basis
Homogenize a sample point,
given (3, 2) (3, 2)(3,2 ) , the corresponding homogeneous coordinates are(1, 3, 2) (1,3,2)(1,3,2 ) , that is, add a 1 to the front. Generally:
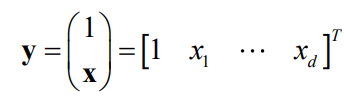
Normalize negative samples, assuming(1, 3, 2) (1,3,2)(1,3,2 ) is a negative class, then normalize it to(− 1, − 3, − 2) (-1,-3,-2)(−1,−3,− 2 ) .
Namely:

Then we discuss its linear separability:
if there isaaa makes:

then it is linearly separable, intuitive example:
Explanation: There are many a, and the red above is one. In addition, each a in the blue area is ok. In this way, we get the demarcation function: y = a T xy=a^TxY=aT x.
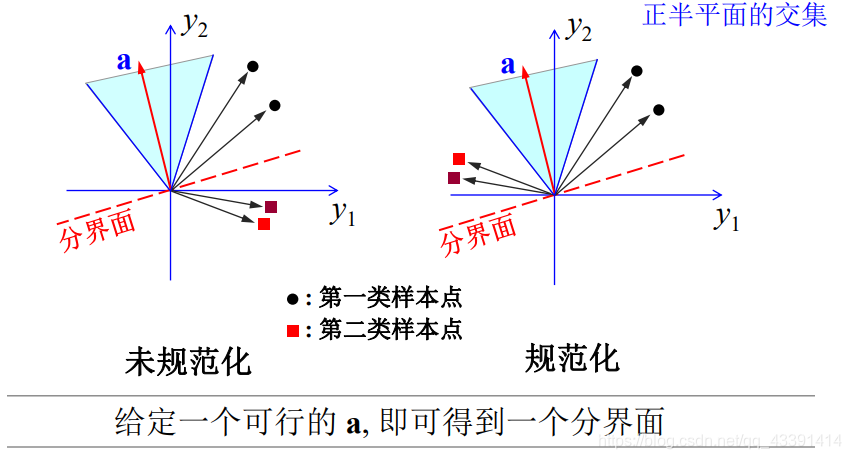
However, we need to limit the solution interval, because if linearly separable, there are an infinite number of a.

We can be as follows:
Perceptual criterion function


Among them:

In view of the specific time of the parameter update in the program, it is divided into single sample update and batch update.
Among them, each type of update can be divided into fixed increments and variable increments according to the size of the update step. That is, one is that the update step size is fixed, knowing that the model is trained, the other is that the update step size will be dynamically adjusted with the number of iterations or the size of the gradient, which is called a variable increment. Example:

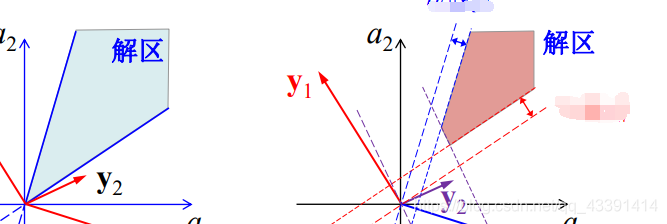
geometric interpretation of gradient update:
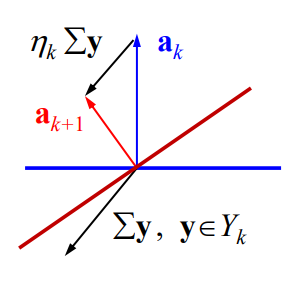
another interpretation:

that is: if the original yk y_kYkThe division is wrong, that is, ak T yk <0 a_k^Ty_k<0akTYk<0 , now the inner product after the change is added with a positive number, then it is more likelyak + 1 a_{k+1}ak+1Can be paired > 0> 0>0 .
Other related methods: the

first two have some shortcomings, the third is the best.

Explanation: Some people don't understand why the objective function of the linear criterion is piecewise linear, and why the gradients of the latter two are continuous. First you need to know
- Piecewise linearity is for a. That is, a is a variable, and each a will determine a batch of y, so that a loss function can be written, and it is linear. When a reaches a certain critical value (usually there are many), a turning point will occur, that is, segmentation Linear. Imagine y = ∣ x ∣ y=|x|Y=∣ x ∣ example. This function is continuous at 0, but not differentiable, and we just want the derivative. In case of bad luck a is there, it will be bad. But I don't think it is generally possible.
- Squaring the absolute value function is of course smoothed.
Advantages of the relaxation criterion:


Pseudocode:

Note: The batch update used here, and the batch here directly refers to the full sample. As for whether to use fixed increments, whatever.

Minimize square error method MSE
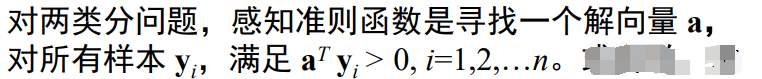

which is:

It turned out to be an inequality, but now it is changed to an equation. Obviously, there is no solution vector a, that is, Y is irreversible, so we define the error function and allow the equations to be unequal secretly.

Immediately there is:


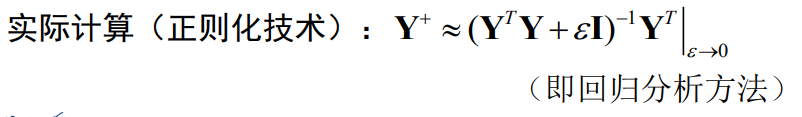


Obviously, it is a single-sample variable incremental update.

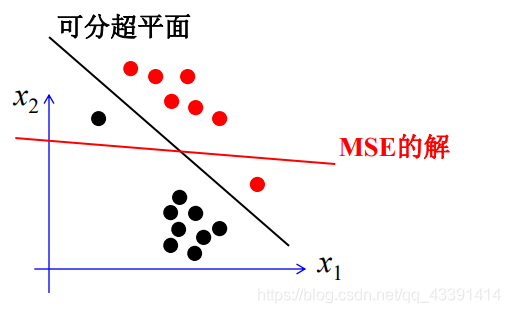
Everyone should be able to realize that the problem of MSE, allowing unequal, may lead to sample classification errors!


There may be situations:
Ho-Kashyap method

This method is not bad, obviously, our previous MSE is fixed b is a given value, such as 1, all are bi = 1 b_i=1bi=1 . This change has also become a parameter, but we don't know what it is, which is equivalent to participating in the training of the model and learning it.

Note that the negative of the vector here means that the median value of each component of the vector is changed to 0, otherwise it remains the same.

That is to initialize b as a positive number, and after other parameters are initialized, first use b to update a, then update b, and then the next round. Obviously, MSE generally only has one round, that is, it is done directly and fixed b using pseudo-inverse calculation to get a. So this algorithm has the meaning of promoting MSE.


MSE multi-class extension
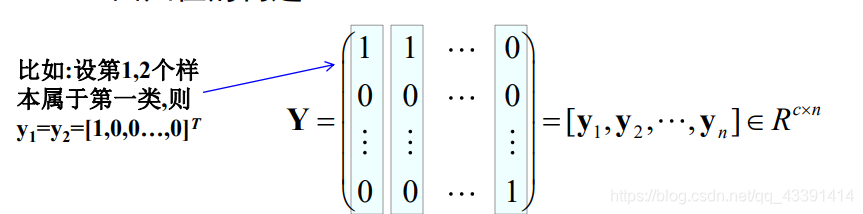
That is, it turned out to be a vector of all 1, b = 1 b=1b=1 , now becomes a matrix. And each category has a discriminant function.
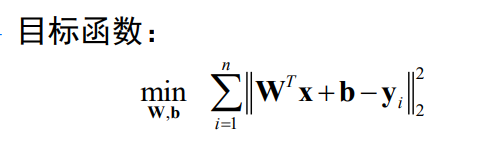
So there are:
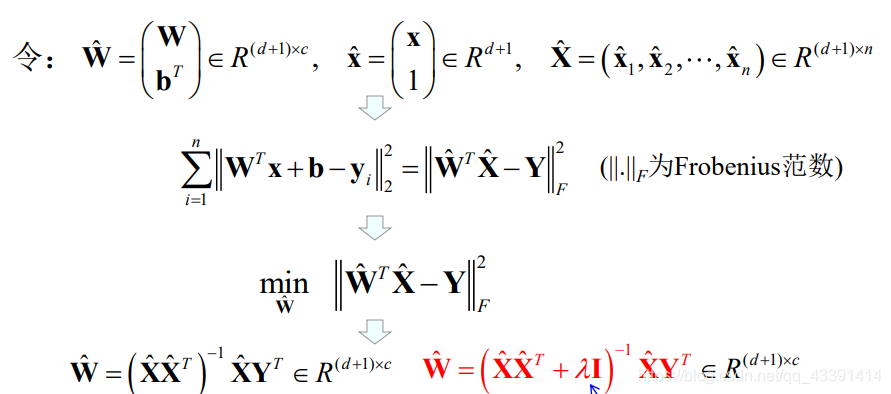
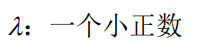
other multi-class methods:



that is, for one sample, only two weight vectors are changed. This is very heuristic, so you can design whatever you want.

The last multi-category method:

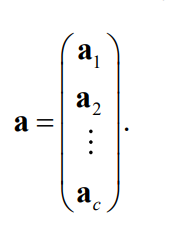
For one sample, copy so many samples out.
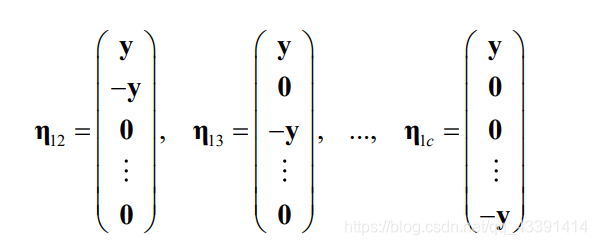
You should be able to find: the aboveyyThe y sample belongs to the first category.
Finally:
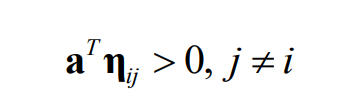
everyone can try, for the first type of sampleyyaboveIn terms of y , if the above formula is satisfied, then there is:
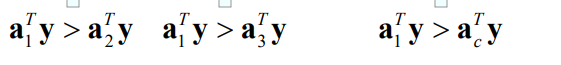
This is our idea, and other samples are similar. Slowly optimize, and finally all samples are paired.
