The characteristics of synchronized
Atomicity
The so-called atomicity refers to one operation or multiple operations, either all are executed and the execution process will not be interrupted by any factor, or it is not executed.
In Java, the reading and assignment operations of variables of basic data types are atomic operations, that is, these operations cannot be interrupted, either executed or not executed. However, operation characters such as i++ and i+=1 are not atomic. They are divided into steps of reading, calculation, and assignment . The original value may have been assigned before these steps are completed, so the final assignment is written The data is dirty data, and atomicity cannot be guaranteed.
All operations of the synchronized modified class or object are atomic, because the lock of the class or object must be acquired before the operation is performed, and the lock can not be released until the execution is completed. The intermediate process cannot be interrupted (except for the abandoned stop() Method), that is, atomicity is guaranteed.
note! In interviews, I often ask about comparing synchronized and volatile. The biggest difference between the two features is atomicity. Volatile does not have atomicity.
Visibility
Visibility means that when multiple threads access a resource, the status and value information of the resource are visible to other threads.
Both synchronized and volatile have visibility. When synchronized locks a class or object, a thread must first obtain its lock if it wants to access the class or object, and the state of this lock is visible to any other thread, and Before releasing the lock, the modification of the variable will be flushed to the main memory to ensure the visibility of the resource variable. If a thread occupies the lock, other threads must wait for the lock to be released in the lock pool.
The implementation of volatile is similar. Variables modified by volatile will update the main memory immediately whenever the value needs to be modified. The main memory is shared and visible to all threads, so it ensures that the variables read by other threads are always the latest value. Visibility.
Orderliness
The order in which the order value program is executed is executed sequentially according to the code.
Synchronized and volatile are both ordered. Java allows compilers and processors to rearrange instructions, but instruction rearrangement does not affect the order of a single thread. It affects the order of concurrent execution of multiple threads. Synchronization ensures that only one thread accesses the synchronization code block at each moment, which also determines that the threads execute the synchronization code block in a sequential order, ensuring orderliness.
Reentrancy
Both synchronized and ReentrantLock are reentrant locks. When a thread tries to operate a critical resource of an object lock held by another thread, it will be in a blocked state, but when a thread requests the critical resource of the object lock held by itself again, this situation is a reentrant lock. In layman's terms, it means that a thread that owns the lock can still apply for the lock repeatedly.
1. Three locking methods of synchronized
For ordinary synchronization methods, the lock is the current instance of the object (object lock)
In this way of use, it is important to note that the lock is an instance of the object, because it is necessary to ensure that multiple threads use the same instance, otherwise there will still be problems.
For example, the following code, because the instance of each thread is different, because they are not acquiring the same lock


If you want the execution result to be correct, you must ensure that the instances of multiple threads are the same, as shown below:

For static synchronization methods, the lock is the current Class object (class lock)

- For the synchronized method block, the lock is the object configured in Synchronized brackets
1. The object in brackets is the class object

The object in brackets is the current instance

java object header
In JVM, the layout of objects in memory is divided into three areas: object header , instance data, and alignment padding . as follows
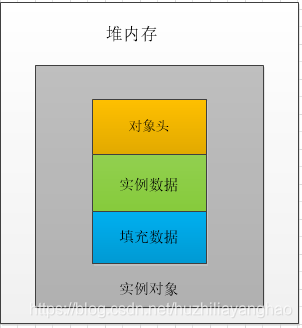
- Instance data : store the attribute data information of the class, including the attribute information of the parent class. If it is the instance part of the array, it also includes the length of the array. This part of the memory is aligned with 4 bytes.
- Filling data : Because the virtual machine requires that the start address of the object must be an integer multiple of 8 bytes. The padding data does not have to exist, it is just for byte alignment, this is enough to understand.
- Object header : The lock used for synchronized is stored in the Java object header. If the object is an array type, the virtual machine uses 3 words to store the object header, if the object is a non-array type, it uses 2 words to store the object header. In a 32-bit virtual machine, 1 word width is equal to 4 bytes, that is, 32bit
Mark Word
Mark Word records the information about the object and the lock. When the object is treated as a synchronized lock by the synchronized keyword, a series of operations around the lock are related to Mark Word.
The length of Mark Word in 32-bit JVM is 32bit, and the length in 64-bit JVM is 64bit.
Mark Word stores different contents under different lock states, which is stored in the 32-bit JVM:
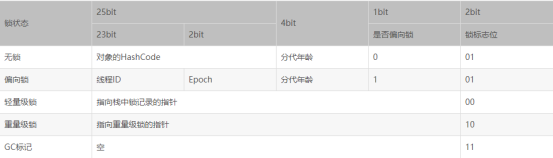
Among them, the lock flags of lock-free and biased locks are both 01, but the first 1 bit distinguishes whether this is a lock-free state or a biased lock state.
JDK1.6 and later versions have the concept of lock upgrade when dealing with synchronization locks. JVM's processing of synchronization locks starts from biased locks. As competition becomes more and more fierce, the processing method is upgraded from biased locks to lightweight locks. Finally upgraded to a heavyweight lock.
Lock expansion
As mentioned above, the lock has four states, and will be expanded and upgraded due to actual conditions. The expansion direction is: no lock -> bias lock -> lightweight lock -> heavyweight lock , and the expansion direction is irreversible.
Bias lock
Summarize its function in one sentence: to reduce the cost of acquiring locks by the unified thread . In most cases, there is no multi-thread competition for the lock, and it is always acquired by the same thread multiple times, then the lock is biased at this time.
main idea:
If a thread acquires a lock, the lock enters the biased mode. At this time , the structure of Mark Word becomes a biased lock structure. When the thread requests the lock again, no synchronization operation is required, that is, the process of acquiring the lock only requires Check that the lock flag of Mark Word is a biased lock and the current thread ID is equal to the ThreadID of Mark Word , which saves a lot of lock application operations.
Lightweight lock
In the unlocked state, the lock can be grabbed through CAS, and what is grabbed is a lightweight lock
Lightweight locks are upgraded from biased locks. When a second thread applies for the same lock object, the biased locks will be upgraded to lightweight locks immediately. Note that the second thread here only applies for locks. There are no two threads competing for locks at the same time. It can execute synchronization blocks alternately one after the other.
Heavyweight lock
Heavyweight locks are upgraded from lightweight locks. When multiple threads compete for locks at the same time , the locks will be upgraded to heavyweight locks. At this time, the cost of applying for locks will increase.
Heavyweight locks are generally used in scenarios where throughput is pursued, and synchronization blocks or synchronization methods take a long time to execute.
For example:
Thread 1 that is in the Runnable state but not yet running will grab the owner, and then turn on the bias lock after grabbing, and the thread will run.
2. If thread 2 grabs the lock at this time, the lock will be upgraded to a lightweight lock.
3. If thread 2 cannot grab the lock (thread 1 has not released the lock), then thread 2 will spin and continue to grab the lock. The spin has a certain limit. If the spin exceeds a certain number of times, the lock will be upgraded to a heavyweight lock again. Threads that cannot grab the lock will enter the lock pool to wait for execution
4. If thread 2 grabs the lock (thread 1 has released the lock before thread 2 starts), then the lock is still biased towards the lock state.
supplement:
Spin lock and adaptive spin lock
After the lightweight lock fails, the virtual machine will perform an optimization method called spin lock in order to prevent the thread from actually hanging at the operating system level.
Spin lock: In many cases, the lock state of shared data lasts for a short time, and it is not worth switching threads. By letting the threads execute loops and wait for the lock to be released, the CPU is not given up. If you get the lock, you will enter the critical section smoothly. If the lock cannot be obtained, the thread will be suspended at the operating system level. This is the optimization method of spin locks. But it also has disadvantages: if the lock is occupied by other threads for a long time and the CPU is not released, it will bring a lot of performance overhead.
Adaptive spin lock : This is equivalent to a further optimization of the above spin lock optimization method. Its number of spins is no longer fixed, and the number of spins is determined by the previous spin time and lock on the same lock. The state of the owner is determined, which solves the shortcomings caused by the spin lock.
I haven't talked about the underlying implementation of synchronized yet. I will talk in detail in the JVM later, and I will conclude here today.