Article Directory
foreword
Synchronized lock upgrade process
Students who have been in touch with thread safety must have used the keyword synchronized. In the java synchronization code block, there are two ways to use synchronized:
- Synchronization is achieved by locking an object;
synchronized(lockObject){
...
}
- Locking a method to achieve synchronization
public synchornized void test(){
...
}
Whether it is locking an object or locking a method, in fact, it is locking the object.
For method 2, the virtual machine actually fetches the corresponding instance object or Class object to lock according to whether the synchronized modification is an instance method or a class method.
- The lock is added to the object, so how does a thread know that the object is locked?
- And how do you know what type of lock it adds?
Based on these problems, let me explain step by step how synchronized is optimized, and how it changes from biased locks to heavyweight locks.
1. Lock object
The lock is actually added to the object, so the locked object is called a lock object. In java, any object can become a lock object.
In order to better understand how the virtual machine knows that this object is a lock object, let's briefly introduce the structure of an object in java.
The storage structure of java objects in memory mainly has three parts:
- Object header (Markword (4 bytes), Class object pointer (4 bytes))
- instance data
- Align padding data (aligned by 8 bytes)
It is emphasized here that the data in the object header is mainly some runtime data.
Its simple structure is as follows
| length | content | illustrate |
|---|---|---|
| 32/64bit | Mark Word | hashCode GC generational age, lock information |
| 32/64bit | Class pointer | pointer to object type data |
| 32/64bit | Array Length | the length of the array (when the object is an array) |
As can be seen from the table, the lock pair information in the object is locked in Markword.
LockObject lockObject = new LockObject();//随便创建一个对象
synchronized(lockObject){
...
When we create an object LockObject, some of the key Markword data of the object are as follows:
| bit fields | Whether to bias the lock | lock flag |
|---|---|---|
| hash | 0 | 01 |
The flag bit of the biased lock is "01", and the state is "0", indicating that the object has not been locked with a biased lock. ("1" means that a bias lock is added). The moment the object is created, there is a bias lock flag, which also shows that all objects are biasable, but the status of all objects is "0", which also shows that the bias lock of all created objects is not in effect.
2. Bias lock
When the thread executes to the critical section, it will use the CAS (Compare and Swap) operation to insert the thread ID into the Markword and modify the flag bit of the biased lock at the same time.
Critical section: It is an area where only one thread is allowed to enter to perform operations, that is, a synchronous code block. As long as it affects multi-thread concurrency, it is called a critical section. CAS is an atomic operation
At this time, the structural information of Mark word is as follows:
| bit fields | Whether to bias the lock | lock flag | |
|---|---|---|---|
| threadId | epoch | 1 | 01 |
The status of the biased lock is "1", indicating that the biased lock of the object is in effect, and you can also see which thread has acquired the lock of the object
Biased lock: a lock optimization introduced by jdk1.6, where "bias" is an eccentric bias. It means that this lock will be biased towards the first thread that acquires it. In the next execution process, if the lock is not acquired by other threads and no other threads compete for the lock, then the thread holding the biased lock will never need to perform synchronization operations.
That is to say:
in the execution process after this thread, if you enter or exit the same synchronization block code again, you no longer need to perform locking or unlocking operations, but will do the following steps:
- Load-and-test is to simply judge whether the current thread id is consistent with the thread id in Markword.
- If they are consistent, it means that this thread has successfully acquired the lock, and continue to execute the following code.
- If not, check whether the object is still biasable, that is, the value of the "lock biased" flag.
- If it has not been biased, use the CAS operation to compete for the lock, which is the operation when the lock is acquired for the first time.
- If this object is already biased, and not biased to itself, then there is a race. At this time, depending on the situation of other threads, it may be re-biased or unbiased, but in most cases it is upgraded to a lightweight lock.
The biased lock is for a thread. After the thread acquires the lock, there will be no unlocking and other operations, which can save a lot of overhead. If there are two threads competing for the lock, then the biased lock will become invalid, and then it will be upgraded to a lightweight lock.
Why do you want to do this? Because experience shows that in most cases, the same thread will enter the same synchronization code block. This is also the reason why there are biased locks.
In Jdk1.6, the switch of the biased lock is enabled by default, which is suitable for scenarios where only one thread accesses the synchronization block.
3. Lock Expansion
When there are two threads competing for the lock, the biased lock will become invalid, and the lock will expand and be upgraded to a lightweight lock. This is also what we often call lock expansion
4. Lock Cancellation
Since the biased lock is invalid, the lock must be revoked next, and the overhead of lock revoking is still quite high. The approximate process is as follows:
- Stops the thread that owns the lock at a safe point.
Traversing the thread stack, if there is a lock record, you need to repair the record and Markword to make it lock-free. - Wake up the current thread and upgrade the current lock to a lightweight lock.
- So if some synchronization code blocks have two or more threads competing in most cases, then the biased lock will be a burden. For this case, we turn off the biased lock by default from the beginning.
5. Lightweight lock
After the lock revocation is upgraded to a lightweight lock, the Markword of the object will also change accordingly. The following briefly describes the process of upgrading to a lightweight lock after the lock is revoked:
- A thread creates a lock record LockRecord in its own stack frame.
- Copy the MarkWord in the object header of the lock object to the newly created lock record of the thread'
- Point the Owner pointer in the lock record to the lock object.
- Replace the Markword of the object header of the lock object with a pointer to the lock record.
The corresponding diagram is described as follows:
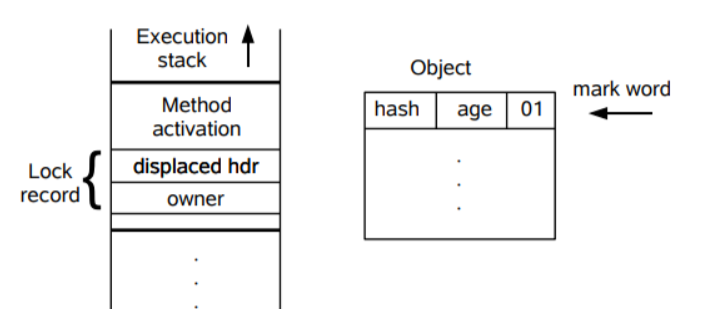
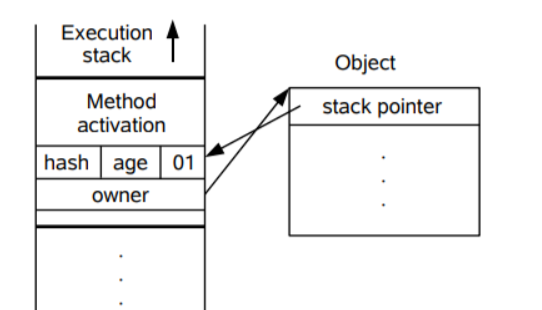
At the moment Markword:
| bit ields | lock flag |
|---|---|
| Pointer to LockRecord | 00 |
The lock flag "00" indicates lightweight locks.
There are two main types of lightweight locks:
spin locks
and adaptive locks.
Six, spin lock
The so-called spin means that when another thread competes for the lock, the thread will wait in a loop instead of blocking the thread until the thread that acquires the lock releases the lock, and the thread can immediately acquire the lock.
Note that when the lock loops in place, it will consume cpu, which is equivalent to executing a for loop with nothing.
Therefore, lightweight locks are suitable for scenarios where synchronized code blocks are executed quickly, so that threads can acquire locks by waiting in place for a very short time.
Experience shows that the execution time of most synchronized code blocks is very short, and it is for this reason that there is such a thing as a lightweight lock.
Some problems with spin locks
- If the synchronization code block executes very slowly and takes a lot of time, then other threads are waiting in place to consume CPU at this time.
- Originally, after a thread releases the lock, the current thread can acquire the lock; but if there are several threads competing for the lock at this time, then the current thread may not be able to acquire the lock, continue to wait and consume CPU, and may even fail to acquire the lock.
Based on this problem, we must set a number of empty loops for the thread. When the thread exceeds this number, we think that it is not appropriate to continue using the spin lock. At this time, the lock will expand again and be upgraded to a heavyweight lock.
By default, the number of spins is 10, users can change it by -XX:PreBlockSpin.
7. Adaptive spin lock
The so-called adaptive spin lock means that the number of spins that the thread waits for in an empty loop is not fixed, but will dynamically change the number of spins and waits according to the actual situation.
If thread 1 has just successfully acquired a lock, when it releases the lock, thread 2 acquires the lock, and thread 2 is running. At this time, thread 1 wants to acquire the lock again, but thread 2 has not released the lock, so thread 1 can only spin and wait.
In addition, if for a certain lock, after a thread spins, it rarely successfully acquires the lock, then when the thread wants to acquire the lock in the future, it is possible to ignore the spin process and directly upgrade to a heavyweight lock, so as to avoid wasting resources by waiting in an empty loop.
Lightweight locks are also called non-blocking synchronization and optimistic locks, because this process does not block and suspend threads, but allows threads to wait in an empty loop and execute serially.
Eight, heavyweight lock
After the lightweight lock expands, it is upgraded to a heavyweight lock. Heavyweight locks are implemented by relying on the monitor lock inside the object, and monitors are implemented by relying on the MutexLock (mutual exclusion lock) of the operating system, so heavyweight locks are also called mutex locks.
After the lightweight lock has been upgraded to a heavyweight lock through steps such as lock revocation, its Markword part data is roughly as follows:
| bit fields | lock flag |
|---|---|
| Pointer to Mutex | 10 |
9. Why are heavyweight locks expensive?
Mainly, when the system checks that the lock is a heavyweight lock, it will block the thread waiting to acquire the lock, and the blocked thread will not consume cup. But when blocking or waking up a thread, the operating system is required to help, which requires switching from user mode to kernel mode, and switching state takes a lot of time, which may be longer than the time for the user to execute code.
This is why heavyweight threads are expensive
Mutex locks (heavyweight locks) are also known as blocking synchronization and pessimistic locks
Summarize
Through the above analysis, we know why the synchronized keyword is so popular, and we also know the evolution process of locks.
In other words, the synchronized keyword does not add a heavyweight lock to the object from the beginning, but also a process from biased locks, lightweight locks, and heavyweight locks .
This process also tells us that if we know from the beginning that the competition of a certain synchronization code block is fierce and slow, then we should use heavyweight locks from the beginning, thus saving some lock conversion overhead.