1. Baidu search Tesseract-OCR to download Tesseract-orc-setup-3.02.02.exe . Remember your installation directory (the blogger’s installation path is: C:\Program Files(x86)\Tesseract-OCR), and you will need to configure the environment variables later.
If you are not doing English graphic recognition, you also need to download recognition packages in other languages. Recognition packages in other languages are downloaded . For example, the simplified character recognition package corresponds to chi_sim.traineddata, and the traditional character recognition package corresponds to chi_tra.traineddata.
There are other installation package download addresses:
Stable version: https://digi.bib.uni-mannheim.de/tesseract/tesseract-ocr-setup-3.05.01.exe
Development version: https://digi.bib.uni-mannheim.de/tesseract/tesseract-ocr-setup-4.00.00dev.exe
2. I installed the development version
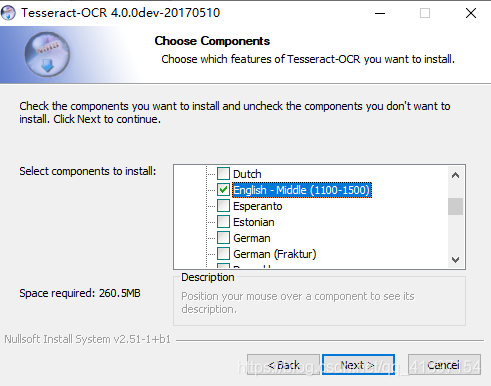
Here you can expand and choose your favorite language pack. Since I am dealing with the old newspaper series, it is best to have both traditional and simplified characters. By the way, leave the English as well.
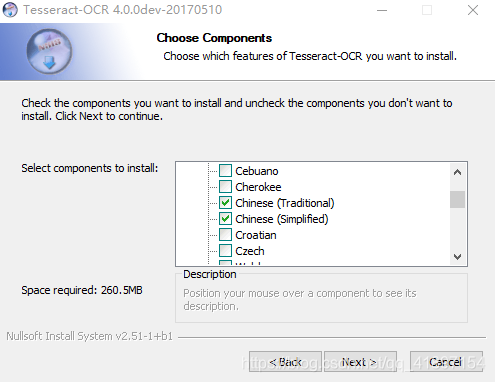
Choose installation location

Start menu name (I don’t know what it’s used for)
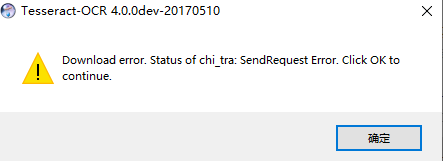
An error is reported , as follows
Solution
https://blog.csdn.net/qq_41897154/article/details/109499741
Found a big guy’s suggestion, first keep the address https://github.com/PaddlePaddle/PaddleOCR
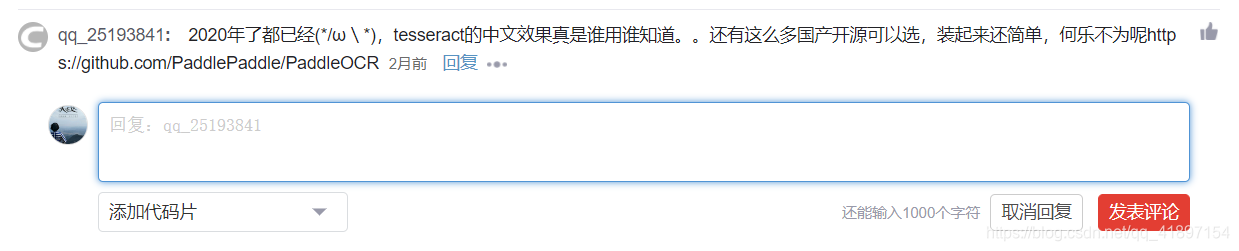
Seeing a font made by it, it feels a bit powerful
https://www.cnblogs.com/wangkevin5626/p/9640165.html