Preface
Crawlers are an automated method of scraping large amounts of data from websites. Even copying and pasting quotes or lines from your favorite website is a form of web scraping. Most websites do not allow you to save the data on their website for your use. Therefore, the only option is to copy the data manually, which will consume a lot of time and may even take several days to complete.
The data on the website is mostly unstructured. Web scraping helps to store these unstructured data in a customized and structured form locally or in a database. If you are crawling web pages for learning purposes, you are unlikely to encounter any problems. It is a good practice to do some web crawling yourself to enhance your skills without violating the terms of service. .
Crawler steps
Why use Python for web scraping?
Python is incredibly fast and makes web crawling easier. Because it is too easy to code, you can use simple small codes to perform large tasks.
How to do web scraping?
We need to run the web crawling code in order to send the request to the URL of the website we want to crawl. The server sends data and allows us to read HTML or XML pages in response. The code parses HTML or XML pages, finds data and extracts them.
Here are the steps to extract data using Python using web scraping
- Find the URL you want to crawl
- Analyze the website
- Find the data to be extracted
- Write code
- Run the code and extract data from the website
- Store the data in the required format in the computer
Libraries for web scraping
- Requests
- Beautiful Soup
- Pandas
- Tqdm
Requests is a module that allows HTTP requests to be sent using Python. HTTP request is used to return a response object containing all response data (such as encoding, status, content, etc.)
BeautifulSoup is a Python library for extracting data from HTML and XML files. This works with your favorite parser in order to provide idiomatic methods for navigating, searching, and modifying the parse tree. It is specially designed for fast and highly reliable data extraction.
pandas is an open source library that allows us to perform data manipulation in Python web development. It is built on the Numpy package, and its key data structure is called DataFrame. DataFrames allow us to store and manipulate tabular data in observation data rows and variable columns.
Tqdm is another python library that can quickly make your loop display a smart progress meter-all you have to do is wrap any iterable with Tqdm (iterable).
Demo: crawl a website
Step 1. Find the URL you want to crawl
To demonstrate, we will grab the web page to extract the detailed information of the phone. I used an example (www.example.com) to demonstrate this process.
Many people learn python and don't know where to start.
Many people learn python and after mastering the basic grammar, they don't know where to find cases to get started.
Many people who have done case studies do not know how to learn more advanced knowledge.
So for these three types of people, I will provide you with a good learning platform, free to receive video tutorials, e-books, and the source code of the course!
QQ group: 721195303
Stpe 2. Analyze the website
Data is usually nested in tags. Analyze and check that the data we want to get is marked on the page under which it is nested. To view the page, simply right-click the element and click "inspect". A small inspection element box will be opened. You can see the original code behind the site. Now you can find the detail tag you want to scrape.
You can find an arrow symbol in the upper left corner of the console. If you click the arrow and then click the product area, the code for the specific product area will be highlighted in the console tab.
The first thing we should do is to review and understand the structure of HTML, because getting data from a website is very important. There will be a lot of code on the website page, and we need the code that contains our data. Learning the basics of HTML will help you become familiar with HTML tags.
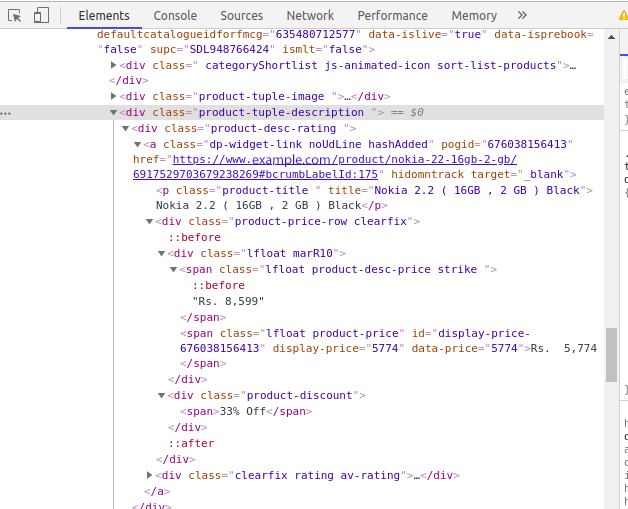
Step 3. Find the data to be extracted
We will extract mobile phone data, such as product name, actual price, discount price, etc. You can extract any type of data. To do this, we must find the tags that contain our data.
Open the console by inspecting the area of the element. Click the arrow in the upper left corner, and then click the product. You will now be able to see the specific code of the product we clicked on.
Step 4. Write the code
Now we must find out where the data and links are. Let's start coding.
Create a file called scrap.py and open it in any editor of your choice. We will install the four Python libraries mentioned above using pip.
The first and main process is to access site data. We have set the URL of the website and visited the website.
url = 'https://www.example.com/products/mobiles-mobile-phones?sort=plrty'headers = { 'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64)' 'AppleWebKit/537.36 (KHTML, like Gecko)' 'Chrome/64.0.3282.167 Safari/537.36' }result = requests.get(url, headers=headers,verify=True)Print(result)Output: <Response [200]>
If you see the result above, then you have successfully visited this website.
Step 5. Run the code and extract data from the website
Now, we will use Beautifulsoup to parse HTML.
soup = BeautifulSoup(result.content, 'html.parser')If we print soup, then we will be able to see the HTML content of the entire website page. What we have to do now is to filter the part that contains the data. Therefore, we will extract the section tag from the soup.
section=soup.find("section", class_='js-section').find_all("div",{'class':'product-desc-rating})Print(section)
The results are as follows:
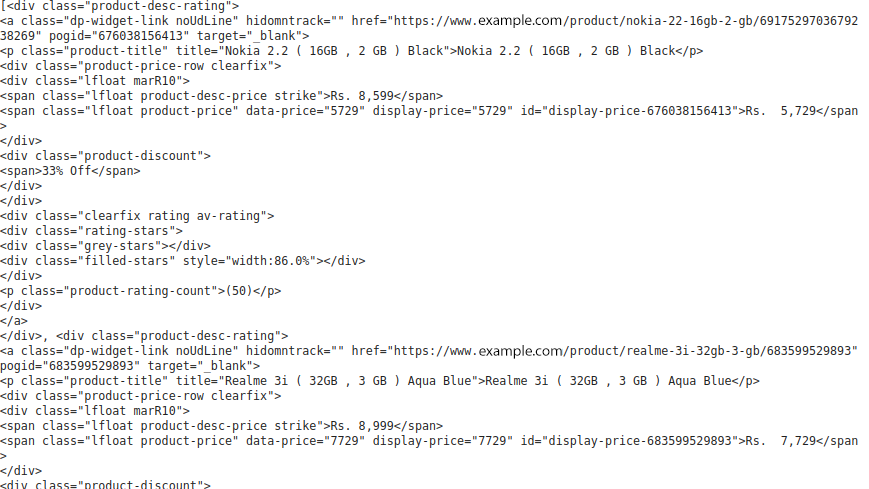
Now, we can extract the detailed information of the mobile phone in the "product-desc-rating" class of the div. I have created a list for each column detail of the mobile phone and appended it to that list using a for loop.
Products = []url = []Actual_Price = []Discounted_Price = []Discount = []
The product name appears under the p tag (paragraph tag) in the HTML, and product_url appears under the anchor tag.
The HTML anchor tag defines a hyperlink that links one page to another page. It can create a hyperlink to another web page and file, location or any URL. The "href" attribute is the most important attribute of HTML tags. And a link to the target page or URL.
Then we will extract the actual price and the discounted price, both of which appear in the span tag. Tags are used to group inline elements. And the label itself does not provide any visual changes. Finally, we will extract the quote percentage from the div tag. The div tag is a block-level tag. It is a universal container label. It is used for various markup groups of HTML so that you can create sections and apply styles to them.
for t in tqdm(section): product_name = t.p.text Products.append(product_name) product_url = t.a['href'] url.append(product_url) original_price = t.span.getText() Actual_Price.append(original_price) discounted_price = t.find('span', class_ = 'lfloat product-price').getText() Discounted_Price.append(discounted_price) try: product_discount = t.find('div', class_ = 'product-discount') Discount.append(product_discount.text) except Exception as e: product_discount = None Discount.append(product_discount)
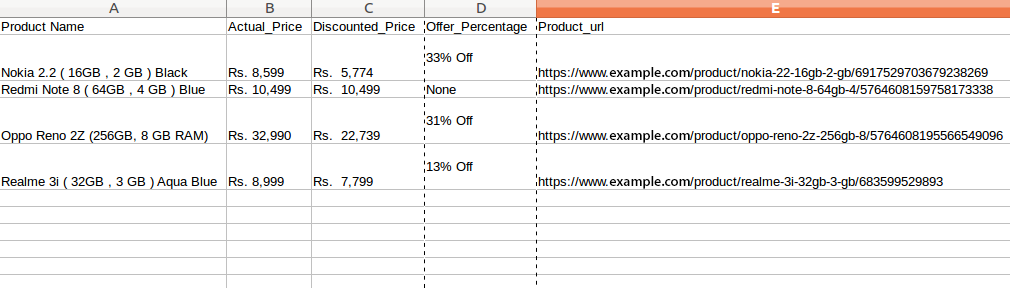
Step 6. Store the data in the required format
We have extracted the data. All we have to do now is to store the data in a file or database. You can store the data in the required format. It depends on your requirements. Here, we will store the extracted data in CSV (Comma Separated Value) format.
= pd.DataFrame({'Product Name':Products,'Actual_Price':Actual_Price,'Discounted_Price':Discounted_Price,'Offer_Percentage':Discount,'Product_url':url}) df.to_csv(' products.csv', index=False, encoding='utf-8')