Fun Big Data Day2
An introductory course on Datawhale's 
big data technology-related content: Juicy Big Data
3. Hadoop Distributed File System (HDFS)
1. Distributed file system
Distributed file system : manage the file system stored across multiple computers in the network; solve the problem of efficient storage of massive data.
Files are stored in "blocks", and a block is the basic unit of data reading. The default block size of HDFS is 64MB (ordinary file system disk blocks are 512 bytes). The purpose of designing relatively large blocks is to minimize the addressing overhead; at the same time, it is also necessary to avoid the impact of too large blocks on the parallel speed of MapReduce.
Design: "Client/Server"
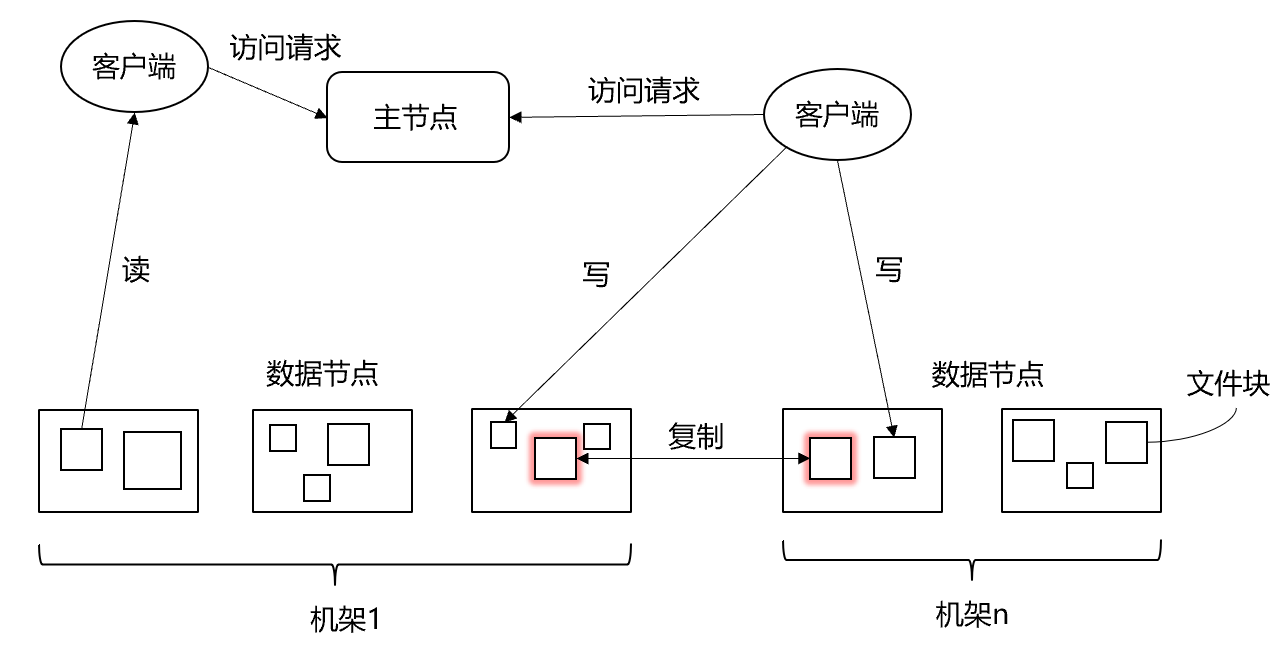
Physical structure:
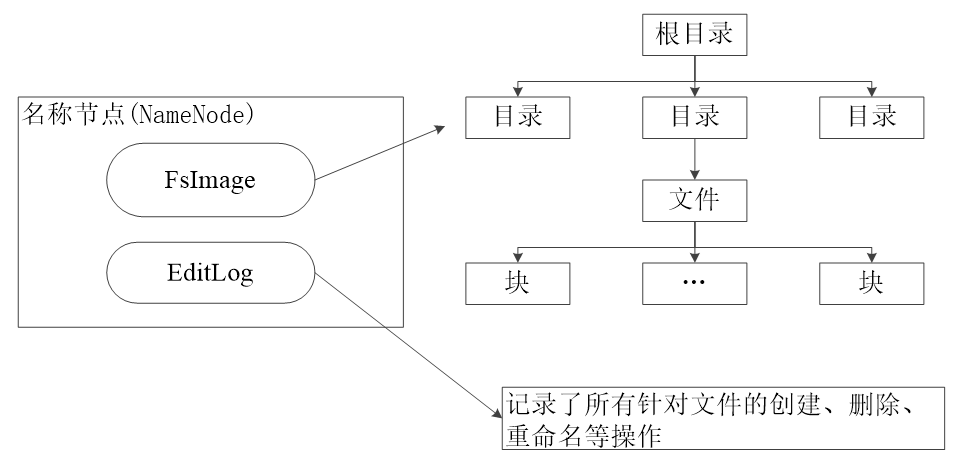
- Master Node, NameNode
- Creation, deletion and renaming of files and directories
- Manage the mapping relationship between data nodes and file blocks
- From the node (Worker Node), the data node (DataNode)
- Data storage and reading
- The distributed file system adopts multi-copy storage to ensure data integrity
- Distributed file system designed for large-scale data storage (TB-level files)
2. Introduction to HDFS
HDFS(Hadoop Distribute File System)
- It is a storage system for storing large data files in a distributed manner in the field of big data
- HDFS is the data storage layer for Hadoop and other components
advantage:
- Compatible with cheap hardware devices : to ensure data integrity even in the event of hardware failure
- Stream data read and write : does not support random read and write operations
- Large data sets : the amount of data is generally at the level of GB or TB
- Simple file model : write once, read many
- Strong Cross-Platform Compatibility :
JavaImplemented in Languages
limitation:
- Not suitable for low-latency data access : streaming data reading, high latency
- Unable to efficiently store a large number of small files : affect metadata reduction efficiency, increase Mpa task thread management overhead, frequent jumps between data nodes affect performance
- Does not support multi-user writing and arbitrarily modifying files : a file has only one writer, and only append operations are allowed on the file
3. HDFS Architecture
Master-slave (Master/Slave) structure model
An HDFS cluster includes:
- A name node (NameNode)
- Several data nodes (DataNode)
- Send "heartbeat" information periodically to report status
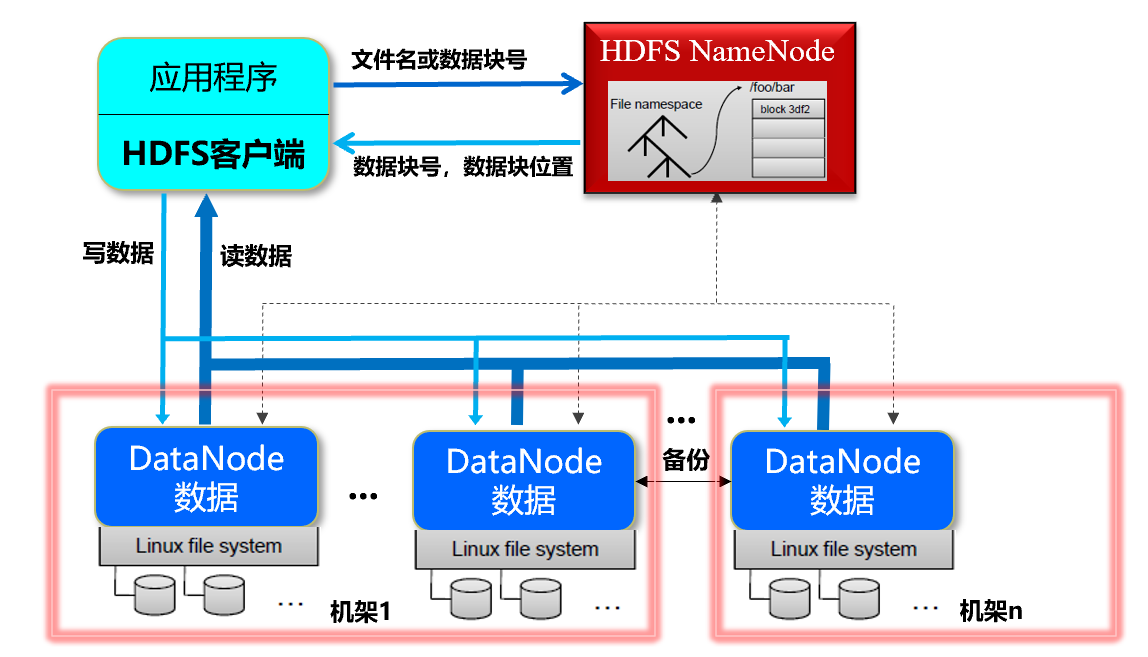
【Description】Users use HDFS,
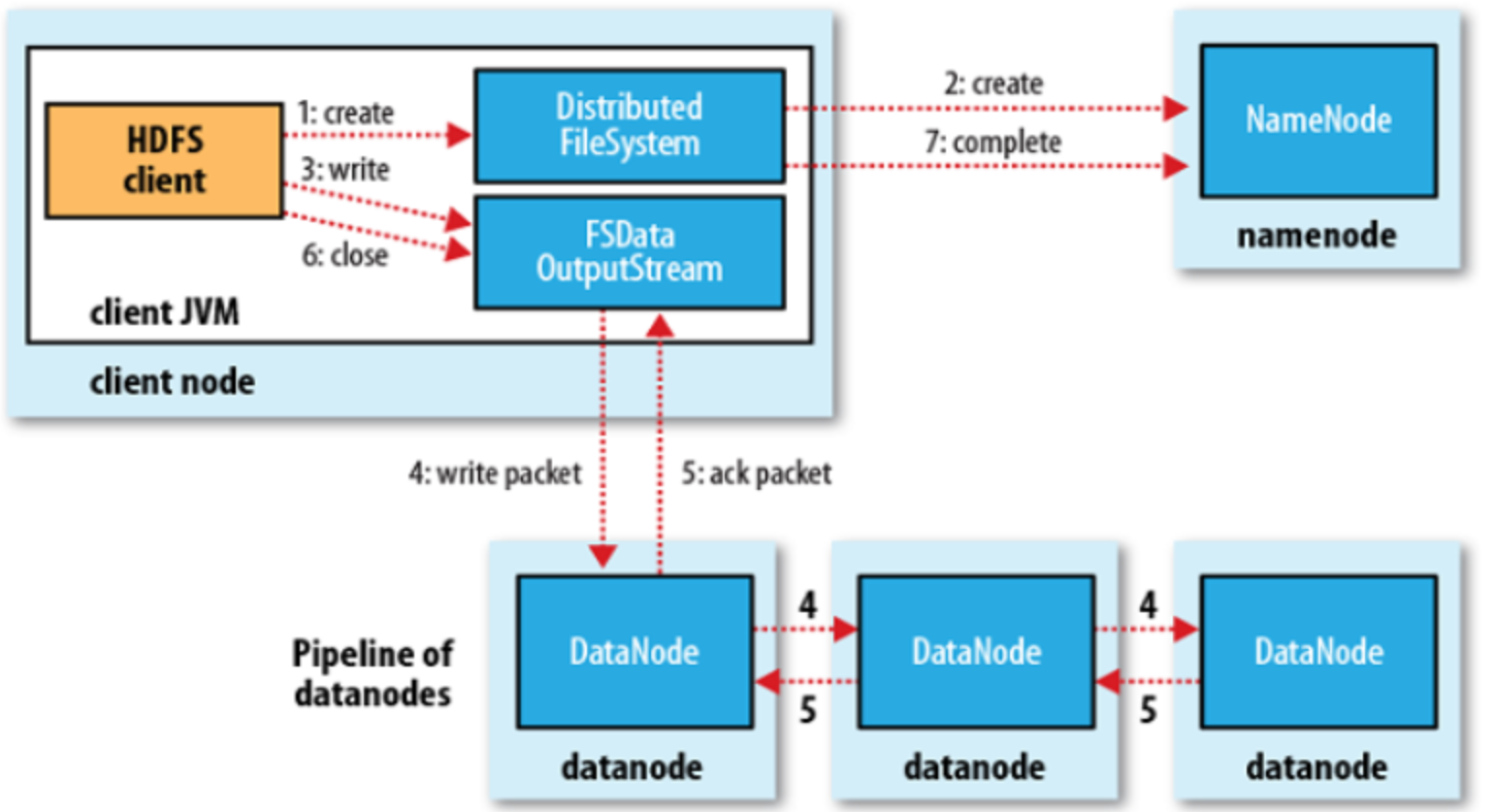
When client storage:
- A file is divided into several data blocks for storage
- Each data block is distributed and stored on several DataNodes
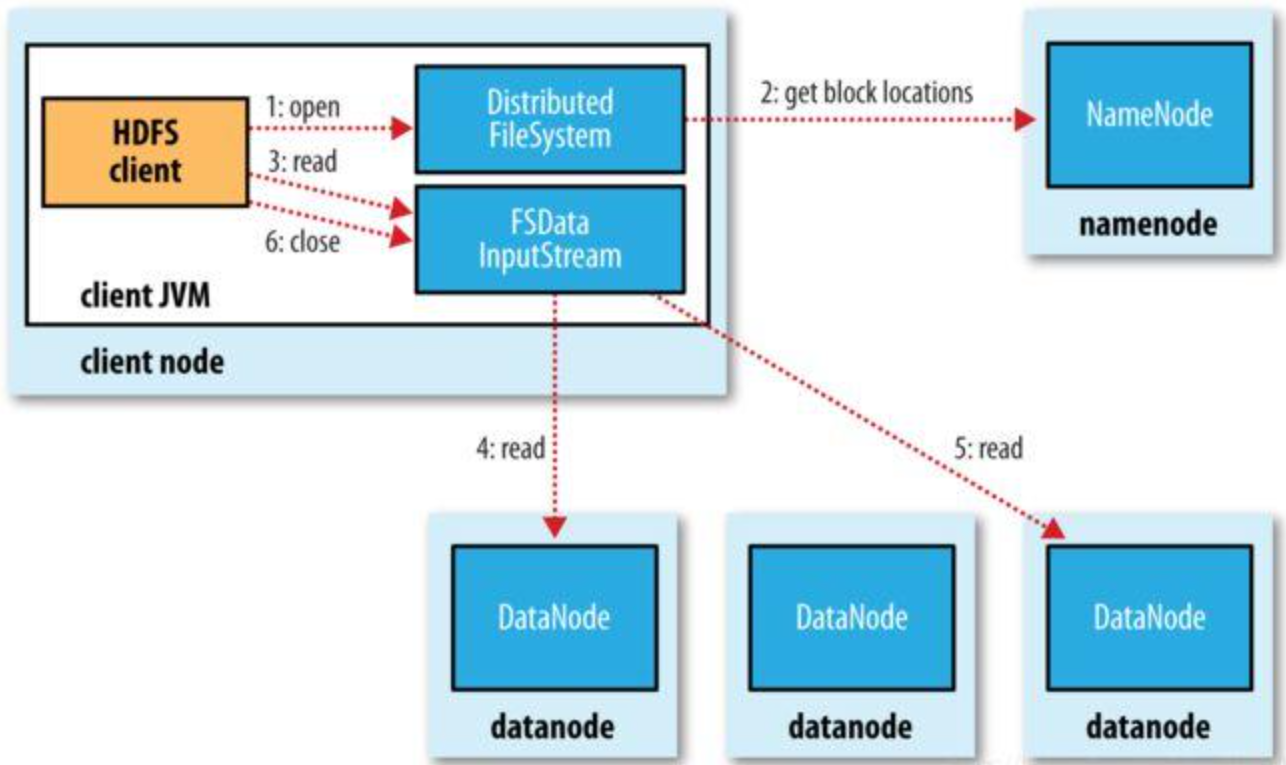
When the client reads:
- Get data block and data block location from NameNode according to file name (DataNode)
- Access DataNode to get data
[Advantages] Improved data access speed, concurrent access from different DataNodes when reading a file
4. HDFS storage principle
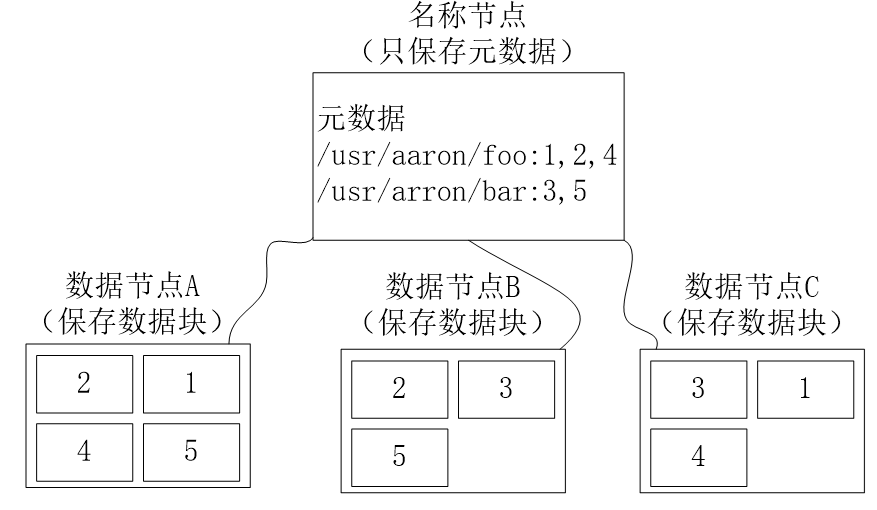
data redundant storage
In multi-copy mode , multiple copies of a data block are distributed to different data nodes
- Speed up data transfer
- Easy to detect data errors
- Ensure data reliability
data storage strategy
-
data storage
-
HDFS adopts a data storage strategy based on **rack (Rack)**, and an HDFS cluster usually includes multiple racks
- Data communication between different racks needs to go through switches or routers
- Data communication between different machines in the same rack does not require switches or routers (the communication bandwidth is larger than that between different racks)
-
By default, each data node of HDFS is on a different rack
-
Disadvantage : When writing data, the bandwidth between internal machines in the same rack cannot be fully utilized
-
Advantages : 1. High data reliability
2. Multiple racks read data in parallel to improve data reading speed
3. It is easier to achieve load balancing and error correction within the system
-
-
HDFS default redundancy replication factor is 3
- Each file will be saved to 3 places at the same time
- Two copies are placed on different machines in the same rack
- The third copy is placed on a machine in a different rack
- Each file will be saved to 3 places at the same time
-
-
data read
- HDFS provides an API to determine the ID of the rack to which the DataNode belongs, and read it nearby
-
data replication
- Pipeline replication (after the first DataNode writes data, it will pass the data and list to the second DataNode according to the DataNode in the list, and so on)
Data Error and Recovery
-
NameNode error
- Synchronous storage of NameNode metadata information to other file systems
- second name node
-
DataNode error
- If the NameNode does not receive the 'heartbeat' information from the DataNode, it is defined as 'downtime', the data is marked as unreadable, and the I/O request is canceled
- When the name node checks and finds that the number of copies of a certain data is less than the redundancy factor, start data redundancy replication to generate a new copy
-
data error
- Network transfer and disk errors
md5Sumsha1check, information file check
5. HDFS data read and write process
read and write process
Types of HDFS failures and their detection methods
- Handling of read and write failures
- Read: Read from other backup nodes (NameNode will return all DataNodes where the data block exists)
- Write: Did not receive the response signal from DataNode to accept the data block, adjust the channel to skip this node
-
DataNode fault handling
-
NameNode table
- Data block list: data block N - stored in DN1, DN2, DN3
- DataNode list: DATANODE 1 - store data block 1,..., data block N
-
Keep updating these two tables
-
DataNode backup will be started if the data is not fully backed up (provided that there is at least one backup in HDFS)
-
-
Replica layout strategy
- The first one: nearest
- Subsequent: different racks (up to two copies per rack)
HDFS Programming Experiment
1. Operation between local and cluster files
# 拷贝目录到集群
hadoop fs -put <local dir> <hdfs dir>
# 拷贝文件
hadoop fs -put <local file> <hdfs dir>
# 拷贝到本地
hadoop fs -get < hdfs file or dir > < local file or dir>
# 拷贝并移除
hadoop fs -moveFromLocal <local src> <hdfs dst>


2. Basic file operations
# 查看
hadoop fs -ls / # -R: 包含子目录下文件
# 删除
hadoop fs -rm -r <hdfs dir> ...
hadoop fs -rm <hdfs file> ...
# 创建
hadoop fs -mkdir <hdfs path>
# 复制
hadoop fs -cp <hdfs file or dir>... <hdfs dir>
# 移动
hadoop fs -mv <hdfs file or dir>... <hdfs dir>
# 统计路径下的目录个数,文件个数,文件总计大小
hadoop fs -count <hdfs path>
#显示文件夹和文件的大小
hadoop fs -du <hdsf path>
# 查看文件
hadoop fs -cat /demo.txt
hadoop fs -tail -f /demo.txt
# 更改权限
hadoop fs -chown user:group /datawhale
hadoop fs -chmod 777 /datawhale
![[External link picture transfer failed, the source site may have an anti-leeching mechanism, it is recommended to save the picture and upload it directly (img-ObVAZO1S-1676724750207)(HDFS/image-20230218171901366.png)]](https://img-blog.csdnimg.cn/683538375ed349de99e8ece10c41820a.png#pic_center)
# 本地文件内容追加到hdfs文件系统中的文本文件
hadoop fs -appendToFile <local file> <hdfs file>
![[External link picture transfer failed, the source site may have an anti-leeching mechanism, it is recommended to save the picture and upload it directly (img-H9cJuM6m-1676724750207)(HDFS/image-20230218202538200.png)]](https://img-blog.csdnimg.cn/2cf7535a6b5c45d8804a9e97da5cb307.png#pic_center)
An error is encountered here:Failed to APPEND_FILE /p1 for DFSClient_NONMAPREDUCE_985284284_1 on 192.168.137.101 because lease recovery is in progress. Try again later.
Solution: hdfs dfs -appendToFile error problem solving
# 修改 hdfs-stie.xml 文件
<!-- appendToFile追加 -->
<property>
<name>dfs.support.append</name>
<value>true</value>
</property>
<property>
<name>dfs.client.block.write.replace-datanode-on-failure.policy</name>
<value>NEVER</value>
</property>
<property>
<name>dfs.client.block.write.replace-datanode-on-failure.enable</name>
<value>true</value>
</property>
3. Hadoop system operation
# 改变文件在hdfs文件系统中的副本个数
hadoop fs -setrep -R 3 <hdfs path>
# 查看对应路径的状态信息
hdoop fs -stat [format] < hdfs path >
# %b:文件大小
# %o:Block大小
# %n:文件名
# %r:副本个数
# %y:最后一次修改日期和时间
# 手动启动内部的均衡过程(DataNode 数据保存不均衡)
hadoop balancer # 或 hdfs balancer
# 管理员通过 dfsadmin 管理HDFS
hdfs dfsadmin -help
hdfs dfsadmin -report
hdfs dfsadmin -safemode <enter | leave | get | wait>
![[External link picture transfer failed, the source site may have an anti-leeching mechanism, it is recommended to save the picture and upload it directly (img-WPScNjvH-1676724750207)(HDFS/image-20230218204809616.png)]](https://img-blog.csdnimg.cn/b94e06de44f84f5c9fa6ddc7d1cd09a5.png#pic_center)
![[External link picture transfer failed, the source site may have an anti-leeching mechanism, it is recommended to save the picture and upload it directly (img-IjuanMXa-1676724750208)(HDFS/image-20230218205017836.png)]](https://img-blog.csdnimg.cn/609cfeaf796446e9aa9f5d7eb0f3afb6.png#pic_center)
An introductory course on Datawhale's
big data technology-related content: Juicy Big Data