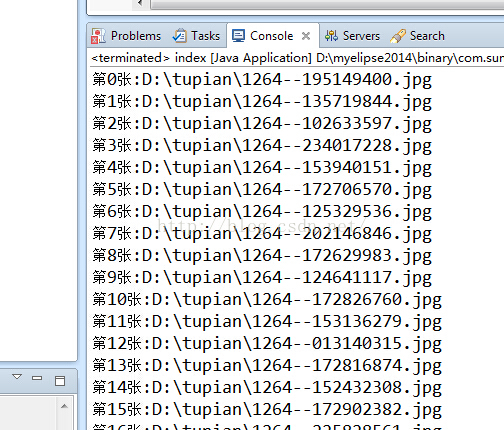
This article mainly introduces how to use pure java to write a picture crawler, beauty picture crawler code sharing, this article takes the collection and crawling of beauty pictures as an example, friends in need can refer to the next to continue to tinker with the crawler, you know!
Cough! I'm a bit excited about what I said, let me be quiet.
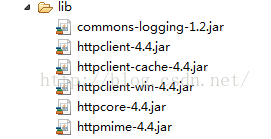
1. The shelf bags that need to be used are as follows
2. Program entry (take a good name and call it index)
import java.io.InputStream;
import org.apache.http.client.config.CookieSpecs;
import org.apache.http.client.config.RequestConfig;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpPost;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
public class index {
private static final int page = 1264;
public static void main(String[] args) {
//HttpClient 超时配置
RequestConfig Config = RequestConfig.custom().setCookieSpec(CookieSpecs.STANDARD).setConnectionRequestTimeout(6000).setConnectTimeout(6000).build();
CloseableHttpClient httpClient = HttpClients.custom().setDefaultRequestConfig(Config).build();
System.out.println("开始lol....");
for (int i = page; i > 0; i--) {
HttpPost httpPost = new HttpPost("http://www.jf258.com/nansheng/"+ i+"1.html"); //需要爬的网站
httpPost.addHeader("User-Agent", "Mozilla/4.0 (compatible; MSIE 5.0; Windows NT; DigExt)");//伪装一个浏览器
try {
CloseableHttpResponse response = httpClient.execute(httpPost);//开始
InputStream ism = response.getEntity().getContent();
String context = Utils.convertStreamToString(ism);
new Thread(new CheDHtmlParser(context, i)).start();
} catch (Exception e) {
e.printStackTrace();
}
}
}
}</strong></span>import java.util.List;
public class CheDHtmlParser implements Runnable {
private String html;
private int page;
public CheDHtmlParser(String html,int page) {
this.html = html;
this.page = page;
}
@Override
public void run() {
List<String> list = new ArrayList<String>();
html = html.substring(html.indexOf("list"));
String[] ss = html.split("li>");
for (String s : ss) {
if (s.indexOf("<img src=") > 0) {
try{
int i = s.indexOf("<img src=\"") + "<img src=\"".length();
list.add(s.substring(i, s.indexOf("\"", i + 1)));
}catch (Exception e) {
System.out.println(s);
}
}
}
for(String imageUrl : list){
new Thread(new CheDImageCreator(imageUrl,page)).start();
}
}
}
</strong></span>import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
public class Utils {
public static String convertStreamToString(InputStream in) {
BufferedReader reader = new BufferedReader(new InputStreamReader(in));
StringBuilder sb = new StringBuilder();
String line = null;
try {
while ((line = reader.readLine()) != null) {
sb.append(line + "/n");
}
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
in.close();
} catch (IOException e) {
e.printStackTrace();
}
}
return sb.toString();
}
}
</strong></span>import java.io.File;
import java.io.FileOutputStream;
import java.io.InputStream;
import java.io.OutputStream;
import java.net.URL;
import java.net.URLConnection;
public class CheDImageCreator implements Runnable {
private static int count = 0;
private String imageUrl;
private int page;
//存储路径
private static final String basePath = "D:/tupian";
public CheDImageCreator(String imageUrl,int page) {
this.imageUrl = imageUrl;
this.page = page;
}
@Override
public void run() {
File dir = new File(basePath);
if(!dir.exists()){
dir.mkdirs();
}
String imageName = imageUrl.substring(imageUrl.lastIndexOf("/")+1);//获取图片名字
try {
File file = new File( basePath+"/"+page+"--"+imageName);//拼接
OutputStream os = new FileOutputStream(file);
//创建一个url对象
String u="http://www.jf258.com"+imageUrl;
URL uri = new URL(u);
URLConnection connection = uri.openConnection();
connection.setRequestProperty("User-Agent", "Mozilla/4.0 (compatible; MSIE 5.0; Windows NT; DigExt)");//伪装成一个浏览器
InputStream is = connection.getInputStream(); //开始一个流
byte[] buff = new byte[1024];
while(true) {
int readed = is.read(buff);
if(readed == -1) {
break;
}
byte[] temp = new byte[readed];
System.arraycopy(buff, 0, temp, 0, readed);
//写入文件
os.write(temp);
}
System.out.println("第"+(count++)+"张:"+file.getAbsolutePath());
is.close();
os.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
</strong></span>