1. CCLM technology principle
CCLM, the cross-component linear model (CCLM) prediction mode, the core idea of this technology is to reduce cross-component redundancy and perform cross-component prediction, mainly using the reconstructed luminance pixels of the same coding block to construct the predicted values of chrominance pixels.
![]()
Among them, it represents the chrominance prediction pixel of the
current CU , represents the down-sampling reconstructed luminance pixel of the current CU,
and is
called a linear model parameter, which is generated and derived from the adjacent 4 chrominance pixels and the corresponding down-sampled luminance pixel. Suppose the current chroma block size is W×H, then W'and H'are set to
- W'= W, H'= H when the current mode is LM mode;
- W'= W + H when the current mode is LM-A mode;
- H'= H + W when the current mode is LM-L mode;
The position of the upper adjacent pixel is represented as S[0, −1]…S[W'−1,−1], and the position of the adjacent pixel on the left is represented as S[−1,0]…S[−1,H '−1]. The four pixels needed are selected as follows:
- When LM mode is applied and both the upper and left adjacent pixels are available, S[W' / 4, −1 ], S[ 3 * W'/ 4, −1 ], S[ −1, H'/ 4] , S[ −1, 3 * H'/ 4 ];
- When LM-A mode is applied or only the adjacent pixels above are available, S[ W'/ 8, −1 ], S[ 3 * W'/ 8, −1 ], S[ 5 * W'/ 8, −1 ], S[ 7 * W'/ 8, −1];
- When the LM-L mode is applied or only the adjacent pixels on the left are available, S[ −1, H'/ 8 ], S[ −1, 3 * H'/ 8 ], S[ −1, 5 * H'/ 8 ], S[ −1, 7 * H'/ 8];
Four adjacent luminance pixel downsampling on selected position, and after four comparisons to find the two smaller values: and
, and two larger values
and
. Their corresponding chroma samples is expressed as
,
,
and
, then the parameters can be calculated by the formula:

The following figure shows an example of the positions of the neighboring pixels on the left and the neighboring pixels above, and an example of the current block involved in CCLM mode.

It can be seen from the above formula that division occurs during the calculation of α. In order to avoid the division operation, the table look-up method is used to calculate α. At the same time, in order to reduce the space of the storage table, the diff value (the difference between the maximum value and the minimum value) and α are expressed in exponential form. For example, diff is approximately represented by a 4-bit significant part and an exponent. Therefore, for 16 valid bit values, the 1/diff table is reduced to 16 elements, as shown below:
DivTable [ ] = { 0, 7, 6, 5, 5, 4, 4, 3, 3, 2, 2, 1, 1, 1, 1, 0 }
The advantage of this is that it not only reduces the complexity of the calculation, but also reduces the amount of memory required to store the required tables.
In addition to the brightness of all the upper reference pixels and the left reference pixels to jointly calculate the parameters of the linear model, there are two other calculation methods for the model parameters, that is, the CCLM has two two modes, called LM-A and LM-L mode.
- In the LM-A mode, only the upper reference pixels are used to calculate the linear model parameters. In order to obtain more reference pixels, the upper reference pixels need to be expanded to (W+H).
- In the LM-L mode, only the left reference pixel is used to calculate the linear model parameters. In order to obtain more reference pixels, the left reference pixel needs to be expanded to (H+W).
For non-square blocks, the upper reference pixel is expanded to (W+W), and the left reference pixel is expanded to (H+H).
In order to match the chroma sampling position of the 4:2:0 video sequence, two down-sampling filters are provided to make the luminance component down-sampling 2:1 in the horizontal and vertical directions. The selection of the downsampling filter is specified by the SPS flag. The two downsampling filters are as follows, corresponding to "type-0" and "type-2":
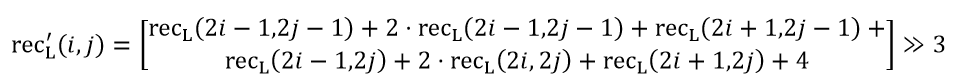

Note that when the upper reference pixel is located at the CTU boundary, only one row of luminance pixels is used for downsampling.
This parameter calculation is performed as part of the decoding process, not just as an encoder search operation. Therefore, no syntax is used to transfer the alpha and beta values to the decoder.
Two, CCLM technical coding
For chrominance intra mode coding, a total of 8 intra modes are allowed to be used for chrominance intra mode coding. These modes include five traditional intra-frame modes and three cross-component linear model modes (CCLM, LM_A and LM_L). The coding and derivation process of chrominance mode signal is shown in the following table. Chroma mode coding directly depends on the intra prediction mode of the corresponding luma block. Since a separate block division structure is enabled for the luminance and chrominance components in the I slice, one chrominance block can correspond to multiple luminance blocks. Therefore, for the chroma DM mode, the intra prediction mode of the luminance block corresponding to the central pixel of the current chroma block is directly used.
| Chroma prediction mode |
Corresponding luma intra prediction mode |
||||
| 0 |
50 |
18 |
1 |
X ( 0 <= X <= 66 ) |
|
| 0 |
66 |
0 |
0 |
0 |
0 |
| 1 |
50 |
66 |
50 |
50 |
50 |
| 2 |
18 |
18 |
66 |
18 |
18 |
| 3 |
1 |
1 |
1 |
66 |
1 |
| 4 |
0 |
50 |
18 |
1 |
X |
| 5 |
81 |
81 |
81 |
81 |
81 |
| 6 |
82 |
82 |
82 |
82 |
82 |
| 7 |
83 |
83 |
83 |
83 |
83 |
Regardless of the value of sps_cclm_enabled_flag, a binarization table is used, as shown in the following table.
| Value of intra_chroma_pred_mode |
Bin string |
| 4 |
00 |
| 0 |
0100 |
| 1 |
0101 |
| 2 |
0110 |
| 3 |
0111 |
| 5 |
10 |
| 6 |
110 |
| 7 |
111 |
In the above table, the first bin indicates whether it is in normal mode (0) or LM mode (1). If it is LM mode, the next bin indicates whether it is LM_CHROMA (0). If it is not LM_CHROMA, the next bin indicates whether it is LM-L (0) or LM-A (1). For this case, when sps_cclm_enabled_flag is 0, the first bin of the binarization table of the corresponding intra chroma prediction mode can be discarded before entropy coding. Or, in other words, the first bin is inferred to be 0, so no encoding is performed. This single binarization table is used for sps_cclm_enabled_flag equal to 0 and 1. The first two bins in the above table use its own context model for context encoding, and the remaining bins use bypass encoding.
In addition, in order to reduce the luma-chroma delay in the dual tree, when the 64x64 luma coding tree node does not use Not Split (and 64x64 CU does not use ISP) or QT for partitioning, the chroma in the 32x32/32x16 chroma coding tree node is allowed CUs use CCLM in the following way:
-If the 32x32 chroma node is not split or partition QT split, then all chroma CUs in the 32x32 node can use CCLM
– If the 32x32 chroma node uses horizontal BT partitioning, and the 32x16 child nodes are not split or use vertical BT splitting, all chroma CUs in the 32x16 chroma node can use CCLM.
Under all other luma and chroma coding tree segmentation conditions, CCLM is not allowed for chroma-CU.