, based on the complex analysis, streaming, and machine learning capabilities provided by Spark. The Spark analysis engine can be connected to various data sources of Alibaba Cloud, such as cloud HBase database, MongoDB, Phoenix, etc., and it also supports the connection to the cloud database PolarDB. POLARDB is a next-generation relational cloud database developed by Alibaba Cloud. It is 100% compatible with MySQL and has a maximum performance of 6 times that of MySQL. This article mainly introduces how the HBase Spark analysis engine connects to the cloud database PolarDB.
Scene introduction
POLARDB often stores some dimension table information, such as user dimension table information, including user ID, name, address and other information. The characteristic of this type of data is that the amount of data is small and does not change frequently.
There are often some massive fact table data in Spark for data analysis, such as user call information, transaction information, etc. This type of data is characterized by a large amount of data and incremental updates. Users need to count, analyze and mine valuable content in this type of data.
For example, the user fact table data generally contains the user's ID information. When the fact table is statistically analyzed on the Spark side, the results of the analysis need to be supplemented with other information of the user, such as name, address, etc.
At this time, you can use the Spark analysis engine to directly perform associated query and statistical analysis with the PolarDB data table, without worrying about the relocation of the PolarDB data, as well as the data synchronization problems and additional maintenance workload caused by the relocation data.
Let's take a look at how to associate the cloud database PolarDB in the Spark analysis engine.
Create a table in the Spark analysis engine
The SQL sample in this article can run on the SQL service ThriftServer of the Spark analysis cluster:
https://help.aliyun.com/document_detail/93902.html?spm=a2c4e.11153940.blogcont690754.15.454833521E4hrG
The syntax for creating an associated PolarDB table in the Spark analysis engine is as follows:
create table jdbc_polordb
using org.apache.spark.sql.jdbc
options (
url "jdbc:mysql://pc-xxx.rwlb.rds.aliyuncs.com:3306",
dbtable "testdb.test_table",
user 'testuser',
password 'xxx'
)
The sample uses Spark's JDBC DataSource API. The meaning of each parameter is as follows:
jdbc:mysql://pc-xxx.rwlb.rds.aliyuncs.com:3306 : The database address of the PolarDB, obtained from the PolarDB cluster, it can be the cluster address, the main address or the SQL acceleration address, corresponding to the connection of the PolarDB in the figure below address: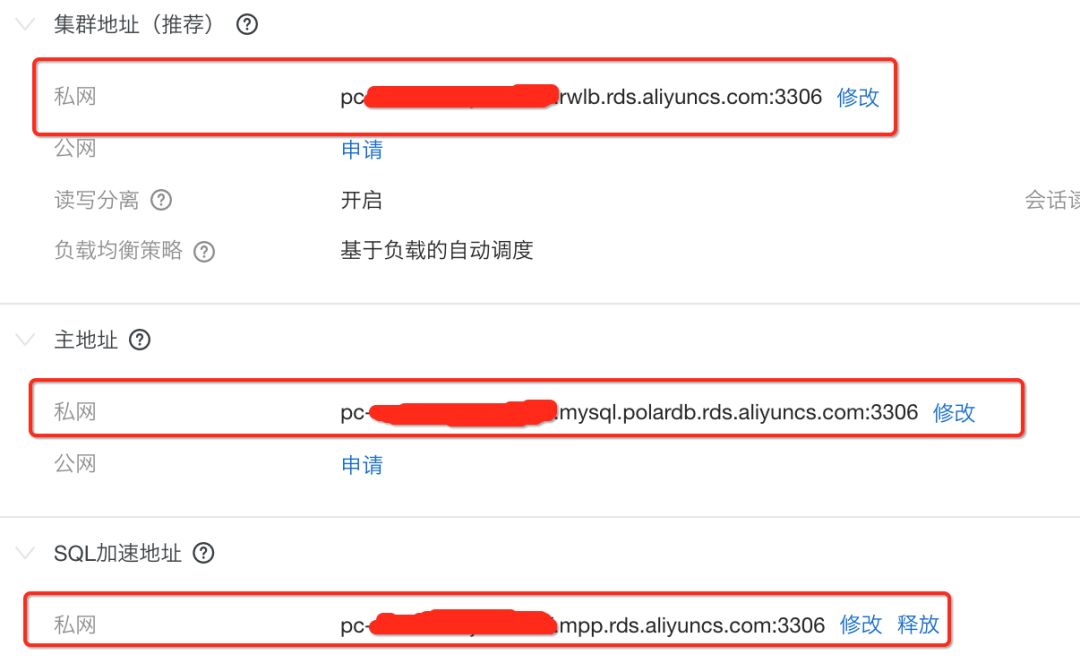
testdb.test_table: testdb is the name of the database created in PolarDB, and test_table is the name of the created table.
user and password correspond to the user name and password for logging in to the database, respectively.
Manipulate tables in Spark analysis engine
After creating a table in the Spark analysis engine, you can directly manipulate the POLARDB table in the Spark analysis engine. Commonly used table operations include querying tables, inserting data, and deleting tables.
1. Query sample:
select * from jdbc_polordb limit 5;
+-----+---------+--+
| id | name |
+-----+---------+--+
| 9 | name9 |
| 15 | name15 |
| 9 | name99 |
| 28 | name28 |
| 15 | name15 |
+-----+---------+--+
select * from jdbc_polordb where id >= 96;
+------+-----------+--+
| id | name |
+------+-----------+--+
| 96 | name96 |
| 99 | name99 |
| 98 | name98 |
| 99 | name99 |
| 97 | name97 |
| 100 | name100 |
| 200 | testdata |
+------+-----------+--+
2. Insert data sample:
insert into jdbc_polordb values(200, 'testdata');
+---------+--+
| Result |
+---------+--+
+---------+--+
select * from jdbc_polordb where id=200;
+------+-----------+--+
| id | name |
+------+-----------+--+
| 200 | testdata |
+------+-----------+--+
3. Examples of join with other tables:
select j.id, j.name from jdbc_polordb j join test_parquet t on j.id = t.id;
+-----+--------+--+
| id | name |
+-----+--------+--+
| 1 | name1 |
| 3 | name3 |
| 5 | name5 |
+-----+--------+--+
4. Example of deleting a table (deleting a table on the Spark side will not delete the table in PolarDB):
drop table jdbc_polordb;
+---------+--+
| Result |
+---------+--+
+---------+--+Spark analysis engine query PolarDB performance optimization
The Spark analysis engine provides the following optimization capabilities for querying the performance of the PolarDB table:
1. Column value trimming
obtains the data of the required fields in the PolarDB according to the user's SQL statement. For example, the table test_table in PolarDB has four fields, col1, col2, col3, and col4. The query statement in Spark is:
select col1, col3 from jdbc_polordb
Then the Spark analysis engine will only obtain the data corresponding to the two fields of col1 and col3 in the table test_table, reducing the amount of data obtained.
2. Push down by filter conditions
Spark analysis engine supports push down by commonly used filter conditions, for example: =,>,>=,<,<=,is null, is not null,like xx%, like %xx, like %xx% ,in,not. Query SQL such as:
select * from jdbc_polordb where id >= 96;
select * from jdbc_polordb where id=200;
The Spark analysis engine will push the filter condition id=200, id>=96 down to PolarDB to reduce the amount of data obtained and improve query performance.
3. Partition Parallel Reading
When creating a JDBC table in the Spark analysis engine, you can specify the partition, and the query will be concurrently queried according to the partition field and the number of partitions. The syntax is as follows:
create table jdbc_polordb
using org.apache.spark.sql.jdbc
options (
url "jdbc:mysql://pc-xxx.rwlb.rds.aliyuncs.com:3306",
dbtable "testdb.test_table",
user 'testuser',
password 'xxx',
partitionColumn 'id',
lowerBound '20',
upperBound '80',
numPartitions '5'
)
partitionColumn : is the name of the field that needs to be partitioned, corresponding to the field of the table in POLARDB;
lowerBound : the lower bound value of the corresponding field;
upperBound : the upper bound value of the corresponding field;
numPartitions : the number of partitions.
On this basis, execute select * from jdbc_polordb, and the Spark analysis engine will issue 5 parallel jobs to query the PolarDB database. The following figure shows the parallel job of the Spark analysis engine:
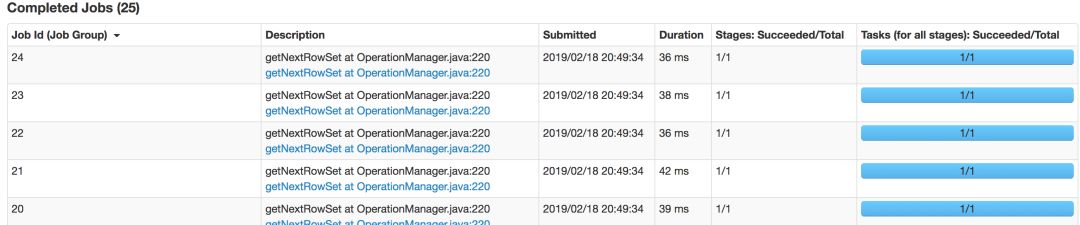
to sum up
As a big data computing framework, the Spark analysis engine can be easily combined with the cloud database PolarDB. It is very convenient to associate and analyze PolarDB data in the Spark analysis engine. This article briefly introduces the common operations of combining the HBase Spark analysis engine with the cloud database PolarDB. For more content, you are welcome to use the HBase Spark analysis engine, the cloud database PolarDB.
https://help.aliyun.com/document_detail/93899.html?spm=a2c4e.11153940.blogcont690754.16.45483352yIZFhW
https://help.aliyun.com/product/58609.html?spm=a2c4e.11153940.blogcont690754.17.45483352yIZFhW
