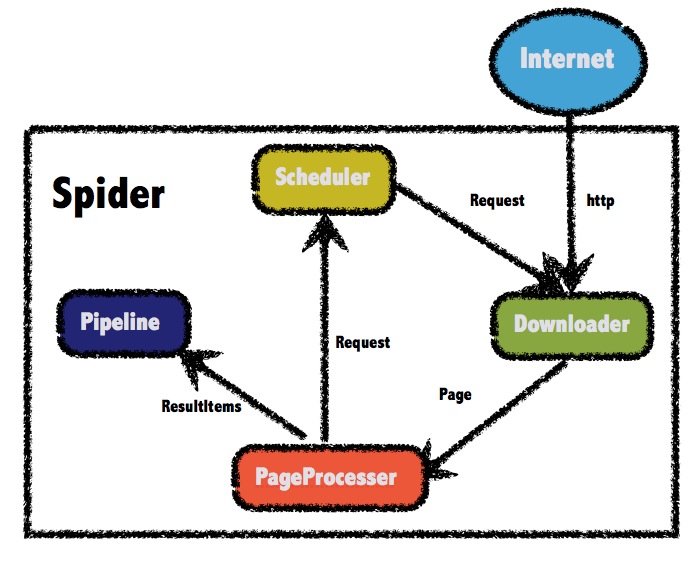
1. The overall architecture of WebMagic
Five, how to use WwbMagic
1.5.1 Four Components of WebMagic
1.Downloader
The Downloader is responsible for downloading pages from the Internet for subsequent processing. WebMagic uses Apache HttpClient as the download tool by default.
2.PageProcessor
PageProcessor is responsible for parsing pages, extracting useful information, and discovering new links. WebMagic uses Jsoup as an HTML parsing tool, and based on it developed a tool Xsoup for parsing XPath .
Among these four components, PageProcessoreach page is different for each site and needs to be customized by users.
3.Scheduler
The Scheduler is responsible for managing the URLs to be crawled, as well as some deduplication work. WebMagic provides JDK's memory queue by default to manage URLs, and uses collections for deduplication. Distributed management using Redis is also supported.
Unless the project has some special distributed requirements, you do not need to customize the Scheduler yourself.
4.Pipeline
Pipeline is responsible for the processing of extraction results, including calculation, persistence to files, databases, etc. By default, WebMagic provides two result processing solutions: "output to console" and "save to file".
PipelineDefines the way to save the result. If you want to save to the specified database, you need to write the corresponding Pipeline. For a class of requirements generally only need to write one Pipeline.
1.5.2 Simple example of crawler project
rely:

<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-core</artifactId>
<version>0.6.1</version>
</dependency>
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-extension</artifactId>
<version>0.6.1</version>
</dependency>
Simple code:
import us.codecraft.webmagic.Page; import us.codecraft.webmagic.Site; import us.codecraft.webmagic.Spider; import us.codecraft.webmagic.processor.PageProcessor; public class GithubRepoPageProcessor implements PageProcessor { private Site site = Site.me().setRetryTimes(3).setSleepTime(100); @Override public void process(Page page) { page.addTargetRequests(page.getHtml().links().regex("(https://github\\.com/\\w+/\\w+)").all()); page.putField("author", page.getUrl().regex("https://github\\.com/(\\w+)/.*").toString()); page.putField("name", page.getHtml().xpath("//h1[@class='entry-title public']/strong/a/text()").toString()); if (page.getResultItems().get("name")==null){ //skip this page page.setSkip(true); } page.putField("readme", page.getHtml().xpath("//div[@id='readme']/tidyText()")); } @Override public Site getSite() { return site; } public static void main(String[] args) { Spider.create(new GithubRepoPageProcessor()).addUrl("https://github.com/code4craft").thread(5).run(); }
如果仔细分析这段代码的逻辑,将其弄明白了,那么对于一个简单的爬虫项目,你就可以自己写了。
addUrl是定义从哪一个页面开始爬取;
addTargetRequests(page.getHtml().links().regex("(https://github\\.com/\\w+/\\w+)").all());是指定抓取html页面的符合此正则表达式的所有链接url;
page.getHtml().xpath("//h1[@class='entry-title public']/strong/a/text()").toString是指定抓取h1标签下的class属性值为entry-title public的子标
签strong下的a标签下的文本内容;
tidyText()所有的直接和间接文本子节点,并将一些标签替换为换行,使纯文本显示更整洁。当然这也就要求大家也要对正则表达式熟悉了。本文用的是xsoup,Xsoup是
基于Jsoup开发的一款XPath 解析器,之前WebMagic使用的解析器是HtmlCleaner,使用过程存在一些问题。主要问题是XPath出错定位不准确,并且其不太合理的代码结构
,也难以 通过注解将值赋给model属性的实体类:
@TargetUrl("https://github.com/\\w+/\\w+")
@HelpUrl("https://github.com/\\w+")
public class GithubRepo {
@ExtractBy(value = "//h1[@class='entry-title public']/strong/a/text()", notNull = true)
private String name;
@ExtractByUrl("https://github\\.com/(\\w+)/.*")
private String author;
@ExtractBy("//div[@id='readme']/tidyText()")
private String readme;
}
提示:
HelpUrl/TargetUrl是一个非常有效的爬虫开发模式,TargetUrl是我们最终要抓取的URL,最终想要的数据都来自这里;而HelpUrl则是为了发现这个最终URL,我们需要访问的页面。几乎所有垂直爬虫的需求,都可以归结为对这两类URL的处理:- 对于博客页,HelpUrl是列表页,TargetUrl是文章页。
- 对于论坛,HelpUrl是帖子列表,TargetUrl是帖子详情。
- 对于电商网站,HelpUrl是分类列表,TargetUrl是商品详情。
模拟浏览器请求:
public VideoSpider(String url, String proxyStr) { this.client_url = url; String[] tmp = proxyStr.split(":"); HttpHost proxy = new HttpHost(tmp[1].substring(2), Integer.parseInt(tmp[2]), tmp[0]); Site site = Site.me().setRetryTimes(3).setHttpProxy(proxy).setSleepTime(100).setTimeOut(10 * 1000).setCharset("UTF-8") .setUserAgent("Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/31.0.1650.63 Safari/537.36"); GPHttpClientDownloader downloader = new GPHttpClientDownloader(); Request request = new Request(this.client_url); this.setCookie(request, site, downloader); this.setParameters(request, site, downloader); }
中setUserAgent("Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/31.0.1650.57 Safari/537.36"),jobInfoDaoPipeline, LieTouJobInfo.class)
是模拟火狐、苹果、谷歌等浏览器进行请求将通过实体类LieTouJobInfo来抓取指定的内容并通过数据库访问层jobInfoDaoPipeline将相关属性存入数据库。
6. Thinking
简单的爬虫用以上代码基本就可以实现,但是我们要知道,要想真正爬取自己想要的内容,还有一段很长的落要走。因为我们在抓取数据的时候要考虑到去重、动态页面的产生、快速的更新频率、巨大的数据量等等的问题。针对这些问题我们该怎么做才能有效简单的去解决,这是
一个特别值得探讨的问题。就先写到这吧,如果我研究的有进展了,足以在公司项目中稳定投入使用了,再来完善吧。download:
Latest version: WebMagic-0.6.1
Maven dependencies:
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-core</artifactId> <version>0.6.1</version> </dependency> <dependency> <groupId>us.codecraft</groupId> <artifactId>webmagic-extension</artifactId> <version>0.6.1</version> </dependency> Documentation:
- Chinese: http://webmagic.io/docs/zh/
- English: http://webmagic.io/docs/en
Source code: