Source code of this article: GitHub·click here || GitEE·click here
1. Basic overview of HDFS
1. HDFS description
The two core modules that the big data field has always faced: data storage and data computing. As the most important big data storage technology, HDFS has a high degree of fault tolerance, stability and reliability. HDFS (Hadoop-Distributed-File-System), it is a distributed file system used to store files and locate files through the directory tree; the original intention of the design is to manage hundreds of servers and disks, so that applications can use The ordinary file system stores large-scale file data like a common file system, which is suitable for scenarios where one write and multiple reads, and does not support file modification, so it is suitable for data analysis.
2. Infrastructure
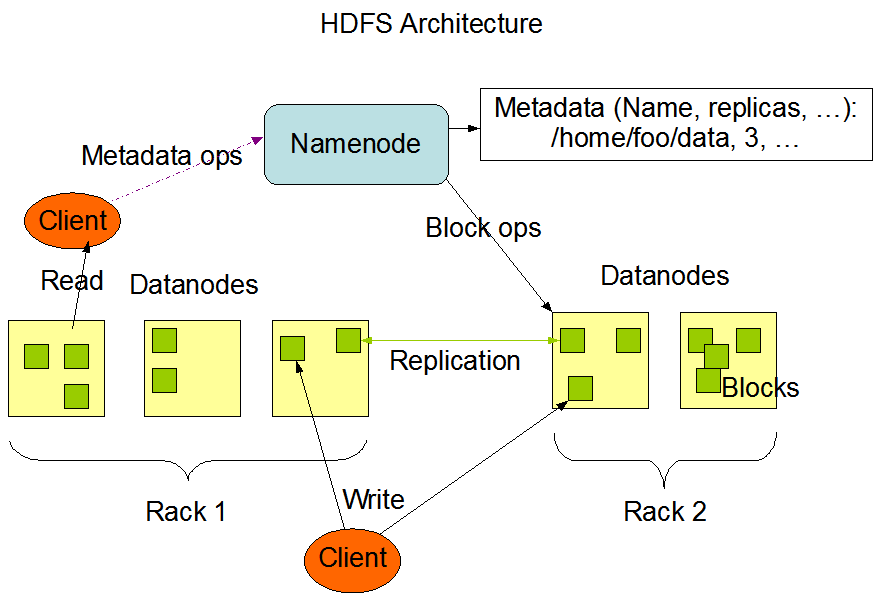
HDFS has a master/slave architecture with two core components, NameNode and DataNode.
NameNode
Responsible for the metadata (MetaData) management of the file system, that is, the file path name, data block ID, storage location and other information, and configure the copy strategy to handle client read and write requests.
DataNode
Perform actual storage and read-write operations of file data. Each DataNode stores a portion of file data blocks, and the entire file is distributed and stored in the entire HDFS server cluster.
Client
On the client, when the file is split and uploaded to HDFS, the client divides the file into blocks and uploads it; obtains the location information of the file from the NameNode; communicates with the DataNode to read or write data; the Client uses some commands to access or Manage HDFS.
Secondary-NameNode
It is not a hot standby of the NameNode, but shares the workload of the NameNode, such as regularly merging Fsimage and Edits and pushing them to the NameNode; in an emergency, it can assist in the recovery of the NameNode.
3. High fault tolerance
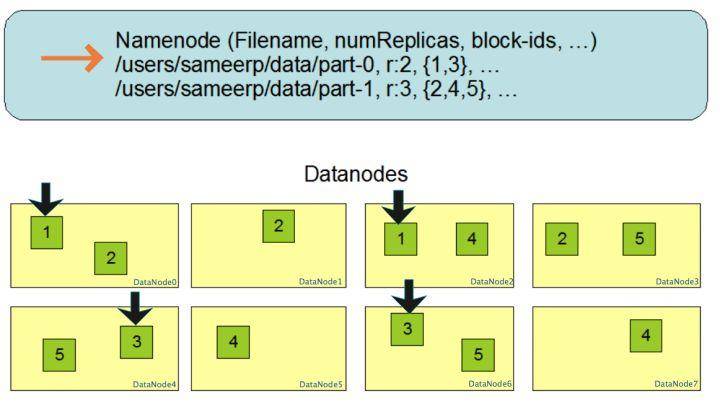
An illustration of multiple copy storage of data blocks, file /users/sameerp/data/part-0, copy backup is set to 2, stored block-ids are 1, 3; file /users/sameerp/data/part-1, The replication backup is set to 3, and the stored block-ids are 2, 4, and 5 respectively; after any single server goes down, at least one backup service exists for each data block, which will not affect file access and improve overall fault tolerance Sex.
Files in HDFS are physically stored in blocks (Block). The block size can be configured by the parameter dfs.blocksize. If the block setting is too small, it will increase the addressing time; if the block setting is too large, it will take time to transfer data from the disk. It will be very slow, and the HDFS block size setting mainly depends on the disk transfer rate.
Two, basic Shell commands
1. Basic commands
View relevant Shell operation commands under Hadoop.
[root@hop01 hadoop2.7]# bin/hadoop fs
[root@hop01 hadoop2.7]# bin/hdfs dfs
dfs is the implementation class of fs
2. View the command description
[root@hop01 hadoop2.7]# hadoop fs -help ls
3. Recursively create directories
[root@hop01 hadoop2.7]# hadoop fs -mkdir -p /hopdir/myfile
4. View the catalog
[root@hop01 hadoop2.7]# hadoop fs -ls /
[root@hop01 hadoop2.7]# hadoop fs -ls /hopdir
5. Cut and paste files
hadoop fs -moveFromLocal /opt/hopfile/java.txt /hopdir/myfile
## 查看文件
hadoop fs -ls /hopdir/myfile
6. View file content
## 查看全部
hadoop fs -cat /hopdir/myfile/java.txt
## 查看末尾
hadoop fs -tail /hopdir/myfile/java.txt
7. Append file content
hadoop fs -appendToFile /opt/hopfile/c++.txt /hopdir/myfile/java.txt
8. Copy files
The copyFromLocal command is the same as the put command
hadoop fs -copyFromLocal /opt/hopfile/c++.txt /hopdir
9. Copy HDFS files to local
hadoop fs -copyToLocal /hopdir/myfile/java.txt /opt/hopfile/
10. Copy files in HDFS
hadoop fs -cp /hopdir/myfile/java.txt /hopdir
11. Move files in HDFS
hadoop fs -mv /hopdir/c++.txt /hopdir/myfile
12. Merge and download multiple files
The basic commands get and copyToLocal commands have the same effect.
hadoop fs -getmerge /hopdir/myfile/* /opt/merge.txt
13, delete files
hadoop fs -rm /hopdir/myfile/java.txt
14. View folder information
hadoop fs -du -s -h /hopdir/myfile
15, delete the folder
bin/hdfs dfs -rm -r /hopdir/file0703
3. Source code address
GitHub·地址
https://github.com/cicadasmile/big-data-parent
GitEE·地址
https://gitee.com/cicadasmile/big-data-parent
Recommended reading: finishing programming system
| Serial number | project name | GitHub address | GitEE address | Recommended |
|---|---|---|---|---|
| 01 | Java describes design patterns, algorithms, and data structures | GitHub·click here | GitEE·Click here | ☆☆☆☆☆ |
| 02 | Java foundation, concurrency, object-oriented, web development | GitHub·click here | GitEE·Click here | ☆☆☆☆ |
| 03 | Detailed explanation of SpringCloud microservice basic component case | GitHub·click here | GitEE·Click here | ☆☆☆ |
| 04 | SpringCloud microservice architecture actual combat comprehensive case | GitHub·click here | GitEE·Click here | ☆☆☆☆☆ |
| 05 | Getting started with SpringBoot framework basic application to advanced | GitHub·click here | GitEE·Click here | ☆☆☆☆ |
| 06 | SpringBoot framework integrates and develops common middleware | GitHub·click here | GitEE·Click here | ☆☆☆☆☆ |
| 07 | Basic case of data management, distribution, architecture design | GitHub·click here | GitEE·Click here | ☆☆☆☆☆ |
| 08 | Big data series, storage, components, computing and other frameworks | GitHub·click here | GitEE·Click here | ☆☆☆☆☆ |