The "Nazhang Takes You to Read Papers" series is mainly to urge myself to read excellent papers and listen to academic lectures, and share them with everyone, hope you like them. Since the author's English level and academic ability are not high and need to be continuously improved, please criticize and correct me. Welcome to leave me a comment. I look forward to moving forward with you on the academic road. Come on~
Recently I plan to squeeze time to read the papers and write related papers. This blog is shared by the teacher "Deep Eyes" Pvop at Station B. The topic is "How do masters learn NLP". It is highly recommended that you go to the original website to learn and purchase The course is really a good tutorial. Xiuzhang also hopes to go forward with you on the road of academic research. The doctor's journey is long, come on~
- https://www.bilibili.com/video/BV1zf4y1y7g6?p=2
- https://blog.csdn.net/oldmao_2001/article/details/101898723

Previous recommendation:
[Xiuzhang takes you to read the paper] (01) What can I do to save my procrastination? How to increase the interest of beginners in programming and the introduction of LATEX
[Na Zhang takes you to read the paper] (02) SP2019-Neural Cleanse: Identifying and Mitigating Backdoor Attacks in DNN
[Na Zhang takes you to read the paper] (03) Tsinghua Zhang Chao teacher-GreyOne : Discover Vulnerabilities with Data Flow Sensitive Fuzzing
[Na Zhang takes you to read the paper] (04) Is artificial intelligence really safe? The Bund Conference of Zhejiang University team shares AI countermeasure sample technology
[Na Zhang takes you to read the paper] (05) NLP knowledge summary and NLP paper writing method-Pvop teacher
detailed explanation of malicious code detection technology based on machine learning
Article Directory
1. Why learn the basic theory of NLP
Before talking about why should we learn NLP (Why should we learn NLP), everyone may see the sentence "NLP is the jewel in the crown of artificial intelligence." The figure below divides artificial intelligence into four levels, which are becoming more and more complex from the bottom up. Natural language processing can be used for language communication and can extract information from large-scale text data.
- Operational intelligence: computer CPU\GPU operation speed, the most basic bottom layer
- Perceptual intelligence: mainly includes hearing, vision and touch, involving speech recognition, image recognition, and CV fields
- Cognitive intelligence: mainly includes language, knowledge and reasoning. Natural language distinguishes humans from animals, and language reflects intelligence
- Create intelligence: build robots that have human emotions and communicate with humans
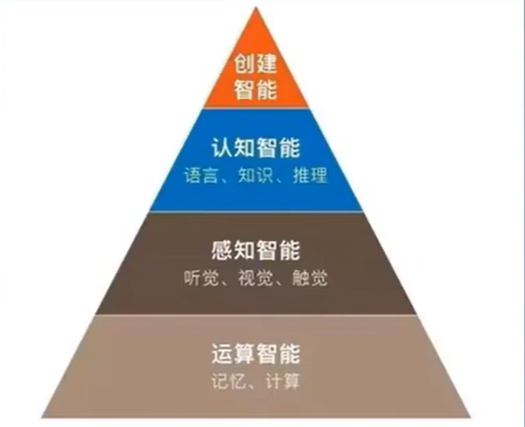
1. As the purpose of language communication
This purpose mainly talks about intelligent dialogue and machine translation.
- Smart dialogue
Smart customer service, smart speakers - Machine translation
Simultaneous interpretation, text translation
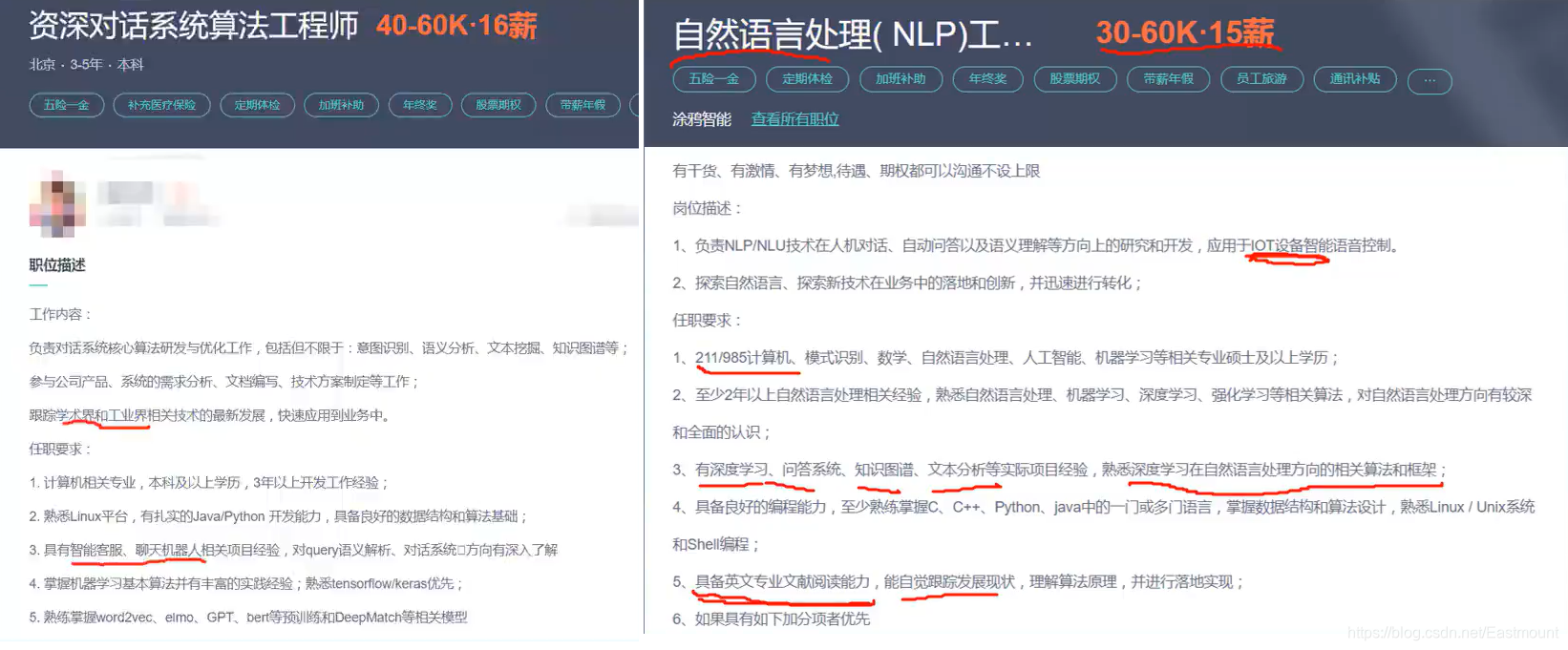
For example, the picture below is a piece of information for recruiting NLP algorithm engineers. He needs to be able to track the latest developments in academia and industry. Because new technologies are updated very quickly, academic papers are very important. At the same time, knowledge of query semantic analysis, tensorflow\keras, word2vec, GPT, bert, DeepMatch, etc. is required. If you have CCF A conference papers (such as ACL\AAAI), many big companies will recruit, and the monthly salary is also very high.
2. Extract information from large-scale text data
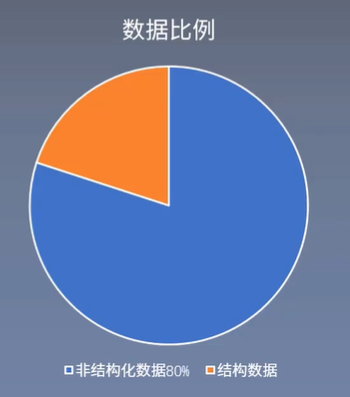
Data is usually divided into structured data and unstructured data, as follows:
- Structured data: database, date, phone number, etc.
- Unstructured data: text, email, social media, etc.
Unstructured data contains a large amount of information to be mined. Extracting information from large-scale text data derives the following tasks:
- Machine reading comprehension: give you an article and a question to find answers from the article, similar to English reading comprehension. For example, search for the birth date of "Yao Ming" from the article.
- Information extraction: Convert news from unstructured data to structured data, such as time, location, people, events, etc.
- Public opinion analysis: For example, discovering public sentiment tendencies of the public through microblog mining, and public relations companies researching the evaluation of artists.
- Text classification: For example, divide news into sports or fashion categories, and identify and classify spam.
- …
So, why learn natural language processing by reading papers?
- With the rapid development of technology, the most cutting-edge technology can be obtained through thesis.
- Thesis can gain first-hand knowledge.
- He is familiar with three hundred Tang poems, and he can chant without writing poems.
- Reproducing thesis can also improve programming ability. Algorithm engineers include theoretical and engineering skills. The programming ability is enough, and a good idea can reproduce and realize your own ideas.
- …
Why read a baseline paper?
The following summarizes the basics of natural language. The three most basic directions are as follows:
- Word vector
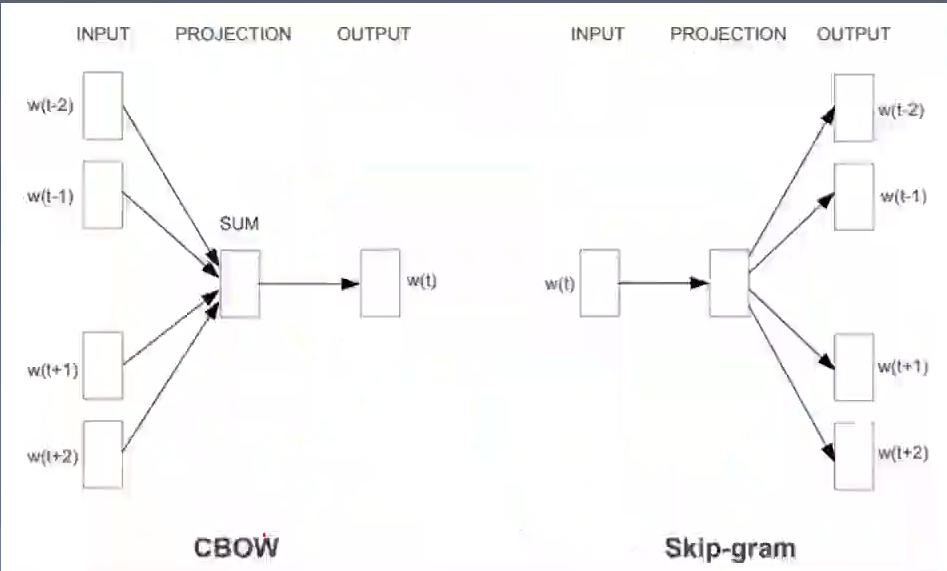
Nowadays, natural language processing is based on neural networks. The input required by neural networks is numbers, so words need to be mapped into numbers for input. This is the role of word vectors, and the one-hot dimension is too large and sparse, and the word vector With semantic information. - Sequence generation Seq2Seq
Sequence generation tasks such as dialog generating responses, smart speakers generating sequences, etc., are also called Seq2Seq tasks. Only when you can generate some beautiful sentences can you be considered intelligent, and you have been doing the task of classifying others is a statistical method. - Attention mechanism
Attention is to find important information from a lot of information.
At the same time, text classification and machine translation are two important tasks. Among them, textcnn and chartextcnn papers are pure text classification tasks, fasttext is related to word vectors, HAN is related to attention, and SGM is sequence generation for multi-label text classification. Machine translation mainly introduces two classic models, namely Deep LSTM and Bahdanau NMT.

2. NLP development history and direction
The development process here is mainly explained in conjunction with the Baseline paper.
1. In 2003, NNLM neural network language model was proposed
- Traditional method: learning language models through statistical n-grams
- NNLM: Automatically learn a language model through deep learning, and the effect is equivalent to the n-grams model, the first paper that maps words into vectors

2. 2013 Word2Vec model
The previous word vector learning speed was too slow, and the training time was too long to train on a large-scale corpus, so the effect was poor. In 2013, Google proposed the Word2Vec model. By accelerating the training of word vectors, it achieved very good word vectors trained on large-scale corpus, which greatly promoted the development of natural language processing. The importance of Word2Vec in the NLP field is similar to the importance of AlexNet in the CV field. It is really critical.
3. 2014 TextCNN model
The previous text classification model was more complicated and the effect was average. The TextCNN model is very simple, but the effect is very good, including convolutional layer, pooling layer and fully connected layer, convolutional layer kernel_sizes=(2,3,4). Why is it effective? Because it uses Word2Vec, it has achieved very good results on a simple CNN model by using pre-trained word vectors.
Yoon Kim proposed TextCNN in the paper (2014 EMNLP) Convolutional Neural Networks for Sentence Classification.
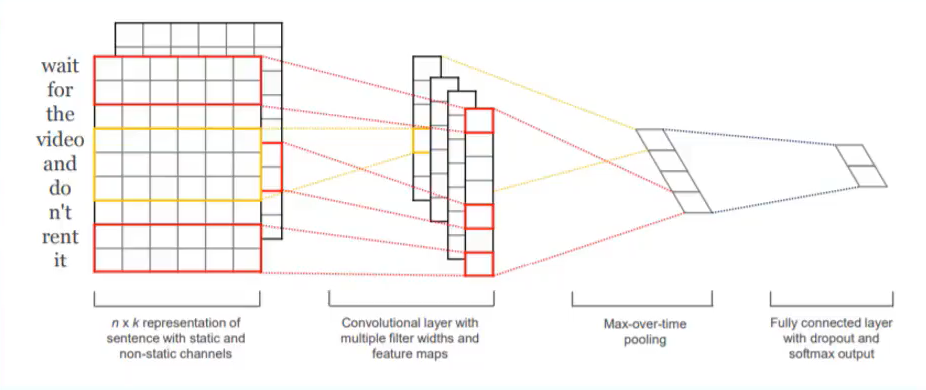
4. 2014 Deep NMT model
The previous statistical machine translation contained complex rules and statistical methods. Neural machine translation used neural networks to automatically train neural machine translation models, including four-layer SLTM. In 2016, Google Translate officially used neural machine translation instead of statistical machine translation. The person in charge stated that “this means replacing 500,000 lines of phrase-based machine translation code with 500 lines of neural network model code”.
Ilya Sutskever(Google)在2014 NIPS年发表Sequence to Sequence Learning with Neural Networks。
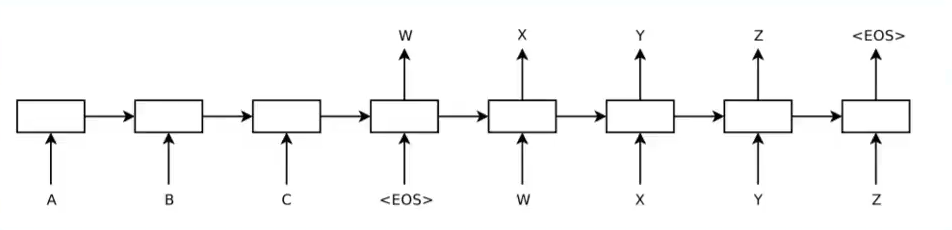
5. 2015 Attention model
The attention mechanism is one of the core algorithms of natural language processing. It can automatically select key information from complex information through a simple mechanism. Because natural language processing has a huge vocabulary, only certain vocabulary is very important, such as sad and happy in sentiment classification.

3. Technology Evolution Path
1. One-hot expresses wanting the development of distributed representation
- Word2Vec
- Glove
One-hot means that N-bit status registers are mainly used to encode N states, and each state has its own independent register bit. You have as many words as you have, so the dimensions are large and sparse. Distributed representation has a low dimension and contains semantic and grammatical information, and their similarity can be obtained through word vectors.
- ["China", "United States", "Japan", "United States"] —> [[1,0,0], [0,1,0], [0,0,1], [0,1,0 ]]

2. The development of machine learning methods to deep learning methods
- TextCNN
- CharTextCNN
- NMT
Previously, it was based on statistical features, such as n-grams counting how many phrases the article has, how many times each phrase appears, plus machine learning model (SVM, LR) prediction. The deep learning method is the integration of feature engineering and model.

3. Development of large granularity to small granularity
- FastText
- CharTextCNN
- C2W
Previously, they were all word-level models, such as Word2Vec, Glove, and TextCNN. Each word is mapped to a vector. Some people will think "Why not map each character to a vector?", or map the prefix and suffix (such as pre) As a vector, a small-grain N-gram model and a character-level model have been developed. For example, paper was a vector before, but I didn’t recognize it after papers, so a small-granularity model was slowly developed.

4. The development of simple tasks to complex tasks
- NMT
- SGM
Complex tasks include neural machine translation, multi-category text classification, reading comprehension, and information extraction.

4. Recommended learning path
I hope you don’t worry about the weak foundation or change your major. I hope you can learn from basic theoretical knowledge, programming practice (Python+Pytorch), paper reading, and find ideas for improvement.
- Basic knowledge learning
Programming ability, deep learning, basic knowledge of natural language processing - Baseline learning
word vector, text classification, Seq2Seq, Attention - Advanced learning
Information extraction, pre-training model, graph neural network, knowledge graph

So, how to produce papers?
If you want to send CCF A, you need to have a good idea. To find an idea, you need to read a lot of papers, find out the problem (idea) by looking at what others do and shortcomings, and then find solutions and research, and check to see if anyone is there Similar papers have been posted. To solve the problem, you must continue to read a lot of papers, add new ideas repeatedly, and finally produce papers.
Here is a supplement to the learning path of teacher Pvop. I really admire it. I also need to study hard and publish my own class A paper as soon as possible.
Teacher Pvop first started reading from text classification papers and found that there was a problem with the part of speech in Google translation. He wondered if he could combine part of speech and neural machine translation (part of speech + NMT), which was equivalent to discovering the first idea. Then I went to read the article of neural translation and found that someone else had done it. This is the paper crash. Then I continued to read about more than 10 articles, and found that many people have already done it and formed the field, so I stopped doing this work. At that time, I also tried to improve other people's models. In fact, the idea was still possible, but the programming ability was relatively weak at the time, and the TensorFlow code was not improved, so there was no written document. Then continue to read the article on machine translation and see the noise added in machine translation to judge the translation effect. He wondered whether he could add noise in text classification or named entity recognition, forming his own final idea, which was finally delivered to AAAI. Because of the inconsistent direction of the teacher, the whole process was done by himself.
In the three major natural language processing conferences, their papers are relatively high, although there are C-type ones.
- ACL(CCF-A)
- EMNLP(CCF-B)
- NAACL(CCF-C)

The basic knowledge is shown in the figure below:

The following is a learning path NLP Baseline papers, I recommend everyone to study these basic papers, many works in this field are improved on their basis, they are the cornerstone of NLP. The first article here is about Word2Vec. Although ICLR is not on the CCF list, its influence is very high because it was only held in 2013, and the eighth attention mechanism is also the conference.

The knowledge system is given below, and it is recommended that you go to DeepEye to learn their courses.
- Elective knowledge
One-stop basic learning, clearing obstacles for students with weak foundations - baseline
study baseline paper common knowledge module, entry NLP \ CV, to lay the foundation for entry into the field of subdivision - Subdivided topics
Learn classic and cutting-edge knowledge in subdivided fields, understand the development trend of research fields, and apply knowledge to engineering
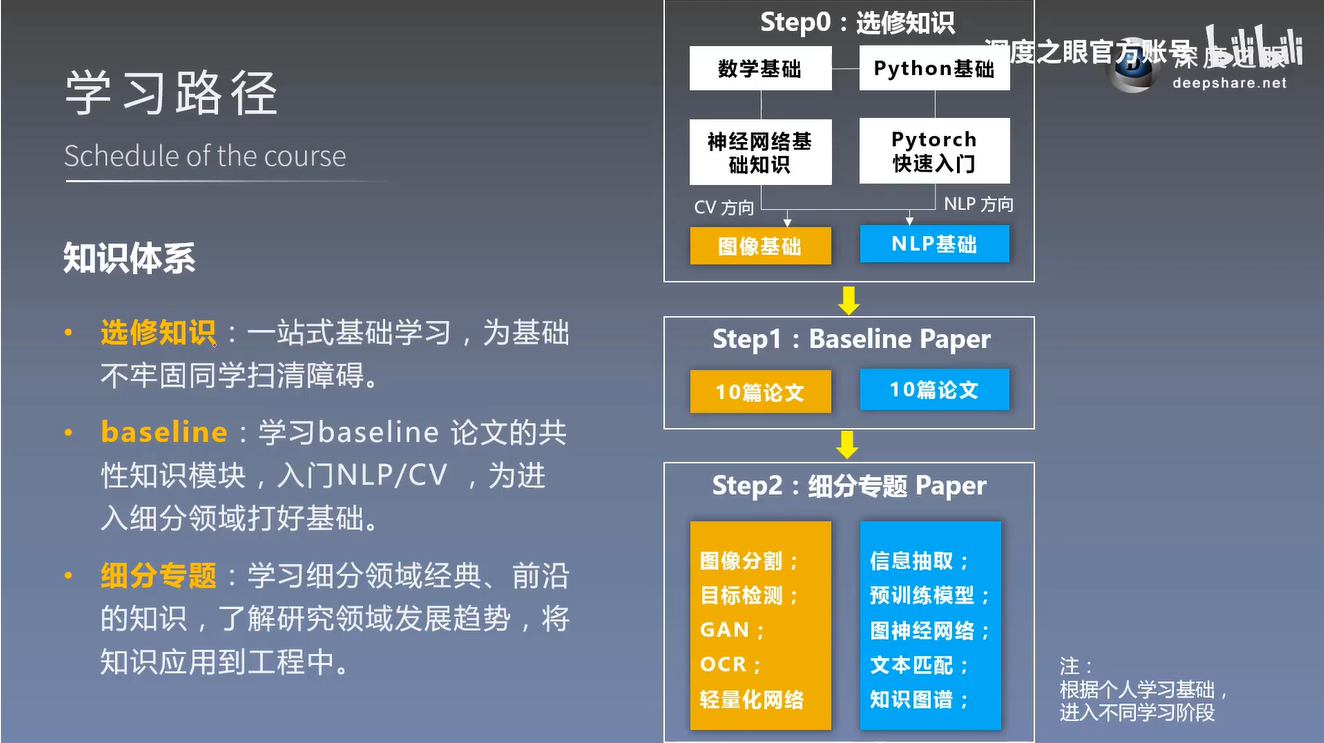
V. Course Arrangement
Their course schedule is one Paper study a week, including papers and code reproduction, and I feel pretty good. The specific content is as follows
- Word2Vec: word vector training
- Glove: word vector training
- C2W: Word Vector Training
- TextCNN: Text classification
- CharTextCNN: text classification
- FastText: word vector + text classification
- Deep NMT:Seq2Seq
- Bahdanau NMT : Seq2Seq
- Han Attention: attention mechanism
- SGM: Sequence annotation for text classification

The reading method of each paper is shown in the figure below:
- Guide
Reserve knowledge and background introduction (what problem the paper solves, why it is done and the significance of research) - intensive reading
Model intensive lecture, experimental analysis and discussion, paper summary (key points, innovation points, inspiration points) - Code
Data set, based on Pytorch implementation, training and testing

The learning gains are summarized as follows:
- Learn to understand the key technologies of NLP, such as word embedding, pre-training, text classification, Seq2Seq, attention mechanism, etc.
- Learn a lot of programming knowledge of NLP, such as word segmentation, clause, word2id, attention writing, etc.
- Learn how to read a paper, know the general structure of the paper, so that you can read the paper without rush and focus clearly
- Learn the general structure and writing methods of papers, and lay a foundation for writing papers
- Have the ability to independently learn other characters of NLP


Six. Summary
The embracing wood is born at the end of the mill; the nine-story platform starts from the basement; the journey of a thousand miles begins with a single step.
Finally, I hope this article is helpful to you!

At the same time, I will also help promote their official account, thank you again Pvop teacher of Deep Eyes, come on!

The newly opened "Nazhang AI Security Home" on August 18, 2020 will mainly focus on Python big data analysis, cyberspace security, artificial intelligence, Web penetration and offensive and defensive technology, and share CCF, SCI, South and North nuclear papers The algorithm is implemented. Nazhang’s House will be more systematic, and will reconstruct all the author’s articles, explain Python and security from scratch, and have written articles for nearly ten years. I really want to share what I have learned and felt. I would also like to invite you to give me your advice and sincerely invite your attention! Thank you.

(By: Eastmount 2020-11-20 night in Wuhan https://blog.csdn.net/Eastmount )