
Author | Cai Fangfang In the past two years, federated learning has developed rapidly, and it has begun to move from theoretical research to the stage of batch application. More and more companies try to introduce federated learning to solve the data bottleneck problem encountered in the large-scale deployment of artificial intelligence. . However, the ready-made federated learning tools and frameworks are not a “magic bullet” that is ready to use. If federated learning is to truly play a role in the actual business scenarios of enterprises, there are still many problems to be explored, such as how to match the actual needs of the business and how to be compatible with existing ones. Business processes, how to minimize changes to the existing training system, etc. To this end, InfoQ interviewed the intelligent learning team of Tencent’s TEG Data Platform Department to gain an in-depth understanding of the practice of federated learning in Tencent and their solutions to the technical difficulties of federated learning.
Development History of Federal Learning Technology
As early as 2016, Google first proposed the concept of Federated Learning in the paper "Federated Learning: Strategies for Improving Communication Efficiency", which is mainly used to solve the data that exists in multiple terminals (such as mobile phones). Carry out the problem of centralized model training, and apply it to scenarios such as input method improvement.
However, for a considerable period of time since then, Federated Learning has been in the stage of theoretical research, and there are not too many landing cases. There may be several reasons for this: First, there is a lack of demand. In the past two or three years, artificial intelligence has developed rapidly and has reached the stage of landing. It is bound to face the problems of where the data comes from and how to get through, but there is no data to get through before this. The problem, naturally, there will be no need for federated learning; secondly, the technical maturity is not enough. In the Federated Learning model proposed by Google, a central server is required to collect the local models trained by all parties for aggregation. Then the problem lies in Is this central server credible and reliable? In addition, this model requires the data attributes of different participants to be the same. For example, the data of Zhang San and Li Si are required to be age, height, and gender. Although their specific values are different, the attributes must be the same.
In the paper "Federated Machine Learning: Concept and Applications" published in early 2019, Professor Yang Qiang of Hong Kong University of Science and Technology further developed Federated Learning and proposed two frameworks, Horizontal (Horizontal) and Vertical (Vertical) Federated Learning, as shown in Figure 1 below. As shown, the model proposed by Google can be regarded as a kind of horizontal federation.
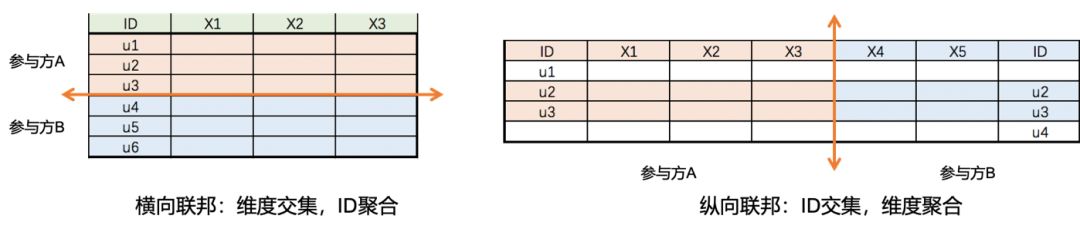
With the continuous development and maturity of technology and the increasingly prominent data pain points in the process of artificial intelligence landing, federal learning has received more attention, academia and industry have begun to unite and systematically study the entire technology system, and there are more and more companies Begin to try to introduce federated learning as a solution to open up multi-party data.
Tencent Federal Learning Practice
Based on the self-developed distributed machine learning platform Angel launched in 2016 (open sourced on GitHub in 2017), the Angel intelligent learning team of Tencent's TEG Data Platform Department is working on a federal learning project. According to reports, the development of Angel federation learning is mainly driven by business needs.
In machine learning, especially deep learning, the acquisition of a model requires a large amount of training data as a prerequisite. Since being launched internally in Tencent in early 2016, Angel has been applied to businesses such as WeChat Pay, QQ, Tencent Video, Tencent social advertising, and user portrait mining. As Angel is used more and more widely within companies and partners, in many business scenarios, the training data of the model is often scattered in different business teams, departments, and even different companies. For example, in order for the advertising recommendation model to obtain accurate recommendations for each user, in addition to the user's basic natural attributes, it also needs the user's behavior data, such as web browsing behavior, contextual information, purchase and payment behavior, etc. These behavioral data are usually used in other products such as browsers, news sites, games, or content, and cannot be directly used to train advertising models. How to combine multiple data sources for model training under the premise of protecting user privacy has become a new challenge for Angel's intelligent learning team.
At the beginning of October 2019, a special team was established within the team to start the development of a federal learning platform. First, sort out and integrate business requirements and find common key issues; then investigate whether there are mature solutions in academia and the industry that can meet business scenarios; finally, focus on solving the landing problems, namely, safety, ease of use, efficiency and stability.
Among them, the business requirements mainly have the following characteristics:
90% of the scenarios are vertical federated learning problems, that is, the same ID and joint modeling in the data dimension. Take advertising as an example. One party has a basic portrait of the user, mainly static tags, while the other party has information about their purchasing behavior and interests. The demand is how to safely and effectively combine the data of the two parties.
Users generally care about safety issues, that is, whether the learning process is safe. In addition to the final output model parameters, the data information of any party should not be leaked in the process, nor can the intermediate results of the data information be reversed.
For efficiency and stability issues, the platform's training speed should not be too slow, and it should be stable to reduce the cost of problem investigation and task re-running.
To be compatible with the existing business process, do not change the existing training system too much. In addition, it must be easy to deploy, and the system must not be too complicated.
Based on the investigation of the business and existing technical solutions, the team redesigned a "decentralized" federated learning framework without relying on a trusted third party. The entire system uses Angel's high-dimensional sparse training platform as the bottom layer, and abstracts the "algorithm protocol" layer to implement various common machine learning algorithms.
Angel federated learning system architecture
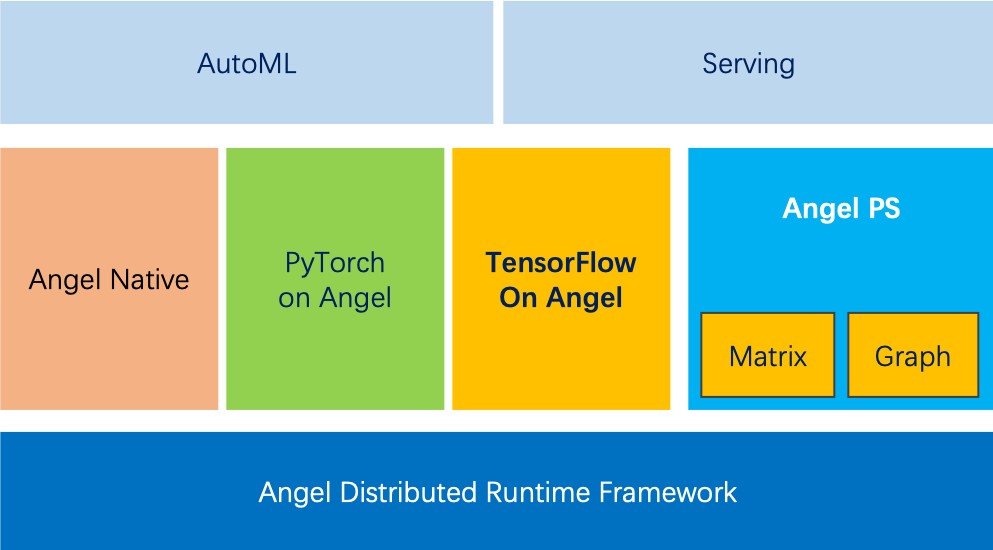
From a technical perspective, the architecture of the distributed machine learning platform Angel is shown in Figure 2. Its core component is the Angel PS parameter server. In the field of machine learning, when the parameter scale of the model reaches high-dimensional, such as hundreds of billions, a single machine's memory can no longer accommodate such large-scale data. It must rely on a distributed method to use multiple machines to complete the training task. The parameter server is one of the better solutions. Angel PS has made a lot of optimizations for high-dimensional sparse scenes, such as batch processing of parameter updates, and many calculations on the worker are upgraded to the PS-side calculation, which improves the calculation efficiency and consistency, and accelerates the algorithm convergence speed. Angel PS currently supports trillion-level models. At the same time, the bottom layer of the entire Angel platform is based on Spark. Using the efficiency and flexibility of Spark RDD, it is easy to connect with big data systems such as HDFS and has high compatibility; the backend can be connected to TensorFlow, PyTorch, etc. as runtime operators.
腾讯目前整个联邦学习框架构建在 Angel 之上,以两个业务方 A 和 B 为例,Angel 联邦学习系统架构如图 3 所示(也可以扩展到多个参与方的场景)。
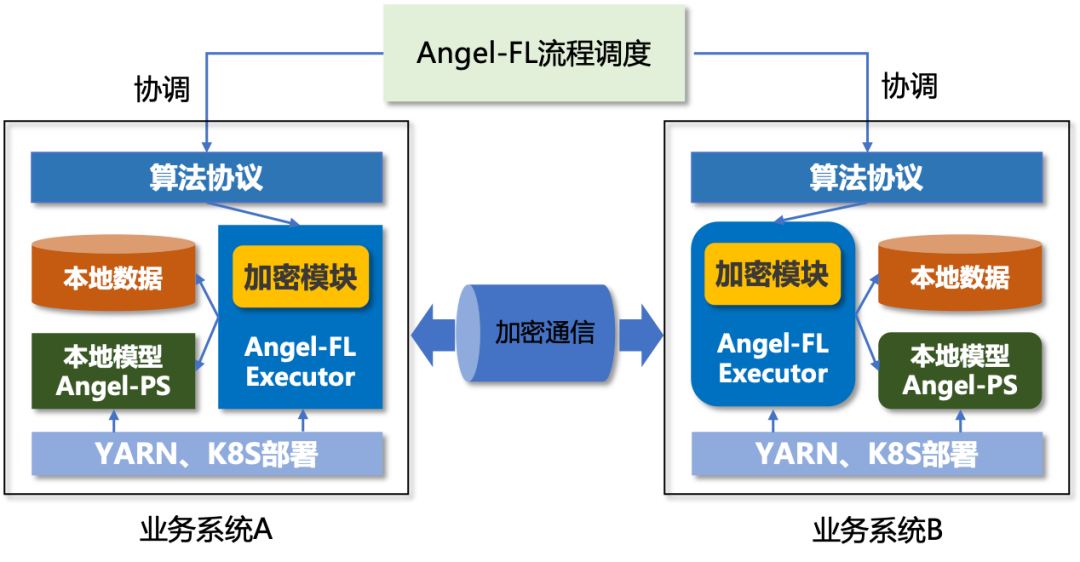
A、B 双方分别拥有各自的与用户相关的数据,存储在本地集群,在整个联合建模的训练过程中,A 和 B 双方的原始数据均不出本地。可以看到,架构具有以下特点:
A、B 两方独立部署 Angel 联邦学习的本地框架,支持 YARN、K8S 多种资源申请方式,与业务现有系统完全兼容,灵活易用;
本地训练框架 Angel-FL Executor 的计算采用 Spark,充分利用其内存优先和分布式并行的优点,效率高且易于和现有大数据生态(如 HDFS 等)打通;
本地模型保存在 Angel-PS 参数服务器中,支持大规模数据量训练;同时,PS 写有 checkpoint,意外失败的任务可以从上次保存的进度继续执行,具有很好的容错性;
模型训练相关的数据经过加密模块加密后,在 A、B 两方之间直接通信而不依赖第三方参与“转发”,实现了“去中心化“,整个训练流程仅需要协调双方的进度即可,能够增强实际应用中的安全性。
在上述系统框架的基础上,再抽象出一层算法协议层,利用平台提供的计算、加密、存储、状态同步等基本操作接口,实现各种联邦机器学习算法。在训练任务执行时,通常拥有标签的一方作为训练的驱动方,算法协议层会控制本地训练步骤,例如梯度计算、残差计算、模型更新、消息发送等,同时与 Angel-FL 流程调度模块交互同步执行状态,并按照协议触发对方进行下一步动作。
一个典型的算法过程如下图 4 所示:
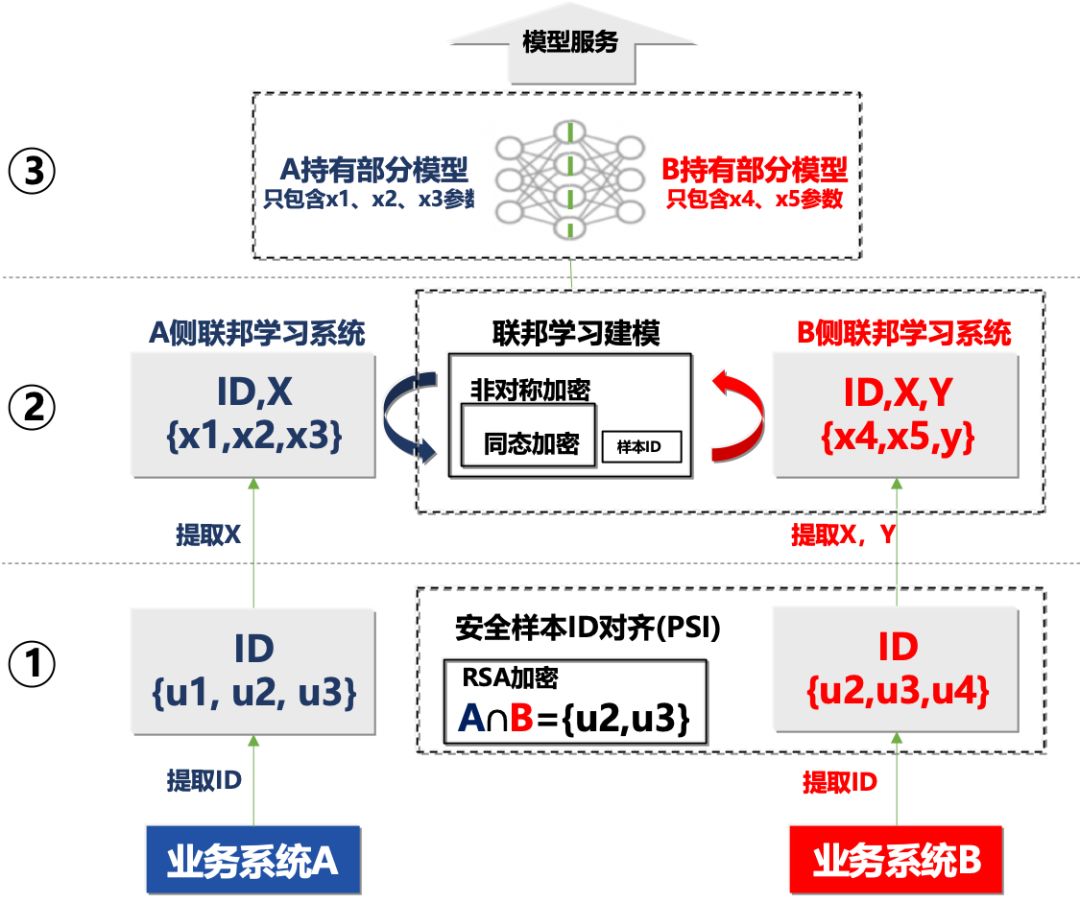
假设还是两个业务系统 A 和 B,其中 ID 表示样本 id 的集合,X 表示维度数据,Y 表示 ID 样本标签,联邦学习的目的是联合 A 和 B 的 X 来训练得到能预测 Y 的最优模型。B 拥有标签,将作为训练的发起方,过程如下:
1)A、B 双方提取样本 ID,通过加密算法加密后,在 B 方进行安全样本 ID 对齐(PSI),得到双方共同的 ID 集合的交集 A^B = {u2, u3}; A,B 均不知对方除了交集外的部分;
2)根据交集 ID,双方提取相应样本的维度数据 X,先在计算本地模型数据如梯度,然后 A 通过加密方式,将中间数据发送给 B,B 根据标签计算预测误差,并将模型更新信息加密后传回 A;
3)模型收敛后训练结束,A、B 分别持有模型中与自己维度 X 相关部分的参数,并共同提供模型服务。
2019 年年底,Angel 智能学习团队已经完成了上图中 Angel 联邦学习框架的 Demo 原型验证,证明了系统可以满足业务场景的需求,并开始产品系统的开发。
技术难点
在技术层面,Angel 联邦学习系统存在几个主要的难点:
- “去中心化”。Angel 联邦学习系统主要采用了密码学中的同态加密算法,该加密算法有一个特点是:对经过同态加密后的密文数据进行运算,将运算结果解密,与未加密的原始明文数据进行同样运算的结果是一样的。利用这种特点,研发团队对需要双方交互的模型相关数据采用同态加密,直接发送给对方,对方在密文上完成训练所需的计算,然后将结果返回,接收方解密后,能得到计算后的结果,而无法获知其原始数据。
- 消息通信膨胀,这个问题也与同态加密有关。采用高强度加密算法,例如如果采用 2048 位 Paillier 加密,一个浮点数的体积将膨胀到 4096 位。研发团队采用 bit-packing 的方法压缩了密文的体积,从而较少网络传输量。
- 跨网传输消息拥塞。算法在训练过程中通常有大量的数据需要交换,这导致网络传输量巨大,而联邦的双方一般处于不同网络域中,如果采用简单的 RPC 点对点通信,容易引起交换机 in-cast 现象而导致消息拥塞。为了解决这一问题,研发团队采用 MessageQueue 作为消息管道,控制拥塞并提供消息持久化功能,增强系统稳定性。
- 加密解密加速。联邦学习涉及大量的数字加密和解密操作,属于计算密集型任务,可以采用硬件如 GPU 加速来解决,这方面研发团队正在探索中。
早期应用
目前,整个 Angel 联邦学习框架已初步成型,并逐渐在实际场景中落地。在腾讯内部,Angel 联邦学习已经在金融私有云、广告联合建模等业务中开始尝试落地应用。
以广告场景为例,广告用户画像数据库中有用户的基础属性标签,如性别、年龄等,而其他业务上则有更丰富的行为数据,如何综合这些数据维度给用户更好的广告推荐?针对这个场景,Angel 智能学习团队用多分类问题建模,以候选广告为分类标签,采用联邦 GBDT 算法来训练分类器。在 500 百万训练样本、100 万测试样本、500 维数据特征的数据集上,联邦 GBDT 算法的训练和测试 ACC 准确率均达到 80% 以上,具体提升指标还在业务放量收集中。
另外,Angel 智能学习团队还在腾讯内部筹建了联合项目组,由多个团队参与共建,接下来将对联邦学习框架做进一步的性能优化,并开发更多联邦学习算法,例如 FM、神经网络等。
未来展望
虽然联邦学习技术正在快速演进,但从国内企业的整体落地情况来看,联邦学习在业界还处于早期阶段。在安全标准上,还没有一套完善且业界都认可的安全认定标准出台;加密和解密带来的计算量剧增也需要性能优化;深度学习等复杂算法如何改造成联邦学习模式也是面临的挑战。
目前,不同企业和研究团队在上述这些技术发展的细节上还存在分歧,但 Angel 智能学习团队认为这并不妨碍联邦学习在各个实际场景的应用,分歧反而可能成为促进发展的催化剂,过多纠结于这些分歧,不如去应用场景中寻找答案。
Like the development of most technologies, federated learning technology will also experience concept germination, to a trough period, and then to a process of gradual attention. In the eyes of the Angel intelligent learning team, federated learning technology has its unique value. If conventional machine learning solves the problem of model training on a department’s own data, then federated learning is to solve the problem of how to train the model on the data of different departments. , Which expands the boundaries that machine learning can reach. With the continuous implementation of artificial intelligence technology, federated learning will play an increasingly important role in cross-departmental cooperation and data privacy protection, and has broad application prospects.