Create a Simulink environment and train the agent
This example shows how to convert a PI controller in a watertank Simulink® model. Use Reinforcement Learning Deep Deterministic Strategy Gradient (DDPG) agent.
Water tank model
The original model for this example is the water tank model. The purpose is to control the water level in the water tank.

Modify the original model by making the following changes:
-
Delete the PID controller.
-
Insert the RL Agent block.
-
Connect the observation vector [∫ e dt e h] [\int e\, dt\, e \,h][∫edteh ] , inhhh is the height of the water tanke = r − he = r − he=r − h and $r $ are the reference heights.
-
Set reward reward = 10 (∣ e ∣ <0.1) − 1 (∣ e ∣ ≥ 0.1) − 100 (h ≤ 0 ∣ ∣ h ≥ 20) 10(|e|< 0.1)-1(|e| \geq 0.1 )-100(h\leq0||h\geq20)10(∣e∣<0.1)−1(∣e∣≥0.1)−100(h≤0∣∣h≥20)。
-
Configure the termination signal so that the simulation stops under the following conditions h ≤ 0 h ≤ 0h≤0 orh ≥ 20 h ≥ 20h≥20。
open_system('rlwatertank')
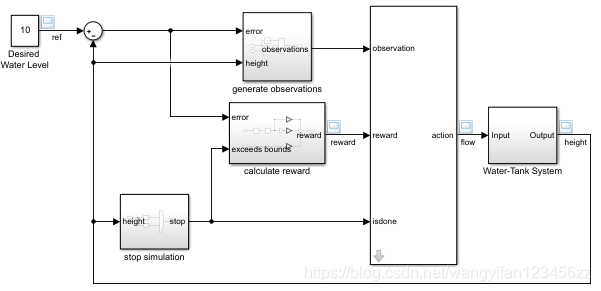
Create environment interface
Creating an environment model includes defining the following:
-
The actions and observation signals used by the agent to interact with the environment.
-
The agent uses reward signals to measure its success.
obsInfo = rlNumericSpec([3 1],...
'LowerLimit',[-inf -inf 0 ]',...
'UpperLimit',[ inf inf inf]');
obsInfo.Name = 'observations';
obsInfo.Description = 'integrated error, error, and measured height';
numObservations = obsInfo.Dimension(1);
actInfo = rlNumericSpec([1 1]);
actInfo.Name = 'flow';
numActions = actInfo.Dimension(1);
Build environment interface objects.
env = rlSimulinkEnv('rlwatertank','rlwatertank/RL Agent',...
obsInfo,actInfo);
Set up a custom reset function to randomize the reference value of the model.
env.ResetFcn = @(in)localResetFcn(in);
Specify the simulation time Tf and the agent sampling time Ts in seconds.
Ts = 1.0;
Tf = 200;
Fix random generator seed to improve repeatability.
rng(0)
Create DDPG agent
Given observations and operations, DDPG agents use the reviewer value function to express approximate long-term rewards. To create a commenter, you first need to create a deep neural network with two inputs, namely observation and action, and one output. For more information on creating deep neural network value function representations, see Creating Strategy and Value Function Representations.
statePath = [
imageInputLayer([numObservations 1 1],'Normalization','none','Name','State')
fullyConnectedLayer(50,'Name','CriticStateFC1')
reluLayer('Name','CriticRelu1')
fullyConnectedLayer(25,'Name','CriticStateFC2')];
actionPath = [
imageInputLayer([numActions 1 1],'Normalization','none','Name','Action')
fullyConnectedLayer(25,'Name','CriticActionFC1')];
commonPath = [
additionLayer(2,'Name','add')
reluLayer('Name','CriticCommonRelu')
fullyConnectedLayer(1,'Name','CriticOutput')];
criticNetwork = layerGraph();
criticNetwork = addLayers(criticNetwork,statePath);
criticNetwork = addLayers(criticNetwork,actionPath);
criticNetwork = addLayers(criticNetwork,commonPath);
criticNetwork = connectLayers(criticNetwork,'CriticStateFC2','add/in1');
criticNetwork = connectLayers(criticNetwork,'CriticActionFC1','add/in2');
Observe the configuration of the commenter's network.
figure
plot(criticNetwork)

Use the rlRepresentationOptions represented by the specified commenter.
criticOpts = rlRepresentationOptions('LearnRate',1e-03,'GradientThreshold',1);
Create a commenter representation using the specified deep neural network and options. You must also specify the reviewer’s operation and observation specifications, which you can obtain from the environment interface.
critic = rlQValueRepresentation(criticNetwork,obsInfo,actInfo,'Observation',{
'State'},'Action',{
'Action'},criticOpts);
Given the observations, the DDPG agent uses the participant's representation to decide the action to take. To create a character, you must first create a deep neural network with one input (observation) and one output (action).
Construct actors in a manner similar to critics.
actorNetwork = [
imageInputLayer([numObservations 1 1],'Normalization','none','Name','State')
fullyConnectedLayer(3, 'Name','actorFC')
tanhLayer('Name','actorTanh')
fullyConnectedLayer(numActions,'Name','Action')
];
actorOptions = rlRepresentationOptions('LearnRate',1e-04,'GradientThreshold',1);
actor = rlDeterministicActorRepresentation(actorNetwork,obsInfo,actInfo,'Observation',{
'State'},'Action',{
'Action'},actorOptions);
To create a DDPG agent, first use to specify the DDPG agent options rlDDPGAgentOptions.
agentOpts = rlDDPGAgentOptions(...
'SampleTime',Ts,...
'TargetSmoothFactor',1e-3,...
'DiscountFactor',1.0, ...
'MiniBatchSize',64, ...
'ExperienceBufferLength',1e6);
agentOpts.NoiseOptions.Variance = 0.3;
agentOpts.NoiseOptions.VarianceDecayRate = 1e-5;
Then, create a DDPG agent using the specified participant representation, commenter representation, and agent options.
agent = rlDDPGAgent(actor,critic,agentOpts);
Training agent
To train the agent, first specify the training options. For this example, use the following options:
-
Each training is carried out at most 5000 times. Specify that each episode lasts up to 200 times.
-
Display the training progress in the "Plot Manager" dialog box (set the Plots option), and disable the command line display (set the Verbose option to false).
-
When the average cumulative reward obtained by the agent in 20 consecutive episodes is greater than 800, please stop training. At this time, the agent can control the water level in the water tank.
maxepisodes = 5000;
maxsteps = ceil(Tf/Ts);
trainOpts = rlTrainingOptions(...
'MaxEpisodes',maxepisodes, ...
'MaxStepsPerEpisode',maxsteps, ...
'ScoreAveragingWindowLength',20, ...
'Verbose',false, ...
'Plots','training-progress',...
'StopTrainingCriteria','AverageReward',...
'StopTrainingValue',800);
Use the train function to train the agent. Training is a computationally intensive process that takes a few minutes to complete. In order to save the time of running this example, please load the pre-trained agent false by setting doTraining to. To train the agent yourself, please set doTraining to true.
doTraining = false;
if doTraining
% Train the agent.
trainingStats = train(agent,env,trainOpts);
else
% Load the pretrained agent for the example.
load('WaterTankDDPG.mat','agent')
end

Validate the trained agent
Validate the learned agent against the model through simulation.
simOpts = rlSimulationOptions('MaxSteps',maxsteps,'StopOnError','on');
experiences = sim(env,agent,simOpts);

Local function
function in = localResetFcn(in)
% randomize reference signal
blk = sprintf('rlwatertank/Desired \nWater Level');
h = 3*randn + 10;
while h <= 0 || h >= 20
h = 3*randn + 10;
end
in = setBlockParameter(in,blk,'Value',num2str(h));
% randomize initial height
h = 3*randn + 10;
while h <= 0 || h >= 20
h = 3*randn + 10;
end
blk = 'rlwatertank/Water-Tank System/H';
in = setBlockParameter(in,blk,'InitialCondition',num2str(h));
end