
Author | Yuying In the past two years, federal learning technology has developed rapidly. As a distributed machine learning paradigm, federated learning can effectively solve the problem of data islands, allowing participants to jointly model without sharing data, and technically break data islands. However, at present, this technology has encountered difficulties in many companies. InfoQ will introduce how each major company implements the technology in the financial field through the selection of topics.
In the field of artificial intelligence, technical practice, especially large-scale implementation, is a topic of great concern to all developers. However, in the actual landing process, we always face various problems. Only the most basic data has become a bottleneck that most companies cannot achieve breakthroughs in technology: poor data quality-for example, many data labels are difficult to collect, or even no labels; data is scattered-the data of each application is different. It is difficult to collaborate on data across organizations, etc. As domestic laws and regulations on data become more and more stringent, data issues have become more difficult, and the emergence of federal learning has allowed developers to discover the feasibility of solving the problem.
In the past few years, many domestic companies have invested in the research and development of federal learning and have entered the stage of implementation. In this article, InfoQ interviewed Chen Tianjian, deputy general manager of the artificial intelligence department of WeBank, to gain an in-depth understanding of the practice of various federal learning methods in WeBank.
Application of Federal Learning in the Financial Field
At present, Federated Learning has made progress in some key financial fields, such as joint anti-money laundering modeling, joint credit risk control modeling, joint equity pricing modeling, joint customer value modeling, etc. Compared with other fields, the financial field has stricter data control and more emphasis on data privacy. Therefore, it is also the field where technical means are most needed to solve the problem of data islands.
Chen Tianjian said that credit risk management and underwriting risk assessment are all suitable financial applications for federal learning. Compared with other fields, financial applications focus more on the quantification of risks. After all, risk prices are often the main component of financial product prices. The risk quantification model based on federated learning can significantly improve risk quantification capabilities by expanding data dimensions, thereby reducing overall financial product prices and further improving the availability of financial services to the general public.
Practice of the three major classification systems of federated learning
In the classification system of federated learning, it includes:
In horizontal federated learning, the user characteristics (X1, X2, …) of the two data sets have a large overlap, while the users (U1, U2, …) have a small overlap;
In longitudinal federated learning, the overlap of users (U1, U2,…) of the two data sets is large, while the overlap of user characteristics (X1, X2,…) is small;
Federated transfer learning, through federated learning and transfer learning, solves the problem that the user (U1, U2,…) and user feature overlaps (X1, X2,…) of the two data sets are relatively small.
Different classification systems are suitable for solving problems in different scenarios in the financial field.
Horizontal federated learning
First, let's take a look at the application practice of horizontal federated learning. Chen Tianjian said that horizontal federated learning is characterized by the same data characteristics and different sample IDs. A common application in the financial field is bank processing anti-money laundering.
Anti-money laundering plays an important role in the daily operation of banks. But determining whether a transaction record is a money laundering activity is boring and error-prone. Traditionally, banks have used a rule-based model to filter those obvious non-money laundering records and manually review the remaining records. This type of rule-based model can provide a lot of help, but due to the small coverage, manual review can still take a lot of time. In addition, although the traditional model works well in known traditional situations, it lacks awareness of unknown situations, such as new forms of money laundering.
Through horizontal federated learning, various institutions can share a common model without establishing a physical model, which can effectively solve the problem of small samples and low data quality in this field. For example, on the premise of not sharing user data, WeBank established an anti-money laundering model with multiple banks. After simulation tests, the more banks involved in this model, the higher its performance.
The federated training model used in this application is called Homogeneous Logistic Regression (Homo-LR). All banks provide similar data, which means they have the same characteristics but different sample numbers. Through this combination, the entire data set includes a large number of positive cases and makes the model perform well. The principle of Homo-LR is as follows:
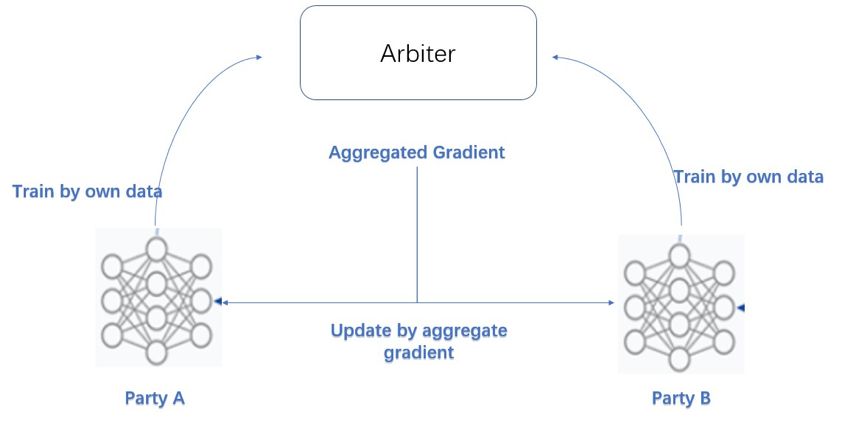
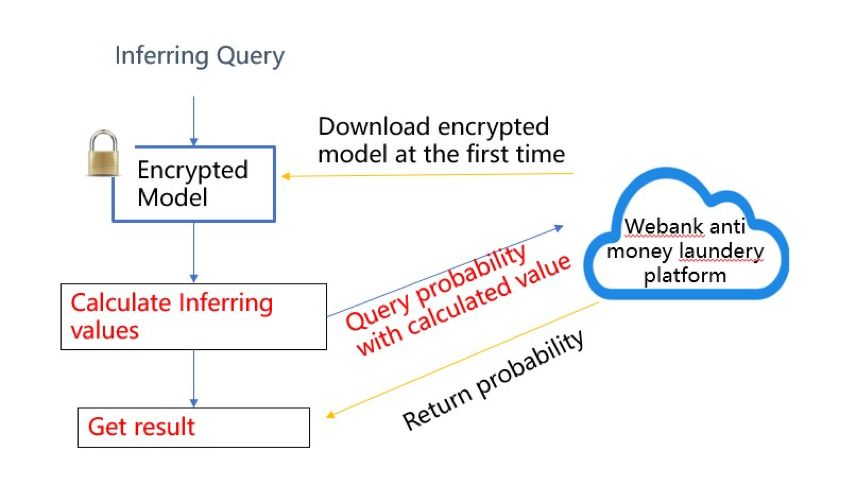
In each iteration, each party trains the model with its own data and sends their model weights or gradients to a third party called Arbiter. The arbiter aggregates all these model weights or gradients, and then updates them back to all parties. When the model is jointly trained by everyone, the data of each party will never come out of its own database. The inference process is also easy to understand and execute:
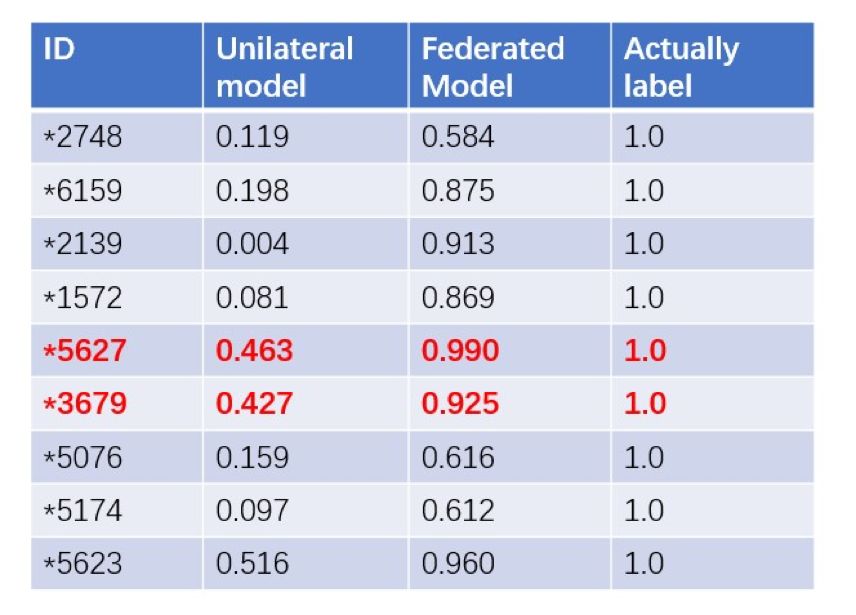
This method greatly improves the performance of the model. The AUC of the lr model has increased by 14%, reducing the number and difficulty of manual review. The following figure shows the effect comparison before and after using the model:
Longitudinal federated learning
其次是纵向联邦学习,特点是数据特征不同,样本 ID 相同,这种方法可以应用在风控信贷方面。
近年来,在国家政策的支持下,小微企业贷款受到越来越多关注,已成为衡量银行发展潜力和能力的重要指标。由于风险过高,许多银行不愿向小微企业贷款,因此如何规避风险并降低小微企业的不良率尤为重要。
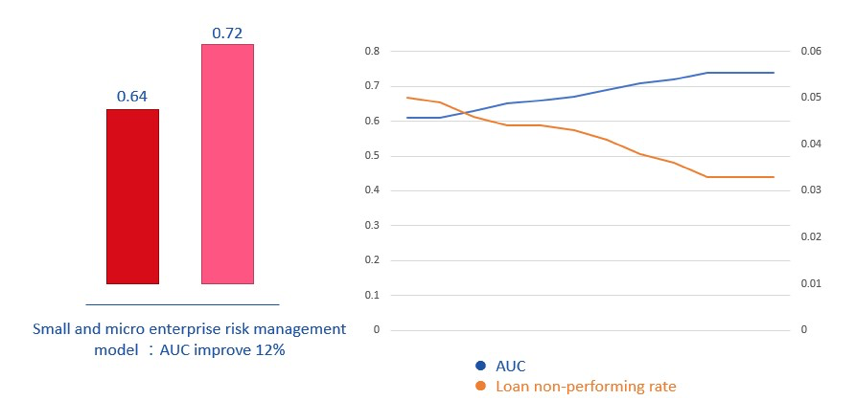
目前,大多数银行都将白名单机制用于小微企业贷款的风险管理,而白名单是通过筛选规则和风险模型来实现的。规则和风险模型都取决于小型和微型企业及其控制者的相关数据。对于风险管理,相关数据可以包括中央银行的信用报告、税收、声誉、财务、无形资产等。但是,对银行而言,实际上只有中央银行的信用报告,拿不到其他有效信息。纵向联邦学习为模型训练提供了一种可行的方式:不将数据泄漏给其他人,并且可以实现等效或接近完整数据模型的效果。
举例来说,假设银行拥有标签 Y 和中央银行信用报告特征 X3,合作公司拥有相关数据 X。因为缺少 Y 的信息,合作公司无法训练模型,但因为隐私安全问题,又不能直接将数据 X 传给微众银行,通过联邦学习,找到两者之间的交集,比如纳税人识别号,但这项工作不能让另一方知道,利用 RSA 加密技术,合作公司可以通过与加密的中间结果(而不是原始用户数据)交互来安全地得到相关信息。陈天健表示,银行目前能够结合发票开票金额与央行的征信数据等标签属性进行联合建模,将小微企业风控模型区分度——AUC of ROC(衡量模型区分好坏样本的评估标准之一)提升 12%。
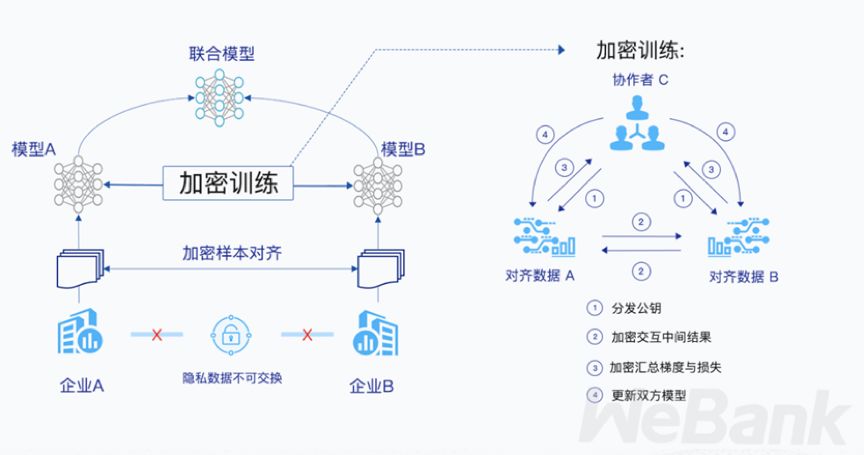
通过使用 FATE(下文详述,这是微众银行开源的联邦学习平台),微众银行与合作公司一起训练了模型。联邦训练的模型称为异构逻辑回归(Hetero-LR)。与传统的 Logistic 回归不同,Hetero-LR 维护其模型,并使用各自的数据进行训练,使用加密的中间结果来交互,并汇总最终模型梯度,在每一侧更新模型。这提高了模型性能,与仅使用中央银行的信用评分相比,Hetero-LR 模型的 AUC 增加了 12%。随着模型效果的改善,贷款不良率明显下降。
最后,则是走在科技前沿的联邦迁移学习技术。陈天健表示,联邦迁移学习目前还处于研究阶段,是纵向联邦学习和横向联邦学习的一种增强、提升和统一,实际工业应用还有待进一步开发。
微众银行联邦学习实践三个阶段
纵观科技领域的大部分技术发展,两大重要节点:一是技术标准的确立;二是大规模落地实践。标准的完善,可以让更多企业愿意尝试该技术,大规模落地实践阶段会暴露出很多问题,这是技术走向成熟的必经之路。这两点都体现在了微众银行对联邦学习的落地过程中。
2018 年,在业务实践和行业观察中,陈天健所在团队发现训练 AI 所需要的大数据实际上很难获得,数据的控制权分散在不同机构、不同部门,“数据孤岛”问题严重,加之政策法规对数据隐私和数据安全的要求让数据共享和合作更加困难。
针对实际的业务痛点,他们发现联邦学习是一种行之有效的解决方案。从全球视野来看,随着数据保护立法不断深化,进程进一步加快,大数据合规合作的需求更为迫切,联邦学习蕴藏巨大的发展潜力。从 2018 年起,微众银行人工智能团队基于联邦学习理论研究进行相关开源软件研发,并且在 2018 年向 IEEE 提交联邦学习国际标准获批。
陈天健补充道,联邦学习的发展需要经历三个阶段,即“联邦学习理论研究发展阶段”,“批量应用落地阶段”与“联邦学习价值联盟网络建立阶段”。在经历以理论研究为重点的第一阶段之后,目前的联邦学习正在迈向批量应用的落地阶段(第二阶段)。
在第一阶段,联邦学习的探索主要是理论研究和小范围实践,搭建联邦学习生态框架。
从 2018 年到 2019 年初,微众银行发表了多篇联邦学习相关论文,对于联邦学习的概念、分类、基本原理等基础理论进行系统性研究;同时,在 2018 年向 IEEE 提交联邦学习国际标准获批;经过第一阶段探索,搭建起了理论研究、工具软件、技术标准、行业应用的多层级联邦学习生态框架,并且开始有腾讯、华为、京东、平安等生态合作伙伴加入。
第二阶段,联邦学习在更多领域行业落地,积累案例,联邦学习生态进一步扩大。
2019 年初,微众银行正式开源全球首个工业级联邦学习框架 FATE(Federated Learning Enabler),并开始尝试将联邦学习应用于金融业务中。
随着联邦学习理论研究的深入,微众银行在国内、国际大会上联合多家合作伙伴举办联邦学习研讨会,比如国际顶会 IJCAI 和 NeruIPS,国内计算机学会 CCFTF 等,吸引了更多研究者加入;FATE 开源社群也渐渐吸纳上百家机构应用和共建;行业落地在金融领域更加深入,在风控、反洗钱领域的应用均取得了很好的效果。
而在标准制定层面,IEEE 国际标准预计于今年出台草案,国内首个联邦学习团体标准于 2019 年 6 月发布,目前也在积极提案将联邦学习纳入国家标准。
2019 年至今,越来越多的合作伙伴加入,无论是 FATE 的共同开发实践,还是标准讨论、理论研究,联邦学习越来越为行业所知,也受到了政府部门的关注。
实践成果开源框架
在实践过程中,微众银行开源了联邦学习平台 FATE,该项目于 2019 年 1 月份首次上线,近期发布了 FATE 1.2 版本,这是一种通用的纵向联邦神经网络算法解决方案,可将深度学习算法应用于分散割裂的数据中。
联邦神经网络算法的实现依赖 FATE 1.2 新增的核心功能模块:SecretShare 多方安全计算协议。同时,联邦化的特征变量相关性分析也依赖此模块。在金融风控领域,特征变量间相关性分析是一个非常重要的风控建模步骤。
据陈天健透露,FATE 项目研发大体有三大方向:
打通与三大深度学习框架 Tensorflow,Pytorch,PaddlePaddle 的互操作;
持续提升实际商业化场景中,联邦建模的性能、易用性和可管理性;
不断应对新的数据安全挑战和合规要求。
微众银行正在基于 FATE 构建一个基于联邦学习的数据合作网络。在这个网络里面,越来越多的企业可以找到对其业务有帮助的合作企业,并进行合规的安全数据合作。陈天健表示,目前正在推进的包括银行业,保险业,零售业等多个领域的批量应用落地。
标准制定
国际技术标准会为业界提供通用的技术沟通语言,无论本身是怎样的技术架构和技术工具,在统一的标准下,大家才能更好地协作,这对于联邦学习这个本身就强调“联邦”合作机制的技术范式来说尤为重要。
对于联邦学习这项新技术而言,技术标准的出台将标志着技术向更通用、更成熟的方向发展,为社会各界共建联邦生态奠定基础,同时为立法和监管提供技术依据。理想情况下,不同厂商基于同一技术标准开发的联邦学习系统可以相互协作,就像现在的网络设备一样。
作为国内“联邦学习”技术的首倡者,微众银行不断推进联邦学习的标准化建设工作。陈天健表示,根据已召开的四次联邦学习标准工作组会议的讨论,标准内容大致包含联邦学习的定义、框架,以及在 To B(企业端)、To C(用户端)以及 To G(政府端)不同情境下的场景分类、联邦学习的安全测评等内容。
从时间周期上来说,IEEE 联邦学习标准草案预计在今年上半年出台,正式的标准预期最快下半年发布。
金融企业实践建议
从一项技术真正成为关键系统和产品方案,微众银行在这个过程中也遇到了很多挑战,比如一站式建模过程的联邦化;广域网场景下的分布式加密机器学习算法的 易理解和易维护;跨站点数据传输安全性和可管理性,如何让交互部分是可以被管理和被审计的等。
对于同样希望部署联邦学习的金融企业,陈天健结合微众银行的实践经验给出了一些建议。他表示,首先,金融企业需要意识到,数据规制的严格化是个趋势性问题,因此需要在制定企业长期发展所依赖的数据战略时,将联邦学习技术作为数据发展战略的一个重要组成部分。
其次,与大数据打交道最为频密的中台部门,例如风险管理部,需要牵头对联邦学习应用进行验证和改进,以一个示范应用为突破,再推广到其他。
Third, you need to choose a more reliable and compliant data partner, because federated learning is a data protection technology, not all of data protection. The premise of federal learning compliance is to assume that the data collection process of all parties is compliant, which must be guaranteed.
Finally, at the technical level, we must choose open, open source, and third-party auditable technologies. On the one hand, open source guarantees the continuity of technology supply; on the other hand, open source guarantees the feasibility of third-party audits. For example, FATE, which has become a federal learning international project hosted by the Linux Foundation, would be a better choice.
Interview guests:
Chen Tianjian, deputy general manager of WeBank's artificial intelligence department, is responsible for the construction of bank intelligence and federal learning technology ecology. Worked in many technology companies such as Baidu, Xunlei, BGI, and served as Baidu Chief Architect (T10), Baidu Finance Chief Architect, designing the overall structure and structure of Baidu search, recommendation, big data, finance and other businesses Critical system.